基于维基百科链接特征的词语语义相似度计算
2019-11-16张波
张波


摘 要:针对目前基于维基百科的相似度计算方法预处理过程烦琐、计算量大的问题,本文以维基百科为本体引入基于特征的词语语义计算,提出了一种基于维基百科的快速词语相似度计算方法。根据维基百科页面链接结构的特点,该方法把页面的入链接和出链接作为页面特征值构建特征向量模型,通过计算页面的特征向量相关系数计算对应词语的语义相似度。本文还改进了维基百科消歧处理算法,在一词多义的处理中减少社会认知度低的义项页面的干扰,进一步提高了计算准确度。经Miller & Charles(MC30)和Rubenstein & Goodenough(RG65)测试集的测试,测试结果表明了基于维基百科链接特征的方法在计算相似度方面的可行性,也验证了本文的计算策略和消歧改进算法的合理性。
关键词:语义相似度;维基百科;基于链接;基于特征值
中图分类号:TP391 文献标识码:A
Abstract:Measuring semantic similarity is a critical basic research in natural language processing.Because Wikipedia has open-editing,huge vocabulary,rapid update and other features,more and more research and applications have been focused on Wikipedia.This paper proposes a page-link approach for calculating word semantic similarity by taking Wikipedia as data resource.This approach improves the Wikipedia Link Vector Model (WLVM) method taking outgoing links as the feature vector,and utilizes page's incoming links and outgoing links as feature values in Wikipedia,then calculates the semantic similarity between words by measuring feature set similarity between the corresponding pages.The method also improves the disambiguation page processing by reducing the interference of the low social recognition pages.Through testing with Miller & Charles (MC30) and Rubenstein & Goodenough (RG65) benchmark,the validity of this method on the measuring word semantic similarity measurement is verified.
Keywords:word similarity;Wikipedia;link-based;feature-based
1 引言(Introduction)
詞语之间的语义相似度(SS)测量是自然语言处理领域重要的基础研究之一,在很多领域都有着广泛的应用,比如词义消歧[1]、同义词探测[2]、信息抽取[3]等。传统的词语相似度计算方法主要包括两类:其一是基于语料库的概率统计方法,它的计算策略是使用统计学的方法把词语相似度问题转换为词语在语料库中上下文信息概率分布问题,把词语在语料库中的统计学特征作为语义相似度计算依据;其二是基于某个世界知识本体模型的计算方法,把词语在本体概念模型中特征的共性和差异性作为计算依据[4]。目前英文词语相似度研究所使用的基本参考本体模型主要是WordNet[5],而中文词语相似度研究主要使用的模型有董振东的“知网”[6]与哈工大的“同义词词林”[7]。由于WordNet具有严谨的词义分类结构和语义关系,基于WordNet的英文词语语义相似度计算已经得到了较为广泛地应用[8-19]。然而,WordNet词汇量覆盖面窄,且版本更新周期长,这些缺点也限制了它的进一步应用范围。进入21世纪后,随着维基百科这一全球性多语言百科全书的推广使用,开始出现了基于维基百科的词语相似度与相关度的研究。维基百科是一种带类目结构的网页文本语料库,具有与WordNet相似的分类结构,其包罗万象的网页内容和复杂的页面链接蕴含着丰富的词语语义信息。同时,由于维基百科的内容和结构由世界各地的志愿者合作创建和编辑,其词汇量和更新速度均远超其他语义知识源。因此,根据维基百科的数据特点,探索基于维基百科的语义相似度和相关度计算方法问题,吸引了越来越多研究者的关注。
2 研究背景(Research background)
维基百科是一个允许用户编辑的开放网络百科全书,自2001年推出后得到了迅猛增长,截止到2017年10月2日,共涵盖299种语言,具有46483635个页面[20],其中包括5486459个英文页面。维基百科每月发布两次数据库备份转储(Database backup dumps),为基于维基百科数据资源的研究和应用提供便利[21]。
维基百科的基本信息单元是页面(Page),其中页面分为内容页面(Content Page)、消歧页面(Disambiguation Page)、类目页面(Category Page)。每一个页面的底部都列出该页面所从属的类目(Category)。内容页面通过文本定义概念词条,并显示与该概念词条相关的信息内容,文本中以超链接的形式包括了用于定义该词条的其他页面,比如“United States” 页面定义了“美国”这一概念,并呈现关于“美国”的相关信息内容,其中包括了1632个超链接;消歧页面用于解决一词多义的问题,它以列表的方式呈现该词条的所有义项页面超链接,比如“Apple(disambiguation)”页面呈现了词语“Apple”的59个义项页面;类目页面用于以列表的形式呈现该类别的主页面、子类别、从属页面等信息,比如“Category:Fruit”页面呈现了该类别的一个主页面、四个直接子类别和12个从属页面的信息。
目前,基于维基百科的词语语义相似度计算方法主要包括基于维基百科类目图(Wikipedia Category Graph,WCG)的方法、基于文本语义分析的方法和基于页面链接的方法。
(1)基于WCG的方法以维基百科的类目结构作为语义计算的本体模型基础,把基于语义词典语义相似度计算方法扩展到基于维基百科的相似度计算。该方法可以追溯到Strube等人在2006年提出WikiRelate方法。WikiRelate方法是最早把维基百科作为知识来源的词语相似度计算方法,该方法借鉴了基于语义词典的路径计算方法,在维基百科类目结构的基础上建构维基百科类目树(Category Tree),根据概念在类目树上的距离和深度计算词语语义相似度[22]。2012年,Taieb等人把基于IC的方法引入维基百科相似度计算中,他们根据WCG的结构特点改进了IC计算方法,并通过限制图的搜索深度提高计算精度[23]。2013年,Taieb等人继续把基于特征值的计算方法擴展到维基百科相似度计算中,他们通过页面词语的词根统计为WCG中的每一个类目构建语义描述特征向量,在此基础上尝试了多种特征向量计算方法,并在计算过程中通过增加页面重定向、页面文本特征等因素改善计算结果[24]。2016年,Aouicha等人改进了基于WCG的IC计算方法,提出了WordNet和维基百科结合的计算方法[25]。由于维基百科由众多用户共建而成,使其类目结构并不严谨,作用主要是词语推荐和网站导航。因此,基于WCG的方法均需要进行复杂的类目数据预处理,计算准确率并不理想。
(2)基于文本语义分析的相似度方法是以维基百科页面文本为计算依据,通过对页面文本进行语义分析和词语统计建立维基百科概念的向量空间模型,根据向量模型的相似度计算维基百科概念的相似度。由Gabrilovich和Markovitch提出的ESA(Explicit Semantic Analysis)方法最具代表性[26]。ESA方法利用维基百科词语覆盖面大、概念语义描述丰富的特点,在使用机器学习技术对页面文本中的词语和词组进行文本解析的基础上,把维基百科概念表示为概念解释向量(interpretation vector)。解释向量由页面文本中包含的文本片段组成,文本片段对于概念的重要程度体现为文本片段在向量中的权重。文本片段的权重计算采用了TF-IDF算法,该算法是信息检索领域与数据挖掘领域的常用加权技术,一个文本片段在某一个页面中的权重等于该文本片段在页面中的统计频率与该页面片段在整个维基百科中逆向页面频率之积。ESA方法不仅可以用于计算词语语义计算,也可以计算任意长度的语义计算,但是该方法需要事先构建解释向量空间,计算量大。
(3)基于页面链接的相似度方法是把维基百科的页面超文本链接结构作为相似度计算数据模型。在维基百科中,页面通过超文本链接相互关联。一个页面的超链接结构既包括在页面文本中链接到其他页面的出链接(Outgoing Link),也包括从其他页面链接到该页面的入链接(Incoming Link)。Milne和Witten是首先使用维基百科页面链接计算文本相似度的学者,他们在2008年尝试了根据出链接向量余弦夹角计算方法和入链接集合Google距离计算方法,并提出了把两种计算求平均值的方式计算词语相似度的方法[27]。在2009年,Milne在前一种方法的基础上提出了WLVM(Wikipedia Link Vector Model)方法[28]。在WLVM方法中,维基百科页面表示为页面文本中包含的超链接(即出链接)组成的向量,根据向量的余弦夹角计算维基百科概念的相似度。WLVM方法对链接的权重计算提出了改进,以超链接在文本中出现的次数代替TF-IDF算法中的词语统计频率。
本文提出了一种基于链接特征的词语相似度计算方法,该方法以维基百科概念页面之间的链接作为特征,通过计算两个维基百科页面的链接特征集合的相似度得出页面之间的相似度,进而实现页面对应的词语之间的相似度计算。另外,本文还对维基百科一词多义的处理过程进行了改进,通过对一些社会认知度低的义项页面进行裁剪,进一步提高了计算结果的准确度。
3 计算方法(Computing method)
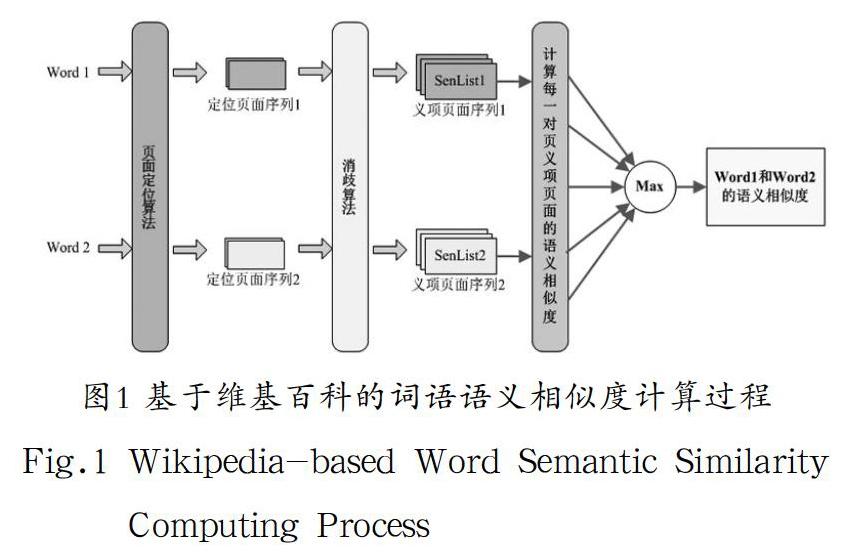
基于维基百科的词语语义相似度的计算过程主要包括三个步骤。首先在维基百科数据资源中获取词条的定位页面。若定位页面属于内容页面,说明词条义项单一,定位页面即是义项页面;若定位页面属于消歧页面,说明词条是一词多义,需要把页面消歧处理为多个非消歧义项页面,每一个义项页面描述词条的一个义项。最后通过计算义项页面之间的相似度来计算词语之间的相似度,计算基本过程如图1所示。
3.1 页面定位和消歧
计算两个词语相似度的第一步是找到词语在维基百科数据资源中的定位页面,把词语相似度计算转换为页面相似度度量。本文采用查询维基百科词条来实现词语与页面的映射,具体分为三种情况。其一,在维基百科中存在标题与词语完全一致的页面,比如词语“glass”可以定位到标题为“Glass”的页面;其二,在维基百科中词语重定位到的页面,这种情况表示词语与页面的标题属于同义词,比如词语“automobile”重定向为标题为“Car”页面;其三,在维基百科中存在标题为“词语+(disambiguation)”的页面,比如词语“tool”可以定位到标题为“Tool(disambiguation)”的页面。
本文的页面定位采用JWPL(Java Wikipedia Library)工具,对于任意词语w,通过检索数据资源找到w对应的一到多个页面,并最终选取计算定位页面列表。具体的定位过程包括以下步骤:
(1)若w只能检索到一个页面,则直接确定该页面为w的唯一定位页面。
為了确保阈值参数θ取值的客观性,我们选择了AG203相似度基准测试集作为训练集来训练计算参数。AG203[29]是Agirre等在2009年创建,由203对词组成,词语的词性包括名词、动词和形容词,人工判定值在0—10。在训练集AG203上使用式(4)、式(5)、式(6)和式(7),通过不断改变阈值参数θ的取值,计算相似度值与人工判定值的Pearson相关系数值,当Pearson相关系数达到峰值时阈值参数θ的取值确定为最终参数值。在训练集AG203上,本文方法计算相似度与人工判定值的Pearson系数随阈值参数θ取值变化情况如图4所示。
如图4所示,设置阈值参数的测试结果整体优于不设阈值的结果,且阈值θ=0.7时,训练数据集计算结果与人工判定值的Pearson相关系数达到最优状态,在本文中,阈值参数最终确定为0.7。在下文章节所采用的测试数据集在计算过程中,阈值θ=0.7为计算的最优状态这个现象依然表现明显。
4 实验与分析(Experiments and analysis)
使用基准测试数据集对算法进行测试和对比是目前最主要的相似度计算方法的评测方式,本文选取两种国际通行计算词语相似度基准测试集:Miller & Charles(MC30)和Rubenstein & Goodenough(RG65)。其中,MC30数据集是由Miller和Charles在1991年发布的,包括30对名词,人工判定值的取值在0—4[30]。RG65是Rubenstein和Goodenough在1965年创建,由65对名词测试数据组成,人工判定值在0—4[31]。为了便于计算结果对比,本文对测试集进行了归一化处理,即MC30和RG65的人工判定值除以4,使其值域统一为[0,1]。
首先,我们对本文改进的语义相似度方法进行测试,消岐算法采用传统的取消歧页面所有的义项页面的方法,相关公式包括式(1)、式(4)和式(5)。测试采用的维基百科数据资源是2017-8-1版维基百科数据库备份转储。在两个测试集上的计算结果与人工判定值之间的Pearson相关系数如表1所示。
接下来,我们在上述页面相似度算法的基础上,采用本文改进的消岐算法处理一词多义,使用两个测试数据集对算法重新测试,相关公式包括式(4)、式(5)、式(6)和式(7),阈值参数θ设为0.7,计算结果如表2所示。
MC30测试集测试结果与人工判定值数值对比如表3所示。
为了比较本文相似度算法与现有相似度算法的优劣,本文使用2017-8-1版维基百科数据库对前文学者提出的出链接余弦夹角计算方法、Google距离计算方法和WLVM进行重新计算,并与文献中主要的词语语义相似度算法测试结果进行对比,如表4所示。
根据表4数据分析,由于维基百科数据资源页面规模和义项数的增加,使用新版本维基百科数据资源对原有的基于链接的维基百科相似度方法的重算结果均差于原文献的计算结果,本文提出的页面链接为特征值的维基百科相似度方法总体上优于前文学者提出的出链接余弦夹角计算方法、Google距离计算方法和WLVM等方法。对比这些方法的计算过程中使用本文改进的消歧算法,可以看出本文的消歧方法在这些方法中依然起到改善计算结果的作用。本文方法在总体上优于文献中其他基于维基百科的相似度计算结果,也优于目前大部分基于WordNet的语义相似度计算方法。虽然本算法的RG65测试结果略低于目前基于WordNet方法的最高值[11,18],但相较于WordNet(3.1版本)[5]中数据集中只有155287个词、117659个同义词集和206941个义项,维基百科具有超过其30倍的词汇量,且在快速更新,因此本文方法具有更为广泛的应用前景。
5 结论(Conclusion)
本文使用维基百科链接作为数据资源计算词语语义相似度,提出了一种基于维基百科页面链接特征的计算词语语义相似度方法。首先,通过页面定位和消歧,把词语定位到维基百科页面,把词语相似度问题转换为页面相似度的计算问题。然后把页面表示为由入链接和出链接组成的特征集合,通过计算特征集合的相似度计算对应词语的相似度。本文提出了对一词多义问题的消歧算法的改进,通过阈值参数限制消歧义项页面的方式减少社会认知度较低义项对测试过程的干扰,以达到提高计算准确度目的。
本文使用2017-8-1版维基百科数据资源,通过基准测试数据集对本文方法今次测试。MC30数据集的计算结果与人工值之间的Pearson相关度达到0.906513536,RG65达到0.82858353。经实验数据与其他方法的对比,本文提出的方法总体优于现有的基于维基百科链接的词语相似度计算方法,且与其他维基百科方法和基于WordNet方法对比也有较好的表现,说明本文提出的基于维基百科链接的词语语义相似度计算方法是合理有效的。
参考文献(References)
[1] Patwardhan S,Banerjee S,Pedersen T.Using measures of semantic relatedness for word sense disambiguation[C].International Conference on Computational Linguistics & Intelligent Text Processing.Springer-Verlag,2003:241-257.
[2] Lin D.An Information-theoretic Definition of similarity[C].The Fifteenth International Conference on Machine Learning.Morgan Kaufmann Publishers Inc.,1998:296-304.
[3] Atkinson J,Ferreira A,Aravena E.Discovering Implicit Intention-Level Knowledge from Natural-Language Texts[J].Knowledge-Based Systems,2009,22(7):502-508.
[4] 石靜,吴云芳,邱立坤.基于大规模语料库的汉语词义相似度计算方法[J].中文信息学报,2013,27(01):1-6.
[5] Princeton University.WordNet[EB/OL].http://wordnet.princeton.edu,2019-8-1.
[6] 董振东,董强.知网[EB/OL].http://www.keenage.com,2015-1-8.
[7] 哈工大社会计算与信息检索研究中心.同义词词林扩展版[EB/OL].http://ir.hit.edu.cn/demos,2019-7-20.
[8] Rada R,Mili H,Bicknell E,et al.Development and application of a metric on semantic nets[J].IEEE Transactions on Systems,Man and Cybernetics,1989,19(1):17-30.
[9] Wu Z,Palmer M.Verbs Semantics and Lexical Selection[C].Proceedings of the 32nd annual meeting on Association for Computational Linguistics(COLING-94).Association for Computational Linguistics,1994:133-138.
[10] Leacock C,ChodorowM.Combining Local Context and WordNet Similarity for Word Sense Identification[M].WordNet:An Electronic Lexical Database,1998:265-283.
[11] Hao D,Zuo W,Peng T,et al.An Approach for Calculating Semantic Similarity between Words Using WordNet[C].Second International Conference on Digital Manufacturing & Automation.IEEE,2011:177-180.
[12] Resnik P.Using Information Content to Evaluate Semantic Similarity in a Taxonomy[C].the 14th International Joint Conference on Artificial Intelligence,Morgan Kaufmann Publishers Inc.,1995:448-453.
[13] D Lin.An Information-Theoretic Definition of Similarity[J].Fifteenth International Conference on Machine Learning,1998,1(2):296-304.
[14] JJ Jiang,DWConrath.Semantic Similarity Based on Corpus Statistics and Lexical Taxonomy[J].International Conference Research on Computational Linguistics,1997:19-33.
[15] A Tversky.Features of similarity[J].Readings in Cognitive Science,1988,84(4):290-302.
[16] MA Rodríguez,MJ Egenhofer.Determining Semantic Similarity among Entity Classes from Different Ontologies[J].Knowledge & Data Engineering IEEE Transactions on,2003,15(2):442-456.
[17] EGM Petrakis,G Varelas,A Hliaoutakis,et al.X-similarity:computing semantic similarity between concepts from different ontologies[J].Journal of Digital Information Management,2006,4(4):233-237.
[18] Hadj Taieb M A,Ben Aouicha M,Ben Hamadou A.Ontology-based approach for measuring semantic similarity[J].Engineering Applications of Artificial Intelligence,2014,36:238-261.
[19] Zhu X,Li F,Chen H,et al.A density compensation-based path computing model for measuring semantic similarity[J].Computer Science,2015:17-25.
[20] Wikipedia.List of Wikipedias[EB/OL].https://meta.wikimedia.org/wiki/List_of_Wikipedias,2019-8-1.
[21] Wikipedia.Wikimedia Downloads[EB/OL].http://dumps.wikimedia.your.org,2018-8-2.
[22] M.WikiRelate!Computing Semantic Relatedness Using Wikipedia[J].National Conference on Artificial Intelligence,2006,2(6):1419-1424.
[23] MAH Taieb,MB Aouicha,M Tmar,AB Hamadou.Wikipedia Category Graph and NewIntrinsic Information Content Metric for Word Semantic Relatedness Measuring[C].International Conference on Data and Knowledge Engineering,Springer Berlin Heidelberg,2012:128-140.
[24] MAH Taieb,MB Aouicha,AB Hamadou.Computing semantic relatedness using Wikipedia features[J].Knowledge-Based Systems,2013,50(50):260-278.
[25] MB Aouicha,MAH Taieb,AB Hamadou.Taxonomy-based information content and wordnet-wiktionary-wikipedia glosses for semantic relatedness[J].Applied Intelligence,2016,45(2):1-37.
[26] E Gabrilovich,S Markovitch.Computing Semantic Relatedness using Wikipedia-based Explicit Semantic Analysis[C].International Joint Conference on Artifical Intelligence,2007:1606-1611.
[27] D Milne,IH Witten.An Effective,Low-cost Measure of Semantic Relatedness Obtained from Wikipedia Links[J].Proceedings of AAAI,2008:35-42.
[28] D Milne.Computing Semantic Relatedness using Wikipedia Link Structure[C].NewZealand Computer Science Research Student Conference,2009.
[29] E Agirre,E Alfonseca,K Hall,et al.A Study on Similarity and Relatedness Using Distributional and Word Net-based Approaches[C].The Conference of the North American Chapter of the Association for Computational Linguistics,2009:19-27.
[30] George A.Miller,Walter G.Charles.Contextual Correlates of Semantic Similarity[J].Language Cognition & Neuroscience,1991,6(1):1-28.
[31] H Rubenstein,JB Goodenough.Contextual Correlates of Synonymy[J].Communications of the ACM,1965,8(10):627-633.
作者簡介:
张 波(1983-),男,硕士,讲师.研究领域:自然语言处理,远程教育技术.
