基于由粗到精定位的列车驾驶员瞳孔和眼角点检测
2019-11-08王增才房素素张国新齐亚州
王增才,赵 磊,房素素,张国新,齐亚州
(1.山东大学 机械工程学院,山东 济南 250061; 2.高效洁净机械制造教育部重点实验室,山东 济南 250061)
近年来,我国铁路事业不断发展,随着高铁速度的不断提升,到达的地域越来越广,越来越多的人首选铁路作为出行工具。高速列车与其他交通方式(如轮船、飞机和汽车)相比,安全系数较高,但是一旦出现交通事故,带来的经济损失和人员伤亡是十分巨大的,而在所有列车事故发生的原因中,驾驶员疲劳及注意力不集中占比例最高[1],在列车长时间运行时,单一的驾驶环境极易引起驾驶员的疲劳,因此为了保证列车驾驶员和乘客的安全,对列车驾驶人的疲劳状态进行识别是必要的[1]。而视线方向的变化往往能够反映列车驾驶员的疲劳和注意力状态,瞳孔相对于眼角点的位置和运动状态是视线方向估计的关键特征。
本文结合图像纹理和学习模型,采用粗到精定位的策略来获取列车驾驶员眼角点和瞳孔位置。首先,利用监督下降法SDM[13]定位模型对列车驾驶人的面部特征点进行定位和跟踪,获取眼角点初始位置。然后在区域中通过加权遍历积分投影算法对瞳孔中心进行粗定位获得其初始位置。最后,将已定位的瞳孔和眼角点作为初始点,采用基于局部二值特征LBF的级联回归方法[14]对眼角和瞳孔点进行进一步精确定位。技术路线见图1。
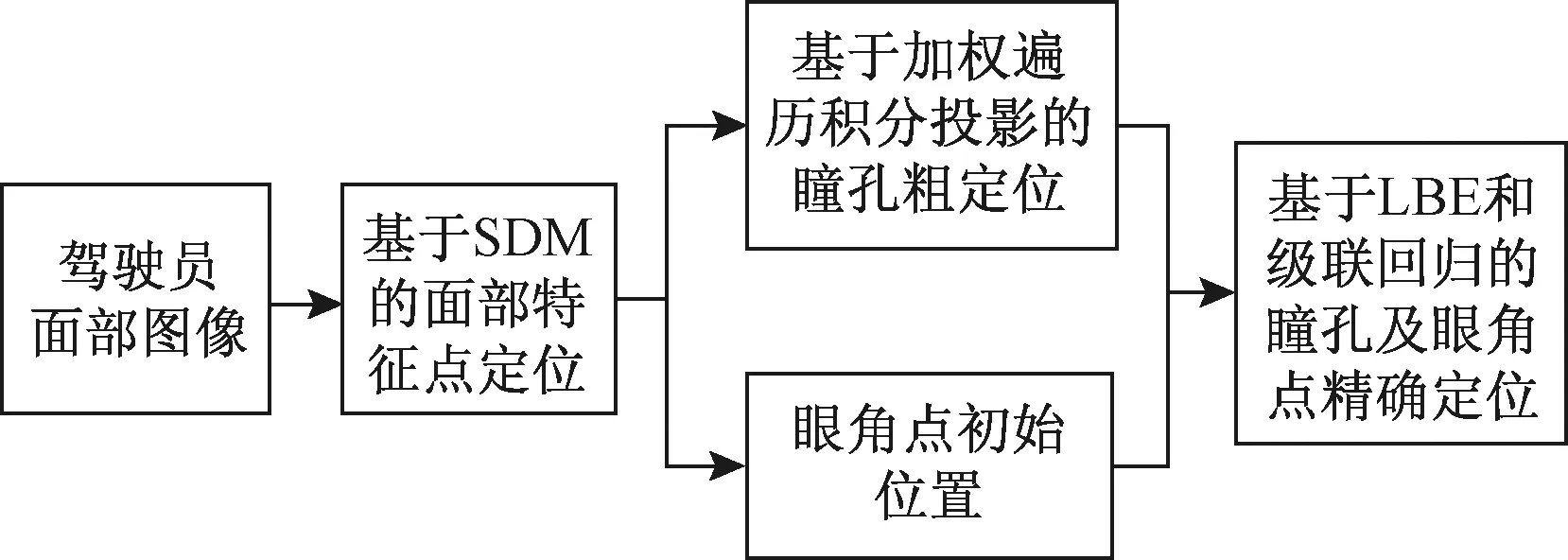
图1 总体技术路线
1 眼角点粗定位
采用SDM模型对面部特征点进行定位,从而获取眼睛区域和眼角点初始位置。SDM是牛顿法的改进,主要通过对机器学习模型进行训练求出梯度的下降方向,解决复杂最小二乘问题。该方法训练用的目标函数为

(1)
式中:x0为特征点坐标初始值;h(d(x))为在关键点x附近提取的纹理特征(HOG和SHIFT等);φa=h(d(xa))为在标定点附近提取的纹理特征。初始点坐标x0可通过不同的特征点初始化策略得到。该方法通过对式(1)的迭代,使xk+1=xk+Δxk逐渐接近人工标定值xa。首次迭代的式(1)的泰勒展开式为

(2)
式中:Jf(x0)为矩阵的一阶导数;H(x0)为矩阵的二阶导数。将式(2)对Δx求导并设置为0,得到
Δx1=-H-1(x0)Jf(x0)=-2H-1(x0)Jf(x0)(φ0-φa)
(3)
其中,φ0=h(d(x0)),首次迭代可以看作特征差Δφ0=φ0-φa在R0=-2H-1(x0)Jf(x0)方向上的投影,其投影结果用Δx1表示。因此,可以用式(4)来表示首次迭代。
Δx1=R0φ0+b0
(4)
根据SDM算法,第k步迭代后式(4)改写为
xk=xk-1+Rk-1φk-1+bk-1
(5)
式中:xk为第k次迭代后面部关键点的位置:φk-1为第k-1次迭代后关键点附近的特征;Rk-1为下降方向;bk-1为偏差项,Rk-1和bk-1通过训练得到。在训练过程中,该模型主要更新形状差值Δxk=xa-xk-1和特征向量φk两个参数,来生成新的训练样本,训练的过程为

(6)
式中:di为第i张图像;j为特征点的编号。式(6)是最小二乘问题,可求解析解。定义F=[φ1],A=[Rb]。则

(7)
根据式(7),可求Ak的解析解为
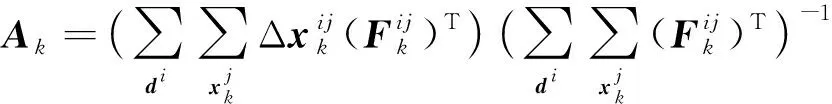
(8)
得到Ak后,根据迭代公式和每张人脸图片上的面部特征,可以得到

(9)
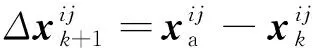
(10)
在训练过程中,只需要在每次迭代后的新坐标附近计算纹理特征,然后通过式(9)和式(10)进行多次迭代可以得到最终位置。将每次迭代得到的A保存,用于定位新的样本图像。
训练好模型后,其测试过程如下:(1)采用Adaboost人脸定位算法定位人脸区域;(2)根据人脸区域初始化人脸形状,得到x0;(3)采用SDM学习到的参数下降方向Rk和bk不断更新人脸形状xk,回归出最终的人脸形状。本文采用3名驾驶员的视频图像来对模型进行测试,部分定位结果见图2。可以看出该方法能够实现驾驶员眼睛特征点的有效检测。

图2 面部特征定位检测结果
2 瞳孔粗定位
在面部特征点定位后,确定眼角点的初始位置,但是该模型无法确定瞳孔的初始位置。因此,本文通过模板遍历法[5]提取眼睛图像的灰度比率,然后将其作为权值构建积分投影曲线,用来粗定位驾驶员瞳孔位置。
利用滑动模板对眼睛区域进行灰度分析:首先将在获取眼睛区域图像,然后用图3所示的模板W从图像左上角对其进行遍历。在每个位置上计算模板所覆盖区域的灰度比率值。模板W区域内灰度比率的计算公式为

(11)
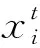

图3 圆形滑动模板的遍历方法
将灰度比率作为权值,通过式(12)和式(13)来计算图像的加权积分投影曲线。在瞳孔区域的位置,投影曲线在x轴和y轴两个方向均有极小值,将两个方向曲线的极小值作为粗定位的坐标值,实现瞳孔位置的初始定位。

(12)

(13)
3 瞳孔和眼角点精确定位
本文利用LBF特征和回归模型同时定位瞳孔点和眼角点,该方法不仅能够对驾驶员的眼角点和瞳孔点进一步精确定位,而且还能将眼角点作为约束,避免干扰对瞳孔点定位精度的影响。
3.1 形状回归算法
本文采用的回归方法通过级联形式来拟合得到总体形状S。以S0作为初始形状,利用每次迭代获取的形状增量ΔS对总体形状S拟合。第t次迭代求得的ΔSt为
ΔSt=WtΦt(I,St-1)
(14)
式中:St-1为上一次迭代获取的形状;I表示输入图像;Фt为关键点的征映射函数向量,依赖I和St-1;Wt为回归矩阵。利用这种方式学习的特征作为关键点的编码特征。将ΔSt加入到St-1,进行下一步计算。
映射函数向量Фt主要通过学习和手动设计得到。但是,若将所有样本中关键点均在手动设计的映射函数中选择,那么在较大空间中学习到较为理想的特征组合是很难的。因此,该模型通过基于局部学习的策略来获取映射函数。
特征映射函数由多个局部特征映射函数构成,本文Φt主要由3个关键点组成:左右两侧的眼角点和一个瞳孔点。因此映射函数向量为

(15)
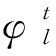
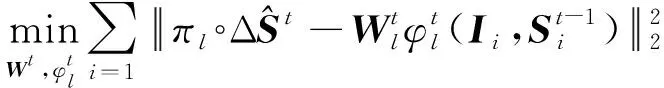
(16)
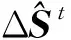
本文用训练随机森林RF(Random Forest)回归模型作为每个关键点的映射函数,提取每一个点的LBF特征,通过全局级联回归精确定位左右两侧的眼角点和瞳孔点。
3.2 RF模型
RF是一种基于多个决策树的组合算法,主要是以分类回归树为基础的分类回归模型。RF由多个决策树构成,模型通过Bootstrap算法随机地在数据中有放回地抽取样本来训练每一颗树,每一次训练的决策树都因为训练样本不同而其参数也不一样。因此,RF能够随机生成多个决策树,最后选择重复程度最高的决策树作为结果。由回归树构成的组合模型通过求每颗回归树的平均值形成RF模型的预测值。RF回归算法的流程见图4。

图4 RF模型
3.3 LBF特征
与RF模型不同,本文利用基于RF结构的模型来提取特征点局部特征。在特征提取的过程中,每一个特征点都对应一个RF模型,而每个RF是由相互独立的多个决策树构成。本文通过求图像中两个不同坐标点像素的差值获取形状索引特征,并将其作为输入。本文RF模型是针对单个特征点,每个RF回归模型所对应的点不会关联到其他RF对应的特征点。图5中,随着迭代次数的增加,随机点生成的圆形区域半径逐渐减少。

图5 最优局部区域选取
利用以上形状索引特征的获取方法,训练RF模型。在训练过程中,令输入为X={I,S},预测目标由Y=ΔS表示。在训练的过程中,每棵树中的每个节点的训练过程都相同,从随机生成的形状索引特征集合中选取一个特征的集合,然后将获取的样本分配到每个决策树的左右子树中。对决策树的每个节点,我们期望左右子树的样本数据方差减少最大。每一个决策树的节点都利用这种方法进行训练,而且每颗树均相互独立训练,且方法相同。训练完后,决策树的所有叶节点都保存一个特征点的二维偏移量。利用RF输出由0和1组成的二值特征。将所有样本点的特征串联起来,建立整个特征点形状的LBF特征。该方法技术路线见图6。

图6 LBF特征提取
3.4 整体线性回归方法
在得到LBF特征后,求出关键点的全局特征映射函数Wt,即

(17)
式中:λ为正则项系数,防止模型出现过拟合;NT为样本的个数。
该模型的优化和检测步骤过程为:(1)利用SDM模型和加权遍历积分投影方法获取基于NT个关键点的初始形状S0;(2)根据真实特征点形状S和图像I学习每个点的RF模型并求LBF特征;(3)利用式(17)计算全局线性投影Wt;(4)重复步骤(2)和(3),一直到模型收敛,得到Фt和Wt;(5)在检测过程中,将眼睛图片和初始坐标作为输入,求出对应的LBF特征,然后利用Wt和Фt得到关键点的形状差值,并根据下式对形状进行更新
St=St-1+WtΦt
(18)
多次迭代后,获得眼角点和瞳孔点的位置。
4 实验与讨论
为了验证本文方法的有效性,采用基于静态图像和视频图像的数据集进行实验。首先,利用公共图像数据集进行实验并与之前提出的方法比较;然后,利用公共视频和自建视频数据集模型进行实验分析,并研究该算法的检测精度和效率。
本文采用目前通用的定位精度判定准则[7-12]来验证提出方法的有效性,其计算方法为
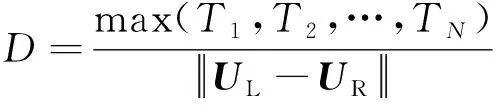
(19)
式中:Ti(i=1, 2, …,N)为第i个需要定位的点与其标定点之间的距离;UL和UR为左右眼睛中心的位置,可以通过标对眼睛标定点平均得到;D为每个需要定位的点的误差值。错误特征曲线[7-12]是通用的特征点定位模型评价工具,因此本文用该曲线进行模型精度比较,误差曲线的x轴坐标为D,y轴坐标的值为正确率,即横坐标中点d对应的纵坐标的正确率为定位误差率D≤d的样本数量占测试样本总数的比率,其公式为
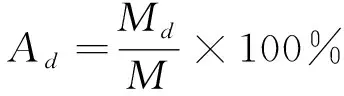
(20)
式中:Ad为当误差值为d时的正确率;Md为定位误差值在D≤d的情况下样本的数量;M表示样本总数量。
4.1 静态图像模型性能试验
为了保证本文提出模型的有效性和鲁棒性,采用MUCT[15],UULM[16]和Gi4E[17]数据集作为训练集,采用BioID[18]数据集作为测试集。训练用的3个数据集是由不同的研究机构建立的,其图像大小和分辨率互不相同。但是,与面部特征点定位模型的训练方法相似,本文模型在训练中仅需提取面部特征点位置附近区域的纹理特征,图像的大小和分辨率并不影响模型的训练过程。因此,本文将这3个数据集合并训练模型。
BioID数据集包含了23个人的总共1 521张图片。该数据集包含了不同的环境、被检测人的头部姿态和眼镜状态,部分被检测人有佩戴眼镜。因此,能够验证检测模型的有效性[7-12]。
BioID数据集是由静态图像构成的,在实验过程中采用以下定位步骤:(1)利用AdaBoost方法对图像中的人脸进行定位;(2)采用SDM方法得粗定位眼角点;(3)采用积分投影曲线粗定位瞳孔位置;(4)采用LBF判别形状回归模型精确定位眼睛特征点。在实验过程中,需要去除BioID数据库中无法定位人脸特征的图片,但是并不影响最终的结果[7, 11],因为去除的图片仅为5张图片,不超过整个数据集的0.5%。
提取部分结果图像并分析其有效性,见图6。图6(a)、图6(c)和图6(d)所示在驾驶人佩戴眼镜时,本文方法能够有效定位。图6(b)当驾驶人眼睛状态改变时,本文方法能够有效定位眼角点和瞳孔位置。图6(c)所示光照改变时,本文方法的定位效果也没发生较大改变。图6(d)~图6(f)所示,在被测试者的瞳孔位置发生大范围改变时,该模型也能正确定位。

图6 在BioID数据集中瞳孔和眼角点的定位结果
我们对瞳孔眼角点定位精度曲线进行分析,实验结果见图7,其中GP为基于本文采用的瞳孔粗定位方法,即通过加权的灰度积分投影曲线定位瞳孔位置。结果显示,与基于GP的瞳孔检测方法比较,基于SDM的眼角粗定位精度较高。可以看出,本文采用的瞳孔和眼角点定位方法的定位精度均高于粗定位方法。另外,眼角点的定位精度比瞳孔点的定位精度差,这主要是由于不同数据集对眼角点的标定位置略有不同。

图7 在BioID数据集中瞳孔和眼角点的错误特征曲线
该部分将本文方法与之前提出的瞳孔定位方法进行比较,来进一步验证本文算法有效性。本文将文献[7-12]提出的方法与本文提出的算法进行比较,这些算法的实验数据均采用BioID[7-12]数据集。提取当D≤0.05、D≤0.1和D≤0.25时的样本占有率作为比较结果,其实验结果如表1所示。根据实验结果可以看出,本文模型在取D≤0.05时样本占比为96.4%,而当D≤0.1时,样本占比达到100%,在其他方法中,除了文献[12]的方法外,D≤0.05的样本占比均未超过90%。其中,取D≤0.1时样本占比最高为99.4%,D≤0.25时样本占比均未达到100%。可以看出,与之前提出的方法相比,本文提出方法的定位精度最高且误差始终保持D≤0.1以内。
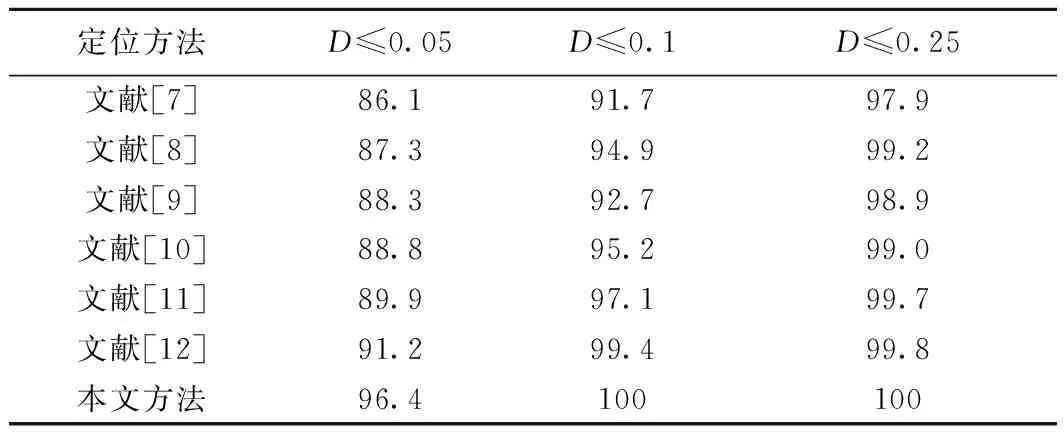
表1 BioID数据集的瞳孔定位检测结果 %
4.2 基于视频图像的模型性能试验
为了保证定位模型的有效性和鲁棒性,本文将Gi4E、MUCT、BioID和UULM数据集作为训练集,采用FRANK视频数据集[11,19]和自建的眼睛特征点定位HELD视频数据集来对模型进行测试。
FRANK数据集是说话的面部视频数据集,该数据集包含了5 000帧图像,共一位测试者。
HELD数据集为自建数据库,共采集了6名测试者在不同头部姿态和视线方向的面部视频,并通过手动标定的方法确定瞳孔和眼角点的正确位置,共包含2 103帧图像。
由于视频的图像是连续的,因此实验过程为:(1)如果是初始帧的图像则根据4.1节的步骤对眼角点和瞳孔点进行定位,并获取定位结果;(2)根据前一帧的定位结果,建立眼睛特征点初始模型;(3)采用本文提出的模型精确定位眼睛特征点。
对瞳孔和眼角点定位精度进行分析,实验结果见图8、图9。通过实验结果看出,基于由粗到精方法的眼角点和瞳孔点的检测精度均高于粗定位方法,且基于GP的瞳孔位置检测方法定位精度最低。与4.1节中的实验结果相似,模型对于眼角点的定位精度仍然低于瞳孔点。由于HELD数据集中的被测试者多于FRANK数据集,模型在HELD数据集中的眼角点定位精度要略低于在FRANK数据集中的精度;但在两个数据集中,瞳孔定位精度近似,并且眼角点和瞳孔点的定位精度几乎均在D<0.1范围达到100%(FRANK:99.9%,HELD:98.6%)。

图8 在FRANK数据集中瞳孔和眼角点的定位结果
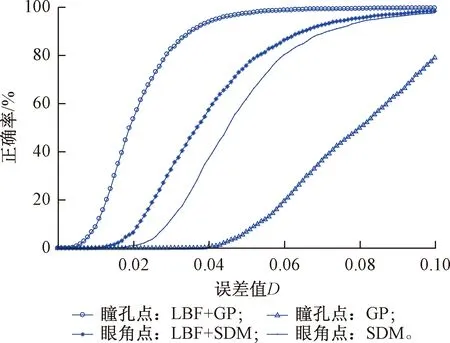
图9 在HELD数据集中瞳孔和眼角点的定位结果
分别计算本文提出的模型在这两个视频数据集中每帧瞳孔和眼角点的定位误差值D,其错误率结果如表2所示。FRANK数据集中,瞳孔点的误差值D≥0.15的帧数有2帧(0.04%);D≥0.1的帧数的有5帧(0.10%)。眼角点误差值D≥0.15的帧数有6帧(0.12%);D≥0.1的帧数的有20帧(0.40%)。HELD数据集中,瞳孔点的误差值D≥0.15的帧数有0帧(0.00%),D≥0.1的帧数的有3帧(0.14%);眼角点误差值D≥0.15的帧数有0帧(0.00%);D≥0.1的帧数的有29帧(1.40%)。可以看出,在这两个数据集中,所有特征点误差值D≥0.1的帧数均不超过30帧。因此,该方法能够在不同的面部视频中鲁棒地定位瞳孔和眼角位置。
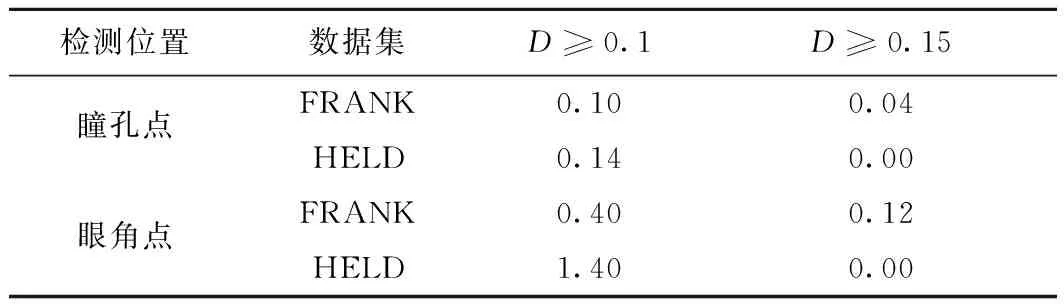
表2 视频数据集中瞳孔与眼角点定位错误率 %
分析该模型在FRANK和HELD视频数据集中的检测效率。模型采用MATLABC++混合编程,其硬件运行环境为:Intel(R) Core (TM) i7-6700 CPU @ 3.40 GHz,软件环境为Windows 10,MATLAB 2017a和VS 2015,其平均运行时间的计算结果如表3所示。从结果可以看出,在这两个数据集中,模型的平均运行时间差距不大,分别为21 ms和23 ms;经过换算可得出,模型的运行速度均超过43帧/s。因此,本文提出的模型在该软、硬件环境中能够满足对瞳孔和眼角点的实时检测。

表3 模型运行时间结果
5 结束语
本文提出一种由粗到精定位的列车驾驶员眼角点和瞳孔点定位方法。该方法采用SDM模型对进行粗定位并提取眼睛区域,采用圆形滑动模板遍历眼睛图像,根据眼睛瞳孔区域灰度值的特点用加权遍历积分投影算法对瞳孔进行粗定位。将瞳孔中心点和眼角点作为初始点,采用基于LBF的定位技术对眼角点和瞳孔位置进行精确定位。实验结果表明:本文提出的方法能够鲁棒地定位瞳孔和眼角点位置,其瞳孔定位精度明显优于其他方法。因此,利用该方法能够获取更加精确的瞳孔相对于眼角点的运动信息,为研究列车驾驶人的视线方向、注意力分散和疲劳驾驶识别方法打下了基础。
