图像显著性传播及约束的协同显著性检测*
2019-11-12赵悉超刘政怡
赵悉超,刘政怡,李 炜
1.安徽大学 计算智能与信号处理教育部重点实验室,合肥 230601
2.安徽大学 计算机科学与技术学院,合肥 230601
3.安徽大学 信息保障技术协同创新中心,合肥 230601
1 引言
在过去几年中,人们一直在探索人类的视觉注意力机制,并在这一领域做出了很多卓著的工作。其中的显著性检测是使机器视觉系统具有这样的能力,即自动地选择单个图像中的显著区域。然而,随着大规模的图像数据和无处不在的互联网时代的到来,使得人们的注意力从单一图像转移到图像组[1]。协同显著性检测是突出显示图像组的共同的前景对象[2],它是视觉显著性检测的一个新分支,并且是一个具有挑战性的任务,因为单个图像中的特定显著对象在图像组中可能不够突出。协同显著区域具有两种性质:(1)每张图片的协同显著区域与其周围相比应该具有较强的局部显著性;(2)所有的协同显著区域应该是相似的[3]。协同显著性检测近年来得到了广泛的研究与应用,例如图像/视频协同分割[2]、视频兴趣动作提取[4]、图像/视频协同定位[5]。
协同显著性模型从检测一对图像之间的协同显著对象开始。文献[6]利用显著对象引起的局部结构变化来获得协同显著性,从而获得图像对的协同显著图。在文献[7]中,协同显著性被表述为使用三个可用显著性模型的单幅图像显著性图和基于多层图的多图像显著性的组合。协同显著性检测不限于图像对。在文献[8]中,使用聚类性对比线索和空间线索用于检测协同显著区域。Li 等人[9]将区域级融合和像素级细化相结合,以生成最终的协同显著图。而协同显著性检测方法[7-9]将协同显著物体检测问题转化为图像对显著性传播问题,该问题利用每对图像之间的相似性,在一张图像的显著图的指导下寻找另一张图像中与其具有共同属性的区域。文献[10]通过将改进流形排序算法引入图像显著性检测模型中,生成协同显著图。文献[11]介绍了通过融合前景和背景先验生成协同显著图的方法。Yu等人[12]提出了一种新的自下而上的方法来检测图像协同显著值。当然,关于学习方法在协同显著性检测领域也取得了许多成就,如Zhang等人提出的文献[4,11,13]分别以自适应多实例学习和深度学习进行协同显著检测;文献[14]则采用端到端的群组式完全卷积网络进行协同显著性检测;而文献[15]则是通过结合深度学习和种子传播方式进行协同显著性检测;文献[16]将对象级和区域级处理相结合,以检测一组图像中的协同显著对象;文献[17]则是将协同显著性检测分解为两个子问题,通过两阶段多视图光谱旋转共聚类。这些文献都不同程度上获得一定的效果。
尽管上述基于种子传播与图模型的协同显著性检测方法获得了优异的性能,但它们有两个主要缺点:(1)准确的种子点是模型预测的基石,然而对于处理真实世界图像时,由于图像组中图像随着光照、视角等条件变化时,容易出现混淆前景和背景的情况,传统显著性检测方法不可避免地获得不准确的显著种子点,错误引导了传播算法,限制了协同显著性检测的性能。(2)现有的方法都是模拟节点对之间的关系,忽略了多个顶点之间的高阶信息,导致顶点之间的关系可能是次优的,以及显著性种子点在不完备的节点关系中传播,限制了协同显著性检测的性能。
为了克服这些缺点和限制,本文提出了一个基于超图的种子点传播的协同显著性检测框架,所谓超图是有别于传统的图的构造,图像的边构造基于一定的规则,这部分内容会在后面文章做详解。该无监督的检测方法主要基于两个人类先验,即前景的图像间一致性和图像内凸包约束性。本文的算法框架如图1 所示。从左到右依次是:首先,不可忽视深度学习技术在显著性检测领域中的快速发展,本文利用深度学习技术获取显著性检测的更加精准的显著种子点;其次,提取每个超像素的特征以构建超图模型,超图的高阶信息捕获了更全面的上下文信息,因此提高了检测协同显著对象的能力;然后,每张图像通过其他n-1 张图像对其显著性传播生成该图像的协同显著图组,其个数为n-1 张;接着将该图像自身的显著图与上述生成的协同显著图组经过融合,获得初始的结果;最后,利用图像内显著性约束抑制背景,增强前景,提高协同显著性检测模型的性能,融合两者的显著图获得满意的结果。本文的主要贡献为:
(1)提出了基于相似性的显著性传播方案的协同显著性检测,然后是精确的查询,其带来深层次信息以发现显著图的更高级属性,并且将超图建模引入到协同显著性检测的过程中。超图是一种丰富的结构化超像素图像表示,通过它们的上下文而不是它们的个体值来建模。
(2)基于具有兴趣点的图像内约束来估计显著对象的空间位置带来的位置信息,以抑制非常见部分与真实场景中被错误恢复的背景。
(3)在Cp和iCoseg基准数据集进行实验,并与其他先进方法比较,证明了本文方法的优势。
接下来在第2章中详细介绍本文的方法,并在第3章中给出相应的实验结果分析。
2 本文方法

Fig.1 Algorithm framework图1 算法框架
2.1 超图构造
在本文提出的方法中,每个超像素充当一个顶点,构造超图G=(V,E,w)来表示超像素之间的高阶关系,其中顶点集合定义为V,超边集为E。
超边的权重是一个恒正的值,定义为W(e)。超图的关联矩阵H可以定义如下:

其中,关联矩阵H的维度为|V|×|E|,它的含义是表示顶点属于哪个超边,因此它可以表示顶点和超边界之间的关系。在本文的协同显著性超图模型中,将每个顶点作为“质心”,并使用基于Lab特征描述符计算的相似性距离。每个“质心”vi依据相似性距离选择与其连接的k个邻近顶点vj所在的超边ej,同时连接的权重被赋予二值化描述非1 即0,从定义可以看出,超边的权重w(ei)恒为常数k。依据关联矩阵,如下公式将定义每个顶点的度d(v)和超边的度δ(e)为:
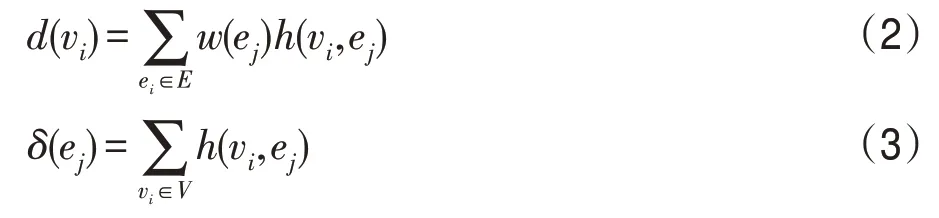
设D(v)、D(e)、V分别代表顶点度矩阵、超边度矩阵以及超边权重。传统的图模型(成对节点表示)是超图模型的一种特列,当超图模型中每个超边仅含有两个节点时就是传统的图模型。图2 展示了超图模型的一个示例,直观地解释了如何构建超图模型。图中的二维空间中展示了7个点,并将它们分配给7个超边。左侧是传统图模型,其中两个节点通过边相互连接;中间图表示同样的节点用超图的关系,表达模型超边取最近临近k=2;右侧是中间超图对应的关联矩阵,如果超边界ej包含vj,则将关联矩阵H(i,j)设置为常数1,反之为0。不同于成对节点不能很好地挖掘节点与节点之间以及节点与边之间的关系,超图可以根据关联矩阵将节点群包围成一个紧密联系的子集合即为超边。因此,超图能够发掘隐藏在节点中的丰富信息。

Fig.2 Example of hypergraph and its corresponding hypergraph matrix H图2 超图及其对应的超图关联矩阵H示例
2.2 基于超图的种子传播算法
协同显著性检测的目的是提取相关图像中的协同显著区域。协同显著区域不仅在每个单独的图像中显著,而且通常出现在一组相关图像中。因此,“显著”和“协同”是共同反映协同显著性j的定义的两个关键属性。将协同显著性检测重新定位为简单分类任务,即将图像中的每个区域/超像素分类为协同显著区域还是非协同显著区域。本文提出的算法首先使用预先训练的深度显著性检测模型为每个图像生成单显著图Tˉ。然后使用超像素分割算法(SLIC)将图像组分割为一组超像素。设为m-th 图像的k-th超像素显著值,其由超像素对应的像素值的平均值计算而来。r(v)和r(u)分别是顶点v和u的协同显著分数,其中r∈[0,1]。定义查询向量y=[y1,y2,…,yu,…,yz]以引入超像素的标记信息并将其初始显著性标签分配给y的相应元素。y(u)是顶点u的标签值,其中假设第i张图像为查询图像,则若节点,则y(u)=1 是指第v个超像素是显著节点,标签为1,反之亦然。若节点u属于待预测图像中的超像素则也赋值为0。h(u,e)和h(v,e)分别表示u和v是否属于超边e。w(e)/δ(e)可以被看作是超边e的归一化权重。协同显著性分数预测值r(u)可以通过以下公式预测得到:

从公式中可以看出,第一项是指两个顶点v和u属于同一超边的概率比较高,并且这些超边具有较高权重,则这些顶点的协同显著性值应该更接近。第二项是流行排序项,是指最终预测的标记节点的值应该逼近原始查询的标签。为了最小化代价函数,通过以下公式求解最优值r:

其中,类比于标准图拉普拉斯矩阵来定义超图拉普拉斯矩阵[10,18]为在获得Γ之后,预测标签r可以由以下公式求得:

其中,I是维数等于总节点数的单位矩阵,α是权重参数,在实验中将其设置为0.5。直接将每个显著图中的超像素的标签构成查询向量,预测剩余图像的节点标签,即r向量。总之,查询y非常重要。不准确的查询可能导致不满意的结果。在这项工作中,深入考虑了查询点在计算超像素的协同显著性传播时的重要性,因此采用深层的基于深度学习的显著性网络生成显著图,学习准确的查询点标签向量y以提高协同显著性检测性能。
对于传统的图模型来说,简单地将超图的拉普拉斯矩阵转移为简单图拉普拉斯矩阵可以实现转移学习。超边结构本质上含有两个或两个以上超像素上的内在联系信息。即,如果两个超像素在多个超边中具有较高的出现频率,则它们倾向于共享更多的视觉特性并且具有更高的视觉相似性。在本文的实验部分中,直观地比较了基于传统图模型的协同显著性检测和本文方法的性能。从中可以看出后者更有效。
本文通过上述方法获得了显著种子传播图。众所周知,如果超像素是共同显著的,它将在大多数显著种子传播图中出现更多的频率。基于此原理,融合公式定义如下:
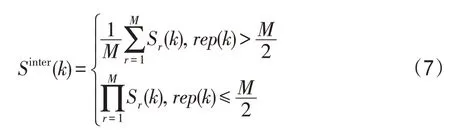
其中,M是一组中的图像数。rep(k)被定义为计算超像素k在M个图像中被分类为共同显著的次数。对于一张图像来说,该策略将来自于不同查询图像对该图像利用上述算法引导生成的M-1张图像以及自身的显著图进行融合,获得精细的协同显著性结果。
2.3 图像内显著性约束
如图1 所示,图像间协同性检测传播图,独立计算每个超像素的协同显著性得分,缺乏完全抑制背景的能力。在图像内显著性约束部分,主要关注如何抑制由上述方法产生的具有高显著分数的背景节点。由于每个图像不仅包含每个超像素的特征信息,还包含节点的空间分布之间的相互关系。因此,设计了改进的凸包方法[18]以获得空间分布图。最优的凸包应该能够提供显著对象的粗略位置。首先计算一个包围兴趣节点的凸包,以估计显著区域的位置。然后使用凸包的边缘作为起点来获得基于凸包的空间兴趣点分布图。通过以下公式生成图像中超像素的显著性值:
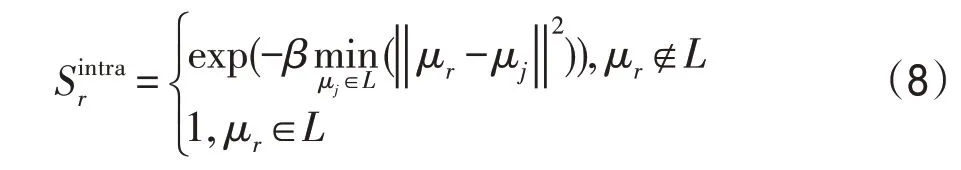
其中,μr表示第r个超像素的平均位置,μr是RGB图像中的上述显著部分的空间分布的边界点。从方程(8)中可以发现,当值距离凸包中的最近点时,它的值更小。
最后结合基于超图的跨图像显著性传播和图像内显著性约束来融合生成图像的最终协同显著图:

如果超像素r属于协同显著对象,则预测值接近1,如果被视为背景,则接近0。最终结果在增强和抑制背景方面获得了显著的提高,达到了最接近人类视觉系统观测的结果。
2.4 算法流程
本文的算法流程如下所示:
初始化:
通过式(1)计算超图G的关联矩阵H;
通过式(2)计算超图节点度矩阵D(v);
通过式(3)计算超图边度矩阵D(e);
通过式(6)预测未标记标签的协同显著值;
通过式(7)融合生成的M-1 张图像以及自身的显著图,得到图像间协同显著图Sinter;
通过式(8)得到图像内协同显著图Sintra;
通过式(9)融合图像间和图像内的协同显著图,得到最终的S协同显著图。
3.结束。
3 实验与比较
3.1 数据集与评价标准
在两个基准数据集上评估了所提出的算法:Cp数据集[19]和iCoseg 数据集[20]。前者包含105 个图像对,后者包含38个图像组,总共643个图像。类似于文献[20-21],采用4 个标准来评估本文方法的性能,即PR(precision-recall)曲线、ROC(receiver operating characteristic)曲线、F-measure 曲线、MAE(mean absolute error)。PR 曲线、ROC 曲线和F-measure 曲线是由一系列阈值T生成,阈值T在0到255之间变化。
3.2 实验细节
实验中,每个图像利用SLIC算法分割为ni个超像素块,其中SLIC 算法的初始分割数量预定义为200。在显著性检测数据集(DUT-OMRON,MSRA10K)上预训练的深度学习网络DHSnet网络被用来生成初始显著图,式(4)中μ=1。
3.3 Cp数据集的评估
使用所提出的模型来生成Cp数据集上的协同显著图。将所提出的模型与三种较先进的协同显著性检测方法进行比较,即CG[19]、CB[8]和EMR[10]。对于主观评价,图3 中显示了部分实验示例,其中包含4 个图像组中的示例,即鳄鱼、狗、交通标志和公共汽车。比如CB 无法检测出协同显著区域的轮廓如前两列的鳄鱼检测效果,而EMR 方式存在错误抑制协同显著区域如后两列卡车的检测效果图,CG存在显著值不平滑问题,可以看出,本文提出的框架明显提高了协同显著性检测的性能。
对于定量评估,实验结果如图4 所示。对于Fmeasure曲线纵轴表示F-measure值,横轴表示[0,255]阈值。与其他方法相比,本文的PR曲线和ROC曲线是最优的。此外,本文模型中的F-measure的最高得分为0.9,并且在大部分区间内[0,240]取得了最高的F-measure值。此外,如表1所示,本文所提出的方法获得最低的MAE分数。因此本文提出的框架相比于其他的现存方法在4种评价指标上均有明显提高。

Table 1 MAE scores on Cp dataset表1 Cp数据集上的MAE对比
3.4 iCoseg数据集的评估
对于另一个广泛使用的iCoseg 数据集,相比Cp数据集,本文方法在主观性和客观性方面与8个现存流行的协同显著性检测模型进行了比较,因为这些方法相关作者已提供相关结果集或代码,包括HS[7]、CB[8]、EMR[10]、CSLDW[4]、CSDR[22]、SP-MIL[13]、TS[16]、MVSRC[17]。两个图像组的示例结果如图5所示。前一组的协同显著目标是一只隐藏在灌木丛中的豹子,即使人眼也很难在豹子和灌木丛之间做精确的细节和边缘区分,但是本文方法可以有效地勾勒出来豹子的边缘。对于后一组,协同显著对象是在操场上玩耍的女孩们,从图像组中可以看到橙色和黑色经常出现在女孩的衣服和背景中。基于低级特征的传统方法不足以区分前景和背景,导致协同显著性检测结果令人不满意。而从图5中可以看到,本文方法达到了与真实的标签图像最接近的结果。从HS和CSLDW 的效果图可以看出这两个方法都没能把非协同限制区域抑制住,导致协同显著区域的轮廓未能检测出来。CB将大部分背景区域抑制了,但是同时也将协同显著区域也抑制住了,EMR 缺点是对非协同显著区域的抑制不够充分,CSDR会错误将协同显著区域抑制住,而本文方法的效果图要好很多。由于SP-MIL、TS、MVSRC等相关文献工作者未能提供代码或结果集,因此未能实现质量效果对比及绘制相应的PR曲线和ROC曲线。

Fig.3 Comparison effect of 4 detection models on Cp dataset图3 4种检测模型在Cp数据集上的对比效果

Fig.4 Comparative experiment of 4 detection models on Cp dataset图4 4种检测模型在Cp数据集上的对比实验
对于定量评估,使用PR 曲线、ROC 曲线和Fmeasure测量曲线,如图6所示。虽然本文PR曲线和ROC 曲线并不总是超过其他曲线,但它们在很宽的阈值范围内都表现很出色。对于F-measure测量,本文模型实现了最高的F-measure 值为0.88,而算法模型HS、CB、EMR、CSLDW、TS、SPMIL、MVSRC、CSDR的F-measure值分别为0.755 1、0.754 1、0.819 4、0.798 5、0.834 0、0.814 3、0.810 0、0.817 6。结果表明,本文方法具有一定阈值的显著对象分割的最佳性能。此外,从表2中可以看出,与其他方法相比,本文模型中MAE的值显著降低。

Fig.5 Comparison effect of 6 detection models on iCoseg dataset图5 6种检测模型在iCoseg数据集上的对比效果

Fig.6 Comparative experiment of 6 detection models on iCoseg dataset图6 6种检测模型在iCoseg数据集上的对比实验
3.5 实验结果分析
本节实验用来展示框架中每个部分的效果。为了公平起见,实验中只进行了一个因素的更改。从图7 和表2 中可以看到:(1)与基于像素级别的方法EMR 相比较,所提出的具有超像素级别(Proposed-NS)的框架的性能取得了更好的结果。(2)在不使用深度学习单显著性模型(Proposed-ND)来产生初始显著性查询的情况下,本文提出框架(Proposed)的MAE得分从0.085大幅增加到0.147。(3)相比基于标准图模型协同显著性检测方法(Proposed-NHG),在结合超图后,本文提出的方法3个评估指标得到显著提高。(4)相比没有图像内的凸包约束的模型(Proposed-NIMC),本文提出协同显著性检测方法获得更高的性能。它可以抑制远离凸包的背景区域并增强前景区域。除此之外,虽然所提出的没有图像内空间分布约束(Proposed-NIMC)的模型比Proposed更差,但它仍然获得了比其他现有方法更令人满意的性能。
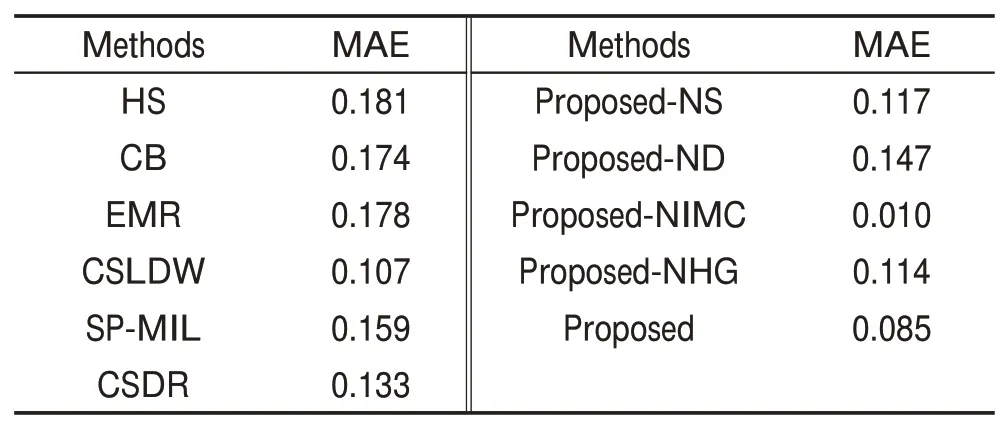
Table 2 MAE scores on iCoseg dataset表2 iCoseg数据集上的MAE对比
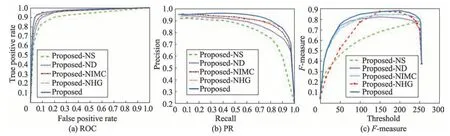
Fig.7 Comparison of algorithm models on iCoseg dataset图7 在iCoseg数据集上的算法模型分析对比
4 结束语
本文提出了一种新颖而有效的协同显著性检测方法。设计了一种图像间显著性传播和图像内的位置约束条件,通过融合两者的结果最终产生了基于超像素级别的协同显著性检测结果。两个基准数据集的定性和定量评估也表明,所提出的协同显著性模型优于较先进的协同显著性检测模型。在以后协同显著性检测的研究过程中,可以通过深度学习框架提取更深层次的特征,或者提取能体现一组图像中的协同信息的特征,这样再结合本文算法进行构图,最终的实验效果会更好。
