基于多指标的文献关联程度研究:指标的合成
2019-11-12郑州大学信息管理学院中国人民解放军陆军军官学院军事运筹教研室
郭 强,赵 瑾(.郑州大学信息管理学院;.中国人民解放军陆军军官学院军事运筹教研室)
1 引言
共引分析是指将文献作为分析对象,根据文献之间的关联程度或距离对文献之间的结构关系进行揭示,由此对某领域的研究内容进行划分,对研究前沿进行探测,对研究方向、研究热点以及对结构关系随时间的变化情况进行显示。[1-4]共引分析可以拓展至不同类型的分析对象,如将主题词作为考察对象,一般主题词在文献中共现的次数越多,主题词之间的关联程度越高,从而可以在共现次数的基础上尝试对主题词之间的结构关系进行探讨,也可以对研究内容进行结构化显示。[5-6]
在共引分析中,文献的共引次数越高,文献之间的关联程度可能越强,因而能够利用文献的共引次数对文献之间的关联程度进行近似的表示。在对关联程度进行表示的基础上可以通过构造相似性度量来探讨文献之间的相似程度以及文献之间的距离,并进一步地对相似程度或距离进行处理,从而得到文献或其他分析对象之间的结构关系。此外,需要对得到的结构关系进行分析与解释。
文献或其他分析对象之间的关联程度是结构分析的基础。在用共引次数对关联程度进行表示的过程中会有这样的情形:文献之间的共引次数不高,文献之间的关联程度可能也不高。但如果文献中相同参考文献的数量较多,那么这两篇文献也会具有一定的相关性,或者说文献之间的关联程度并没有完全反映到文献的共引次数上。此外,如果文献的共引次数较低,同时具有的相同的参考文献的数量也不多,那么当只从共引次数与参考文献来判断时,文献之间的关联程度可能也不会较高。但是,如果这时文献具有相同的作者,那么这两篇文献在内容上可能会具有更为深层次的关联,如在处理问题时所采用的方式与方法会具有一定的相似性,只不过这种关联性可能没有表现在文献的共引次数以及参考文献上,这种相同的作者的影响可能会是显著的,或者说与用共引次数来衡量文献的关联程度相比,将该指标纳入时得到的关联程度在总体上会有所差异。因此,需要对关联程度表示的全面性进行探讨,如在共引次数的基础上纳入相同的参考文献数量、相同的作者数量、相同的关键词数量等,由此形成对文献关联程度的综合表示。另外,当共引次数相同时,由于文献的其余关联指标可能会有所不同,综合关联程度也会有差异,与只考虑单个指标的情形相比,综合关联程度有助于结构分析的区分度。
目前,已有研究比较了建立在不同关联指标上的文献结构以及探测结果,目的是探讨不同探测方法的有效性,从而对结构关系以及研究前沿进行更为有效、更具有针对性的揭示。[3,4,7-10]通常,多指标的纳入会使关联程度的描述更全面,可以考虑将分别建立在不同关联指标上的文献结构以及探测结果进行综合考量。还可以考虑将不同的关联指标进行综合,其中综合的方式会有所不同,如将文献标题中的主题词与参考文献组合作为关联指标,以及对文献标题与摘要中的主题词和参考文献一起进行耦合分析。[3,11]本文拟对关联指标进行综合,综合的方式是给出文献关联程度的多属性描述以及相应的综合关联程度,特别是利用逻辑回归从样本文献中得到非样本文献之间的综合关联程度,并在此基础上对结构关系进行探讨。其中,对综合关联程度的考察包括指标的选取、指标合成方式的探讨、综合关联程度的获取流程以及对综合关联程度的合理性的衡量。
多指标的纳入,包括上述的对综合关联程度的考察,也会有助于对某一领域中各个专业方向的揭示。如在对文献进行共引分析后,分别考察引用每个聚类的文献以及这些文献的特征词及其属性。其中,对于某个聚类而言,可以考察引用该聚类的每篇文献的词特征集与引用该聚类的各篇文献的词特征集之间的相似度,由此建立对引用该聚类的各篇文献的一致性的衡量,即类内的一致性;对于不同的聚类而言,可以考察一个聚类的各篇文献的词特征集与另一个聚类的各篇文献的词特征集之间的相似度或差异,即类间的差异。进一步根据各个聚类的类内与类间的共引强度、每个聚类的类内一致性、不同聚类的类间差异对某一领域中各个专业方向进行更为有效的揭示。[12-14]按照上述过程,① 如果从文献的综合关联程度出发,那么从直观上得到的聚类会更具有合理性。② 当将某些聚类归并为某个专业方向后,由于从直观上所得的聚类会更为合理或者说得到的聚类与实际情况更为吻合,原有的某些在内容上相似性相对较弱的文献会被分离,这样就会减少对专业方向进行定性时的模糊性。此外,当使用这些聚类文献的词特征集来表征专业方向的“当前研究”时,原有相似性相对较弱的文献的分离会减少对“当前研究”的扰动。③ 由于类内的一致性与类间的差异均是由引用各个聚类的文献得到的,将各个聚类归并为不同的专业方向时,也能和实际情况更为吻合。纳入多指标之前,原有的聚类包含某些在内容上相似性相对较弱的文献,这些文献在所属的聚类中可能并不合适,这样对于原有的聚类以及在此基础上类内与类间的相似性,这两种效应的叠加会放大,导致专业方向与实际情况存在偏差。
在对指标进行选取时,除了上述取值为绝对量的指标之外,还需要将取值为相对量的指标纳入在内。如,当两篇文献的共引次数较低时,如果只从共引次数来看,两篇文献的关联程度可能并不高。但是,如果在一篇文献被引用的同时,另外一篇文献也很有可能同时被引用,或者说两篇文献在被引用时往往同时被引用,那么此时尽管两篇文献的共引次数并不高,但这两篇文献的关联程度却有可能是较高的。因此,需要将两篇文献的共引次数与两篇文献的被引次数的比值考虑在内。其中,被引次数是两篇文献的总被引次数与共引次数的差,该比值的分母是两篇文献的施引文献的数量,分子是同时引用这两篇文献的施引文献的数量,比值越高,说明这两篇文献被同时引用的可能越大,这两篇文献的关联程度也会越高。该比值是被引次数的杰卡德指数。类似地,如果两篇文献共同引用的文献占两篇文献所引用的全部文献的比例较高,那么即使这两篇文献共同引用的文献数量相对较少,也会由于这两篇文献所引用的文献中相同文献会具有较高的比例,或其中一篇文献引用某篇文献时,另外一篇文献也很有可能会引用该文献,这两篇文献也会具有一定的关联性。因此,需要将两篇文献相同参考文献的数量与两篇文献参考文献的数量的比值考虑在内,其中,参考文献的数量是两篇文献总参考文献的数量与相同参考文献的数量的差,或是两篇文献所引用的全部文献的数量。该比值是关于参考文献的杰卡德指数。
2 关联指标的直接合成
在得到综合关联程度的过程中,一种考虑是对各个关联指标直接进行合成,这时需要对指标之间的相关性进行考察。如,选取上述的文献关联指标,在对指标直接进行综合时要注意这些指标并不完全独立。当文献的共引次数相对较高时,两篇文献在内容上通常会有一定的关联性,而这种关联性在两篇文献的参考文献中也会有所体现,由此文献的共引次数与相同的参考文献的数量一般也会具有一定的相关性。这时在对指标进行合成时需要转化为独立变量,如对关联指标的主成分进行考察,并由此尝试对内在的独立变量进行探讨。由于每两篇文献均有相应的关联指标值与其相对应,在标准化后的指标值的基础上给出各个指标之间的协方差,并进一步地通过主成分分析,得到相应的总方差解释表以及成分矩阵,从而得到各个主成分与关联指标之间的关系式。当各个主成分的含义从总体上判断均具有正向性时,每两篇文献之间的关联程度可以利用其各个主成分取值的直接求和来表示。
上述这种合成需要建立在对主成分的含义具有一定认识的基础上,尽管判断主成分的含义可能具有一定的粗糙性,但是在有些情形中可以根据主成分的大致含义从总体上判断该含义是否具有正向性。如果某个主成分的含义在总体上具有正向性,或者说当与该含义对应的变量取值增加并且与其余主成分含义对应的变量的取值均保持不变时,文献之间的关联程度的期望值会增加。由于各个主成分的含义具有独立性,从线性回归的角度来看,当各个主成分的含义在总体上均具有正向性的情形下,与各个主成分含义对应的变量均具有正的总体回归系数。因此,可以通过与主成分含义对应的变量的直接求和来近似回归函数。当各个主成分的取值给定时,可以用此时的关联程度的期望值对此时的总体中的个体关联程度进行近似,由此每两篇文献之间的关联程度可以利用其各个主成分取值的直接求和来进行近似。需要指出的是,上述正向性是与主成分含义对应的变量,或者所选取的关联指标对于关联程度的描述并不全面,文献之间的关联程度也并不确定。
3 概率型综合关联程度
首先,选取样本文献,由专家对文献之间的关联程度进行判断并给出相应的关联等级。关联程度只由专家给出判断的原因是精确给出两篇文献之间的关联程度是较为困难的,而给出大致范围反而有可能会使得文献之间的相似性以及结构关系的揭示更具有合理性,同时也更具有操作性。其次,分别获取每两篇文献之间的各个关联指标的取值。由于每两篇文献均有关联指标值以及专家判断的关联等级与其相对应,并且两者具有一定的相关性,由此在考虑关联指标值和专家判断的关联等级的基础上,可通过两者之间的逻辑回归,即可给出给定文献之间的关联程度处于各个关联等级上的可能性。这两篇文献可以是样本文献,也可以是非样本文献。对于样本文献而言,可以通过考察两篇文献位于各个关联等级上的可能性与专家判断等级之间的一致性来检验回归结果的合理性以及有效性。由于通过人工判断关联程度的只是部分文献,可以利用由样本文献得到的回归关系来估计两篇非样本文献的关联程度处于各个关联等级上的概率,进而通过对各个关联等级赋予一定的关联分值而得到两篇非样本文献之间的关联程度的期望分值,并由此对文献之间的关联程度进行近似。在上述过程中,得到的回归关系是对关联指标的合成。① 自变量的观测值之间可能会具有近似的线性相关性,如果此时将回归关系用于预报,还需要尽可能消除这种共线性的影响。②在样本资料中,样本文献之间的关联等级是由判断主体决定的,因而这些参数的估计值仍然会受到判断主体的影响,但是其优势是不需要判断主体直接参与到指标的合成过程中,而是转变为对样本文献关联程度的判断,相比之下,在有些情形中对文献之间的关联程度进行判断可能会更具有可操作性。③尽管在确定关联等级的关联分值时会有主观的因素,但是这与指标的合成是没有关系的。
选取样本。① 样本文献的各个指标的取值能够涵盖相应指标的实际取值范围,这是由于当非样本文献的关联指标值没有落在样本关联指标的取值范围内时,对回归方程进行外推可能会具有较大的误差。②选取的样本文献需要属于同一学科领域,使得关联指标的取值具有可比性。③ 在选取样本时,不同的样本会形成不同的检验结果及估计,当样本中的个别文献具有某种特殊性时,如文献的关联等级与其某些关联指标的相关性偏弱,这时在利用该样本进行回归时,可能会使解释变量的影响并不显著,由此需要在回归模型中剔除这些自变量。但是这里认为包含全部关联指标的回归模型是正确的,当利用剩余变量建立模型时,得到的估计以及预报就可能是有偏差的,而对于该情形预报偏差的方差以及总的预报效果如何还需要做进一步的探讨。因此选取的样本应尽可能地具有一般性,如它能够反映直观认识中的各个关联指标与关联程度之间的相关性,当利用全部关联指标建立回归模型时,使解释变量的影响可能会具有显著性。如果解释变量均具有显著性,此时的回归模型可以考虑作为最终建立的模型;而当模型的共线性偏弱或近似没有共线性时,也可以得到相应的预报概率及其置信区间。[15]
从直观上会有以下的认识:首先,对于各个关联指标而言,文献之间关联指标取值相对较低的情况比例会相对较高,而关联指标取值相对较高的情况占比则会相对较低;其次,文献之间的关联程度也会有类似的情形,样本的等级变量的分布偏重于其较低的取值区域,同时这种分布也需要与样本关联指标取值的分布具有一致性,这里认为选取的关联指标与关联程度之间从直观上会具有相关性;第三,当共引次数减小时,文献之间的关联程度会有减小的趋势,文献之间相同参考文献的数量也会减小,共引次数与相同的参考文献数具有一定的一致性。选取的样本文献需要符合上述的直观认识,目的是使得选取的样本能够具有一般性,样本的性质需要与对总体性质的直观认识相一致,从而使得指标的取值不会侧重于某些方面。
在上述考虑的基础上,可对指标合成过程的合理性进行初步的考察,如可以构造各个关联指标的取值以及相应的关联等级,使其满足上述的选取要求。在图1 中,横轴是每两篇文献的编号,纵轴是每两篇文献之间各个关联指标值以及这两篇文献的关联等级。其中,每两篇文献的关联指标从左至右分别为文献的共引次数、相同的参考文献数量、相同的作者数量以及相同的关键词数量,最右方为两篇文献的关联等级。这里将关联程度分为五个等级,等级越高表示两篇文献之间的关联性越强。

图1 构造的样本文献
由于上述关联指标从直观上会具有一定的相关性,在对样本文献进行回归时需要对自变量的共线性进行考察。① 选取相应的准则来对模型以及自变量的共线性进行判断。② 如果存在中等或较强的共线性,那么可以考虑通过主成分回归来消除共线性。其中主成分选取为相应特征值的累计和达到特征值总和的85%时的各个主成分,由于很小的特征值在特征值总和中的占比很小,会被剔除,经验回归方程的信息损失也在可以接受的范围内。另外,选取主成分回归的原因是希望在模型中保留所有的自变量。③ 如果共线性偏弱或者不存在共线性,那么可以考虑直接对原有自变量进行回归。
对图1 中的样本文献,XTX 的特征值分别为1.811、1.006、0.833、0.351,其中X 为样本矩阵,最大特征值与最小特征值的比值仅为5.160,从条件数的角度来看,模型的共线性偏弱或者可以近似为没有共线性。将图1 中的自变量取值标准化后,通过Spss能够得到每个自变量与其余自变量之间的复相关系数,并可以得到相应的方差扩大因子分别为1.825、1.240、1.019、1.514,其中最大值没有超过经验标准,从方差扩大因子的角度来看,模型也不存在中等或较强的共线性,同时各个自变量也可近似为不包含在某些共线关系中,由此可直接对原有的自变量建立回归模型。
利用Spss 对图1 中的文献关联指标与文献之间的关联等级进行回归,对参数向量的检验结果显示:在0.05 水平下所选取的关联指标在整体上的影响是显著的。各个自变量相应的p 值分别为0.0032、0.0652、0.0432、0.0741,尽管在0.05 水平下相同的参考文献数量以及关键词数量并不显著,但是由于其p 值很小,故在模型中仍然保留这两个变量。由样本文献能够得到参数的估计以及相应的经验回归方程,在经验回归方程的基础上可以给出文献之间的关联程度处于各个等级上的预报概率,由此可以考察样本关联程度的预报结果与样本实际关联程度的一致性。对于构造的样本文献,预报与观测的一致比能够达到89.9%。进一步地对关联分值的合理性进行检验。
(1)构造非样本文献,使文献的共引次数增加,并固定其余的关联指标的取值,这样从直观上文献之间的关联程度应当会有增加的趋势。图2 中的横轴是文献的共引次数,纵轴是样本文献关联程度的期望分值,将共引次数由2 调整至17,其余的关联指标均取为1。由经验回归方程得到非样本文献的关联程度处于各个关联等级上的预报概率以及相应的关联程度的期望分值,对各个关联等级赋予的关联分值分别为1 至5 分。类似地可以对相同的参考文献数量、相同的作者数量以及相同的关键词数量分别进行调整,在调整的同时保持其余关联指标的取值不变,由于这些指标都是关联程度的正向指标,当单独增加某个指标的取值时,文献之间的关联程度均会有增加的趋势。首先,在图2 中将相同的参考文献数量由2 调整至10,共引次数、相同的作者数量以及相同的关键词数量分别取为3、1、2。其次,将相同的作者数量由0 调整至2,共引次数、相同的参考文献数量、相同的关键词数量分别取为4、5、2。最后,将相同的关键词数量由1 调整至4,共引次数、相同的参考文献数量、相同的作者数量分别取为3、5、1。图2 的横轴分别为需要调整的关联指标的取值,需要指出的是,上述其余指标的取值具有随意性。
由图2 可知,当单独增加某个指标的取值时得到的关联分值均会有增加的趋势。但可能会存在这样的情形:在共引次数较高的区域,随着共引次数的增加关联分值的差异可能会具有减小的趋势,而这与实际情况并不相符。究其原因是关联程度的期望分值等于各个关联等级的关联分值的加权求和,其中权重是文献的关联程度处于各个关联等级上的概率,关联程度处于各个等级上的概率之和等于1,所以期望分值的最大值等于各个关联等级的关联分值的最大值。当共引次数增加时,期望分值会有增加的趋势,只有当共引次数增加时期望分值的增长具有变缓的趋势,才能使得期望分值不会超过其最大值,或者说随着共引次数的增加,关联分值的差异会有减小的趋势。对于该情形,改进的方式是增加关联等级的数量,其目的是使得专家在给出等级时能够不受关联等级数量的限制,毕竟从直观上当共引次数增加时关联等级的差异也会有增加的趋势。这样在样本文献的基础上利用回归方程进行预报时,对于非样本文献最有可能处于的关联等级而言,随着共引次数的增加,该类等级的差异也可能会具有增加的趋势。如果此时仍然赋予各个关联等级的分值为等差增长,那么当共引次数增加时,非样本文献的期望分值就有可能会有被拉开的趋势。同时对样本文献而言,由于关联程度的预报结果与其实际关联程度之间具有一致性,当共引次数增加时,样本文献所处的关联等级也可能会有被拉开的趋势,从而样本文献期望分值的差异也可能会增加。
需要指出的是,上述这种改进方式是建立在设定较多的关联等级的基础上,而如果关联等级较多,在确定样本文献所处的关联等级时会涉及到与其余样本文献关联程度的相互比较,当被比较的对象超过一定的数量时,人工判断会丧失一定的准确性;[16]而当关联等级较少时,等级划分的粗糙性反而会使得很多原本需要相互比较的情形变得没有必要。
(2)与相同的关键词数相比,通常共引次数对文献的关联程度影响更为重要。当其余指标的取值相同时,与共引次数偏高且相同的关键词数量偏低的情形相比,共引次数偏低且相同关键词数量偏高的情形在整体上可能会具有相对较低的文献关联程度。在图3中,横轴是每两篇文献的编号,纵轴是每两篇文献的关联程度的期望分值。图的上方区域是将共引次数、相同的关键词数量分别取为13、1 时的情形,此时期望分值的平均值为4.516;图的下方区域是将相同的关键词数量和共引次数分别取为4、3,此时的期望分值的平均值为3.516。在这两种情形中相同的参考文献数量、相同的作者数量分别取2 至10、0 至2,并且将关联等级仍然设定为五个等级。

图2 某关联指标增加且其余关联指标不变时的关联分值的变化情况
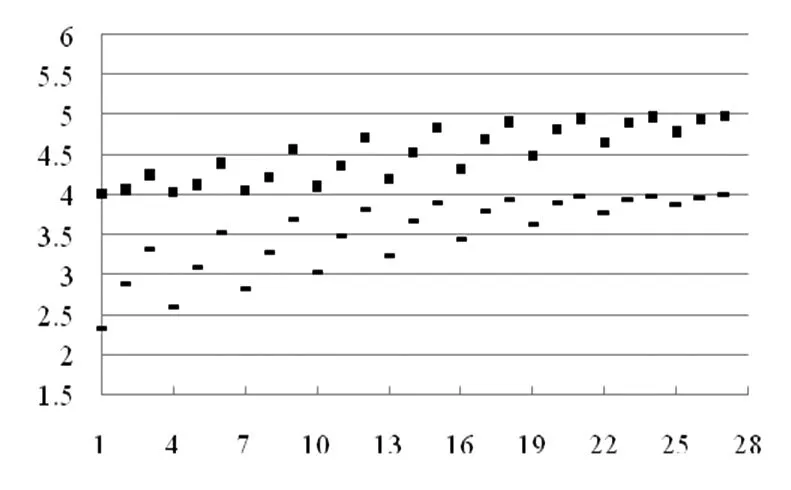
图3 共引次数与相同的关键词数量不变且其余的关联指标增加时的关联分值的变化情况
4 实证分析
概率型综合关联程度的指标合成方式有如下特点。① 回归关系是对关联指标的合成,判断主体没有直接参与到指标的合成过程中,而是转化为对样本文献关联程度进行判断,样本的关联等级取决于判断主体。② 当某一关联指标的取值为零时,两篇文献关联程度的期望分值可能并不会为零,因而这两篇文献仍然可以纳入到后续的文献结构分析中,这也是多指标情形下文献关联程度的特点。③ 由于通过人工对关联程度进行判断需要一个过程,样本中的文献数量可以逐步增加,随着样本容量的增加其性质也会趋向于总体的性质。此外,可以对已建立的样本资料中的文献关联等级进行调整,因为随着某学科领域的发展,人们对文献之间关联程度的认识也会发生变化。
图4 中的样本是按照上述的样本选取要求。在图4 中,横轴为每两篇文献的编号,纵轴是每两篇文献的各个关联指标值以及这两篇文献的关联等级。其中,关联指标从左至右分别为两篇文献的共引次数、相同的参考文献数量、相同的作者数量、相同的关键词数量、被引次数的杰卡德指数、参考文献的杰卡德指数以及两篇文献的关联等级。关联等级仍然取1 至5 五个等级。要使样本文献的关联指标值具有可比性,对于共引次数而言,由于不同的文献具有不同的出版时间,为了消除该因素对文献的被引次数以及对文献之间共引次数的可比性的影响,可以选取足够长的考察时段,如取考察时段的长度远大于被考察学科领域文献的被引半衰期,以至于在该考察时段内文献的被引次数近似等于文献的总被引次数,而不同文献的总被引次数之间会具有可比性,从而在该考察时段内的文献的被引次数以及文献之间的共引次数也相应地会具有一定的可比性。对于参考文献的数量而言,随着被考察学科领域的演变,该领域的文献规模以及每篇文献参考文献的规模会发生变化,处于学科不同发展阶段的文献,其参考文献的数量也会因为学科演变阶段的不同而有可能不能直接比较,或者说学科演变阶段的不同可能会对其参考文献数量的可比性带来影响。对于该影响,如果两篇文献的出版时间间隔大于所属学科领域文献的引用半衰期,那么对于其中出版时间较晚的文献而言,从其出版时间往前的时间长度为引用半衰期,这个时间段内的参考文献的数量能够近似等于这篇文献总的参考文献的数量,能够近似认为这两篇文献的参考文献处于不同的出版时段。当这两个出版时段内的文献规模以及参考文献的规模存在差异时,就可能不能对这两篇文献的参考文献的数量直接进行比较。相反如果这两篇文献的出版时间的差异小于引用半衰期,那么这两篇文献的参考文献的出版时段会有一定的重叠,而重叠时段内的参考文献的数量会具有可比性。如果使得重叠时段足够长或者可以接受,那么这两篇文献的参考文献的数量也会具有一定的可比性,或者说能够在一定程度上避免由学科演变所带来的对参考文献数量的可比性的影响。因此图4中,对样本文献的选取还需要建立在文献服从一般意义上的老化规律以及对文献的引用具有半衰期性质的基础上,其中将学科领域选取为图书情报领域,被引半衰期以及引用半衰期均近似取为5 年。[17]根据对共引次数以及对参考文献的数量的可比性要求,样本文献的选取范围为2009 年至2010 年出版的图书情报类文献,统计时间为2018 年3 月,数据来源于中国知网。
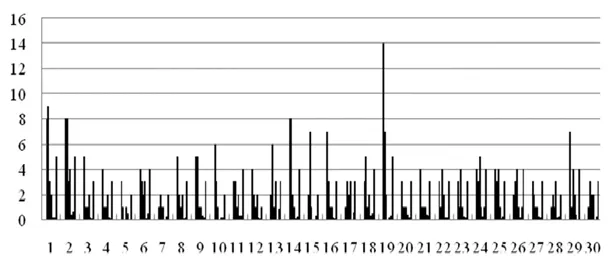
图4 选取的样本文献
因此,期望对不同指标合成方式下的文献结构进行比较。①由于在概率型综合关联程度的指标合成方式中是通过样本文献的关联程度对非样本文献的关联程度进行预报,对结构进行比较时,统一将非样本文献作为考察对象。② 在选取非样本文献时,由于非样本文献的关联指标值要具有可比性,非样本文献不仅要属于同一学科领域,而且要设定非样本文献的出版时间,才能使共引次数以及参考文献的数量能够进行比较。同时,当通过文献结构的比较来对得到的关联程度的合理性进行考察时,非样本文献的选取还要使得由不同关联程度得到的文献结构能够有所差异,这样才能够对得到的文献结构的合理性进行比较。③ 对非样本文献进行选取后,可以在此基础上对文献的结构进行考察,文献关联程度可以分别按照以下四种情形来确定,即对关联指标的直接合成、概率型综合关联程度、只考虑共引次数的情形以及由专家对非样本文献的关联程度进行判断的情形。④ 这里将上述第四种情形作为标准,对前两种多指标情形以及第三种单指标情形下的文献结构关系的合理性分别进行考察。
