多源数据的文献计量功能发展及其比较研究
2019-11-12孙济庆华东理工大学科技信息研究所
朱 雯,陈 荣,孙济庆(华东理工大学科技信息研究所)
1 引言
20 世纪中叶,人们就已经意识到信息研究的关键是准确地度量信息,而文献计量学作为与信息科学关联的定量研究领域,[1]其与科学计量学、信息计量学、网络计量学和知识计量学既有联系又有区别。[2-4]文献计量学是信息计量学的基础,科学计量学的成果形成了信息计量学的重要内容和发展基础,网络计量学和知识计量学是文献计量学在新时代的发展。目前,文献计量学在数字文献资源应用、信息检索等方面已得到广泛应用,[5-9]一方面,提高了文献检索的效率和效果,为学术影响力的评价提供数据支持;另一方面,有力助推了学术检索系统的大数据技术的繁荣发展。在此时代背景下,学术文献检索系统作为信息时代的产物,人们对其提出了更高的要求。
Morris 等人指出基于某种关系的科学计量方法只能从某一方面反映出对科学领域的有限认识。[10]伴随着科技文献数量的爆炸式增长以及文献类型的不断丰富,来自新渠道、新载体的新的数据类型源源不断的产生,拓展了可供科学计量分析的关系类型,而如何充分利用当前多类型的数据和多种计量关系,并对多源数据的文献计量功能进行优化,则成为提高科学计量分析能力的重要突破方向之一。
目前,多源数据还没有一个较为统一的概念,参照化柏林[11]、许海云[12]等人的研究,笔者认为多源数据是指不同类型的来源信息或关系数据。在此基础上,将学术数据库和学术搜索引擎作为多源数据的研究对象。这里的学术数据库是指在计算机可读介质上,使用一定方法将学术类信息组织起来的信息集合,[13]其研究主要集中在检索方法、收录范围、检索结果分析比较等方面;[14-17]而学术搜索引擎是指通过组织、管理和维护网络中的学术信息,用户经一个检索入口,便能快速获取网络学术信息,[18]其研究主要探讨文献来源、检索功能、检索结果以及其与传统数据库的差别。[19-22]
综观多源数据的相关研究发现,目前的研究较多聚焦于利用多源数据的文献数据进行文献计量分析,[23-26]而对其文献计量功能的研究涉及较少。本文以学术搜索引擎(谷歌学术、百度学术)和学术数据库(Web of Science、Scopus、中国知网和维普数据库)为研究对象,在研究多源数据的文献计量功能发展历程的基础上,从数据来源、计量内容、计算方法和结果呈现方式四个方面比较学术搜索引擎与学术数据库的文献计量功能,分析文献计量功能的发展特点及其差异,旨在促进学术搜索引擎和学术数据库完善文献计量功能,提高用户的使用效率,为学术研究提供更为科学准确的文献计量结果。
2 多源数据的文献计量功能发展历程
从20 世纪80 年代第一次出现文献计量功能——“检索结果排序”起,学术搜索引擎和学术数据库的文献计量功能已经发展了近40 年,大致可以分为三个阶段。① 简单排序计量阶段(20 世纪80-90 年代)。20 世纪80 年代,光盘数据库出现,单一的检索功能已不能满足用户需求,出现文献发表年份排序等功能,方便用户筛选出所需文献。此时的文献计量功能为简单计量阶段,主要表现为相关性排序、发表年份排序等。②指数化和模型化阶段(20 世纪90 年代末-2009 年左右)。20 世纪90 年代末,网络版检索系统出现,用户可以在短时间内检索到全球的文献,系统实现了简单文献分析功能,如索引词分析等。此时的文献计量功能从简单排序计量转向简单分析计量,计量内容不断完善。随着学科的不断成熟,评价学术影响力的需求越来越大,不同数据源开始利用自身数据资源优势,构建了各种复杂的评价指标模型,如影响因子、h 指数等。③ 可视化和智能化阶段(2009 至今)。[27]知识经济的发展以及可视化技术的成熟,不同数据源更加重视知识语义的挖掘,在结果呈现方面更加多样化。如利用可视化技术显示某领域论文发展数量年度分布、关键词共现网络等。
2.1 学术数据库的文献计量功能发展历程
从学术数据库文献计量功能发展历程看,主要经历了简单排序计量、简单分析、复杂的评价指标分析以及可视化和智能化分析几个阶段,目前文献计量功能发展到第三阶段。
随着文献数据量的不断扩大,数据库的检索功能日益完善。如检索结果排序功能,以列表的形式将检索到的文献按照文献的类型、文献的作者、刊载文献的出版物等内容进行排序,供用户筛选。
评价分析功能是指学术数据库利用自身引文数据等评价期刊或作者等的学术影响力,如Web of Science中的期刊影响因子、中国知网的作者h 指数、维普数据库的平均引文率、Scopus 的CiteScore 等。
随着知识经济时代的到来,文献的内容价值受到学者们的重视,学术数据库凭借着深厚的数据资源,对文献的关键词、主题词等进行计量分析,计量结果的显示方式从单一的列表方式向可视化方式发展,如中国知网的关键词共现网络图等。
2.2 学术搜索引擎的文献计量功能发展历程
与学术数据库相比,学术搜索引擎起步较晚,目前学术搜索引擎的文献计量功能也已发展到第三阶段。学术搜索引擎在学术数据库已有的文献计量功能基础上,不断完善计量内容,开发了具有自身特色的计量产品。
谷歌学术是谷歌旗下免费的学术搜索平台,2004年11 月发布了第一个Beta 版,2006 年1 月扩展到中文学术文献领域,2012 年推出谷歌学术计量,用来评价各个领域杂志的影响力。该系统主要包括h 指数、h核心(h-core)、h 中值(h-median)等。[28]
百度学术是百度旗下的免费学术搜索平台,旨在将资源检索技术和大数据挖掘分析能力运用于学术研究,自2014 年成立以来推出了研究点分析、相关热搜词分析,具有深入计量文献的内容特征。
3 多源数据的文献计量功能比较
本文从数据来源、计量内容、计算方法、结果呈现方式四个方面对多源数据的文献计量功能进行比较。
(1) 数据来源是文献计量功能的基础,不同的数据来源是导致文献计量结果产生差异的重要原因之一。本文主要从文献种类、文献数量、学科范围、时间范围和国家范围五个方面比较学术搜索引擎和学术数据库的数据来源,旨在探析导致文献计量差异的原因。
(2) 计量内容是文献计量功能的重要组成部分,主要根据文献的外部特征和内容特征进行计量。文献的外部特征计量是基于文献的机构、作者、出版单位、来源等进行计量,主要有简单计数统计和评价指标统计两种统计方式。简单计数统计是指学术搜索引擎或学术数据库对文献数量、下载量、被引量等的计数统计;评价指标统计是指学术搜索引擎或学术数据库利用特定数理模型进行计量分析,评价对象一般为作者和期刊。文献的内容特征计量是基于关键词、主题词、摘要等的计量。通过计量文献内容特征,可以了解某篇文献的重点研究内容以及相关研究点的研究进展等。
(3)计算方法是文献计量内容的基础,其主要包含两种计算方法:① 利用相关计算机软件进行统计发文量、被引量、词频等计数统计;② 利用文献信息计量学基本规律的数学表达式和相关计算机软件建立数学模型。[27,29]
(4)结果呈现方式是学术搜索引擎或学术数据库将计量得到的结果呈现出来的方式,而可视化是呈现计量分析结果的关键性技术路径。[30]除可视化方式外,还包含表格方式。表格方式是利用表格显示特定数据,以列表呈现的计量内容主要有时间分布、语言分布、资源类型分布、学科分布、来源分布、作者分布、机构分布、国家/地区分布、各参考文献、引证文献、相关文献等。可视化方式是通过图形和图像的方式显示特定的数据,并进行相应的交互处理。[31]根据可视化图形图像描述的信息特征关系不同,可视化分为纵向可视化、横向可视化和交叉可视化三种主要形式。[32]纵向可视化表现的是某一计量内容随时间变化的状态,用柱状图、条形图、折线图、散点图等表示;横向可视化表现的是在同一时间状态下不同计量内容之间的相互关系,用柱状图、条形图、网络图等表示;交叉可视化表现的是纵向可视化与横向可视化相结合后的总体数据的状态,用网络图或知识图谱表示。
3.1 数据来源
本文对学术搜索引擎和学术数据库收录的数据来源进行检索查询,检索截止时间为2018 年4 月1 日,结果见表1。从表1 中可以看出学术搜索引擎中的引文数据来源大于学术数据库,谷歌学术和百度学术收录的文献数量较大,学科、时间以及国家覆盖范围广于学术数据库。原因是学术搜索引擎是网络中学术文献信息的第三方集成平台,仅提供网址链接,不提供文献全文,所以数据来源广泛;而学术数据库是数据库商与出版社等建立合作关系,将这些机构出版的期刊、图书等资源进行数字化处理,集成在数据库内部,其数据来源少于学术搜索引擎。
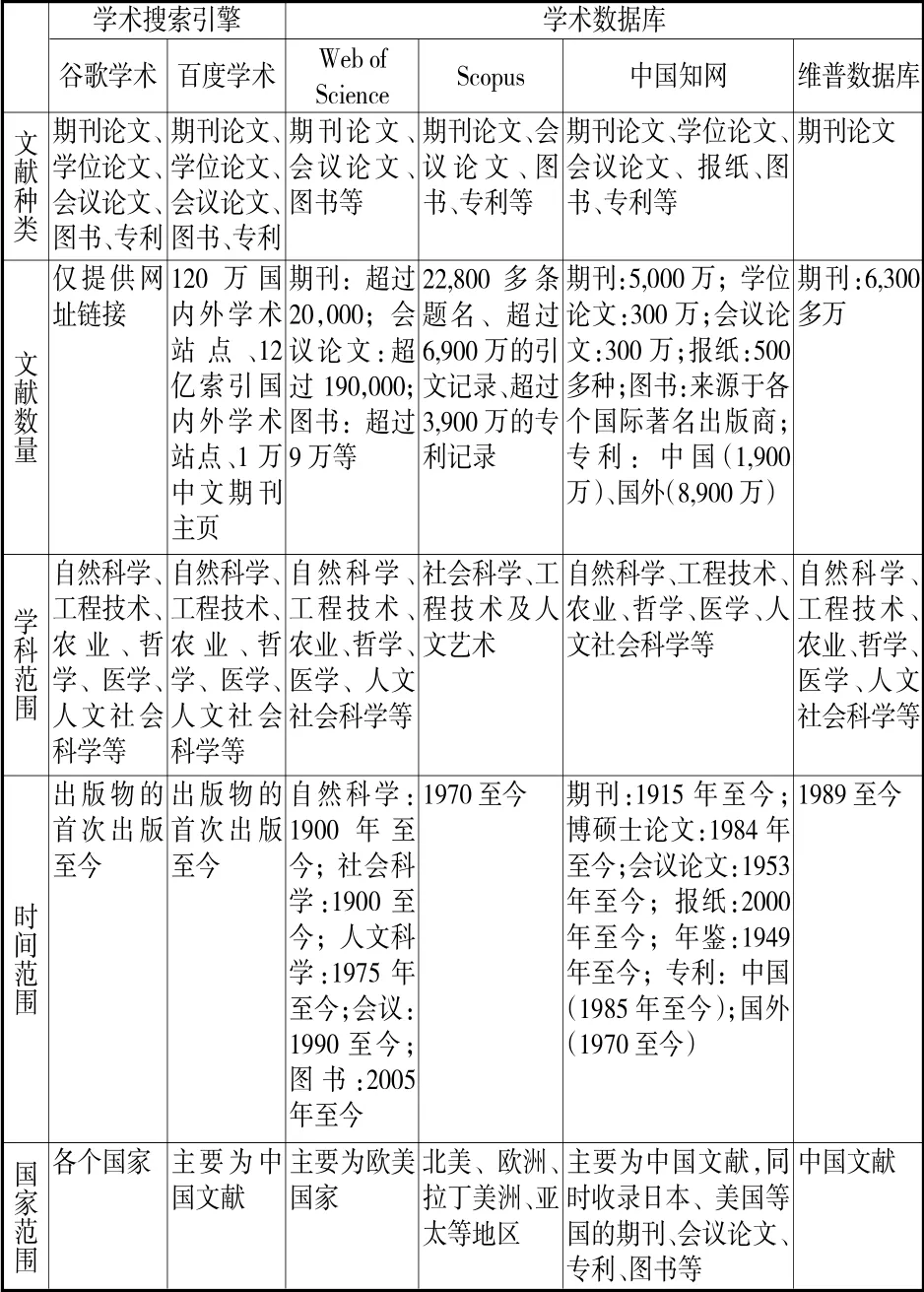
表1 学术搜索引擎和学术数据库的数据来源
3.2 计量内容
从表2 中可以看出,① 简单计数统计方面,学术搜索引擎和学术数据库均计量资源数量、发文量、被引量等,但学术数据库的计量内容种类多于学术搜索引擎,除此之外,Scopus 计量数据库之外的文献阅读量,如提供文献社交媒体的阅读量;② 评价指标统计方面,学术搜索引擎和学术数据库均包含期刊和作者等影响力的计量;③ 中国知网注重提供合作作者网络图等计量内容,百度学术提供了研究点分析等计量内容;④ 在内容特征计量方面,谷歌学术不涉及内容特征计量,中国知网和维普数据库重视挖掘各关键词之间的关系,并提供专利研究热点气泡图等。
3.3 计算方法
由于内容特征计量涉及的数学模型较复杂,故本文仅探讨学术搜索引擎和学术数据库中简单计数统计和评价指标统计的计算方法。研究发现,学术数据库的简单计数统计和评价指标统计的主要方法与学术搜索引擎相似,但也存在一些不同点。

表2 学术搜索引擎和学术数据库的计量内容
(1)共同点主要有三个方面。①目的相同,均是评价学术影响力或为学术研究提供数据支持。②评价指标的数据主要来源于被引次数。③计算公式主要有三种:一是简单求和的计算方式,如期刊被引量等;二是计算平均数,如影响因子等;三是计算中位数,如h 指数等。
(2)不同点主要有两个方面。① 引文数据来源不同。学术搜索引擎统计的引文数量多于学术数据库,如,维普数据库中学者h 指数的数据来源于期刊;而百度学术学者h 指数的数据来源于期刊论文、学位论文、会议论文、图书、专利等。② 评价指标统计时间范围不同。如,百度学术的影响因子是期刊前2 年发表的文献在当年百度学术中的篇均被引次数;Web of Science 中的立即指数是期刊当年发表的文献在当年Web of Science 中的篇均被引次数;Scopus 中的CiteScore 是期刊前3 年发表的文献在当年Scopus 中的篇均被引次数。
3.4 结果呈现方式
学术搜索引擎和学术数据库的结果呈现方式也各异(见表3)。① 学术搜索引擎和学术数据库的结果呈现均包含表格方式。② 学术数据库结果呈现的可视化方式多于学术搜索引擎。如,谷歌学术不包含可视化方式;而学术数据库中的四大研究对象均包含可视化方式。百度学术包含纵向、横向和交叉可视化方式,可视化形式多样;Web of Science 和Scopus 以纵向可视化为主,可视化形式较单一;而中国知网和维普数据库还注重知识图谱的构建,维普数据库将领域、作品、机构、作者、主题等放于同一张知识图谱中,直观地显示了各结点之间的关系,同时在任意一个结点,还可以发现与之有关系的结点(见下图)。
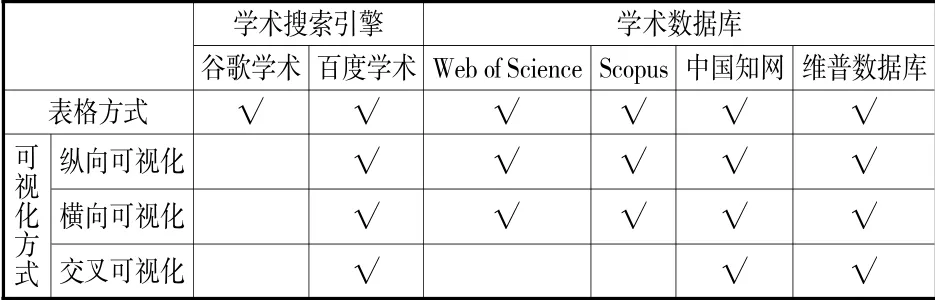
表3 学术搜索引擎和学术数据库的结果呈现方式

图 维普数据库的交叉可视化方式
4 总结与建议
4.1 总结
本文以多源数据——学术搜索引擎(谷歌学术、百度学术) 和学术数据库(Web of Science、Scopus、中国知网和维普数据库)为研究对象,从计量功能发展历程和功能比较两个方面分析学术搜索引擎与学术数据库文献计量功能的特点及其差异,发现目前学术数据库和学术搜索引擎的文献计量功能已发展至可视化和智能化阶段,而学术数据库的文献计量功能优于学术搜索引擎。
(1)计量功能的发展历程。学术数据库的计量功能起步较早,经历了简单排序计量、指数化和模型化、可视化和智能化三个阶段,结果呈现方式则从单一的表格呈现方式发展到可视化的呈现方式。相对而言,由于学术搜索引擎起步较晚,在学术数据库已有的文献计量功能基础上,其着重于深入挖掘文献内容,为评价学术影响力推出一系列评价指标。
(2) 计量功能的比较。① 数据来源。学术搜索引擎的数据来源多于学术数据库,但数据来源质量有待考量。②计量内容。一方面,学术数据库的计量内容种类多于学术搜索引擎,二者也越来越重视在大众社交类(如社交媒体的文献阅读数)、使用统计类(如下载次数) 数量的计量;另一方面,学术数据库与学术搜索引擎不断完善影响因子和h 指数的缺点,提出了5 年影响因子、h5 指数、半衰期、CiteScore等。③计算方法。学术数据库在简单计数统计和评价指标统计方面与学术搜索引擎相似,但在引文数据来源和评价指标统计时间范围与学术搜索引擎不同。④结果呈现方式。学术搜索引擎与学术数据库在表格呈现方式方面无差异,但在可视化显示方面存在显著差异。如,谷歌学术不包含可视化方式,而维普数据库包含纵向、横向以及交叉三种可视化方式。
4.2 建议
(1)加强社交媒体使用量的计量,以弥补被引量延迟问题。随着互联网的普及以及各种社交媒体软件的广泛使用,单一形式的文献传播方式已不能满足人们的需求,出现了多种形式的文献传播方式,如微信、微博、Twitter 等。因此,不能使用单一的被引次数来评价学术影响力,学术搜索引擎与学术数据库应加强社交媒体使用量等的计量,以此来弥补被引量延迟等问题,为全面地评价学术影响力提供数据支持。
(2)构建具有社会影响力的计量内容,深入探讨主体间的相关关系。学术搜索引擎与学术数据库均提供了一些计量内容,但某些计量内容在学术界并没有得到广泛使用,如百度学术的研究点分析。因此,学术搜索引擎与学术数据库需要构建具有社会影响力的计量内容,如,学术搜索引擎网罗文献信息的各个社交媒体使用数据(如微博等网站的阅读数),优先提供文献的社会影响力评价指标,为全面评价学术影响力提供数据支持;而学术数据库深入挖掘作者合作网络关系,为探讨新型作者合作模式提供参考借鉴。
(3) 深入挖掘文献知识语义,优化可视化方式。目前可视化技术比较成熟,但在学术搜索引擎中的应用范围较窄。未来学术搜索引擎需要加强可视化方式,多元化呈现计量结果,学术数据库要不断完善可视化技术,深入挖掘文献的知识语义,将可视化技术运用于显示各个知识元之间的相互关系,有利于系统更好地为用户提供知识服务以及帮助用户发现更多相关研究点,以拓宽研究思维。
