机器翻译发展与现状
2019-11-13黎亚飞张瑞华
黎亚飞 张瑞华
(天津科技大学外国语学院,天津 300222)
一、引言
“机器翻译(Machine Translation)是利用计算机把一种自然源语转换成另一种自然目标语言的过程。机器翻译研究如何利用计算机实现自然语言之间的自动翻译,是人工智能和自然语言处理领域的重要研究方向之一”(刘洋,2017)。机器翻译作为一门涵盖计算机科学、信息学、语言学、统计学等学科的边缘学科,具有多学科的研究视角和跨学科的研究价值。计算机科学与信息工程的巨大进步、现当代语言学和与语料库语言学的蓬勃发展、概率统计学的引入对机器翻译的理论研究和方法探索都产生了深刻的影响和巨大的推动作用。人工智能时代到来,机器翻译的前景一片光明。最初,机器翻译仅用于军事和政府文件翻译,而如今机器翻译被广泛应用于广大网民群众的日常生活,成为大量普通网民日常必备的工具。当前,Google 公司推出的循环神经网络系统已经支持60 多种语言的通用翻译,微软必应、搜狗、腾讯、百度、网易有道等多家互联网公司纷纷推出了自己的互联网免费机器翻译系统(刘群,2012)。机器翻译质量已经得到大幅提升,令语言学和计算机领域的不少学者开始担忧人工智能的发展会抢走不少从事翻译工作者的饭碗。
机器翻译是人工智能不可或缺的一部分,也是计算机语言学下的重要分支(冯志伟,2011)。早在计算语言学的萌芽时期,就已得到了长足的发展。机器翻译也是语料库翻译学应用的一个重要领域。而国内语料库翻译学正是滥觞于机器翻译的研究,始于杨惠中的“语料库语言学与机器翻译”(1993)一文;翻译记忆软件技术的核心就是平行语料库(张继光,2016)。根据知网上学术论文数据分类显示,机器翻译的研究总体上分为两大类:计算机科学类和语言学类。计算机科学类重点关注如何改进机器翻译质量,语言学类则主要关注计算机辅助翻译,致力于应用机器翻译来辅助人工翻译。语言学类的发文数量少于计算机科学类(李晗佶、陈海庆,2018)。机器翻译的发展需要计算机科学家和语言学研究者的共同努力(胡清平,2005)。
二、机器翻译的发展历程与现状
古希腊时期便有人大胆设想“用机器来进行自然语言翻译”。20 世纪30年代初期,法国科学家G.B.Artsouni 明确提出“用机器来进行自然语言翻译”的想法。1933年,苏联发明家ТРОЯНСКИЙ 便设计了一种机械的语言翻译机器,并在1933年9月5日申请登记了发明专利。然而受限于当时的科技水平,ТРОЯНСКИЙ 的机器翻译模型并未制成。1946年,ENIAC 作为世界上第一台电子计算机在美国宾夕法尼亚大学的Eckert 与Mauchly 共同努力下诞生。在ENIAC 问世的同一年,美国科学家Weaver 和英国工程师Booth 又提出了利用计算机进行语言自动翻译的构想。对此英国数学家Turing在1947年9月写给英国国家物理实验室的一份报告中也谈到他在计算机建造计划中就曾指出,机器翻译可以显示出计算机的智能。Weaver1947年首次提出“用解读密码方法指导机器翻译”,这一想法后来便成为了如今统计机器翻译(SMT)噪声信道理论的基础。上世纪90年代,IBM 公司Brown 等开发人员将其想法完善并付诸实践,成为现在统计机器翻译的数学模型。1954年,世界上第一次机器翻译试验成功,IBM 公司和美国乔治敦大学用 IBM-701 计算机把几个简单的俄语句子翻译成了英语。随后,英国、苏联、日本等国家也开始进行机器翻译试验。
然而,机器翻译研究很快便陷入了低谷,直到20 世纪70年代末,机器翻译开始走向实用化。一系列机器翻译实用系统如EURPOTRA 多国语翻译系统、Weinder 系统、TAUM-METEO 系统等先后出现。1976年,在与加拿大蒙特利尔大学合作下,加拿大联邦政府翻译局开发出实用性机器翻译系统TAUM-METEO 并正式投入使用——提供天气预报的翻译服务。据称此翻译系统每天可以翻译1500~2000 篇天气预报资料,翻译速度可达6~30 万词/时,且能通过电视、报纸立即公布。20 世纪90年代初期,IBM 公司Brown 等人提出基于信源信道思想的统计机器翻译模型。同时期,人工神经网络翻译再次把机器翻译研究推向热潮。神经网络法最早可追溯到1997年,西班牙学者Ñeco和Forcada 提出利用“编码-解码”框架进行翻译的思想。2002年1月,世界上第一家把统计机器翻译软件商品化的公司Language Weaver 于美国成立,致力于研制统计机器翻译软件(Statistical Machine Translation Software)。2013年,基于人工神经网络的机器翻译(Neural Machine Translation )崭露头角,加拿大蒙特利尔大学的机器学习实验室发布了开源的基于神经网络的机译系统GroundHog;百度2015年发布了将统计和自动学习相结合的在线机译系统;Google 2016年 在ArXiv.org 上发文介绍了谷歌的循环神经机器翻译系统(Google Recurrent Neural Machine Translation);Facebook2017年推出基于卷积神经网络开发的语言翻译模型(Convolutional Neural Machine Translation)。
基于人工神经网络的机器翻译系统引入了当前最先进的技术,实现了目前为止机器翻译质量的大幅提升。据称,Google 公司在用循环神经网络系统进行机器翻译实验中,取得了惊人的成就,其中汉英机器翻译的错误率下降了85%,而英语-西班牙语和法语-英语的神经机器翻译几乎可以与人工翻译相媲美。Facebook 用其推出的基于卷积神经网络开发的语言翻译模型进行翻译实验,其速度比谷歌公司基于循环神经网络开发的语言翻译模型要快9 倍,且翻译准确率更高。测试结果表明,前者在英-德、英-法的测试上都比后者更接近人工翻译水平(冯志伟,2018)。机器翻译在处理一般的形合语言、规则特征显化的文本时,忠实度较高,译文可读性较强,其翻译水平基本接近人工翻译水平,尤其是在处理日常对话文本、新闻科技文本时,其优势更为突出。2017年国际机器翻译会议(WMT)对于新闻文本的机器翻译结果进行了评测,主流语言之间的机器翻译测评得分都比较高(其测评得分均在70%以上),例如:汉英系统和英汉系统得分均为73%,德英系统得分78%,英德系统得分73%,俄英系统得分82%,英俄系统得分75%(由于法语-西班牙语与法语-英语机器翻译系统已经比较成熟,没有参加这次评测)(冯志伟,2018)。
在这个信息爆炸的大数据时代,机器翻译的研究是历史发展的必然产物,机器翻译的前景也是一片光明。谷歌、微软、百度、搜狗、腾讯、科大讯飞、阿里巴巴、网易有道等多家互联网公司纷纷推出了自己的互联网在线机器翻译系统,用户只需登录相应网站,便可免费获取翻译结果。机器翻译研究不断注有新活力,取得了不容小觑的成就。目前,谷歌公司推出的循环神经网络翻译系统已经可以支持60 多种语言的实时互译,国内百度在线机器翻译系统也已经可以支持28 种语言旳实时互译。这些互联网在线机器翻译系统适配手机端、PC 端、平板电脑端、网页端及各个浏览器插件等多种终端平台;其功能也相当人性化、多样化,支持屏幕取词、文字扫描翻译、拍照翻译、离线翻译、网页翻译等多种翻译形式;其翻译质量虽然有待提升,但是在日常对话、新闻翻译等领域已经较为出色。表1 是以腾讯翻译君为例,截取本论文摘要部分来进行翻译质量的展示。

表1 “腾讯翻译君”示例
大众通常所理解并接触到的机器翻译指的是互联网机器翻译系统中的通用翻译功能,网民只需登录相关网站或者服务器,便可免费获取翻译结果,只是翻译的字数或多或少会有限制,非商业用途已是足够。其实这些网络机器翻译系统和平台不仅提供通用翻译,还提供垂直领域翻译、定制化翻译、语种识别、人工翻译等功能,这些功能会适当收取一定费用。以百度翻译系统为例,通用翻译已支持28 种语言在线实时互译,每人每月可享受200 万字符免费翻译;垂直领域翻译目前适用于科技电子类、水利机械类、生物医药类三个垂直领域,收费标准为49 元/百万字符,垂直领域翻译专有名词、术语等更加准确;定制化翻译依托大规模双语语料,付费标准依情况而定,其翻译结果基本接近人工翻译水平,表2 列出的是旅游领域和科技领域的几个例子。
百度翻译目前支持中、英、日、韩、泰、越六个语种精准识别,且目前供网民免费试用;语音即时翻译目前支持中、英、日、粤四种语言的源语音识别、12 种目标语言的语音输出及28 种目标语言的文本翻译结果,每人每月可享用一万次免费调用量,超出部分每次收费0.02 元/次起;拍照翻译目前支持中、英、日、韩、法、德、葡、意、西、俄等10 个语种的源语言的识别,中、英、日、韩、俄、法等28种目标语言的输出,每人每月可享用一万次免费调用量,超出部分每次收费0.03 元/次起。不仅如此,科大讯飞、腾讯等互联网机器翻译平台也开始提供语音文字转化服务,即时消息翻译功能(以聊天影音工具QQ、Wechat 为代表),聊天影音工具QQ 也能提供拍照翻译、扫描翻译服务,只是目前来说译文可读性较差。尽管如此,机器翻译的诞生与发展还是给我们的生活与工作带来了极大的便利,并且使人工智能向前迈了一大步。
三、机器翻译方法
基于规则的机器翻译系统(Rule-Based Machine Translation)发展成为统计机器翻译系统(Statistical Machine Translation)再到今天的神经网络机器翻译系统(Neural Machine Translation),机器翻译发展不断革新,每一次革新又为机器翻译注入新活力,使我们离人工智能时代更进一步。基于规则的机器翻译系统把基于短语的句法分析(Phrase-Based Syntactic Analysis)放在第一位,另外把语法和算法分开,法国机器翻译专家B.Vauquois 教授用“机器翻译金字塔”(MT Pyramid)总结了基于语言规则的机器翻译方法的翻译过程(见图1),成为了基于规则的机器翻译中的“独立分析-独立生成-相关转换”的方法论原则(冯志伟,2010)。
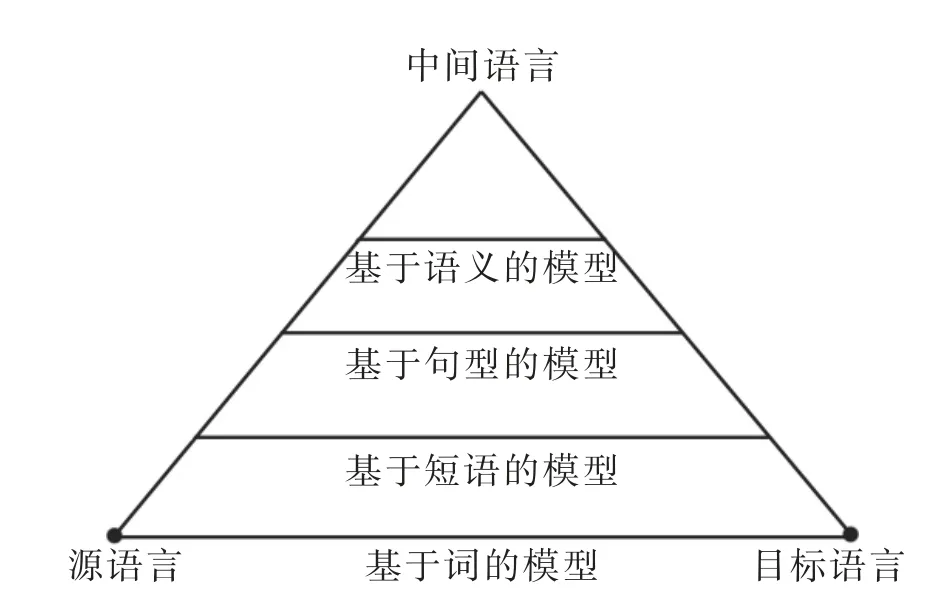
图1 机器翻译金字塔
“在这个金字塔上,越往塔尖的方向走,对语言的分析也越深入”,统计机器翻译要解决的主要问题就是如何避免在引入深层次语言分析时保证分析的正确性(刘群,2009)。20 世纪90年代,RBMT 引入了语料库方法、基于实例的方法、统计方法。机器翻译因此可以从加工处理过的大规模真实语料库中获取语言知识,由此衍生出了统计机器翻译(SMT)系统。这一系统把基于语料库的概率统计方法和基于规则的逻辑推理方法巧妙结合,使机器翻译又向前迈进了一步(冯志伟,2011)。统计机器翻译无需人工编写规则,只需利用平行语料库来训练模型参数,人工成本较低,开发周期较短。统计机器翻译是百度、谷歌、微软等多家国内外机器翻译公司的核心技术(刘群,2003)。机器翻译继续发展,神经网络机器翻译系统应运而生。人工神经网络具有自组织和自学习的能力,信息分布存储和信息处理并行,采用联结主义(connectionism)的方法,克服了之前机器翻译中信息加工处理的障碍。Google 循环神经网络系统利用已有的大规模真实语料进行深度学习,从语料库中自动获取语言特征和语言规则,用函数log p(f|e)表示某一源语言e 转换为目标语言f 的概率,概率越大,证明神经机器翻译的效果越好。该系统把源语言看作输入序列,把目标语言看作输出序列,每次输入与上一次输出结果相关联,循环往复,目的在于得到尽可能大的log p(f|e)参数近似值(parametric approximation)。此系统更具整体性,译文的可读性和准确性较之前更高。Facebook 卷积神经网络将文本序列化、单词向量化,经过分层处理后再输出结果。卷积神经网络由多个隐层按照顺序排列组成,每个隐层又由若干个神经元组成,每个神经元同时又与前一层中的所有神经元关联,而神经元中又具有学习能力的权重与偏差。卷积神经网络工作时,神经网络的输入是一个向量,然后经过隐层的变换和选择,每个神经元得到相应输入数据,接着进行内积运算激活函数运算,整个网络形成一个可导的评分函数。这种编码-解码的框架通过多跳注意(multi-hop attention)(类似于人工翻译时分解句子结构,不断回顾源语言文本确定下一个输出序列)和门控(gating)(控制筛选神经网络中传递到下一个神经元中的信息流,放大翻译中狭义或广义的概览,选取更适于语境的单词)来改善翻译效果。此框架还可结合外部语料,扩展性较强,翻译速度更快,译文质量也更高。
侯强(2019:31)依据知识处理方式将机器翻译方法分为三类:规则法(该类包括直接法、转换法、中间语法);语料库法(该类可细分为实例法、统计法、神经网络法);混合法(集规则法、语料库法于一体:可细分为并行翻译法、串行翻译法、混杂翻译法)(见表3)。
目前,机器翻译研究主要以语料库法为主,其中又以神经网络法最为典型。
综合来看,规则法译文忠实度较高,适合形合语言、规则特征显化的文本;语料库法译文流畅度较高,适合意合语言、规则特征隐化的文本;混合法翻译质量较高,适用范围较广,能够克服单一方法的部分障碍,但其翻译过程还需依据具体文本作适当调整。
四、机器翻译系统评测与改进技术
各类机器翻译系统如雨后春笋般涌现,机器翻译系统的评测成为一大问题。当前,机器翻译评测方法主要有人工评测和自动评测两种。当前,自动评测系统通常采用BLEU(bilingual evaluation understudy)来衡量机器翻译译文与专业人工翻译译文的差异指标(刘群,2012)。BLEU 计算这个指标时,需要选取机器翻译的译文作为candidate docs,同时选取一些专业翻译人员翻译的文本作为reference docs,然后计算两个文本之间的相似程度。机器翻译文本与参考文本之间的相似程度取值范围在0-1,取值越靠近1 表示机器翻译文本与参考文本之间的相似程度越大,机器翻译效果越好。BLEU 作为机器翻译的评估指标,快速便捷,但是仅关注词语搭配关系而忽略句子的整体结构,评估比较粗略,不适用于需要精确评估翻译文本质量的情况。因此在评估时也会用到一些改进方法,如METEOR、TER 等。此外,翻译记忆技术(Translation Memory)是“译者运用计算机程序部分参与翻译过程的一种翻译策略”(Shuttleworth&Cowie,转引自梁三云,2004),也是计算机辅助翻译的核心技术。雪人cat、Déjà Vu、Trados、MemoQ等翻译记忆工具的应用使机器自动翻译省时、省力,同时也能保持翻译的高度一致性。
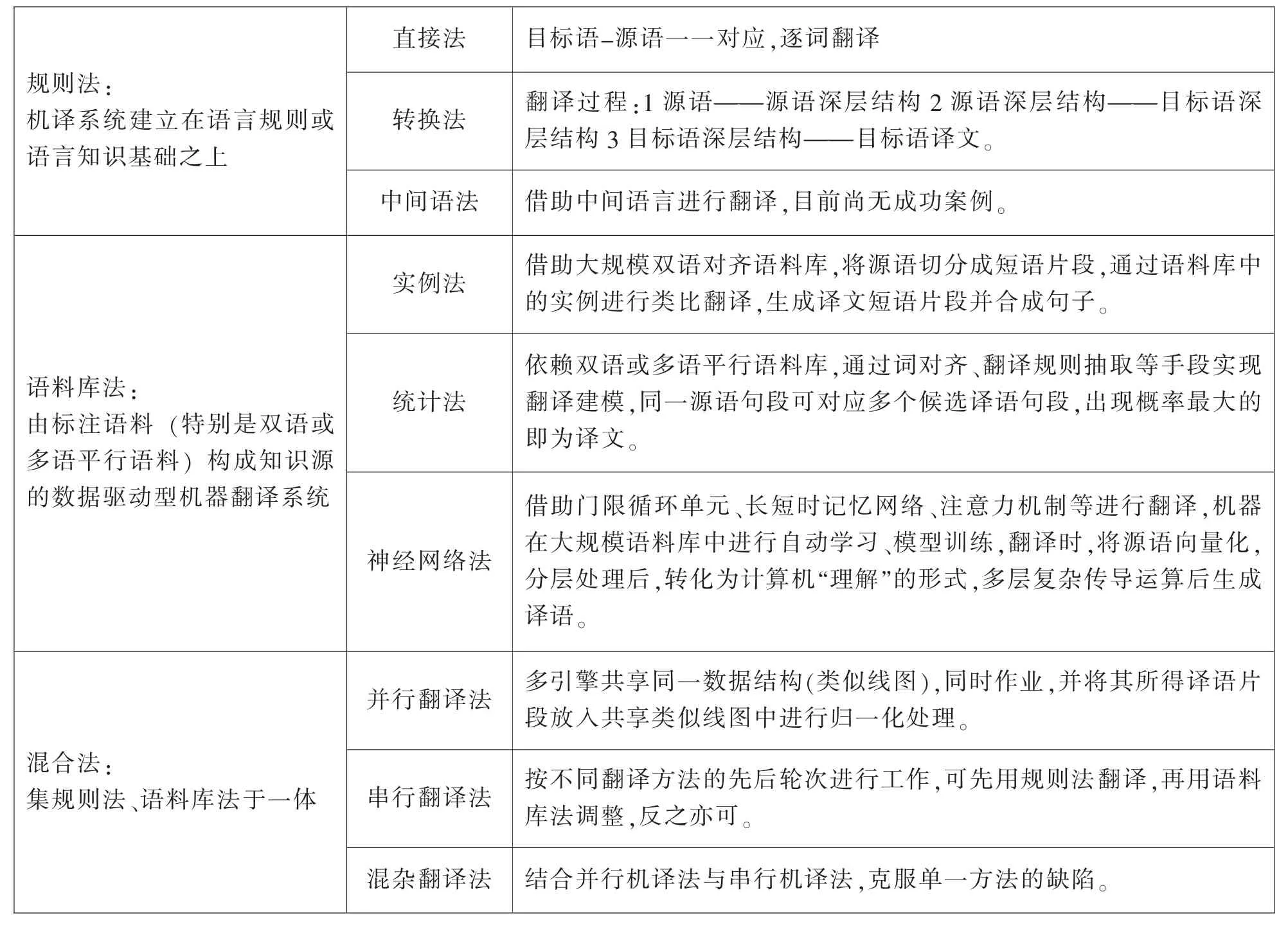
表3 机器翻译方法
机器翻译算法不断更新改进。在WMT 2019的比赛中,微软亚洲研究院机器学习组运用多个创新算法:多体对偶学习(Multi-agent dual learning)、屏蔽序列到序列的预训练(Masked sequence to sequence pre-training)、自动神经网络架构优化(Automatic neural architecture optimization)、软性上下文数据增强(Soft contextual data augmentation)。在机器翻译的任务中,从学习机制、预训练、网络架构优化、数据增强等方面,大大提升了机器翻译结果的质量。在单词语义翻译方面,韩冬提出用Factored 编码器与Gated 编码器来克服传统机器翻译“源端单词语义学习”的障碍,以此提高翻译性能,并通过目前性能最优的神经机器翻译框架Transformer 进行了中英翻译实验,其结果表明,这两种融合源端单词的翻译方式能够显著改善机器翻译质量(韩冬,2019)。由于部分领域机器翻译译文可读性较差,谭敏提出领域适应方法以改善部分资源稀缺领域的机器翻译质量,通过训练使判别器携带所需语域特征并构建集成系统,目前通过实验已证实了在中英广播对话领域与英德口语领域应用该方法,其翻译效果均有显著改善(谭敏,2019)。由于机器翻译系统鲜少对汉语进行优化,为改善汉英翻译质量,肖新凤(2019)提出对不同文本进行预处理并使嵌入层数据参数初始化,在编码器与解码器间加入用于语法变换的转换层,改进seq2seq 模型结构。通过实验已经证实,经过预处理或者使用转换层均使翻译性能显著提高。WMT2019 冠军得主微软亚洲研究院在官微透露:天津大学联合微软亚洲研究院提出的Transformer 的压缩方法,不仅减少了近一半的参数量,模型在语言建模和神经机器翻译任务的表现也有所提升。在ACL 2019年会上,微软亚洲研究院提出无监督中转机器翻译(Unsupervised Pivot Translation),利用单语数据进行训练,对于资源数据较少的语言翻译很重要,源语与目的语可通过多个中转语言连接,经实验证实拆分后的翻译性能得到大幅提升。目前,改善机译质量也依赖于人工译后编辑,人工翻译辅助机器翻译是目前为止输出好译文的最佳方法。一些公司(比如“传神语联网网络科技股份有限公司”)已搭建了人机共译交互平台,人工译后编辑成为了各大互联网翻译平台的重要手段。
五、结语
机器翻译的诞生是新世纪的福音,不仅给我们的日常生活和学习工作带来了极大的便利,也使我们向人工智能时代又迈进了一大步。机器翻译取得的进展有目共睹,在实用化和商业化的道路上,机器翻译只会越走越远。语音机器翻译、术语管理、专门用途文本翻译的需求将会引领机器翻译未来发展的方向。尽管机器翻译发展前景甚佳,但是机器翻译和翻译技术适用范围有限,主要应用于通用新闻报道、科技文本等重复性高的文本,始终不能完全取代人工翻译。即便是当前最先进的神经机器翻译系统也只是在日常会话、新闻翻译等领域取得较好的效果。文学文本隐喻性较强,机器翻译与翻译技术只能作为辅助翻译手段,为专业翻译工作者服务。机器翻译和人工智能不会取代人的创造力和想象力,但是会提升翻译的质量,避免枯燥重复的翻译工作,机器翻译的改进与发展需要计算机科学、信息科学、统计学、语言学等多学界共同努力,才能实现更成熟化的人机互助翻译。
