基于YOLOv3模型的实时行人检测改进算法
2019-11-21范丽苏兵王洪元
范丽,苏兵,王洪元
(常州大学 信息科学与工程学院,江苏 常州 213164)
0 引言
随着科学技术的发展,行人检测在智能视频监控、车辆辅助驾驶、智能机器人等研究领域的应用也变得更加广泛。对视频中行人的检测与识别,不仅需要保证实时性,还需要保证准确性。行人检测是计算机视觉领域中一个基础性的研究课题,行人检测在智能视频监控、车辆辅助驾驶、智能机器人等领域有着广泛的应用。行人检测是指对图片或者视频进行判断,判断图片和视频中是否包含行人以及行人的具体位置。行人检测准确性和实时性是整个系统的一项重要能力。由于行人图像受穿着、姿态及拍摄角度等的影响,给行人检测增加了难度,使得行人检测成为计算机视觉领域的研究难点与热点。
行人检测属于目标检测的范畴,传统的目标检测方法一般分为三个阶段:首先在给定的图像上使用不同大小的滑动窗口选取候选区域;对候选区域提取特征;使用分类器进行分类。提取特征一般采用人工设计的方法,如HOG[1]、SIFT[2],分类阶段主要使用支持向量机(Support Vector Machine,SVM)[3]、Adaboost[4]等分类器。传统的目标检测存在两个主要问题[5]:(1)基于滑动窗口的区域选择是穷举的策略,时间复杂度高,窗口冗余;(2)手工设计的特征对于多样性的变化并没有很好的鲁棒性。这些弊端很大程度上限制了算法的应用。深度神经网络的出现颠覆了传统的特征提取方式,通过大量的数据训练能够自主学习有用的特征[6]。目前主流的通用目标检测方法主要分为两种:(1)two stage方法,比如R-CNN[7]、SPP-Net[8]、Fast R-CNN[9]、Faster R-CNN[10-12]、R-FCN[13];(2)one stage方法,比如 YOLO[14]、YOLOv2[15-17]、SSD[18]、YOLOv3[19]。区域建议的目标检测算法R-CNN首次将CNN引入目标检测,在很大程度上提高了目标检测效果,成为目标检测领域的主流算法。但R-CNN需要对提取的每个区域建议(Region Proposal)都要进行一次前向CNN实现特征提取,这样计算量较大,无法实时更新。针对R-CNN和SPP-Net测试和训练速度慢等问题提出了Fast R-CNN,简化SPP(Spatial Pyramid Pooling,SPP)为单尺度即ROI[20](region of interest,ROI) pooling,且引入多任务学习,将多个步骤整合到一个模型中,同时Fast R-CNN引入多任务损失函数,使整个网络的训练和测试变得十分方便,极大地提高了实时性。Faster R-CNN在Fast R-CNN基础上,引入区域建议网络(Region Proposal Networks,RPN),在VOC数据集达到较高的精度。R-CNN系列有很高的检测精度,但其检测速度较慢,难以满足目标检测实时性的要求。基于回归的YOLO算法,速度能达到45FPS,YOLO没有候选框机制,只使用7×7的粗糙网格回归,对目标的定位并不很精准,对小物体的检测效果不好。YOLO中预测边界框坐标直接用全连接层,导致较多空间信息丢失,YOLOv2借鉴Faster R-CNN,引入anchor机制,利用k-means在训练集中聚类得到anchor值,在卷积层使用anchor boxes,大大提高算法召回率。YOLOv3在不改变YOLOv2的检测速度基础上,借鉴残差网络的思想,引入多个残差网络模块和使用多尺度预测,提高小目标检测精度,保证目标检测的准确率和实时性。
综上所述,区域建议的目标检测算法R-CNN首先产生候选框,再通过卷积神经网络进行样本分类;基于回归方法的目标检测算法则不用产生候选框,将目标框定位问题转化为回归问题。前者在检测准确率和定位精度上占优,后者在算法速度上占优。实时检测是目前智能产品市场的主流需求。本文选择在速度和准确率上综合表现最好的YOLOv3算法作为研究对象。虽然YOLOv3已经取得了较好的实时检测效果,但对于行人检测来说仍有不足。主要表现在以下三个方面:(1)YOLOv3的检测精度低于Faster R-CNN;(2)YOLOv3网络的训练与测试采用COCO和VOC数据集,此数据集有众多种类,引入的anchor值具有一定的适用性,并不专门针对行人检测设计;(3)数据集中难,样本识别率不高。因此,本文研究以YOLOv3模型为基础的改进算法。引入标签平滑[21-22](Label Smoothing),实现对模型进行约束,降低模型过拟合的程度;改进多尺度检测,增加预测层可以利用更多的特征图(Feature Map);通过k-means聚类得到anchor的个数与值,可以自动学习行人特征,实现高精度与快速的行人自动检测。
1 YOLOv3原理
2016年Redmon等提出YOLO算法,不产生候选框,加快检测速度。YOLOv3在YOLOv2的基础上提出,保持YOLOv2的检测速度,并且大大提高了检测的准确率,对小目标效果更好。
YOLOv3将输入的图片缩放到416×416,并按照特征图的大小划分为S×S个单元格,在特征图为13×13、26×26、52×52尺度上检测,每个单元格有3个anchor boxes预测3个边界框。
卷积神经网络在单个单元格上为单个边界框预测4个值,即目标框(x,y)坐标与宽w和高h,分别记为tx,ty,tw,th。目标中心在单元格中相对于图像左上角的偏移(cx,cy),anchor box的高度和宽度pw,ph,则修正后的边界框为:
bx=σ(tx)+cx,
by=σ(ty)+cy,
bw=pwetw,
bh=pheth.
(1)
YOLOv3中用全新设计的Darknet-53提取特征。网络中大量使用残差连接,增加网络的深度;并结合FPN网络结构,在网络后两个特征图上采样,与网络前期相应尺寸的特征图聚合,再经过卷积网络得出预测结果。在目标检测过程中,YOLOv3将13×13的特征图进行卷积操作,然后送入检测层,得到一次检测结果;然后将13×13特征图上采样得26×26特征图与之前网络中26×26特征图进行融合,将新的特征图进行卷积操作后送入检测层,得一次检测结果;再将26×26特征图上采样得52×52特征图与之前网络中52×52特征图进行融合,将新的特征图进行卷积操作后送入检测层,得一次检测结果。将3次检测结果进行非极大值抑制处理,得到最终检测结果。整个检测过程如图1所示。
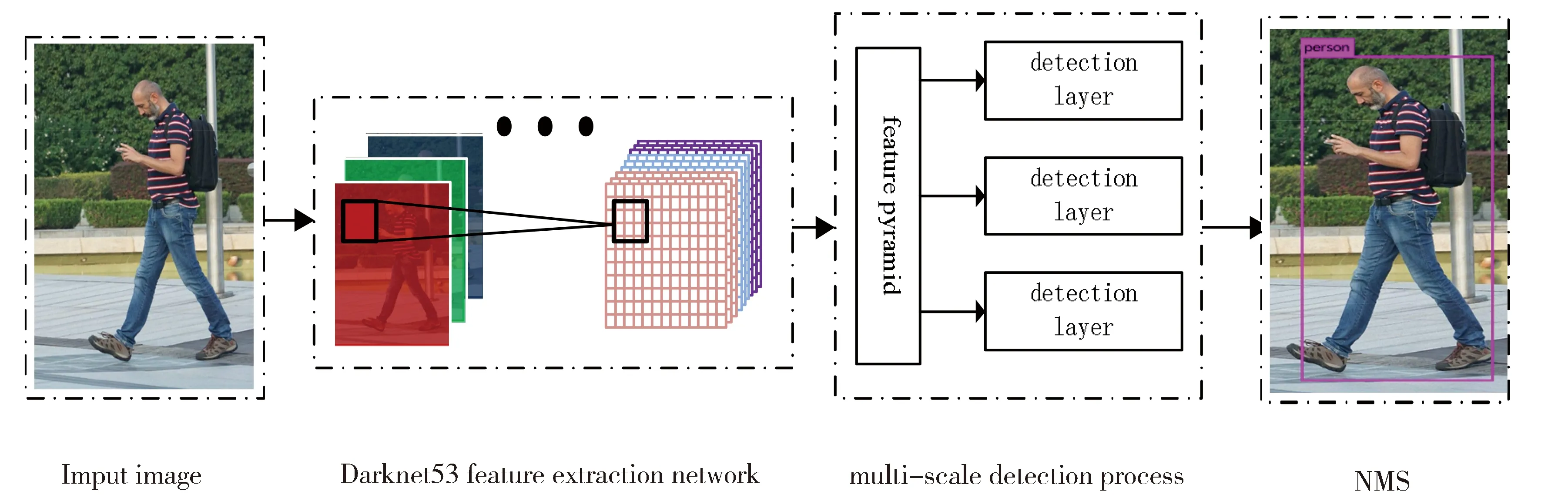
Fig.1 YOLOv3 algorithm detection flow chart图1 YOLOv3算法检测流程图
2 基于YOLOv3模型的改进方法
2.1 标签平滑
对于每个对象,检测网络通常使用softmax函数计算所有类的概率分布:

(2)
其中zi是直接来自最后一个线性层的非标准化logits,用于分类预测。对于训练期间的目标检测,我们仅通过将输出分布p与真实值分布q与交叉熵进行比较来修改分类损失:

(3)
q通常是单热分布,其中正确的类具有概率1而所有其他类具有0。然而,Softmax函数只能在zi≫zj时接近这个分布,但∀j≠i从未到达过。这会造成模型过于相信预测的类别,无法保证模型的泛化能力,容易造成过拟合。
LSR (Label Smoothing Regularization,LSR)由Szegedy等人提出。LSR防止模型对样本的预测值过度关注概率较大类别,忽视概率较小类别,实现对模型进行约束,降低模型过拟合程度。
(4)
其中K是类的总数,ε是一个小常数。该技术降低了模型的置信度,通过最大和最小logits(未归一化概率)之间的差异来衡量。
2.2 多尺度检测改进
YOLOv3中,引入FPN(Feature Pyramid Networks)网络,通过上采样和融合不同层的特征,利用低层特征的高分辨率和高层特征的高语义信息,在3个不同尺度的特征图上检测物体。针对行人实时检测中行人远近导致行人大小不一样,本文将YOLOv3原有的3个尺度扩展为5个尺度检测模块,给不同尺度特征图分配准确的锚点框,提高行人检测的精度。本文提出的YOLOv3多尺度检测模块如图2所示。

Fig.2 Improved YOLOv3 network structure图2 改进的YOLOv3网络结构图
2.3 目标框维度聚类
YOLOv3延用了YOLOv2思想,采用k-means对数据集中的bounding box进行聚类获得合适的anchor。 Anchor的设计影响目标检测的速度与精度。 Redmon等提出维度聚类的方法,通过k-means算法对数据集中标记的目标框来进行维度聚类。YOLOv3在VOC和COCO数据集上聚类,anchor的数量为9。本文根据行人检测数据集和5个尺度检测层的特点,采用k-means维度聚类的方法对训练集的边界框做聚类,选取合适的边界框先验,对行人进行更好的预测,聚类方法中距离公式定义如下:
d(box,centroid)=1-IOU(box,centroid) .
(5)
选取合适的IOU分数,可以在模型复杂度和召回率之间取得好的平衡。
3 实验结果与分析
3.1 实验数据
本文训练的原始数据集采用的是Caltech Pedestrian数据集,Caltech Pedestrian数据集时长约10 h的城市道路环境拍摄的视频,图像分辨率为640×480像素。本文测试集选取24 438张Caltech数据集中图片。本文选取Daimler、 INRIA数据集作为测试集,用于评估模型的泛化能力。Daimler行人数据集是采用车载摄像机获取,更加贴近真实情况,从中选取测试集4 000张。INRIA行人数据集是当前使用最广泛的静态行人检测数据库。样本信息如表1所示。
3.2 实验配置与训练
本实验在Ubuntu16.04系统进行,显卡采用英伟达公司生产的TITAN XP 12G的独立显卡,安装CUDA8.0、CUDNN5.1以及OpenCV3.2。代码运行环境为2.7.12。框架为Darknet-53。

表1 样本信息
训练采用的初始学习率为0.000 1,policy为steps,steps分别取100,25 000,35 000,scales为10,0.1,0.1; max-batches为50 000;momentum为0.9,decay为0.000 5经过50 000次迭代后网络最终收敛。网络训练过程中损失变化曲线如图3所示。

Fig.3 Network iteration loss value change diagram图3 网络迭代损失值变化图
3.3 检测结果
3.3.1 多尺度检测结果对比
对YOLOv3原有的3个尺度扩展为5个尺度检测,在Caltech测试集中测试结果,召回率从93.47%提高到 95.59%,3个尺度检测与5个尺度检测结果如表2所示。从表2中第2列和第3列可以看出,改进后的5个尺度检测的YOLOv3比之前没有改进的3个尺度的YOLOv3 mAP整体有提高,说明改进的5个尺度检测有效果,提高检测精度。
3个尺度与5个尺度检测效果如图4所示。(a)是3个尺度YOLOv3检测效果图;(b)是5个尺度YOLOv3检测效果图。从图4(a)和(b)中可以看出,改进后的5个尺度检测效果比改进前的3个尺度检测效果好。
3.3.2 优化目标框维度聚类
本文根据行人检测数据集和5个尺度检测层的特点,采用k-means聚类的方法。本文权衡平均交并比(avg iou)与锚点框(anchor box)的数量,其关系图如图5所示,确定anchor数量是15,anchors值分别为(10,32)、(7,20)、(9,27)、(12,32)、(9,43)、(13,44)、(17,47)、(15,61)、(20,63)、(22,82)、(30,99)、(38,134)、(51,187)、(71,225)、(109,322)。根据实验得到的anchors值,分配5个尺度每个尺度3个锚点框可以预测3个边界框,更改配置文件重新训练模型。

表2 mAP与迭代次数关系对比

Fig.4 Comparison of detection results before (a) and after (b) improvement图4 改进前(a)和改进后(b)检测效果对比
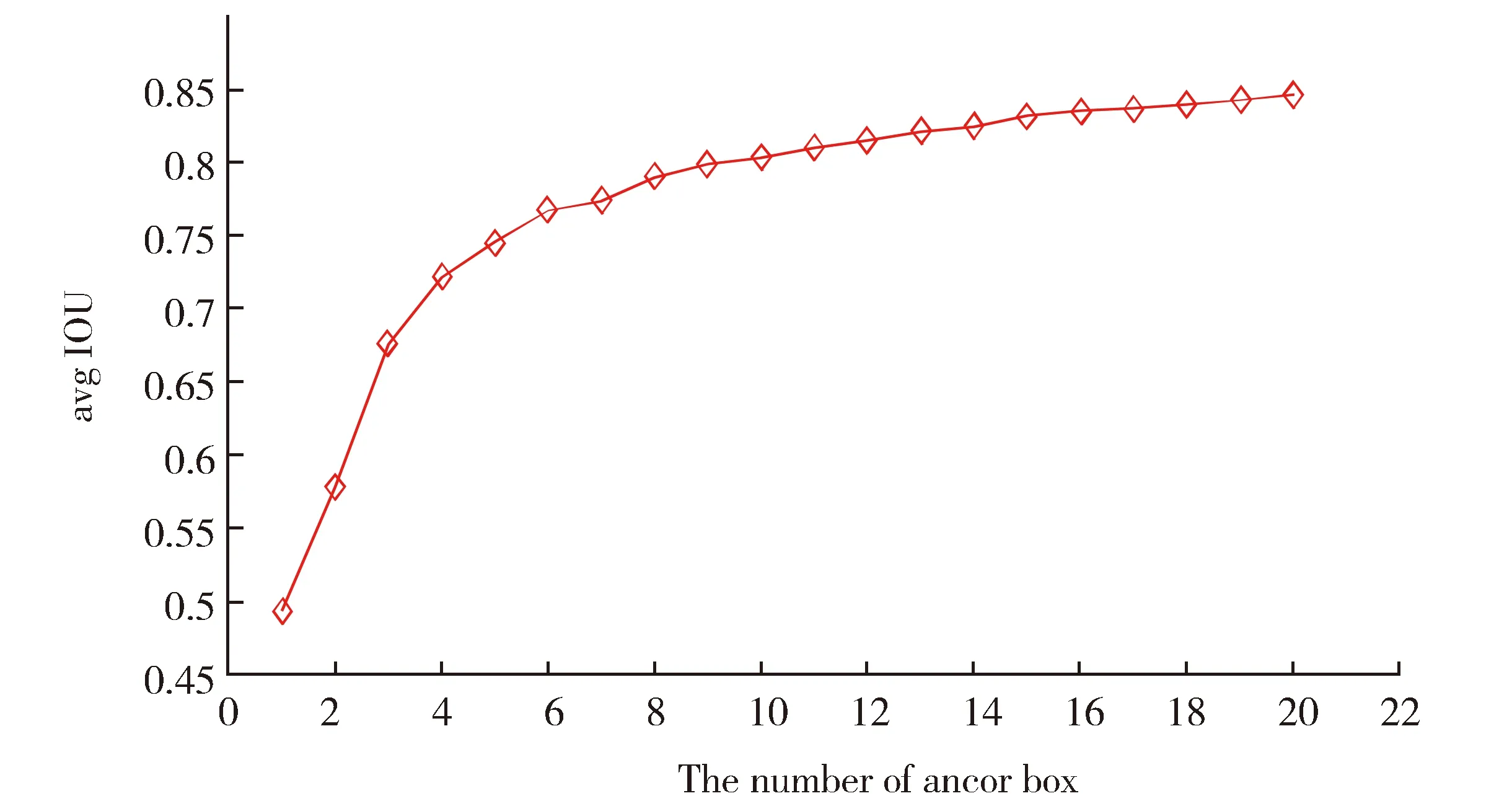
Fig.5 Relationship between the number of anchor boxes and the average IOU图5 锚点框数量与平均交并比的关系
3.3.3 确定最佳阈值
子区域的合并会造成检测窗口的冗余,导致目标可能会被重复框选,影响检测结果。根据不同的阈值得到的检测效果,确定最佳阈值。实验结果如表3所示。从表3中可以看出, 精确度与召回率二者随着阈值变化成反比关系,F1-score是综合考虑精确度和召回率。当阈值约为0.20时,精确度为93.74%,召回率为88.14%,此时检测效果最佳。
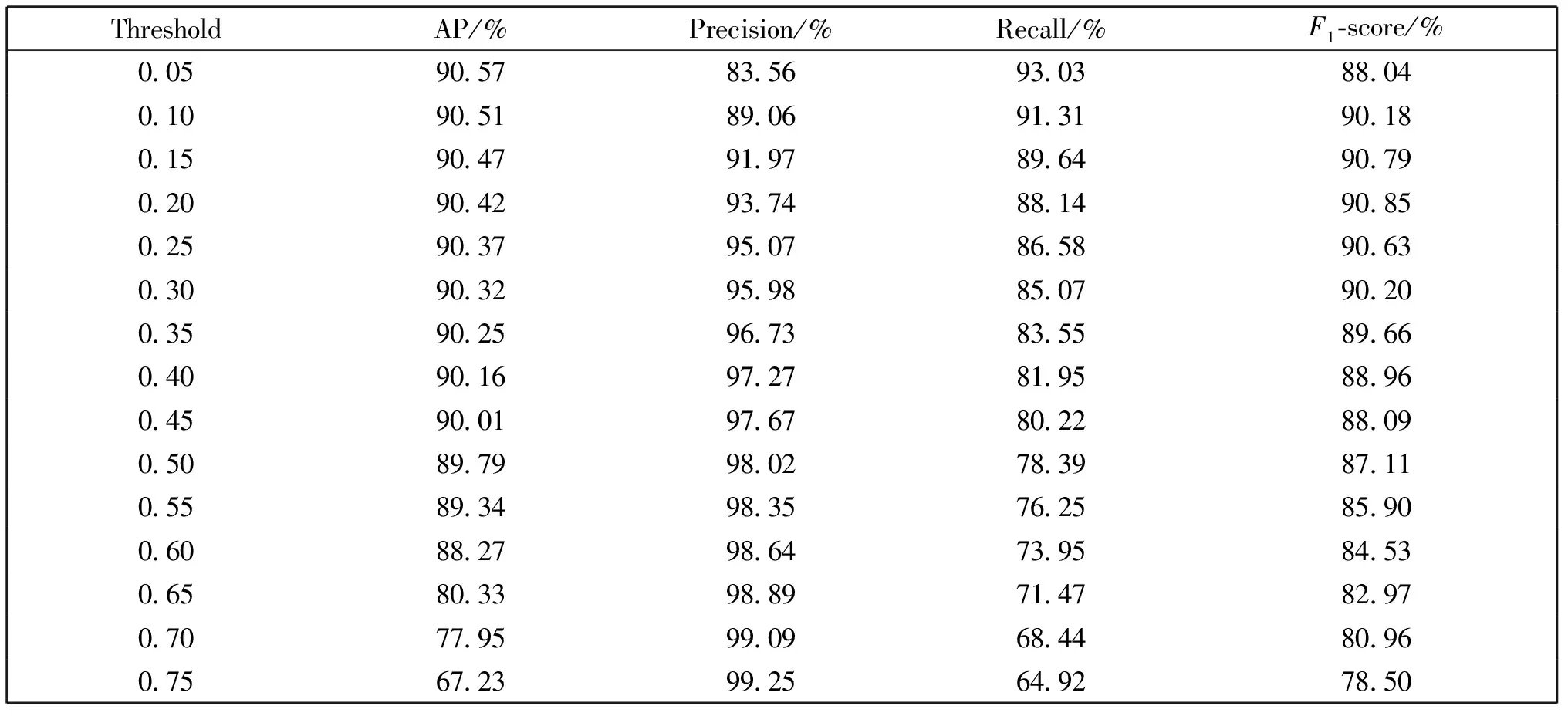
表3 不同阈值检测结果对比
3.3.4 标签平滑数据增强方法检测对比
在5个尺度检测的YOLOv3中融入标签平滑数据增强方法,提高检测精度实验结果如表4所示。从表4中可以看出,融入标签平滑方法的模型mAP和Recall值都有所提高。

表4 在Caltech测试集上测试结果
3.4 不同测试集检测结果对比
为了评估本文算法的好坏,本文在3个不同的测试集上进行模型测试,测试结果如表5所示。从表5中可以看出,本文算法的鲁棒性和泛化能力较好。

表5 不同方法在不同测试集上的检测结果对比
3.5 与其他检测算法对比
将基于YOLOv3改进得到的算法(即本文算法)与YOLOv3、Faster R-CNN这两种目标检测算法在实际场景中进行比较,对比结果如表6所示。训练集采用Caltech数据集,测试是参加2018全球(南京)人工智能应用大赛中官方提供的实际场景中一段视频,视频分辨率为1 920×1 080。从表中可知,与Faster R-CNN算法相比,本文算法在实时性和准确度都略有提高;与原始YOLOv3算法相比,本文算法精度有所提高,但检测速度低于YOLOv3,是因为YOLOv3有3个检测层,本文算法有5个检测层,增加一点测试时间,但仍然满足检测实时性的要求。本文算法比原始YOLOv3算法训练时间长,因为从3个尺度检测扩大到5个尺度检测,实际上模型的网路结构由原来的106层扩大到130层,加深了网络层数,所以训练的时间变长。

表6 不同目标检测算法对比
3.6 实际场景检测结果
本文测试模型的泛化能力,将算法用于实际场景中检测,检测结果如图6所示。从图6(a)和(b)中可以看出检测效果很好,从图6(c)和(d)中可以看出近处的目标检测效果好,但远处目标出现漏检现象。

Fig.6 Pedestrian detection effect in the actual scene图6 实际场景中行人检测效果
4 结论
本文提出一种基于YOLOv3框架的行人实时检测改进算法。该算法以YOLOv3为基础网络结构,根据行人检测任务特点进行算法的优化与改进。通过融入标签平滑,降低模型过拟合程度;增加多尺度检测,利用更多的图片信息;目标框维度聚类等方法来改进检测效果。实验结果表明,本文提出的方法比原始YOLOv3方法检测效果好,视频的检测效果基本达到实际应用的要求,满足行人视频检测需求。但视频中远处行人和遮挡严重的行人检测的出现漏检现象,下一步将进一步研究,尽可能的提高远处行人检测效果。
