Bagging-SVM集成分类器估计头部姿态方法*
2019-11-12梁令羽孙铭堃李凤荣
梁令羽,孙铭堃,何 为,李凤荣
1.中国科学院 上海微系统与信息技术研究所 宽带无线移动通信研究室,上海 201800
2.上海科技大学 信息科学与技术学院,上海 200120
3.中国科学院大学,北京 100864
1 引言
近年来,头部姿态估计因其在人机交互、人脸识别[1]、虚拟现实以及疲劳监测[2]等领域的广泛应用而成为新的研究热点。头部姿态估计是指计算机通过对输入图像或者视频序列的分析、预测,确定人的三维空间中头部的位置以及姿态参量[3]。如图1 所示,如果将人的头部视为一个刚体,则可以通过俯仰角(pitch)、偏航角(yaw)、滚动角(roll)三个角度集合在一个固定的坐标系下描述刚体运动。

Fig.1 Angle of rotation of head pose in three dimensions图1 头部姿态在三维空间中的旋转角度
按照是否需要定位面部关键点,可以将头部姿态估计方法分为基于模型的方法(model-based method)和基于外观的方法(appearance-based method)[4]。基于模型的方法主要是通过检测头部形状以及人脸轮廓、眼角、鼻尖、嘴唇等面部特征点,构建几何模型或以其他方法来估计头部姿态。文献[5]提出了基于面部特征点的头部姿态估计方法,该方法计算简单,有着不错的准确率,然而估计头部姿态前需要手动提取面部区域,且易受到环境、遮挡等干扰因素影响。张万枝等人提出了一种基于面部特征三角形的机车驾驶员头部姿态参数估计方法[6]。该方法在定位眼睛位置、嘴巴区域,构建面部特征三角形的基础上,通过特征三角形的位置变化进行头部姿态估计。该算法的准确率依赖于对人脸特征点的定位精度,虽然可以获得连续的头部姿态估计值,然而准确率易受到遮挡、光照变化及较大头部偏转姿态等干扰因素影响。Derkach 等人提出基于SRILF(shape regression with incomplete local features)算法和基于字典的方法检测面部特征点[7],然后通过几何估计和外观估计的方法估计头部姿态,该方法对具有较大偏转范围的头部姿态估计问题表现良好,然而需要采集带有深度信息的头部姿态图片。
基于外观的方法主要是通过将未知姿态的图片与一组已标记图片数据集进行比较,通过测量未知姿态图片与已标记图片的相似性来确定所属的姿态。Huang等人利用监督局部子空间学习方法,从训练数据的HOG(histogram of orientation gradient)特征中学习局部线性模型来估计头部姿态[8],解决了少量训练样本拟合模型能力的不足,训练样本不均匀影响头部姿态识别准确率等问题。Yan 等人提出了一种基于多任务学习的头部姿态估计框架[9],将识别区域划分为密集的均匀空间网格,通过聚类的方法形成具有相似面部外观的区域并进行学习和识别,该方法解决了低分辨率情况下的头部姿态估计问题。文献[10]提出了一种自适应梯度的卷积神经网络方法,该方法对外观、环境变化、遮挡等干扰因素具有较好的鲁棒性。基于外观的方法不依赖于人脸特征点定位,将头部姿态的估计问题视作头部姿态的分类问题,通过训练-学习的方法获得人脸图像和头部姿态之间的对应关系,该类方法性能依赖于人脸样本好坏和学习模型的设计[11]。
将头部姿态的识别问题视为分类问题,分类器性能的高低直接影响头部姿态识别的准确率。针对离散化的头部姿态估计问题,常用的分类器包括线性判别分类器(linear discriminant analysis,LDA)、支持向量机(support vector machine,SVM)以及朴素贝叶斯分类器(naïve Bayes,NB)等[12]。然而这些分类器性能并不能满足对于头部姿态分类准确性的要求。此外,当面临视频图像中的复杂背景、光照变化等干扰因素影响时,头部姿态识别准确率会降低。本文提出了一种基于Bagging-SVM集成分类器来估计头部姿态算法,该算法在面对离散头部姿态识别问题时具有良好的识别效果,对光照变化等干扰因素具有较好的鲁棒性。
2 Bagging-SVM相关原理
2.1 支持向量机SVM
支持向量机SVM最开始是为了解决二元分类问题而被提出的,对于给定的二分类训练集D={(x1,y1),(x2,y2),…,(xm,ym)},其中y={-1,+1},算法的目的是寻找一个最优分类超平面wTxi+b,该分类超平面满足以下条件:
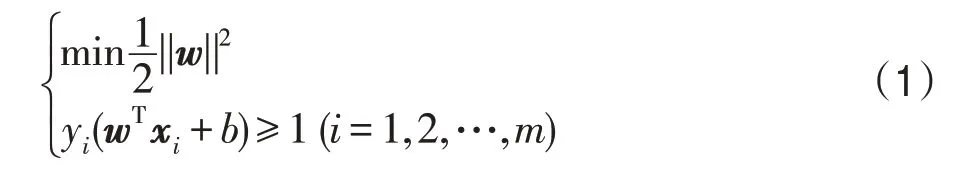
当样本线性不可分时,引入惩罚项C和松弛变量(slack variables)ξi≥0,那么满足最优分类超平面的条件变为:

式(2)是一个二次规划问题,根据最优化理论,通过使用拉格朗日乘子法将该优化问题转换为对偶问题来求解:
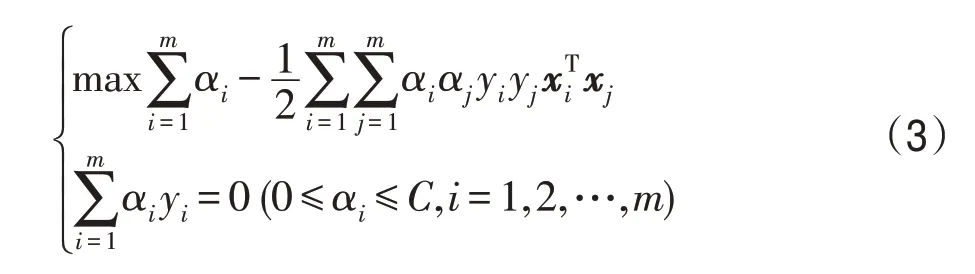

Fig.2 Support vector and margin图2 支持向量和间隔
本文采用的核函数为高斯核函数(Gaussian kernel),将样本从原始空间映射到高维空间中从而实现该特征空间内的线性可分。
2.2 Bagging-SVM基本思想
Bagging 的全称是Bootstrap Aggregating,算法基于自助采样法(bootstrap sampling),核心思想是采用有放回的采样规则[13]。所谓有放回的采样规则是指,在原始数据集里,随机取出一个样本放到新数据集中,然后将这个样本放回到原数据集后继续采样。对于一个含有m个样本的给定集合D,进行T轮采样,每轮采集n个数据(n≤m),从而构成T个采样子集Dk(k=1,2,…,T)。对T个采样子集分别对给定的基分类器进行训练,每个采样子集都会产生一个弱分类器φ(x,Dk),将T个弱分类器集成为强分类器φ(x,D)。测试阶段,强分类器的分类结果为T个弱分类器的简单投票结果,即投票中占多数票数的类别作为测试样本的类别。
由于Bagging算法的采样子集不同,因此每个采样子集训练出的基分类器具有差异。同时,有放回的采样规则保证了多个采样子集中有重复样本出现,为了避免每个基分类器只用了小部分训练数据导致训练效果不足的情况,增强了集成算法的性能。
Bagging过程实现如图3。

Fig.3 Flow chart of Bagging algorithm图3 Bagging算法基本流程图
3 基于Bagging-SVM的头部姿态估计
对于基于外观的估计离散化头部姿态的方法,通常将头部姿态识别视为分类问题,通过设计性能优良的分类器对头部姿态进行分类。本文设计了一种基于Bagging-SVM集成分类器算法来对头部姿态进行估计。本文算法的核心思想是:对于一个给定的训练集,该训练集进行T轮基于自助采样法采样形成T个训练子集,利用这T个训练子集进行SVM分类器训练,生成T个SVM弱分类器,最后基于简单投票的原则将T个弱分类器集成为强分类器。具体流程如图4。
在对图像进行分析前,为了减少复杂背景以及光照变化对头部姿态估计准确率的影响,首先需要对图像进行预处理和检测人脸区域。然后采用融合HOG特征和LBP(local binary pattern)特征对处理好的人脸图片进行特征提取,并利用主成分分析法对主元特征分量进行选择。最后将选择后的特征分量输入到Bagging-SVM集成分类器进行头部姿态估计。
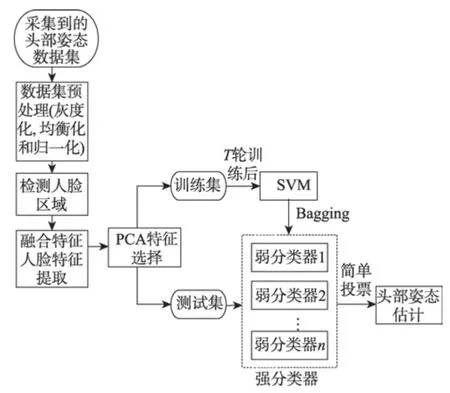
Fig.4 Flow chart of Bagging-SVM integrated classifier algorithm图4 Bagging-SVM集成分类器算法流程
3.1 数据预处理及人脸区域检测
在提取特征前,为了减少背景、光照等干扰因素对人脸特征选择的影响,通常需要对图片进行预处理以及提取人脸区域。本文采用的预处理方法主要包括图像灰度化、直方图均衡化以及图像归一化三个步骤[14]。经过预处理的图像像素点在颜色空间所占字节数降低,增强了图像对比度和灰度色调的变化以及提高了算法处理图片的速度。对于人脸区域的提取,本文采用基于Adaboost 检测人脸算法[15],该算法采用Haar 特征描述符表示人脸特征,通过选取的重要特征构造多个弱分类器。将多个弱分类器组合成若干个强分类器,使用若干个强分类器构造级联分类器。通过该级联分类器完成人脸区域检测。Adaboost算法不容易出现过拟合现象,具有高检测率和高时效性的特点。对于检测到的人脸区域,将其归一化处理成48×32像素大小的图像,方便接下来提取不同头部姿态中人脸特征。
3.2 融合HOG和LBP特征的人脸特征选择
3.2.1 HOG特征
方向梯度直方图(HOG)特征是一种用来进行物体检测的描述因子,主要通过统计图像局部区域的梯度方向直方图来描述图像特征[16]。在一幅图像中,梯度或边缘的方向密度分布能够很好地描述图像的局部目标的表象和形状。由于HOG特征是对局部区域求梯度特征值,因此提取HOG 特征对光照变化具有较好的鲁棒性。
首先,在提取HOG 特征前,采用Gamma 校正法进行颜色空间的标准化。其次,需要计算图片中每个像素点的梯度,包括梯度的幅度和方向。图像中像素点(x,y)的梯度为:
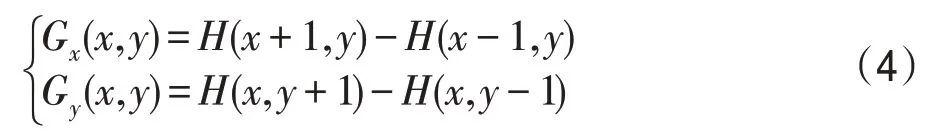
式中,Gx(x,y)、Gy(x,y)、H(x,y)表示像素点处的(x,y)水平方向梯度、垂直方向梯度和像素值。像素点(x,y)处的幅度值G(x,y)和梯度方向θ(x,y)为:

在完成图片像素的梯度计算后,将图像划分为若干大小相同的单元细胞(cell),在每个单元细胞内统计梯度信息。梯度方向范围为(0,π],量化区间个数为n,即由一个n维向量来描述每个单元格的梯度信息。将若干个相邻cell 组合成一个空间上连通的块区域(block),该block 的梯度特征为所有cell 的梯度特征串联后的结果。由于局部光照变化以及前景-背景对比度变化都会导致梯度幅度变化过大[17],因此需要对block 区域进行归一化处理。本文采用L2-norm归一化方法:
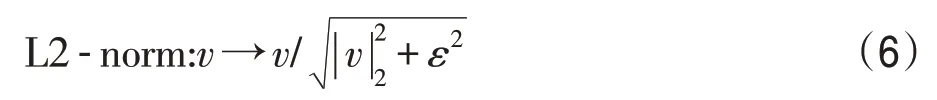
本文采取的cell 大小为6×4 像素,block 大小为12×8像素。针对不同维数n对头部姿态识别率的影响,在CAS-PEAL-R1 数据库上进行实验。结果如表1 所示,维度取9 时,识别率最高,因此将梯度方向量化为9 个区间,对于大小为48×32 像素的图片,HOG特征提取后的数量为576。
3.2.2 LBP特征
局部二值模式(LBP)是一种用来描述图像局部纹理特征的图像描述符[18]。该描述符以局部某个像素点的灰度值为阈值,与周围各个邻域像素点的灰度值进行比较。若大于阈值则标记为1,否则为0,得到的8位二进制数即为该点的LBP值。
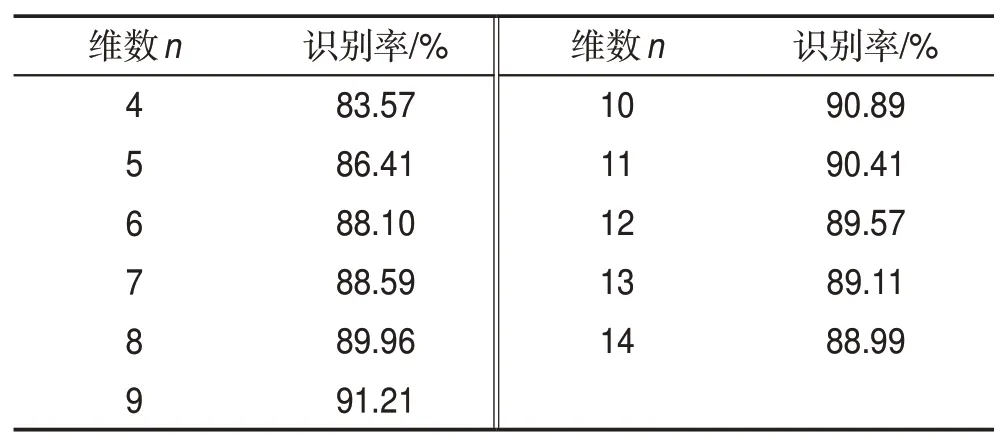
Table 1 Recognition rate based on HOG of different feature dimensions表1 不同特征维度的HOG识别率
如图5 所示,本文将图片分成8×8 个大小统一、互不重叠的图像子块。对每个子块的LBP特征进行直方图统计,直方图的量化区间个数选择为8。将所有子块的直方图特征级联成图像的特征向量,最终的特征向量的维数为512。
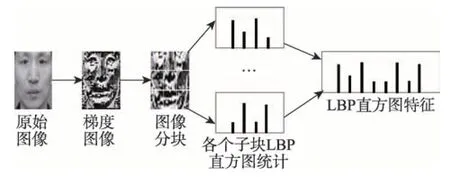
Fig.5 Feature extraction of LBP图5 LBP特征提取
3.2.3 特征融合
将HOG特征ζ1和LBP特征ζ2按照式(7)进行特征融合,得到融合特征向量Ζ,其中σ1和σ2分别为ζ1和ζ2的标准差。

3.3 基于PCA方法的特征提取
本文采用融合HOG 和LBP 特征对人脸图像进行特征提取后得到的特征向量的维数较大,因此需要对提取的图像特征进行特征选择,减少特征数量,增强模型的泛化能力。本文采用主成分分析法,通过线性变换将高维数据在损失最小的情况下映射到低维数据,从而达到降维的目的[19]。对于样本矩阵Dsample=[ξ1,ξ2,…,ξn],其中每个样本ξ都是原始灰度图像样本向量化得到的一维图像向量。利用式(8)中心化所有训练样本,即训练样本矩阵减去样本均值得到标准训练矩阵:
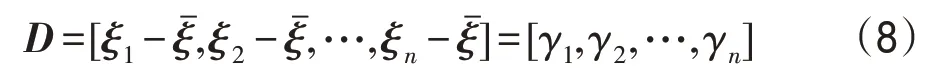

对协方差均值Σ做特征值分解,将求得的特征值按照从大到小的顺序排序可得特征值矩阵V=[λ1,λ2,…,λn],其中λ1≥λ2≥…≥λn。其对应的特征向量组P=[P1,P2,…,Pn]称为最优投影向量组。取最优投影向量组的前d个最大特征值的d个最优向量Pd=[P1,P2,…,Pd](d≤n)用于特征映射,Pd称为投影矩阵,也称特征子空间。利用式(10)可以将标准化后的人脸图像γn投影到低维空间,即可得到降维后的特征向量:

由于PCA(principal component analysis)降维维度对特征的表达能力差异较大,本文给出了不同维度下算法对头部姿态识别的准确率,结果如图6所示。

Fig.6 PCA dimension and head pose recognition rate图6 PCA维数与头部姿态识别率
从图6中可以看出,当维数为170时,头部姿态识别准确率最高,因此本文选择降维后的特征数为170。
经PCA特征选择后,将最终特征输入到Bagging-SVM集成分类器中进行头部姿态估计。
3.4 Bagging-SVM集成分类算法
在图像完成预处理,提取人脸区域以及选择好描述人脸区域的特征符后,采用Bagging-SVM 集成分类器对图片进行分类训练。在训练每个弱SVM分类器时,Bagging 的自助采样过程并不会抽取测试集中的所有图片。因此可以记录抽取出的图片,将剩余未被抽取到的图片作为验证集验证每个弱分类器的分类性能,从而提高集成分类器的性能。
Bagging-SVM算法伪代码如下:
输入:训练集S={(x1,y1),(x2,y2),…,(xm,ym)};基分类器算法H;支持向量机SVM;训练轮数T
1.fort=1,2,…,Tdo
2.Strain,Stest←S
Bagging 从训练集中有放回地抽样,其中Strain为抽出的训练样本,Stest为未抽出的用于验证弱分类器性能的测试样本
3.ht=H(Strain)|ht←Stest
测试样本准确率>0.5则保留该分类器,否则重新训练
4.end for
即多个弱分类器简单投票。
假定弱分类器的计算复杂度为Ο(m),采样和投票/平均复杂度为Ο(s),则本文算法复杂度为Τ×Ο(m)+Ο(s),考虑到采样和投票/平均复杂度Ο(s)较小,Τ通常是一个不太大的常数,因此本文算法与直接训练一个弱分类器的复杂度同阶,是一个很高效的集成算法,较好地适用于多分类、回归等任务。
4 实验结果与分析
4.1 实验数据集准备
本实验采用的数据集为Pointing'04 数据集和CAS-PEAL-R1数据集。Pointing'04数据集由15组图像组成,每组图像包含两个系列的93 张不同姿态的同一人图像。每组图像的不同系列差别包括衣物颜色不同以及有无眼镜等。头部姿态方向包含俯仰角(pitch)和偏航角(yaw)两个方向,其中俯仰角包含{-90,-75,…,75,90},共计13 个离散姿态,偏航角包含{-90,-60,…,60,90},共计9 个离散姿态。CASPEAL-R1数据库由1 040名志愿者,每人21张头部姿态图片,共计21 840 幅图像组成。每个志愿者头部姿态包括抬头、平视、低头3个离散俯仰角的姿态以及7个离散的偏航角的姿态。部分数据库图片如图7。

Fig.7 Part of experimental head posture library picture图7 部分实验用的头部姿态库图片
由于这两个数据库头部姿态旋转的角度并不相同,且实际应用中判断头部姿态处于低头或抬头等动作相比判断头部姿态具体角度更有意义。因此人为设计了9种姿态来进行分类和识别,头部姿态与对应角度如表2。
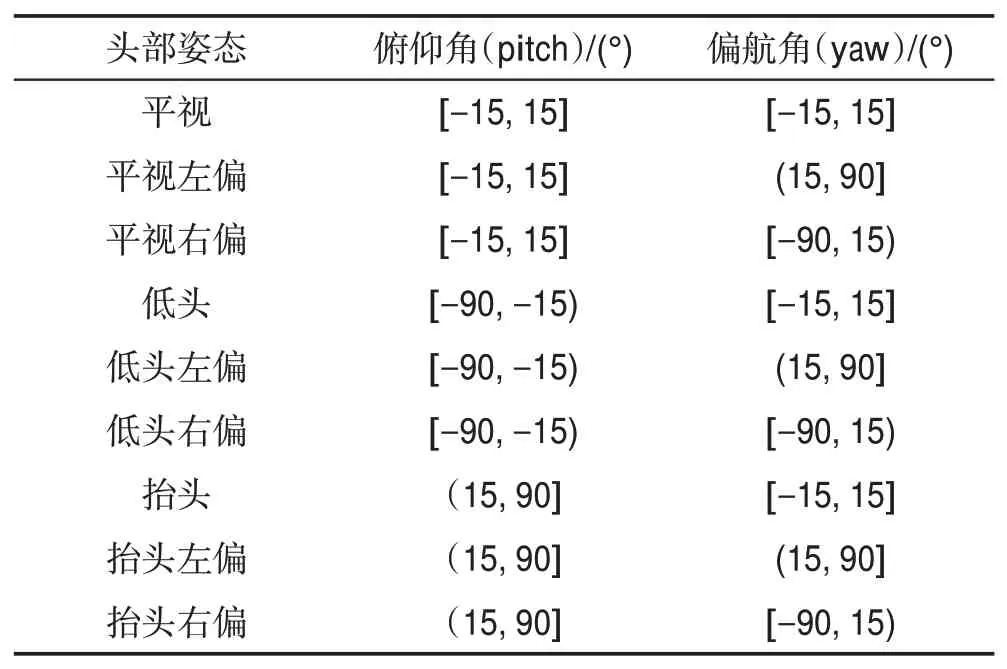
Table 2 Head pose and angle表2 头部姿态及其对应角度
实验采用Python3.6 环境编程,计算机型号为Macbook Pro 13.3,处理器为2.7 GHz Intel Core i5,内存为8 GB 1 867 MHz DDR3。对于数据集选择,本文选择了Pointing'04数据集的全部图像和CAS-PEALR1数据集编号为102到900的图片。
4.2 分类器评价指标
为了更好地评价实验结果,本实验采用准确率(Precision)、召回率(Recall)和F1 值(F1-score)作为算法性能的评价指标。先定义机器学习基础评价-混淆矩阵,定义1为正类,0为反类,如表3。
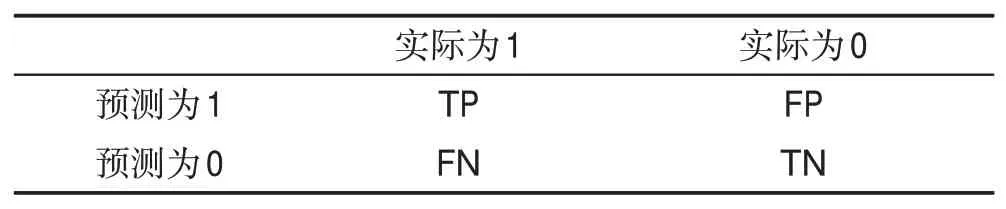
Table 3 Confusion matrix表3 混淆矩阵
根据表3,各个评价指标定义如下:
准确率:用来表示被正确识别的图片和被错误识别的图片数量之比。

召回率:用来表示被正确识别的图片和实际图片数量之比。

F1值:为准确率和召回率的调和平均值。

4.3 实验结果
由于人脸区域检测相关研究和应用非常成熟,且不是本文重点,因此本文采用文献[15]提供的方法完成对人脸区域的检测和提取,并归一化到48×32大小的灰度图片。人脸区域提取的图像如图8。

Fig.8 Face area images after extraction图8 提取后的人脸区域图像
为了验证本文提出算法具有较好的性能,本文选择了K-邻近(K-nearest neighbor,K-NN)、线性判别分类器(LDA)、朴素贝叶斯(NB)以及支持向量机(SVM)等分类器作为对比实验。表4 和表5 分别对比了不同分类器在CAS-PEAL-R1 数据集和Pointing'04数据集上头部姿态识别准确率。从表中结果可以看出:
(1)与HOG 特征和LBP 特征相比,本文提出的融合HOG和LBP特征具有更高的头部姿态识别率。
(2)经过PCA 特征选择后的头部姿态识别率相比于不进行特征选择的头部姿态识别率更高,在各个分类器的识别准确率都有提升。说明经过PCA特征选择能够进一步提高系统的头部姿态识别能力。
(3)本文提出的Bagging-SVM 分类器相比其他常用的分类器在两个数据集上都有更好的性能。相比识别率最低的K-NN算法在CAS-PEAL-R1数据集和Pointing '04 数据集的识别率分别为88.32%和86.78%,本文提出的算法识别率为96.41%和93.21%,提高了8.09%和6.43%。相比识别率最高的SVM 算法在CAS-PEAL-R1 数据集和Pointing '04 数据集的识别率分别为93.57%和91.33%,本文算法提高了2.84%和2.09%。
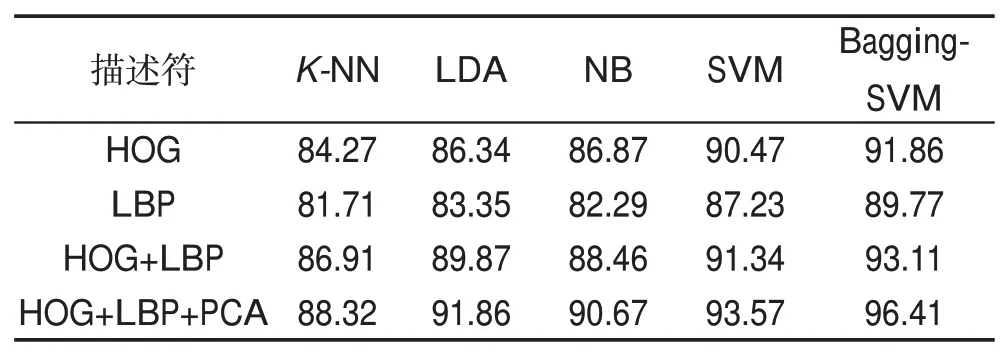
Table 4 Test result of different classifiers on CAS-PEAL-R1 dataset表4 不同分类器在CAS-PEAL-R1数据集测试结果 %
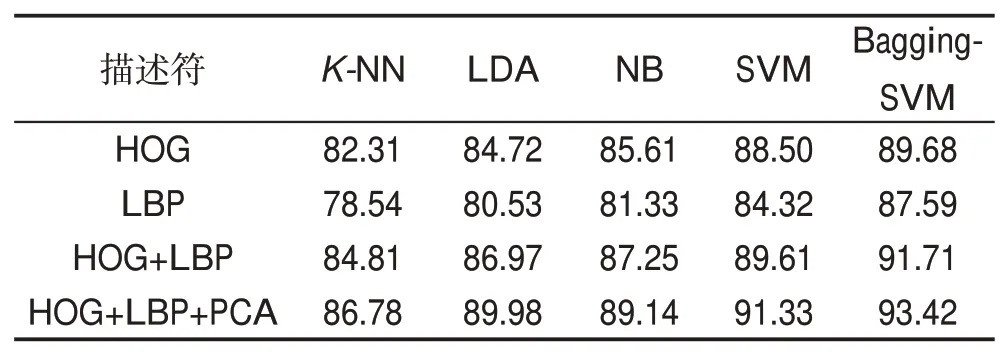
Table 5 Test result of different classifiers on Pointing'04 dataset表5 不同分类器在Pointing'04数据集测试结果 %
表6 和表7 分别对比了本文算法与近年文献提出的算法在Pointing '04 数据集和CAS-PEAL-R1 数据集上所取得的实验结果。实验结果表明,本文提出的算法性能在两个数据集上均好于近年来一些研究成果,说明本文算法对于头部姿态的估计达到了不错的效果。
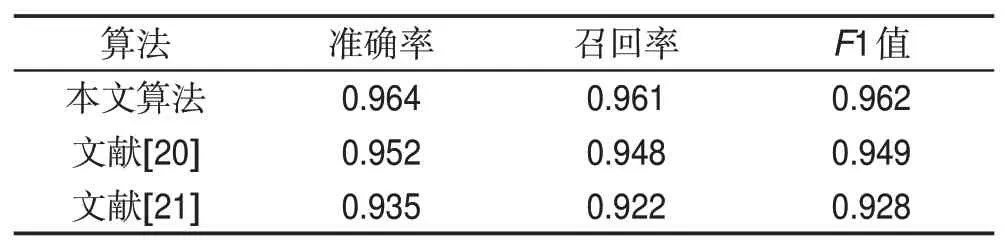
Table 6 Result of different methods on CAS-PEAL-R1 dataset表6 不同方法在CAS-PEAL-R1数据集结果

Table 7 Result of different methods on Pointing'04 dataset表7 不同方法在Pointing'04数据集结果
为了验证本文算法对光照干扰具有良好的鲁棒性,实验采集了35名志愿者在强光照、弱光照和正常光照条件下各9种姿态,共计945张实验图片。部分图片如图9。

Fig.9 Partial head posture picture under different illumination图9 不同光照条件下部分头部姿态图片
图10为不同光照强度下本文提出的算法在各个姿态上识别准确率。从图中可以看出,强光照和弱光照与正常光照趋势大致相同,说明强、弱光照对各种头部姿态识别准确率的影响不大。3 个折线波动较为平缓,说明本文提出的算法在各个头部姿态上都具有较好的识别性能。
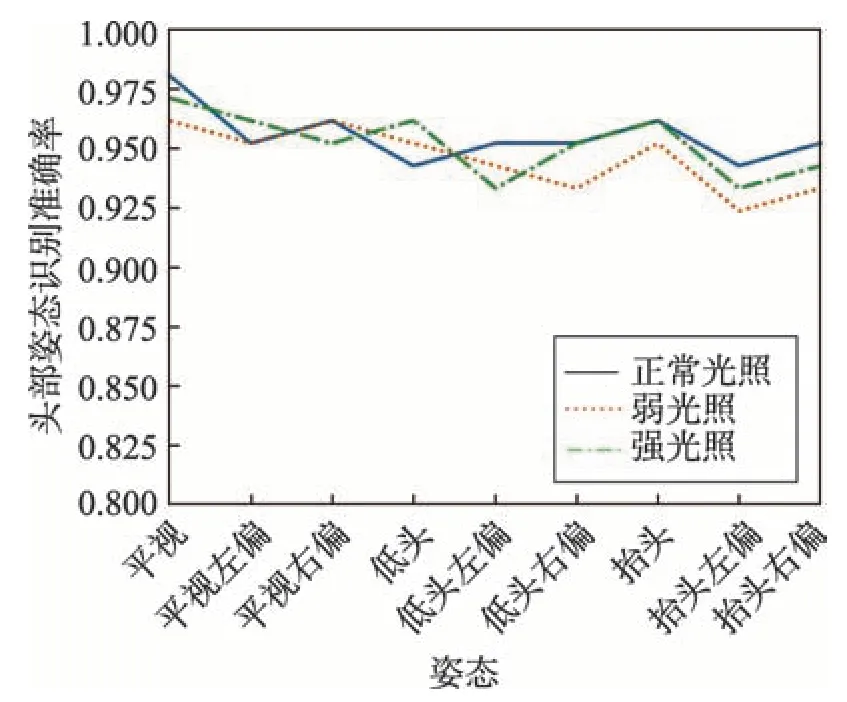
Fig.10 Recognition accuracy of each gesture under different illumination图10 不同光照强度下各个姿态识别准确率
5 结束语
本文提出了一种基于Bagging-SVM集成分类器进行头部姿态估计的方法。该方法通过提取融合的HOG和LBP人脸特征,并引入PCA变换进行特征选择。用设计好的Bagging-SVM集成分类器对特征进行训练。在Pointing'04 数据集、CAS-PEAL-R1 数据集和自建数据集上进行验证实验,实验结果表明相比常用的分类算法和近年最新算法,本文提出的算法具有更好的性能,并对光照变化干扰具有较好的鲁棒性。
