基于模糊加权最小二乘支持向量回归的非线性系统建模方法
2019-11-07熊中刚罗素莲
熊中刚,刘 忠,罗素莲
(桂林航天工业学院机械工程学院,广西 桂林 541004)
0 引言
国内外关于非线性系统建模的研究在工程、科学等领域得到了大力发展,最小二乘支持向量回归作为支持向量回归的变体,极大加速了模型训练问题,在时间序列预测、子空间辨识、信号处理等方面得到了广泛应用[1]。
文献[2]经过大量实验研究表明,最小二乘支持向量回归的泛化性能优于支持向量回归。文献[3]研究了最小二乘支持向量回归能以较好全局性能辨识被估模型,但缺乏可靠的局部建模行为。文献[4]提出了基于最小二乘支持向量回归的局部神经-模糊方法,利用分层二进制学习算法将输入空间划分为若干个小区域,借助最小二乘支持向量回归对每个区域进行独立建模,但由于要为所有测试数据创建局部模型,导致计算负荷较大,效率低。文献[5]通过局部建模方法以训练数据中感兴趣的数据点为中心,选取靠近中心的数据建立模型,与此相似的局部建模方法还有K近邻点方法[6]和欧拉距离方法[7-8],但没有统一标准从数据集中选取K个近邻点保证其性能。文献[9]提出了局部支持向量回归建模方法,该方法能更好捕捉数据中局部信息以及建立各个模型之间的关系,但是当被建模的数据处于或靠近原始数据集边界时,易产生边界效应,即边界数据会产生较大的建模偏差。文献[10]考虑全局最小二乘支持向量回归方法计算量大,提出了局部灰色支持向量回归算法,该方法在建模问题上对计算时间进一步进行了优化。
本文针对最小二乘支持向量回归方法计算量大、非线性系统建模时边界数据会产生较大的建模偏差及数据计算负荷大等问题,提出了基于模糊加权最小二乘支持向量回归的非线性系统建模方法。
1 基础算法研究
1.1 最小二乘支持向量回归
文献[11] 中为了考察一部分核函数的推广能力,通过建立核函数与正则化算子P之间的关系,得出最佳选择是高斯核函数,而且可以获得非常平滑的估计。文献[1]研究了最小二乘支持向量回归并对于输入-输出数据xk=(x1k,x2k,…,xnk)T和yk,k=1,2,…,N,建立了如下初始模型:
(1)
式(1)中,x表示新测试数据。
本文经研究表明,最小二乘支持向量回归的泛化性能优于支持向量回归,基于上述因素、系统特征以及测量数据缺乏先验知识等问题,本文采用高斯核函数,则式(1)可进一步描述为:
(2)
式(2)中,σ为高斯核函数,α=(α1,α2,…,αN)为支持值向量,b为偏差项,以上参数通过如下优化求解
(3)
s.t.yk=wTΦ(xk)+b+ξk,k=1,2,…,N
(4)
Φ表示从非线性空间到线性空间的特征映射,参数γ∈R+表示规则化常量,用于对模型拟合度与平滑性之间相对重要性的控制。对式(3)和(4)使用拉格朗日方法得到如下无约束优化问题:
根据KKT条件有,
(5)
(6)
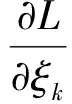
(7)
因此,最小二乘支持向量回归的学习过程可由式(5)—式(7)建立如下方程组求解:
(8)
式(8)中,y=(y1,y2,…,yN)T,1N=(1,1,…,1)TΩij=K(xi,xj)=ΦT(xi)Φ(xj),对任意的i,j=1,2,…,N,K(·,·)为满足Mercer条件的正定核函数。
1.2 GK(Gustafson-Kessel)聚类算法
文献[11—13]对于GK聚类算法的研究最终建立了一种最小化迭代优化算法目标函数:
(9)
GK聚类算法的突出优点在于其聚类协方差矩阵特征值能够为不同聚类的形状和方向提供不同的信息,从而能检测到不同的形状和方向数据集。本设计基于式(9)建立如下所述的约束条件:
(10)
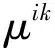
2 基于数据简化及模糊加权最小二乘支持向量回归的非线性系统建模
2.1 数据简化及模糊权值计算
本设计为实现前件参数辨识,采用优于模糊C均值聚类的GK聚类算法,并引入重叠因子去除建模过程中一些非重要数据,减小建模方法的运算时间,从而对数据进行有效简化,在不影响建模性能的条件下为后件参数辨识减小计算量。
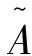
(11)
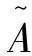
(12)
(13)
式(12)、式(13)中,i=1,2,…,N,k=1,2,…,R,j=1,2,…,n。本设计经由式(12)和式(13)对每个数据子集引入重叠因子进行简化后,同时在式(11)的基础上建立了如下的三角模糊隶属函数:
(14)
基于式(14),第i个规则的执行强度可计算为各个隶属度乘积:
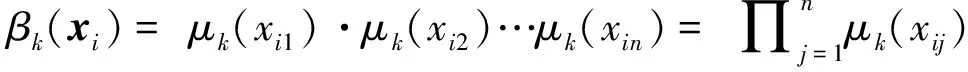
(15)
式(15)中,μAij(x)为模糊集Aij的隶属函数。对于第k个模糊集取标准化触发强度,可得模糊权值:
(15)
经过GK聚类算法处理后不仅能够保持原始数据集容量,而且可有效减小每个子集的容量,理论上认为任意一个数据的隶属度远离聚类中心的三倍标准差时可以忽略,本设计中一般在3附件选择重叠因子λ,进而再划分数据子集后,新的数据子集能够在保证数据重要性的前提条件下极大的简化数据容量,充分简化了T-S模型在计算负荷上的后件参数辨识。
2.2 模糊加权的最小二乘支持向量回归非线性系统建模
本建模方法设计时先将输入空间模糊划分为几个模糊区域,每个区域用子集回归模型代替每个规则对应的线性函数逼近T-S模型子系统,再经由最小二乘支持向量回归(LS-SVR)对每个训练数据子集回归模型独立建模,最终通过模糊加权得到被估系统的全局行为。
该系统非线性系统建模首先基于获取到的未知系统输入-输出数据xk=(x1k,x2k,…,xnk)T和yk,k=1,2,…,N,对于任意未知非线性系统y=f(x)运用T-S模糊模型能进行一个较好的描述和建模,对于各个数据的采样指标采用k表示,同时回归量数目采用n进行表示[15]。在T-S模糊模型描述下的后件部分输入的线性函数:
(17)
式(17)中,i=1,2,…,R,其中n×1的输入变量采用x表示,输出变量采用yi∈表示。系统T-S模糊模型的后件参数采用n×1维向量ai和bi∈表示,第i个规则用Ri表示,总规则数则用R表示。
然而‘xisAi(x)’的逻辑组合有如下形式:
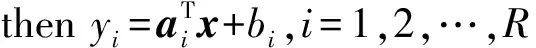
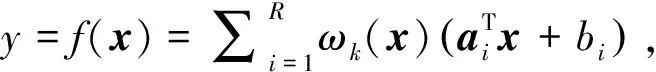
然后基于所获取的新训练子集,同时结合式(2)建立每个子集回归模型SRMk,即
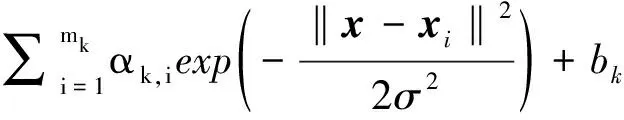
(18)
式(18)中,k=1,2,…,R,其中第k个子集回归模型采用SRMk定义,并通过最小二乘支持向量回归方法对参数αk,i,bk进行求解,mk表示第k新训练数据子集Δk的大小。
最后通过式(16)模糊加权值对子集回归模型SRMk进行组合,得到所提出方法的最终输出。
(19)
在式(19)中,每个子集回归模型SRMk(x)可以通过对应的数据子集独立求解且彼此之间的运算是独立的,本质上不受聚类数的影响。
3 仿真实验
为能有效论证提出的方法,下面将通过仿真从均方根误差和不同方法计算时间进行比较。 第一个实验为双输入单输出非线性函数,第二个是非线性动态系统。
考察的其中一个性能指标均方根误差RMSE的定义如下:
(20)
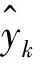
另一个性能指标是提出方法的全局建模时间和局部建模时间、全局最小二乘支持向量回归建模和局部最小二乘支持向量回归建模做比较,同时考虑了重叠因子在试验中的影响。对于不同方法选取一样的超参数集以使比较尽量公平。对于局部建模方法,假设获取的训练数据X={(xi,yi)|i=1,…,N},测试输入xt,并在其邻域采用测试输入与训练数据之间的欧拉距离获取p个训练点用于建立局部模型。首先考虑如下双输入非线性系统:
在-5≤x1,x2≤5进行等距离采样获取训练数据1 681(41×41),测试数据量为6 561(81×81)。
为了将提出的方法与局部最小二乘支持向量回归方法、全局最小二乘支持向量回归方法和文献[3]进行有力比较,同时考虑与现有方法比较的公平性,故采取十阶交叉验证法获取与比较系统一样的超参数集(σ,γ,λ)=(3,15,1.5),表1和表2分别给出了不同方法对于均方根误差以及运算时间的比较。此外,也给出了不同重叠因子λ为1.5和3.0时,提出方法在数据简化后的每个数据子集大小、训练/测试均方根误差以及局部建模时间相关情况如表3所示。从表1到表2的结果可以清晰看到,提出方法无论是从计算时间还是均方根误差,显然优于其他建模方法。表3从某种程度上表明,提出方法对于重叠因子的选择并不是越大越好。

表1 不同方法的均方根误差性能比较
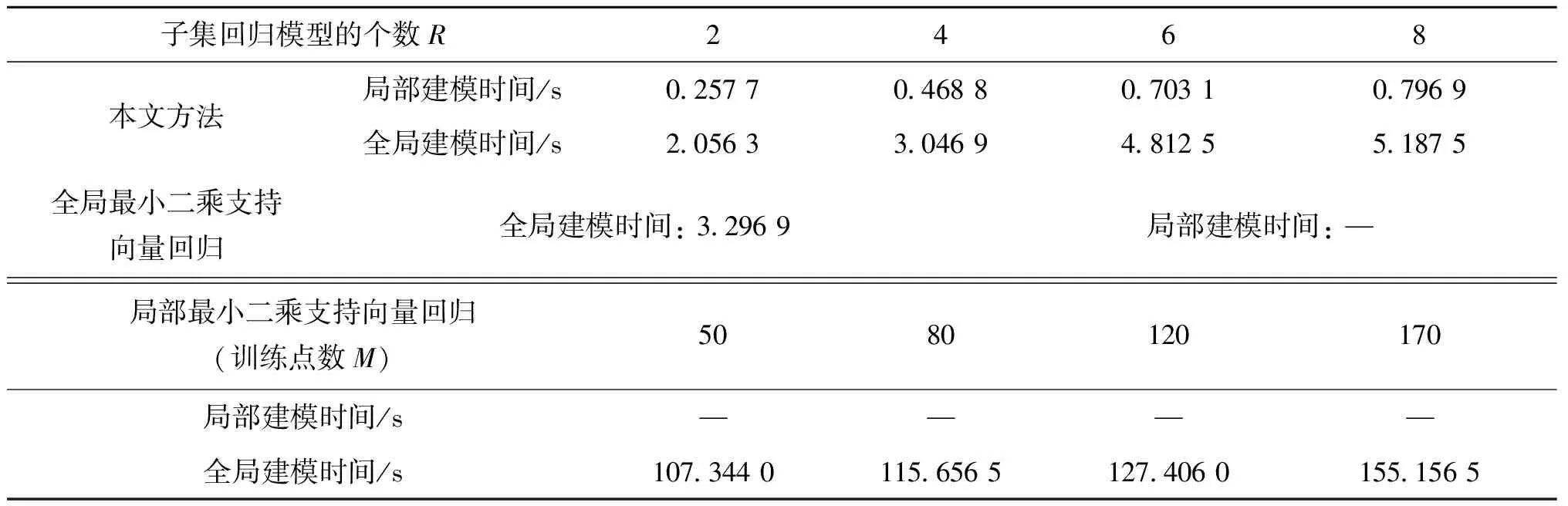
表2 不同方法的运算时间比较

表3 不同重叠因子对应的各个数据子集大小、均方根误差(训练/测试)以及局部时间
采用局部最小二乘支持向量回归方法,通过欧拉距离选取的p个训练点分别为50,80,120和170时,如图1所示,出现了明显的边界效应问题,尤其是训练数据量较小的时候时尤为严重。即便p增加会削弱边界效应问题,但是建模运算时间随之急剧增加,如p取170时,建模时间达到了155.1565秒。图2给出了提出方法在R分别取2,4,6,8的建模输出,即便R取较小时,也没出现边界效应。分别通过图1和图2对局部建模方法和提出方法仿真,将获取到的整个数据通过聚类方法分别聚类成2类、4类、6类、8类进行比较时,得出当类数R选择越大时,局部建模方法的精度越高,然而运算时间也越大;即便如此,提出方法在较小聚类数R时,建模精度和运算时间也能得到较好的保证。
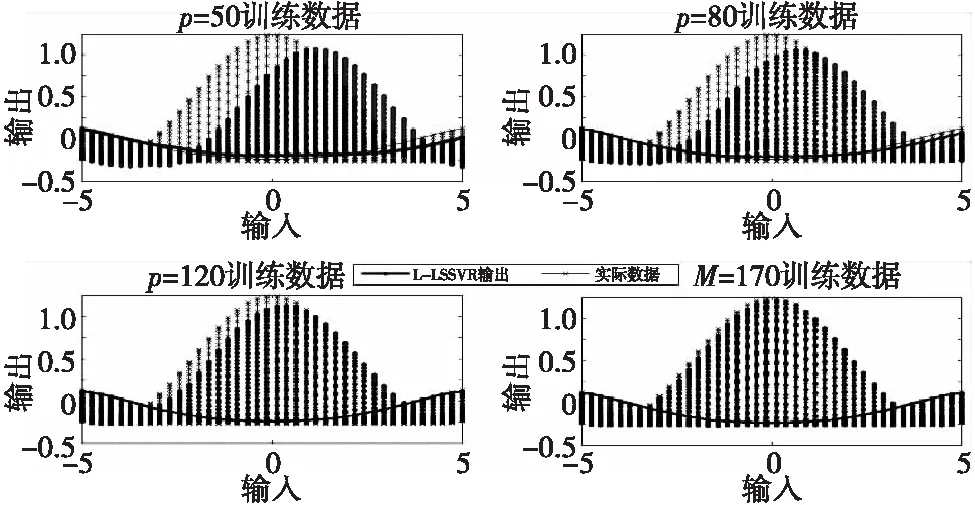
图1 局部最小二乘支持向量回归方法选择p个训练点分别为50,80,120和170Fig.1 L-LS-SVR method selects training points for 50,80,120 and 170 respectively
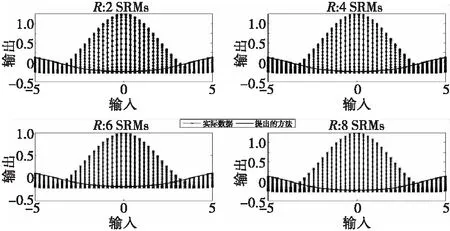
图2 提出方法在R分别取2、4、6、8的建模输出Fig.2 The proposes a method to take 2, 4, 6, 8 modeling outputs in R respectively
接下来,考虑非线性动态系统:
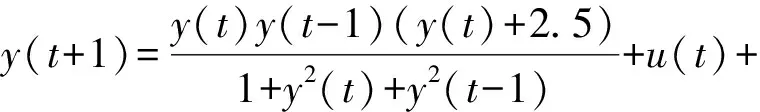
(20)
从该系统产生501个训练点,v(t)是方差为0.5的高斯噪声,使用提出的方法对其进行动态建模,选择聚类数R为7,与文献[3]提出的方法进行对比,本文采用5阶交叉验证选取5组不同的互斥数据集作仿真进行比较,更能体现提出方法与现有方法的合理性和优越性;5阶交叉验证寻优超参数集(σ,γ,λ)为(1,1 000,1.1)。
表4和表5分别给出了不同方法的均方根误差RMSE以及运算时间的比较,重叠因子λ为1.1和2.5时,提出方法在数据简化后的每个数据子集大小、训练/测试均方根误差以及局部建模时间的比较情况如表3所示。表4到表6清晰地表明,提出方法较全局最小二乘支持向量回归和局部最小二乘支持向量回归方法都有着较好的有效性和优越性。例如表4,从均方根误差的性能比较来看,即便子集回归模型个数为3(对应规则数R取3)时,其均方根误差为0.252 3,运行时间为0.328 1 s,而局部最小二乘支持向量回归选择最多数据量为89时也为0.356 1,运行时间达到了18.171 9 s。
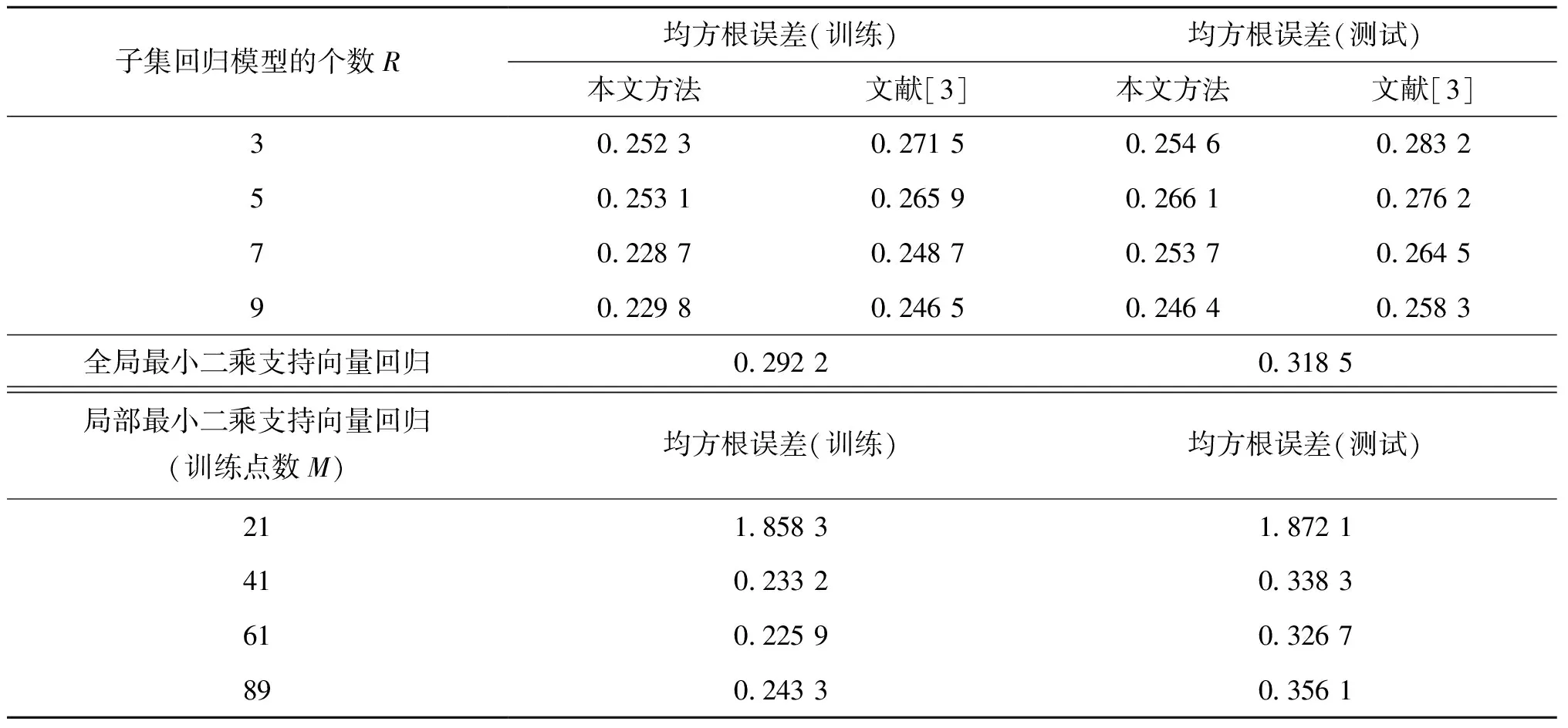
表4 不同方法的均方根误差性能比较
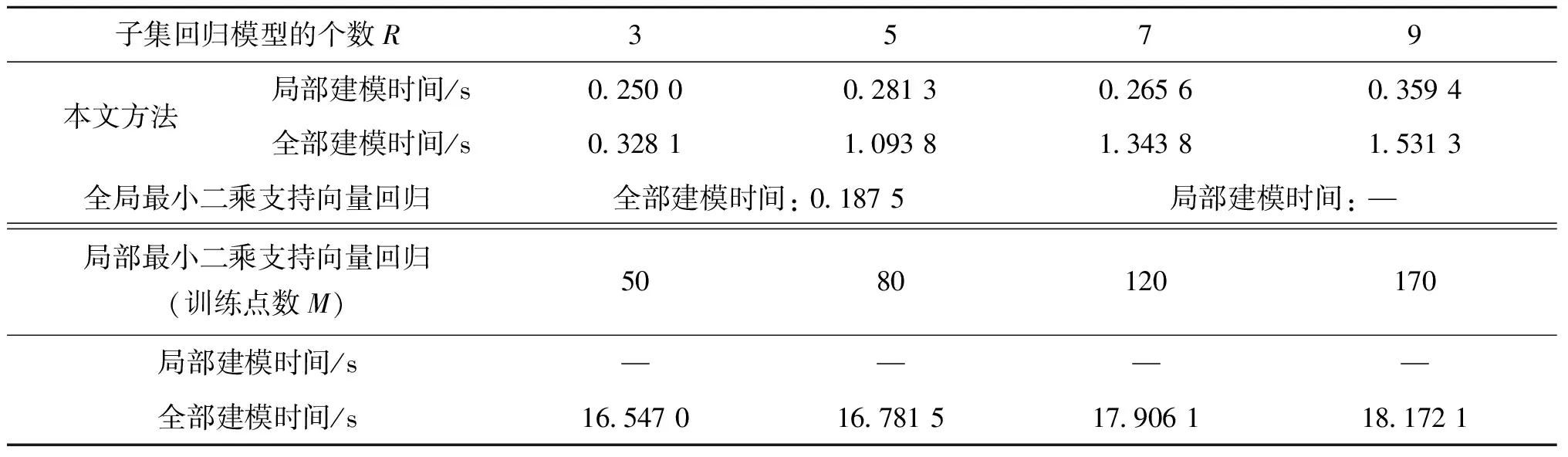
表5 不同方法的运算时间比较

表6 不同重叠因子对应的各个数据子集大小、均方根误差(训练/测试)以及局部时间
综上测试可知本文设计的方法选取较小的重叠因子能够使系统训练和测试的均方根误差更好,并能更好地简化数据,重叠因子越小时,每个聚类子集所包含的数据量越小,从而导致每个数据子集的重要数据消失,最终引起建模精度的下降,故也不能无限制地对重叠因子取小,这样反而会丢失建模过程中的有效数据,但究竟如何适当选取将是下一步进行的工作。
4 结论
本文提出了基于模糊加权最小二乘支持向量回归的非线性系统建模方法。该方法融合了模糊加权机理与最小二乘支持向量回归的优点,通过引入重叠因子,在保证建模精度(均方根误差越小越好)的情况下,去除建模过程中的一些非重要数据,减小建模方法的运算时间,并能将全局与局部建模方法相融合有效解决局部建模方法所产生的边界效应问题。实验验证结果表明,本文设计的几种方法分别从训练/测试均方根误差、不同重叠因子、计算时间方面比较都有明显的有效性和优越性,但重叠因子大小与建模精度的确切关系有待进一步研究。
