基于无监督迁移成分分析和深度信念网络的轴承故障诊断方法
2019-11-20谭俊杰杨先勇徐增丙王志刚
谭俊杰,杨先勇,徐增丙,王志刚
(1.武汉科技大学冶金装备及其控制教育部重点实验室,湖北 武汉,430081;2.武汉科技大学机械自动化学院,湖北 武汉,430081;3.中国舰船研究设计中心,湖北 武汉,430064)
状态监测是保障设备正常运行的重要手段。通常情况下,被监测设备规模大,设备监测点多,每个测点的采样频率高、数据采集周期长,因此,监测系统获取的数据反映了机械设备状态的“大数据”特点[1]。由于监测到的正常样本多,故障样本少甚至没有,如何有效利用这些样本数据进行故障诊断分析具有重要的研究意义。
迁移成分分析(transfer component analysis,TCA)[2]是基于特征的迁移学习方法,其将源域数据和目标域数据映射到隐藏空间中,寻找公共迁移成分进行学习,减小了不同领域数据分布的差异性,明显提高了跨领域、跨任务的学习能力。无监督迁移成分分析(unsupervised TCA, UTCA)[2]是进一步针对特征空间与类别空间相同、边缘分布不同而提出的迁移学习方法。在实际应用中,监测数据通常只有少量与目标域数据相匹配的标签数据,以及大量和源域不匹配的标签数据,而利用UTCA则在特征映射中不需要考虑样本标注信息,有效提高了特征迁移的效率,减少了人为标注的不确定性。迁移成分分析在设备故障诊断中的应用研究有不少。Xie等[3]提出基于TCA和跨域特征融合的变速齿轮箱故障诊断方法。段礼祥等[4]提出基于不同工况下辅助数据集的齿轮箱故障诊断方法,利用TCA减小训练样本与测试样本的差异性,提高了齿轮箱变工况故障诊断的准确性。沈飞等[5]将基于自相关矩阵奇异值分解的特征提取和迁移学习分类器相结合,进行电机故障诊断,提高了分类正确率。
然而,上述迁移学习方法虽然能够用于故障诊断,但无法提高浅层机器学习的诊断能力和泛化能力。深度学习方法可以学习数据中的隐含表征参数,并建立表征参数与类别之间的复杂映射关系。深度信念神经网络(deep belief network,DBN)[6]作为深度学习技术之一,已广泛应用于故障诊断中。Tamilselvan等[7]提出基于DBN模型的多传感器故障诊断方法,在飞机发动机和电力变压器的故障分析中取得较好效果。陶洁等[8]将Teager能量算子(TEO)和DBN相结合应用于滚动轴承故障诊断中,能准确识别不同轴承故障类型,具有较强的泛化能力。李巍华等[9]从滚动轴承时域振动原始信号出发,利用DBN进行不同状态下的故障识别,得到比传统方法更好的诊断效果。但是DBN方法所需训练样本较多,在实际故障样本较少的情况下,其诊断精度有待提高。
为此,本文将UTCA和DBN两种算法相结合,提出了一个新的故障诊断方法,以期在故障样本不足时实现滚动轴承故障的高精度诊断。
1 UTCA算法
UTCA充分利用领域之间特征样本的可迁移性,提高跨领域学习能力。假定源域DS={XS,YS},其中XS是源域样本集,YS是标签样本;目标域为DT={XT},其中XT是目标域样本集,目标域中标签未知。假设源域样本与目标域样本的边缘概率分布不同,即P(XS)≠Q(XT),通过特征映射函数Φ,使映射后的边缘概率分布尽可能相似,即P(Φ(XS))≈Q(Φ(XT))。
设Φ(XS)与Φ(XT)是经过Hilbert核空间映射后的源域特征样本集与目标域特征样本集,映射后源域和目标域之间的距离可以表示为:
dist(Φ(XS),Φ(XT))=
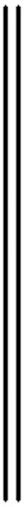
(1)
式中:‖·‖H为RKHS范数;N1为源域样本个数;N2为目标域样本个数;xSi∈XS,xTj∈XT。
由式(1)可知,非线性变换映射函数Φ有许多种,直接计算特征样本间的距离是相当困难的,通过维数约简的最大均值偏差嵌入法(maximum mean discrepancy embedding,MMDE)[10],将上述难求解的映射函数Φ转化为内核学习问题,可采用高斯径向基核函数进行映射,并引入核矩阵K,则映射后源域和目标域距离可表示为:
dist(Φ(XS),Φ(XT))=trace(KL)
(2)
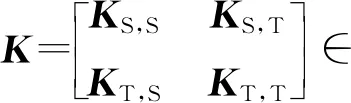
核矩阵K还可以表示为:
K=(KK-1/2)(K-1/2K)
(3)

(4)
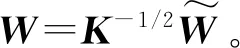
根据式(4),可以将式(2)替换为:
dist(Φ(XS),Φ(XT))=trace((KWWTK)L)
=trace(WTKLKW)
(5)
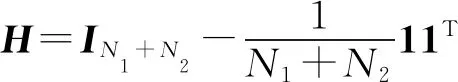
综上所述,为使不同领域分布间距离尽可能小,就要对式(5)进行最优化。添加正则化项μtrace(WTW)来控制矩阵W的复杂度,优化目标转化为:
s.t.WTKHKW=IM
(6)
式中:μ>0是正则化平衡参数;IM∈M×M是单位矩阵。
根据限制条件WTKHKW=IM, 式(6)又可化为如下的目标函数进行求解:
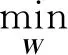
(7)
可由式(7)求解(KLK+μIM)-1KHK,即得到优化后的最佳映射核矩阵W。
2 DBN模型
DBN是由多个受限玻尔兹曼机(restricted Boltzmann machine,RBM)和一层BP神经网络堆叠而成的多层感知器神经网络,可以组合低层特征形成更加抽象的高层特征表示[11],具有逐层挖掘深层特征的能力,无需人工提取特征,避免了传统特征提取过程所带来的复杂性和不确定性,提高了故障识别性能。DBN 训练过程包括两个部分:预训练和微调。预训练主要采用无监督逐层训练的方式对每层RBM参数进行训练,低层RBM隐藏层输出作为高层RBM可见层输入,可从原始信号数据中提取较为抽象的特征参数;微调阶段利用BP神经网络的实际输出与标签信息差值作为度量误差,将误差逐层后向传播,实现对整个 DBN 权值和偏置的微调,经过多次迭代即可得到整个DBN的最优参数。
2.1 RBM网络
RBM[12]由可视层和隐藏层组成,如图1所示。v和h分别表示可视层和隐藏层,w表示两层之间的权值,a和b分别为可视层和隐藏层偏置,层间神经元全连接,层内神经元不连接。
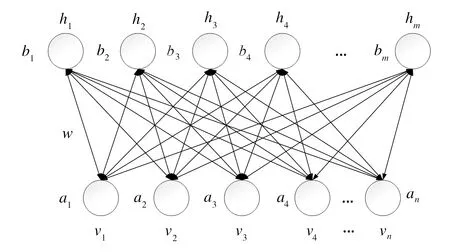
图1 RBM的结构
假设一个RBM中有n个可视神经元和m个隐藏神经元,其中vi和hj分别表示第i个可视层神经元和第j个隐藏层神经元的状态,v=(v1,v2,…,vn),h=(h1,h2,…,hm),RBM的能量函数可描述为:
(8)
式中:参数wij、ai、bj分别为可视节点到隐层节点的连接权重、可视节点偏置、隐层节点偏置。wij、ai和bj构成参数集θ,根据能量函数式(8)可知,v和h之间的联合概率分布如下:
(9)
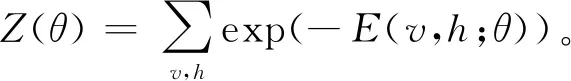
隐藏层与可视层的条件概率为:
(10)
(11)
根据式(10)和式(11)可进一步推导得到激活函数,给定隐藏层h,可视层v的激活函数为:
(12)
给定可视层v,隐藏层h的激活函数为:
(13)
通过随机初始化和迭代训练得到参数集θ,利用极大对数似然函数求解参数集θ*:
(14)
为了增加极大对数似然函数的计算梯度,采用对比散度算法[13]对参数集θ*进行更新:
(15)
式中:ζ为学习率;〈·〉data为训练数据特征样本数学期望;〈·〉rec_er为重构后的模型参数数学期望。
2.2 BP网络微调
BP网络前向传播,将输入特征向量逐层传到输出层,得到预测的分类结果,将预测结果与实际标签信息对比得到误差值,然后将误差逐层后向传播,实现DBN特征参数微调。
对输出层,假设第i个节点的实际输出为τi,期望输出为ei,则灵敏度的计算公式如下:
δi=τi(ei-τi)(1-τi)
(16)
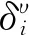
(17)
(18)
3 基于UTCA和DBN的轴承故障诊断流程
本文方法主要由UTCA算法和DBN模型两个部分组成。首先,获取滚动轴承振动信号,将已知工况的滚动轴承振动信号作为源域,未知振动信号作为目标域,利用UTCA对源域样本和目标域样本的差异性进行处理,使源域样本和目标域样本更加相似,通过最大均值偏差统计值判断能够迁移的源域数据,为深度学习提供充足的训练样本,解决实际故障样本较少的问题;然后,利用DBN模型对源域样本进行训练,形成融合UTCA和DBN的故障诊断模型,使源域故障诊断知识能够用于识别目标域未知的故障类型。滚动轴承故障诊断流程如图2所示。
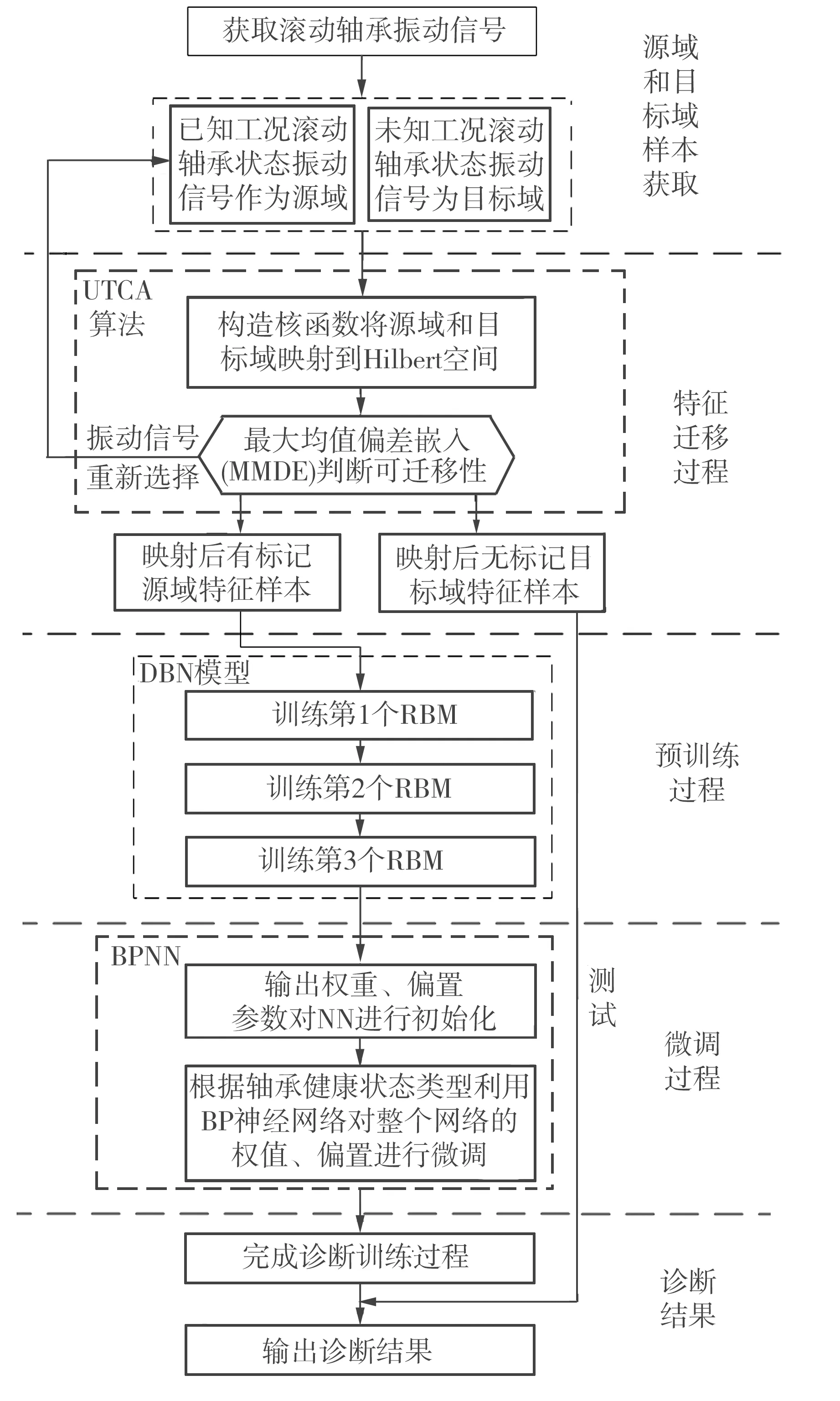
图2 基于UTCA和DBN的滚动轴承故障诊断流程
Fig.2 Flow chart of rolling bearing fault diagnosis based on UTCA and DBN
4 应用实例分析
4.1 试验数据
如图3所示,试验台由驱动电机装置、联轴器、齿轮箱、制动系统和加速度传感器构成。
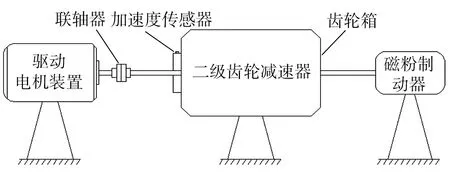
图3 试验台示意图
驱动电机为三相异步电动机,额定功率为2200 W,极对数为2;磁粉制动器是制动系统的主要部件;减速器输入轴齿数Z1=29,中间轴齿数为Z2=100、Z3=36,输出轴齿数Z4=90;试验轴承安装在二级减速器中间轴上,模拟正常工作、内圈故障、外圈故障和内外圈复合故障等几种类型。为了直观起见,加速度传感器安装在齿轮箱的左侧挡板上,实测的是径向的轴承振动信号数据,采样频率为8096 Hz,负载状态为有、无两种。
设定3种工况:①工况A,电机输出转速为1500 r/min;②工况 B,电机输出转速为900 r/min;③工况 C,电机输出转速为600 r/min。
针对单个工况故障诊断的实际可用轴承数据样本较少,可以将其他工况数据迁移过来,为诊断目标数据提供大量的可训练样本。从3种试验工况中选取稳定状态下的振动数据,每种工况和健康状态下的样本均为80个,每个样本包含600个数据点,数据样本组成见表1。根据本文所涉及的滚动轴承故障数据迁移诊断问题,创建3个迁移诊断任务,对所提出的方法进行验证分析,分别为:①A(源域)→C(目标域),即将工况A的样本迁移到工况C,进行DBN模型训练,并用于对工况C的样本进行诊断测试;②B(源域)→C(目标域);③B(源域)→A(目标域)。
表1 不同工况下的样本数据集组成
Table 1 Composition of sample datasets in different working conditions
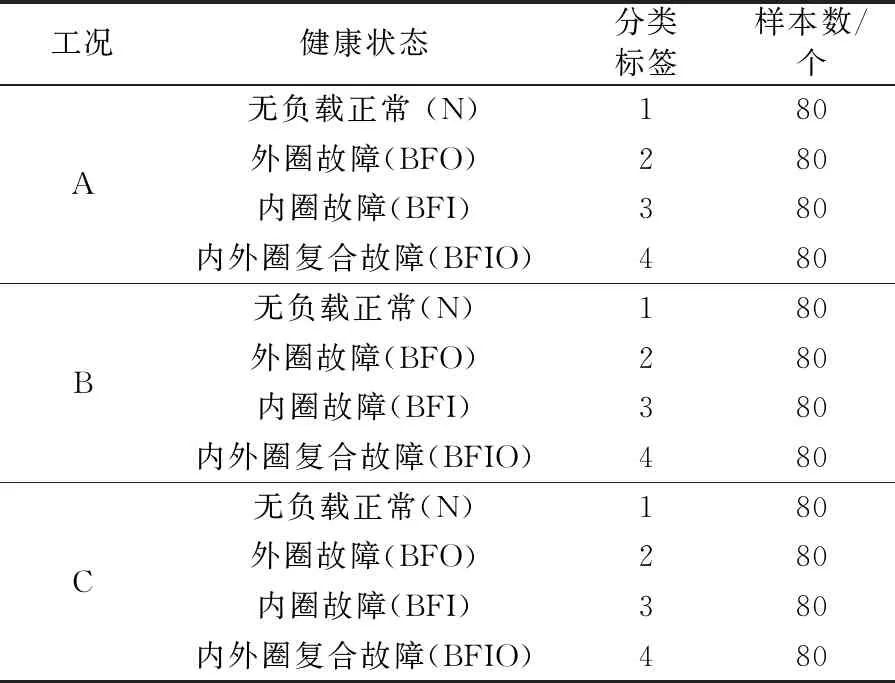
工况健康状态分类标签样本数/个A无负载正常(N)180外圈故障(BFO)280内圈故障(BFI)380内外圈复合故障(BFIO)480B无负载正常(N)180外圈故障(BFO)280内圈故障(BFI)380内外圈复合故障(BFIO)480C无负载正常(N)180外圈故障(BFO)280内圈故障(BFI)380内外圈复合故障(BFIO)480
4.2 故障诊断结果与分析
首先根据不同工况数据集的迁移诊断任务进行故障诊断分析。UTCA算法参数初始设置:核宽度为[10-3,10-2,10-1,1,10,102]的高斯径向基核函数,正则化参数μ为[10-3,10-2,10-1,1,10,102,103]。选择使UTCA模型的目标函数取得最小值时的核宽度和μ为最优参数组合,并以UTCA模型输出数据集作为DBN源域样本集(训练数据集)和目标域样本集(测试样本集)的输入。DBN 结构参数的选取:采用经典的4层结构,两个隐层节点数分别为100、100,学习率ζ=10-4,正则化参数λ=10-4。为减小随机初始化的训练参数对本文方法诊断结果的影响,重复验证 20次,不同迁移条件下的故障识别准确率如表2所示,表中还列出了没有进行数据迁移而直接根据源域样本数据,分别采用支持向量机(SVM)、BP神经网络(BPNN)和普通DBN方法对目标域样本进行故障识别的准确率。
表2 不同迁移条件下滚动轴承故障诊断精度(单位:%)
Table 2 Rolling bearing fault diagnosis accuracy in different transfer conditions

诊断方法源域→目标域A→CB→CB→A平均SVM59.7856.0052.8356.20BPNN57.6953.2455.8455.59DBN71.5074.5870.6772.25本文方法95.8390.0092.2592.69
由表2可知,以不同工况数据作为源域或者目标域时,在3种试验设定中,本文方法的平均故障识别率最高(92.69%),主要原因在于:UTCA在处理源域数据和目标域数据之间的差异性时具备优势,不需要考虑样本是否有标签的问题,降低了人为因素的干扰,通过无监督自主迁移学习,将源域样本迁移到目标域中,解决了因目标域故障样本少导致的识别率低这一问题。至于其他3种分类方法,没有故障样本迁移过程,只能通过不同工况数据进行训练和测试,由于机器学习的诊断能力和泛化性能有明显的不足,而深度学习需要大量训练样本,因此导致诊断精度不高,平均识别率分别只有56.20%、55.59%和72.25% 。
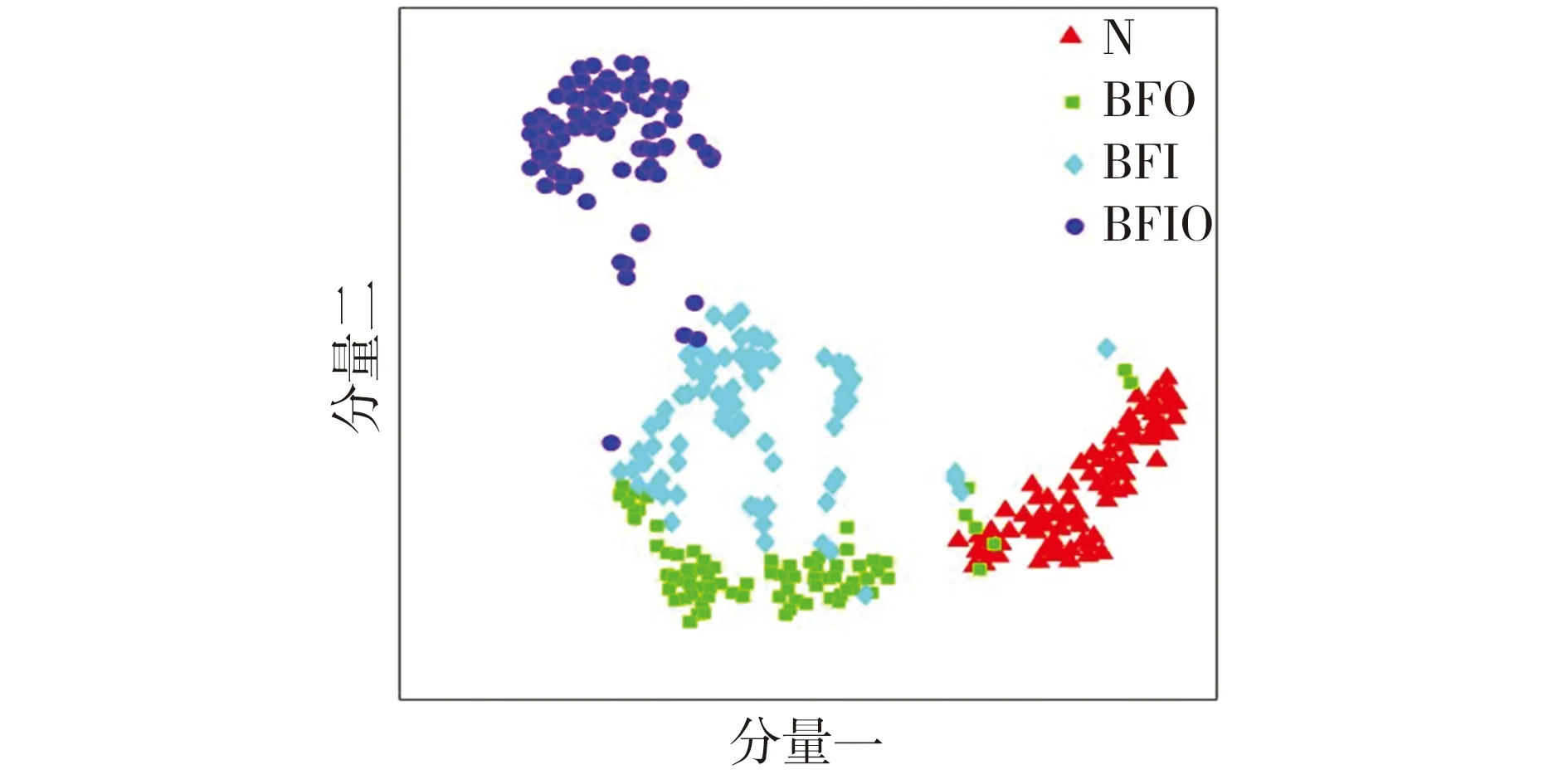
为了使本文方法的有效性更为直观,利用t-分布随机邻域嵌入(t-distribution stochastic neighbor embedding,t-SNE)算法将故障特征进行可视化。以工况A原始数据集为例,将原始样本映射到二维空间来可视化高维数据,得到如图4所示的特征散点图。从图4中可以看出,各种故障类型数据具有明显的不确定性,各种振动信号特征交叉重叠在一起,相互交错,很难区分轴承故障类别。

图4 工况A原始数据集的特征散点分布
Fig.4 Feature scatter distribution of original data set of working condition A
为了进一步对比分析本文方法和普通DBN诊断方法的差异性,通过t-SNE将提取的故障特征降维至二维平面,以散点图形式呈现,如图5和图6所示。
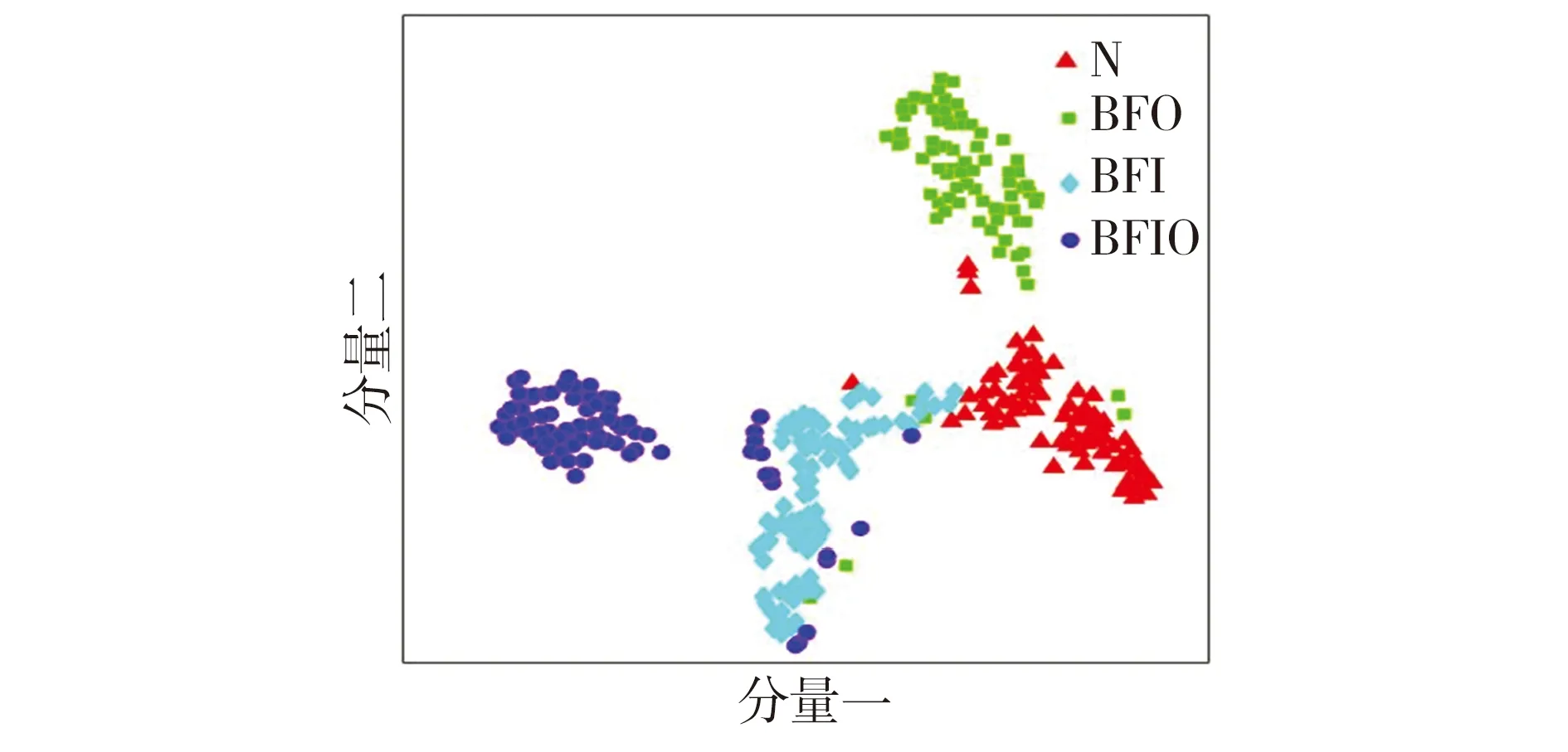
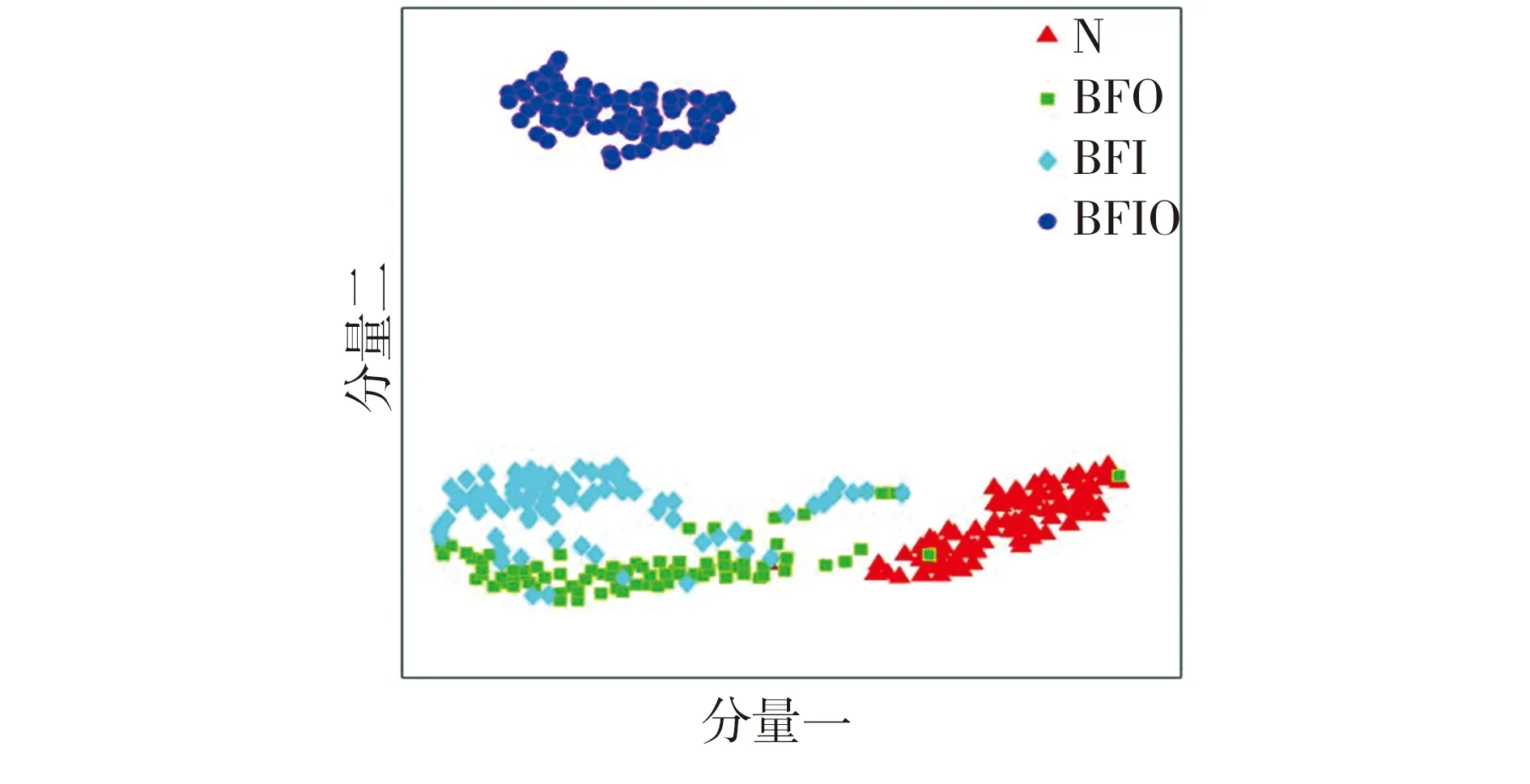
由图5可见:当分别以工况A、B数据集为DBN训练样本时,仅能提取数据集A、B中的深层故障特征,并没有缩小训练集(源域)与测试集(目标域)之间的差异性,直接用于C、A数据中进行故障诊断时,由于所提取的A、B工况下轴承故障特征与C、A工况下的轴承故障特征间存在较大分布差异,导致轴承故障诊断知识即训练得到的诊断模型无法识别其他工况下的轴承故障样本,因此分类效果不好。
(a)诊断任务A→C
(b)诊断任务B→C
(c)诊断任务B→A
Fig.5 Fault feature scatter distribution by ordinary DBN method
(a)诊断任务A→C
(b)诊断任务B→C

(c)诊断任务B→A
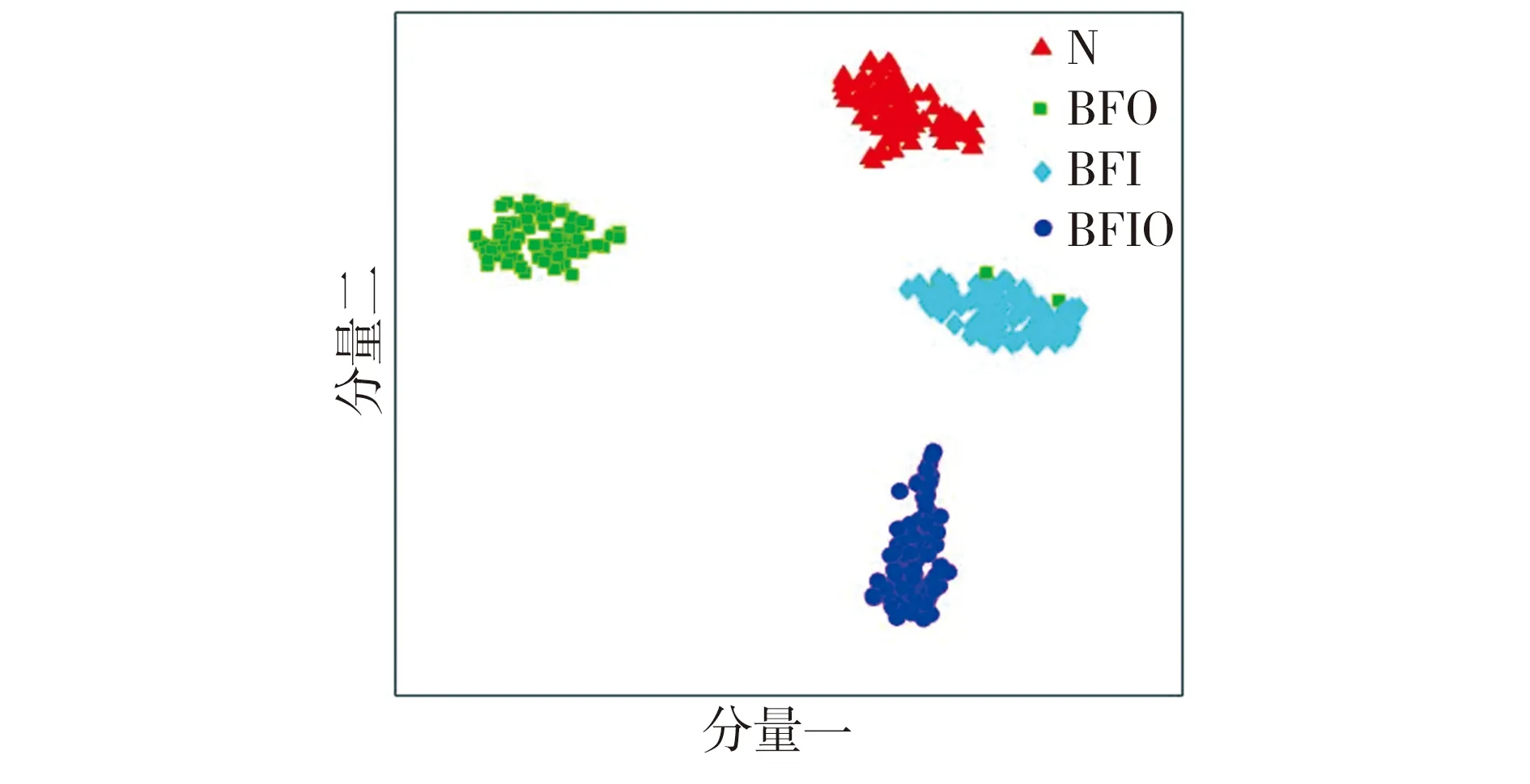
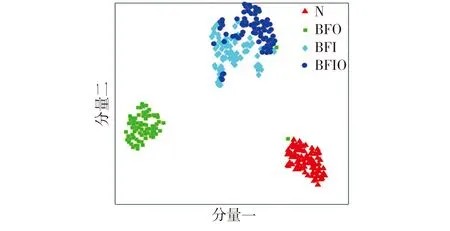
Fig.6 Fault feature scatter distribution by the proposed method
由图 6可见:本文方法在缩小训练集(源域)与测试集(目标域)迁移故障特征间分布差异的同时,增加了不同工况的轴承故障特征的类间距离,放大了不同工况数据中隐含的相似故障信息,使得源域和目标域有更好的相似性,抑制了差异性信息对轴承数据的影响,使得通过训练得到的迁移诊断模型对C、A工况的轴承数据样本的辨识度较高,故障特征分类精度得到提升。对比图5与图6可知,本文方法能够更好地将同一种健康状况样本聚集在一起,而将不同健康状况样本有效地分离。
为了更进一步说明本文方法的优越性,以下将本文方法与融合了传统机器学习(包括随机森林RF,支持向量机SVM,k近邻算法k-NN)和UTCA的方法进行对比分析,得到轴承故障诊断结果如图7所示。
从图7中可以看出,本文方法比其他3种方法有更高的诊断精度,而且在不同迁移任务条件下进行诊断时的结果总体差异性不大。以迁移诊断任务A→C为例:本文方法的识别精度为95.83%,标准差为2.40%;UTCA-SVM方法的识别精度为85.94%,标准差为3.96%;UTCA-RF的识别精度为70.67%,标准差为3.42%;UTCA-k-NN的识别精度为84.54%,标准差为1.36%。这体现了本文方法在故障诊断中的普适性以及深度学习的优势。
综上所述,本文提出的基于UTCA算法和DBN模型的滚动轴承故障诊断方法的识别精度更高,这是因为:①该方法能够直接利用UTCA算法缩小两域之间的差异性,源域数据和目标域数据更加相似,使得源域样本能迁移到目标域样本中,并且在无监督的迁移学习过程中减少了对样本标签进行人为标记的不确定性,降低了诊断误差率;②通过深度学习的强大特征提取能力对UTCA处理后的域数据进行高精度故障诊断,为因实际故障样本少而导致的诊断精度低问题提供了一种解决方案,克服了UTCA和传统机器学习融合方法的诊断能力和泛化能力不强的缺点。
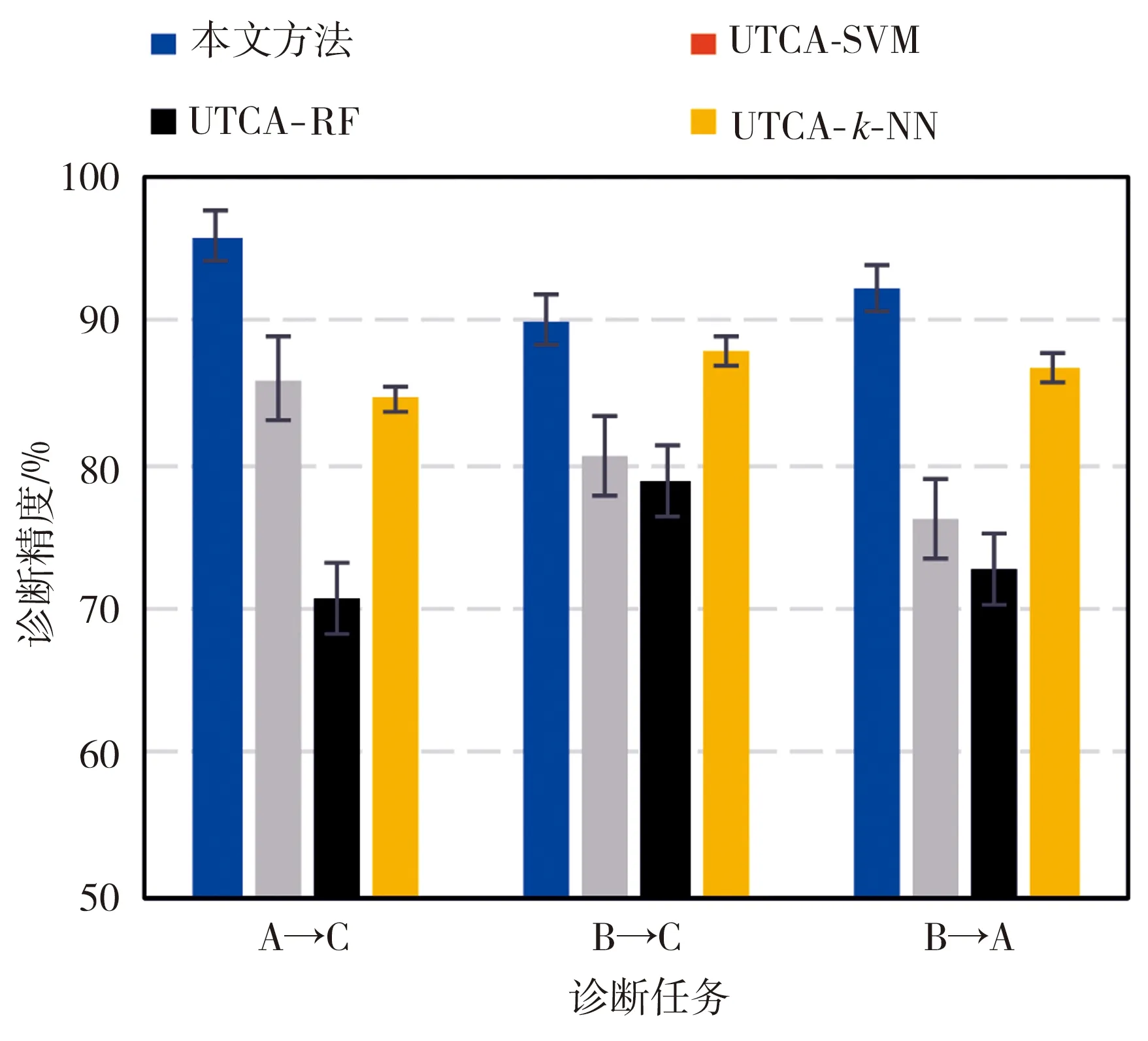
图7 采用不同方法的轴承故障诊断精度对比
Fig.7 Comparison of bearing fault diagnosis accuracy by different methods
5 结语
本文将无监督迁移成分分析和深度信念网络模型相结合,成功应用于滚动轴承故障诊断中。UTCA算法完成了不同工况(领域)间轴承数据的迁移学习,将不同工况振动信号映射到一个新的数据空间中,寻找公共迁移成分进行学习,增加源域数据集与目标域数据集之间的相似程度,克服了源域(训练样本)和目标域(测试样本)必须满足独立同分布要求这一局限,为数据迁移提供了可能性,并且不需要考虑数据标签标注对迁移数据的影响,解决了因目标域中实际故障样本少而导致的诊断精度低这个问题。运用DBN模型对迁移的数据进行识别,充分发挥 DBN自主特征提取能力,取得了比其他对比算法更高的诊断精度。
