分位贸易引力模型及其EM算法分析
2019-11-11王婷婷秦琳杰
王婷婷,秦琳杰
(华侨大学 统计学院,福建 厦门361021)
一、引 言
随着经济全球化和贸易自由化成为世界经济发展的主潮流,世界经济发展越发达,国家与国家(地区)之间的贸易规模也越大,贸易程度也逐渐加深。据2018年发布的《世界贸易投资报告》估算,2017年全球贸易出口额为17.316 2万亿美元,较上年相比增长10.5%,这是自2011年以来上涨幅度首次突破10%。其中,2013年“一带一路”倡议的提出,推动了沿线国家对外贸易的发展,《“一带一路”贸易合作大数据报告(2018)》数据显示,2017年“一带一路”沿线国家对外贸易总额为9.3万亿美元,占全球贸易总额的27.8%。对外贸易的研究中,贸易引力模型的理论基础得到不断完善,众多学者在经济学的基础上验证了贸易引力模型的合理性,Deardorff等学者验证了该模型在国际贸易问题中的适用性以及实用性[1-3]。众多研究都是在基础贸易引力模型上添加或者删减解释变量,用来研究各变量对贸易的影响。例如,方英等的研究说明了基础模型存在未观测数据的情况[4],即存在隐变量,并且已有的实证研究中参数的估计基本上只是基于最小二乘方法,不考虑隐变量情况而直接采用最小二乘法进行参数估计得出的结果存在偏误。另一方面,回归模型是在平均意义上的研究,这些结果不能全面地反映双边出口贸易额,不能有效揭示双边出口贸易在不同水平的受影响程度。
基于以上分析,本文选取45个国家的双边出口贸易数据,在基础贸易引力模型的理论基础上引入考虑隐变量的分位回归的思想,从而分析国家间距离以及国家经济规模对双边出口贸易额在不同分位点的影响。EM算法在存在隐变量的问题研究中具有计算简便、估计结果性质优良的优点,因此本文结合EM算法对分位贸易引力模型的参数进行估计,并应用数据进行实证分析。
二、文献综述
Tinbergen和Poyhonen提出贸易引力模型,该模型的基本理论是指一国与另一国的贸易流量与两国各自的经济规模成正比,并且与两国之间的距离成反比。该模型得到广泛应用得益于其具有经济理论基础,如Deardorff基于H-O模型从无摩擦和有摩擦贸易两方面推导了贸易引力模型[1],Evenett等分别从李嘉图模型、H-O模型、规模报酬模型、IRS模型四个方向推导出了贸易引力模型[3]。随后,贸易引力模型成为研究对外贸易的一种流行工具。在关于出口贸易的分析中,众多学者利用贸易引力模型进行分析,这些研究都验证了距离以及国家经济规模对出口贸易存在显著影响,并且更多学者采取在基础贸易引力模型基础上增加解释变量进行研究。关于新增加的解释变量可以分为两大类:一类是逻辑型的变量,如贸易便利化、人口变量、价格变量、贸易壁垒变量、经济距离、技术距离等;另一类是外延型的变量,如是否拥有共同语言、是否具有共同边界、是否缔结区域贸易优惠协定、是否为内陆国等因素。方英等对2011—2015年中国与“一带一路”沿线64个国家的文化产品出口贸易流量进行分析,实证结果表明,自由贸易协定、关税、人口是影响文化产品出口贸易流量的显著变量[4];田晖等利用中国与42个贸易国家的文化产品出口数据进行分析,认为市场规模、人均国民总收入、劳动生产率、自由贸易协定正向影响中国文化出口[5];张萌等就优惠贸易制度安排、是否具有共同边界、是否为环海国家三个虚拟变量对农产品出口贸易流量的影响进行分析,并认为三个因素对出口贸易流量具有显著影响[6];Laurent利用1948—2012年的全球面板数据构建贸易引力模型,并以“一个中国”政策作为虚拟变量加入模型,得出该政策改善了中国大陆的双边贸易流量[7];Chandran选用650对国家17年的面板数据,采用引力模型研究FTA对贸易流量带来的影响[8]。以上的研究都验证了距离以及国家经济规模对贸易产生了显著影响,再加入其他影响因素,其他不可观测的因素则被纳入到随机扰动项,并采用传统最小二乘方法进行估计,这会导致模型的估计存在偏差[9]。同时,基础贸易引力模型是以“均值”这一理念进行分析,不能体现解释变量在不同分位点的影响,而分位回归模型则是基于线性关系假设的前提,采用残差加权绝对值之和最小化的规则,得到模型在任意分位点处的回归结果,其分析结果表明分位回归模型可以在误差项不满足正态分布时依旧是稳健的,并且在该情况下构造的检验统计量更加具有有效性[10]。因此,本文在基础贸易引力模型的基础上,结合分位回归的理论框架,构建分位贸易引力模型,研究解释变量在不同分位点对贸易出口额的影响。
在采用分位贸易引力模型分析时,参数估计的方法会决定该分析是否有效。在针对分位回归模型参数估计的研究中,Kottas等通过在分位回归模型中应用独立Dirichlet过程,结合马尔科夫蒙特卡洛方法(MCMC)进行后验概率密度推断,最终提出贝叶斯半参数分位回归模型以及其参数估计量[11];曾惠芳等选择非对称Laplace分布的似然函数以及MH算法对分位回归模型进行模拟,以期解决高维数值积分问题,而MH算法需要给定分布π来设计马尔科夫链,这两个方法中马尔科夫链需要是静态分布,因而都会加大模型的计算难度[12];马学俊等提出了K近邻分位回归模型,而该方法在待估函数的跳跃点较多或者突变点较多的情况下进行参数估计才会具有优势[13];Zhao和Lian采用回归样条的方法对分位回归进行局部拟合,并且验证了其收敛的性质,但是该方法适用于局部拟合[14];晏振等基于MCEM算法对分位回归模型进行分析,该算法是对EM算法中对E步简化的方法,但是该算法主要适用于被解释变量存在删失数据的状况[15];Zhao和Tang考虑了逆概率权重的方法对分位回归进行分析,但是该方法适用于响应变量存在非随机的删失数据[16]。尽管上述方法都取得了一定的成功,但是其方法都有一定的适用条件。而本文的前提是基于基础贸易引力模型未考虑存在隐变量,因此上述研究方法都不适用。Tian等提出了采用EM算法进行线性分位回归模型参数估计的方法,该方法不仅考虑了模型存在隐变量的情况,并且EM算法计算简单[17]。基于以上分析,本文在基础贸易引力模型的基础上引入分位回归的理论框架,同时为了解决存在隐变量的问题,采用EM算法进行参数估计,对解释变量的影响进行分析。
三、模型构建与算法实现
(一)模型构建
基础贸易引力模型是将自然物理学科中的万有引力定律应用到经济分析中,研究距离、两个国家的经济规模这三个变量对贸易流量的影响,令Yij代表i国对j国的贸易流量,i国为出口国,j国为进口国,C为常数,xi和xj分别为i国和j国的经济规模,通常用GDP代表,dij代表i国与j国间的距离。贸易引力模型可记为以下线性模型:
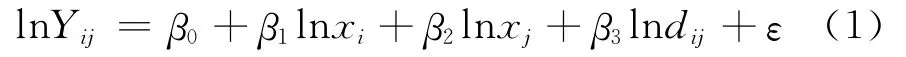
式(1)即为基础贸易引力模型,为与实证部分符号统一,将式(1)中的解释变量统一用x来表示,即xi= [1,x1,i,x2,i,x3,i]T,其 中 x1,i,x2,i,x3,i分别代 表式(1)中的lnxi、lnxj和lndij,即出口国经济规模、进口国经济规模和两国间距离;用yi代表lnYij,即样本国 双 边 出 口 贸 易 额,β = [β0,β1,β2,β3]T,βp=[β0,p,β1,p,β2,p,β3,p]T为参数β的p分位,即本文要分析的参数。式(1)写成:

其分位数函数为:

依据分位回归理论,式(3)参数的估计问题转化为对下式的求解问题:
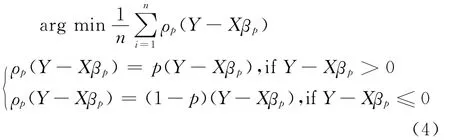
式(4)中,ρp表示损失函数,在零处不可微,因此不能直接求解最小值,本文对该问题采用的方法是令误差项服从非对称拉普拉斯分布。针对模型中残差项部分,常用 的 方 法 有 AEPD(Asymmetric Exponential Power Distribution)、AST(Asymmetric Student-t Distribution)和ALD(Asymmetric Laplace Distribution),而AEPD和AST分布中参数相较于ALD更多,AEPD分布和AST分布需要提前设定参数来控制分布的偏度和厚尾性,而ALD只包含两个参数,并且参数都有有限的中心矩,计算比较方便,并且具有明确的经济意义。Yu等提出残差项服从ALD后对参数进行极大似然求解,就等价于对式(4)求解[18]。因此,令残差项服从ALD,为考虑更一般的情况,在误差项加入尺度参数,式(2)转换为:

σ为误差项εi的尺度参数,假定εi是服从独立同分布的,并且其p分位数为零令变量vi=σzi,并且该变量服从参数为1/σ的指数分布,变量ui服从标准正态分布,并且假设zi与ui两个变量相互独立。变量zi其实际上就是分位贸易引力模型中的隐变量的表达,则式(5)和(6)可以写为下式:

综上可以得到以下分层模型:

式(7)即为分位贸易引力模型,式(4)为其参数估计问题,下文将介绍采用EM算法进行参数估计。
(二)算法实现
分位回归模型不仅能描述解释变量在各分位点对贸易的影响,展示更加丰富的信息,而且分位回归模型对应的是分位数而非平均数,因而相较于回归模型其系数更具稳健性。同时,学者在基础贸易引力模型上不断添加解释变量进行分析,从侧面说明了在基础贸易引力模型中存在隐变量,采用普通最小二乘回归会导致参数估计存在偏差。EM算法是一种用于解决隐变量存在的参数极大似然估计方法,是一种迭代优化策略,它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步)。EM算法是一种无监督的学习方法,EM算法的优点是可以处理隐变量存在的数据,计算简便、估计结果稳定。对上文中提出的分位贸易引力模型运用EM算法对模型中的参数进行估计,算法实现的具体步骤如下所示:
E步:结合上文中推导出的式(8),可以得到参数的密度函数以及完全数据的极大似然对数函数,依据EM算法理论框架可以得到Q函数①此处为EM算法中的Q函数。。给定t-1步的参数后,使得下式达到最大:

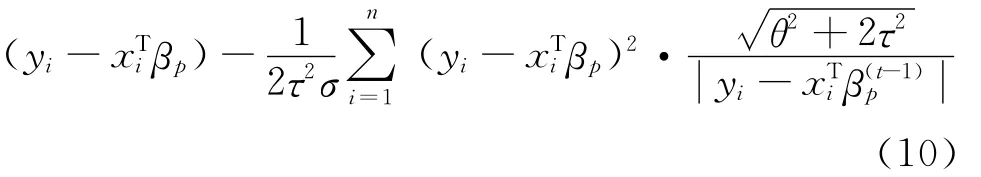
M步:根据E步所求解的Q函数对βp求偏导,需注意的是βp(t-1)为已知因素,故求导时将其视为常数,最终对βp求偏导并令其为零,可以得到βp的t步估计量:
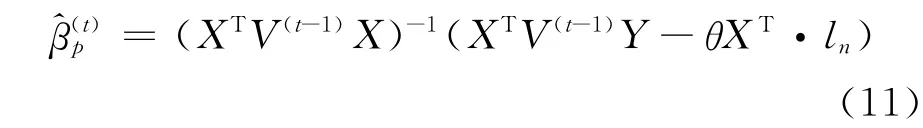
式(11)中,ln为元素为1的n维向量,V(t-1)是元素为的n维对角矩阵。
对E步和M步进行不断交替迭代,直至参数达到最优。在对分位贸易引力模型中参数σ求最值时,令其偏导为0的求解计算过程比较复杂,因此采用Yu和Zhang提出的估计量[19],即:

至此,分位贸易引力模型中的参数估计推导部分均已经求解。
四、实证分析
(一)数据来源与说明
本文为了保证数据的有效性以及全面性,从CEIC数据库选取了2014—2018年包括22个发达经济体以及23个新兴和发展中经济体,共45个国家的双边出口贸易流量①发达经济体包括澳大利亚、比利时、加拿大、希腊、爱尔兰、日本、韩国、荷兰、葡萄牙、瑞典、瑞士、丹麦、爱沙尼亚、法国、意大利、立陶宛、新加坡、西班牙、英国、美国、奥地利、捷克共和国;新兴和发展中经济体包括中国、印度、巴基斯坦、沙特阿拉伯、保加利亚、克罗地亚、匈牙利、波兰、土耳其、白俄罗斯、格鲁吉亚、俄罗斯、乌克兰、约旦、摩洛哥、阿拉伯联合酋长国、肯尼亚、巴西、哥伦比亚、墨西哥、斯里兰卡、卡塔尔、阿尔巴尼亚,其中共包含22个“一带一路”沿线国家。。为了保证数据的完整性,2014年数据中剔除了存在缺失数据的格鲁吉亚、卡塔尔、肯尼亚的数据,删除其余国家与这三个国家的出口贸易额;同样,2015年数据中删除了斯里兰卡、卡塔尔、肯尼亚三个国家的数据,2016年删除了哥伦比亚的数据,2018年删除了卡塔尔的数据。
本文之所以将上述国家选做研究样本,主要是基于以下考虑:(1)数据的可获取性。本文的样本国家数据均来自CEIC数据库,旨在研究国家间的双边贸易流量的影响因素,因而需要选取双边贸易额都可以获取的国家;(2)选取的样本中涵盖了中国的主要贸易伙伴(美国、英国、法国等),2017年中国对这些国家的进出口额占世界进出口额的约6.65%,中国作为目前世界贸易中的最大贸易经济体,对其与贸易伙伴国的贸易进行分析有利于对双边贸易影响因素的分析;(3)由《“一带一路”贸易合作大数据报告(2018)》可知,“一带一路”沿线国家的贸易总额占世界贸易总额的27.8%,因此选取了22个“一带一路”沿线国家作为样本国更具有代表性,更加全面;(4)根据世贸组织发布的报告,本文所选取的国家在世界贸易额排名中既有排名顺序靠前,也有排名顺序靠后的,如排名第1、2、4、5、6的中国、美国、日本、荷兰和法国,排名第50、56、58的希腊、哥伦比亚和巴基斯坦,排名第91、113、131的肯尼亚、格鲁吉亚和阿尔巴尼亚等,使得所选取的样本具有研究的代表性和典型性。
本文选取双边出口贸易额的原因在于,出口流量与贸易总量不同,出口流量具有方向性,并且不同的因素对进口国与出口国的出口贸易的引力作用是不同的,例如中国对外出口的国家中贸易额占前十的国家分别是美国、日本、韩国、印度、荷兰、英国、新加坡、俄罗斯、澳大利亚、墨西哥,其中出口额最高的美国的对外出口贸易额最大的十个国家分别是加拿大、墨西哥、中国、日本、英国、韩国、荷兰、巴西、法国、比利时,这种情况表现出影响因素对出口国和进口国的引力作用存在差异,因而本文选取的是2014—2018年45个国家之间的双边出口贸易流量。
(二)样本数据的实证分析
本文搭建分位贸易引力模型:

其中,yi代表取对数后的双边出口贸易额,xi=[1,x1,i,x2,i,x3,i]T代表截距项、取对数后的出口国的GDP和进口国GDP,以及取对数后的贸易伙伴国间的距离共4个变量。本文研究从0.005到0.955等分的共100个分位点下参数的估计结果,并将最大迭代次数设置为2 000次后得出参数的分位估计值,表1为基于EM算法得出的各个参数估计量在0.255、0.505、0.755、0.955分位点的估计值。
为了更清晰地了解分位贸易引力模型中,各估计参数随分位点的变化而出现的变化趋势,下面将分别给出2014—2018年数据的估计结果,具体见图1。
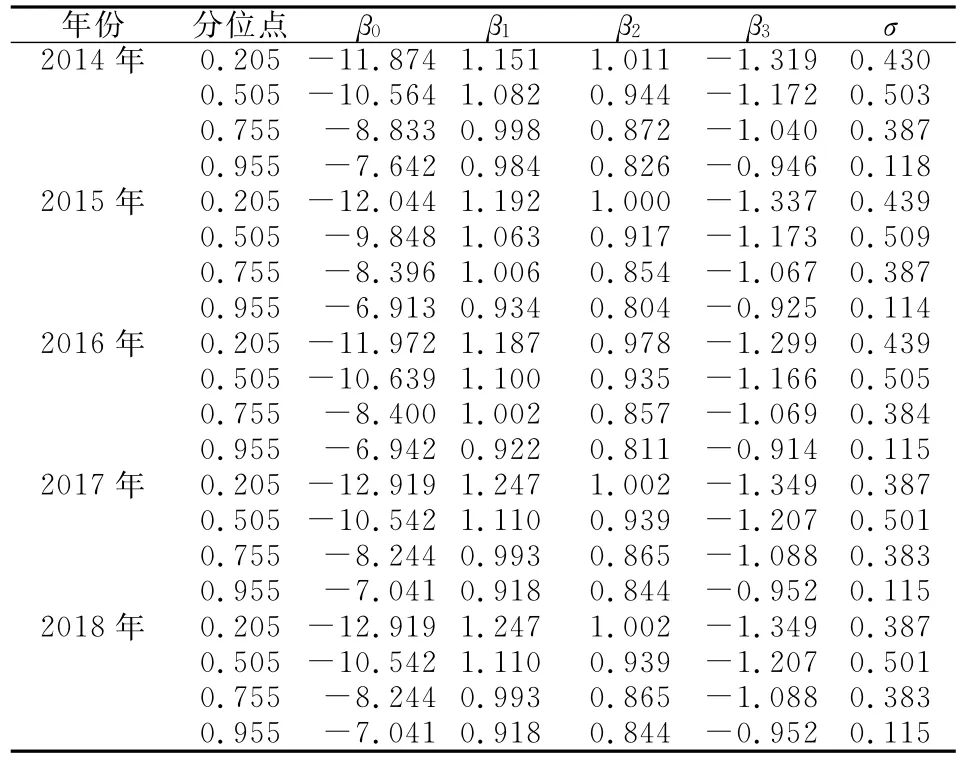
表1 2014—2018年基于EM算法的参数估计值

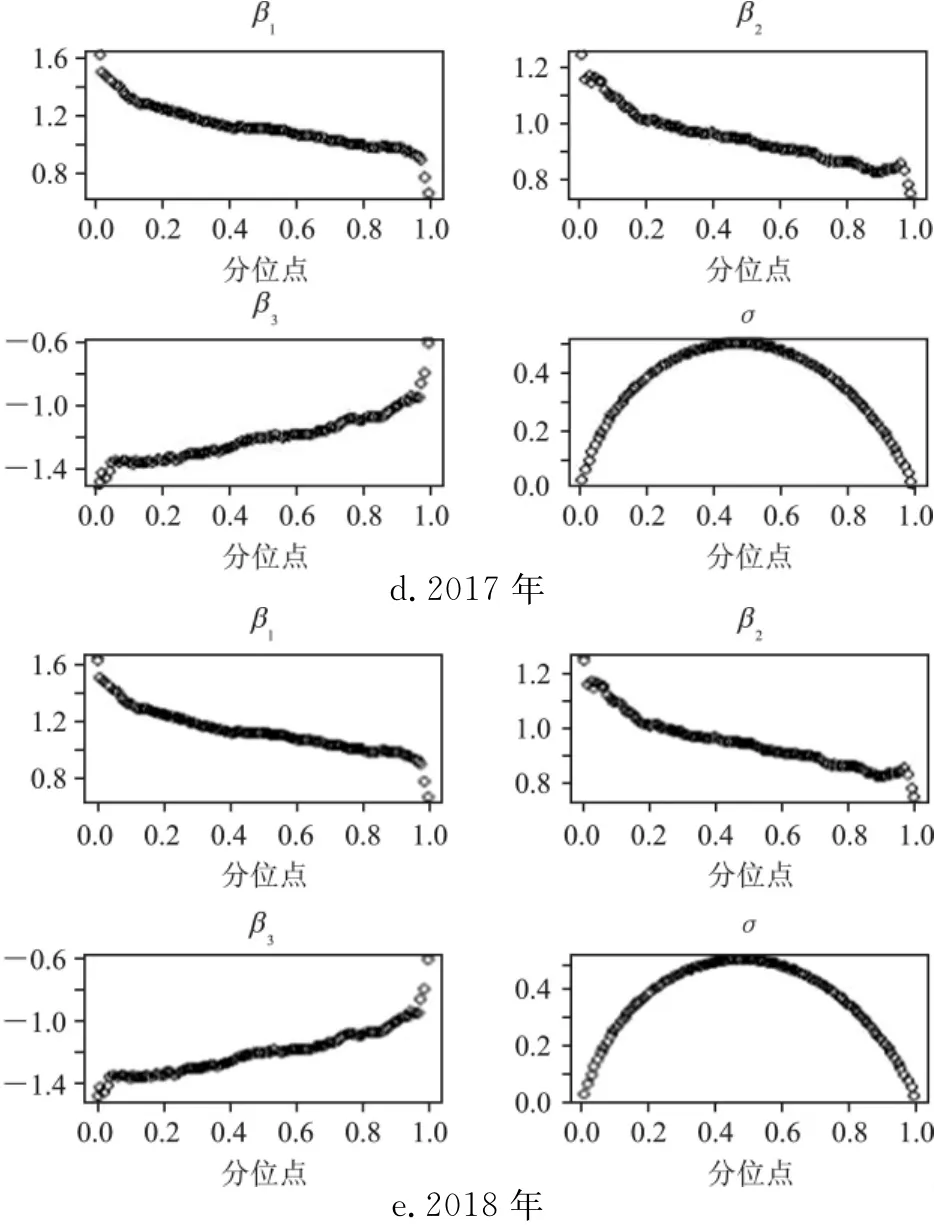
图1 分位贸易引力模型参数估计
图1 中(a)(b)(c)(d)(e)分别是2014—2018年双边出口贸易额的分位贸易引力模型参数估计结果。首先,比较图1各年中参数β1,可以发现2014—2018年各数据下参数估计结果均为正,并且随着分位点的增大逐渐递减;同时在分位点极小和极大时出现下降速度的变化,在分位点极小时出现下降速度减缓,而在分位点极大时出现下降速度变快。再比较图(1)各图中参数β2,在5个年度数据分析结果中均为正,并且都随着分位点增大而减小,并且都在分位点极小时出现减小速度减缓,而在分位点极大时出现减小速度猛增。再比较图(1)各图中参数β3,各年度下该参数取值均为负,且随着分位点增大其绝对值减小,在分位点极小处出现减小速度减缓,在分位点极大时出现递减速度猛增。最后比较图(1)各图中参数σ,其取值均为正,并呈现倒U型。分析可知,在2014—2018年数据的参数估计结果中四个参数取值方向一致,随着分位点变化的变动趋势一致,说明了本文采用EM算法分析的分位贸易引力模型的参数具有稳健性。
(三)影响因素分析
从图1中可以得出,在2014—2018年数据的参数估计结果中各参数的方向和变动趋势均一致,因而以2018年分位贸易引力模型参数估计结果为例对影响因素进行分析,2014—2017年各参数的分析与下面分析类似。
1.出口国经济规模。从图1(e)可以看出参数β1为正,取值范围是(0,1.6),表明出口国的经济规模对双边出口贸易额具有显著为正的影响,并且其影响随着分位点的提高而降低,并且在分位点较小和较大的时候出现急速下降,这表明出口国在其经济规模较小时,其对双边出口贸易额的影响较大;而当规模经济逐渐增大时,其对双边出口贸易额的影响出现逐渐递减的作用,这些国家大多为发展中国家,其经济规模对双边出口贸易额的影响符合常规的解释。在分位点较高的点,其对双边出口贸易额的影响较低,并且在达到一定规模时其影响出现快速递减,通常这些国家是发达国家,其经济规模越大对双边出口贸易额的影响越低,且降低的速度加快。
2.进口国经济规模。从图1(e)中可以看出参数β2为正,取值范围是(0,1.2),表明进口国的经济规模对双边出口贸易额具有显著为正的影响,其随着分位点的变动而呈现出的变化与出口国经济规模一致,表明进口国的经济规模对双边贸易额的影响为:在经济规模较低并逐渐增加时对双边贸易额的影响迅速降低,呈现出边际递减效应;随着经济规模的增大,其作用持续降低,当经济规模达到很大时,其对双边出口贸易额的影响速度加快。与出口国经济规模对双边出口贸易额的影响不同的是,β2比β1在不同分位点数值都小,且降低的速度更快,也就是说进口国经济规模对双边出口贸易额的影响要小于出口国的影响。
3.国家间距离。从图1(e)中可以看出参数β3为负,取值范围是(-1.4,-0.6),表明国家间距离对双边出口贸易额具有显著为负的影响,两国间的距离会增加交易成本,因而具有负向作用,并且其负向影响随着分位点的增加逐渐减小,此结论符合经济理论。两国间距离较近时,两国之间的生活差异、产业差异不大,因而两国间的双边出口贸易会较少;而当两国之间距离较大时,两国之间的生活差异、产业差异相对较大,其会增加双边出口贸易,而且会建设交通运输设施而降低交通运输成本。
4.隐变量。图1(e)中隐变量系数σ呈现出倒U型,即随着分位点增大,先增大,达到最大值后减小,说明出口国和进口国的经济规模、两国之间距离以外还存在其他影响因素,从而也证明了本文关于隐变量考虑的正确性。若仅在基础贸易引力模型的基础上增添解释变量进行分析,其结果会存在偏误。
综上,出口国经济规模和进口国经济规模对双边出口贸易额具有正向影响,但其贡献度随着经济规模的增大而降低,并且降低速度在经济规模较小和较大处出现转变。整体上出口国经济规模对双边出口贸易额的影响大于进口国经济规模的影响,出口国经济规模越大,其会生产更多的商品与劳务,进而促进双边出口贸易额。两国之间的距离对双边出口贸易具有负的影响,并且随着距离的增加其阻碍作用减弱。隐变量系数呈现倒U型,证明存在其他影响变量。
(四)模型诊断
基础贸易引力模型是基于“均值”思想,采用最小二乘回归对参数进行估计,其参数是服从正态分布的。为检验本文分位贸易引力模型的有效性,对估计参数的分布进行分析。图2为对2018年数据进行分位贸易引力模型学习后各参数的柱状图。

图2 分位贸易引力模型参数估计的柱状图
图2 为针对2018年数据进行分位贸易模型学习后参数^β0,p、^β1,p、^β2,p、^β3,p的柱状图。从图 2 可以看出,参数^β0,p呈现出右偏,^β1,p呈现出左偏,^β2,p呈现出左偏,^β3,p呈现出左偏,这显然与正态分布不相符。为验证分位贸易引力模型的有效性,本文采用R软件中fitdistrplus包对参数^β0,p、^β1,p、^β2,p、^β3,p的密 度分布进行验证,结果如图3所示。

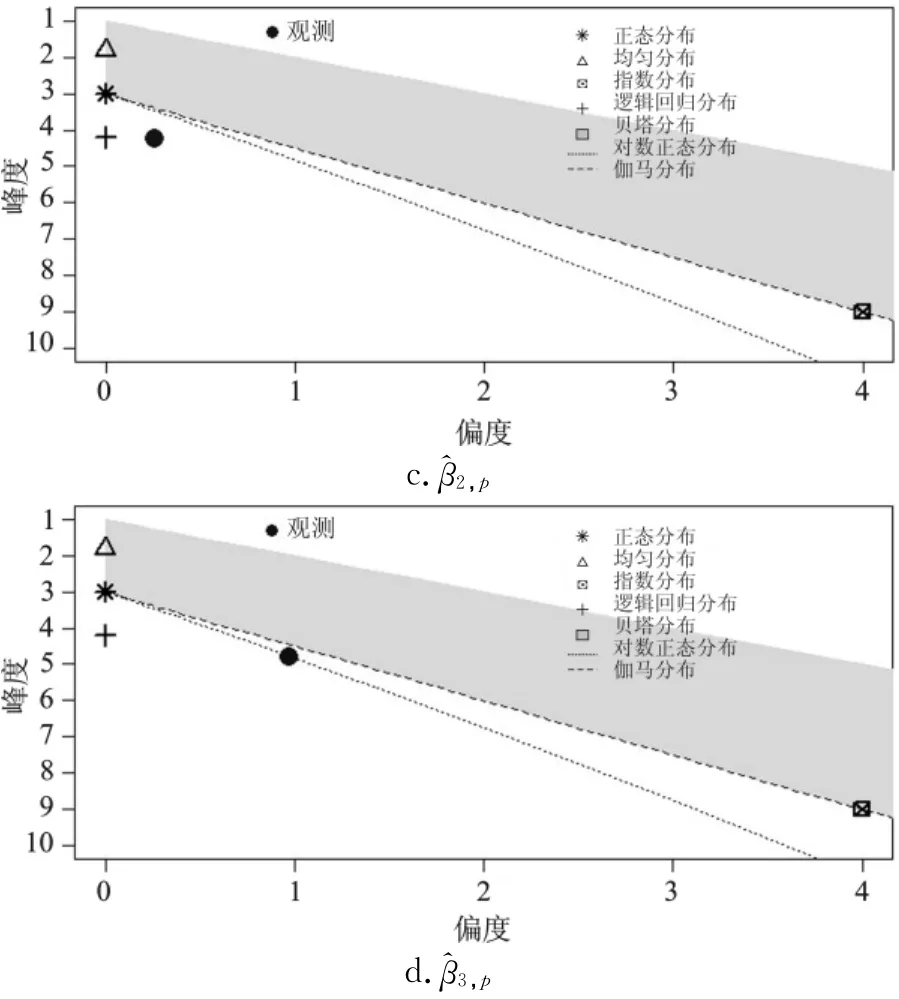
图3 各参数密度分布
图3 中(a)、(b)、(c)、(d)分别代表参数^β0,p、^β1,p、^β2,p、^β3,p的分析结果,图中横轴代表偏度,纵轴代表峰度,图中的圆点是观测数据的偏度―峰度值,图中给出了待比较的密度分布的偏度―峰度,分析观测数据的偏度-峰度与各个分布的偏度-峰度来进行下一步的测定。如图3(a)观测点的偏度―峰度靠近Gamma分布、Beta分布、Logistic分布的偏度―峰度,(b)中观测点的偏度―峰度与Beta分布、Lognorm分布、Logistic分布、Gamma分布的偏度―峰度较近,(c)中观测点的偏度―峰度与Logistic分布、Gamma分布、Lognorm分布的偏度―峰度较近,(d)中观测点的偏度―峰度与Logistic分布、Gamma分布、Lognorm分布的偏度―峰度较近。因此,利用R中的fitdis包分别对这些分布进行分析,比较分析后的残差,选择残差最小的分布,其结果如表2所示。
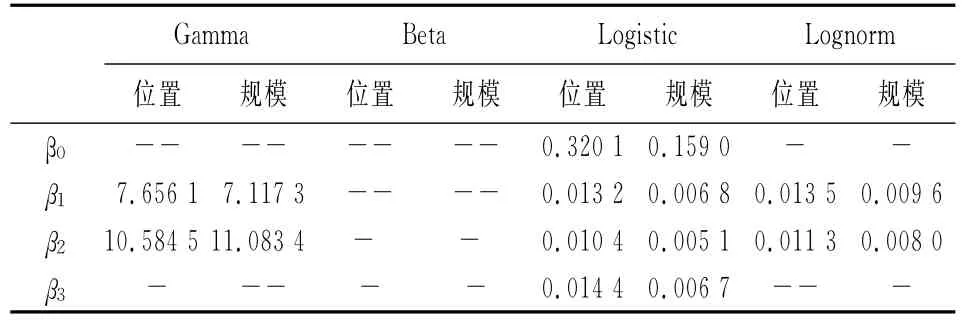
表2 参数与各密度分布分析的残差结果
表2中的数值代表参数与密度分布分析后位置和尺度的残差。从表2可知,各参数均是在Logistic分布下的残差最小,因此参数服从Logistic分布。基础贸易引力模型假定残差服从正态分布,而本文提出的分位贸易引力模型则是考虑隐变量的存在,采用EM算法进行参数估计,结果表明参数服从Logistic分布而非正态分布,这也说明了分位贸易引力模型的有效性。
五、结 论
本文在对贸易流量的分析中,考虑线性回归是在均值意义上的分析,不能全面反映双边出口贸易影响因素的作用,并且残差未能满足正态分布假定,同时现有研究均是在基础贸易引力模型的基础上增加解释变量,这从侧面说明基础贸易引力模型存在隐变量问题。因此,本文在基础贸易引力模型的基础上引入分位回归的思想,构建分位贸易引力模型,采用残差服从ALD分布的假定,并加入尺度参数,以解释更为一般的情况。同时考虑未观测数据所带来的影响,因而利用EM算法对参数估计,解决隐变量存在的问题。结合目前出口贸易发展的状态,本文选取2014—2018年包含22个发达经济体以及23个新兴和发展中经济体共45个国家之间的双边出口贸易额流量数据进行实证分析,结果证明分位贸易引力模型的结果与国际贸易理论相符合,同时对5个年度的参数估计进行分析,结果表明参数估计具有稳健性。为验证模型的有效性,采用R软件中的fitdietrplus包对各参数密度分布进行分析,得出各参数均服从logistic分布,而非正态分布,该结论说明了基础贸易引力模型在对出口贸易的分析中存在偏差,而本文构建分位贸易引力模型对双边出口贸易更具有解释意义。最后,隐变量的系数σ则随着分位点的增大呈现出倒U型,即先逐渐增加,然后再逐渐减小,说明存在其他解释变量对出口贸易额具有边际效应,因此后续工作可以在分位贸易引力模型的基础上增加变量对贸易额进行解释。
