基于深度学习的语义分割算法综述
2019-10-26倪颖婷杨明川
赵 霞,白 雨,倪颖婷,陈 萌,郭 松,杨明川,陈 凤
(1.同济大学 电子与信息工程学院,上海 200092; 2. 上海宇航系统工程研究所,上海 201109;3. 上海航天技术研究院,上海 201109)
0 引言
语义分割是将数字图像分成多个集合(像素集)的过程,在分割图中具有相同标签的像素具有类似的特征。更确切地说,语义分割是为便于图像分析而为图像中的每个像素分配标签的过程[1-2]。语义分割是空间机器人、自动驾驶、医学图像处理等视觉分析技术的基础。这里主要分析空间机器人的应用需求。
地球外层空间是世界各国竞相争夺的领域,各国相继发射了大量航天器。由于设计、制造等因素及空间环境的影响,航天器在轨运行过程中,各种故障及意外时有发生。以航天器维护维修、生命延长及太空垃圾清除等为目的的在轨服务技术十分重要。未来的空间探索任务,对太空组装、星表基地建设等空间操作任务有着迫切的需求。空间机器人操作是在轨作业及空间任务的主要形式,图1为空间机器人的工作示意图。空间机器人试图抓捕目标卫星,并分离螺栓孔和对接环,即空间机器人必须能找到其机器视野中哪些是螺栓孔、对接环,并进行准确定位,其中的识别和定位就要利用语义分割技术。可以说,语义分割技术是未来航天器实现全自动在轨服务的先决条件,对于高效率、高精度、成功执行各种空间任务,具有战略意义。

图1 服务卫星工作示意图Fig.1 Schematic diagram of service satellite operation
在深度学习之前,语义分割领域主要采用Normalized Cut[3]、Grab Cut[4]、纹理基元森林(Texton Forest)[5]或是随机森林(Random Forest)[6]等传统方法,分割精度较低。
2012年,Hinton研究组使用AlexNet网络在imagenet图像分类竞赛上以84.6%的top-5准确率取得了冠军[7]。而传统分类技术仅取得了73.8%的准确率,使得以卷积神经网络为代表的深度学习得到了广泛的关注。凭借对复杂特征强大的学习及提取能力,深度学习被广泛用于图像分类、目标识别、人脸识别、语音识别等任务,并取得了突破性的进展。
虽然卷积神经网络已经被应用于图像分类领域,但受到全连接层与池化层的限制,语义分割领域仍以传统方法为主。2014年,加州大学伯克利分校的LONG等提出的全卷积网络(fully convolutional network,FCN)[8],将传统的卷积神经网络(convolutional neutral network,CNN)末端的全连接层替换为卷积层,不再将神经网络的输出结果限制为一维数组,正式将卷积神经网络引入语义分割领域。同时FCN不限制输入图像的尺寸,分割速度较传统方法有很大提升。迄今为止,语义分割领域几乎所有的先进方法都是由FCN扩展得到。
鉴于语义分割技术的重要意义与深度学习强大的学习能力,近年来新的语义分割方法不断出现和发展。实践证明,卷积神经网络较传统方法更适合于图像特征的学习与表达[9-10]。文献[11-12]也对图像分割算法进行了综述,文献[11]将图像分割分为基于图论的方法、基于像素聚类的方法和语义分割方法, 尤其对利用深度网络技术的语义分割方法的基本思想、优缺点进行了分析、对比和总结。文献[12]将图像语义分割分为基于区域分类的方法和基于像素分类的方法,又把基于像素分类的方法进一步细分为全监督学习和弱监督学习。本文只针对基于深度学习的语义分割方法,将其分为“基于编码器-解码器结构的算法”(如U-Net[13])和“基于整合上下文信息算法”(如DeepLab[14-16])。
1 语义分割常用数据集
深度学习在语义分割领域获得巨大成功地离不开大规模图像数据集的支持。丰富的数据集使大规模特征运算成为可能,同时也有效缓解了卷积神经网络在训练中的过拟合现象。
表1列出了语义分割领域最受欢迎的几大数据集及其输出类别数量,训练、验证及测试集数量。

表1 语义分割常用数据集
PASCAL视觉物体分类2012数据集(PASCAL-VOC 2012)[17]为一个标注过的图像数据集,可用于五个不同的竞赛:分类、检测、分割、动作分类、人物布局,其中分割竞赛的目标是预测图像的每个像素在21个类别(20类物体+背景)中所属的类别。该数据集经过增强,使得训练集图片数量达到10 582张[18]。目前该PASCAL-VOC 2012增强数据集是最受欢迎的语义分割数据集。
PASCAL 部分数据集(PASCAL-PART)[19]是对PASCAL-VOC 2010数据集的扩展,其中20类物体的每个部分都被标注。例如:飞机被分为机身、引擎、左机翼、右机翼、机尾、起落架等。该数据集包含了PASCAL VOC 2010的全部10 103张训练、验证图像以及9 637张测试图像。
PASCAL 语义数据集(PASCAL-CONTEXT)[20]也是对PASCAL-VOC 2010数据集的扩展,不同于PASCAL部分数据集,该数据集将原本的PASCAL语义分割任务拓展到整个场景中,并且将标签数量提高到59种。该数据集也包含了PASCAL VOC 2010的全部训练、验证以及测试图像。
微软常见物体环境数据集(Microsoft COCO)[21]是微软团队提供的图像识别、分割、标注数据集,包含了80个类别,提供了82 783张训练图片、40 504张验证图片以及40 775张测试图片。该数据集的测试集分为4个子集:test-dev子集用于验证及调试;test-standard子集是默认的测试集;test-challenge是竞赛专用子集,用于评估提交的模型;test-reserve子集用于避免竞赛中使用测试数据进行训练的问题。由于规模巨大,Microsoft COCO数据集目前也很常用。
城市街景数据集(CITYSCAPES)[22]包含一系列由50个城市的街景视频序列图片,其提供了3 475张高品质的像素级标注图像以及20 000张的粗略标注图像。该数据集标注物体达到19类,包括道路、人行道、建筑、墙、栅栏、电线杆、交通灯、交通指示牌、植物、地面、天空、人、骑行者、轿车、卡车、公共汽车、火车、摩托车与自行车。城市街景数据集用于城市街景理解视觉算法的两大性能评估: 像素级语义标注和实例级语义标注。该数据集被广泛应用于无人驾驶算法性能的评估。
ADE20k数据集[23]包含了超过2万张以场景为中心的图像,并对对象和对象的部分进行了超过150类标签的标注。具体包括了天空、道路、草地等无法进行部件分割的物体以及人、汽车、床等可以再进行部件分割的物体。该训练集包含2万余张图像,验证集包含2 000多张图像,测试集图像未被公开。
2 语义分割通用深度神经网络
现有语义分割方法主要是将卷积神经网络作为语义分割的基础网络,如VGG16、ResNet等预训练基网络。这些优秀的基础网络可对复杂信息建模,学习更有区分力的特征,更好地分类,提高预测准确率。以下介绍几种常用的卷积神经网络。
AlexNet[7]是取得2012年大规模视觉识别竞赛(ILSVRC-2012)冠军的网络,它的top-5错误率比上一年的冠军下降了10个百分点,而且远远超过当年的第二名。其使用ReLU做激活函数,而且网络针对多GPU训练进行了优化设计,从此开始了深度学习的黄金时代。
VGG-Net[24]是由牛津大学Visual Geometry Group提出的卷积神经网络模型,获得了2013年大规模视觉识别竞赛(ILSVRC-2014)的亚军。VGG-Net卷积层与全连接层的层数达到16层,因此也被称为VGG-16,其结构如图2所示。与AlexNet相比,VGG-Net用大量小感受野的卷积层替代了少量大感受野的卷积层,减少了参数数量,增强了模型的非线性,同时也使得模型更易训练。
GoogLeNet[25]是由SZEGEDY等提出的在2014年大规模视觉识别竞赛(ILSVRC-2014)中以 93.3% 的top-5准确率夺冠的卷积神经网络模型。该模型通过在结构中嵌入Inception来聚合多种不同感受野上的特征,以提升分割精度。Inception可以看作是一个小网络。如图3所示,该模块的核心部分由1个1×1的卷积层、1个3×3的卷积层、1个5×5的卷积层以及1个池化层组成,在多个尺度上进行卷积再进行聚合。同时,3×3卷积层与5×5卷积层前加入的1×1的卷积层对输入进行降维,起到减少特征数、降低计算复杂度的作用,使GoogLeNet在存储空间及耗时等方面均较VGG-16取得了进步。
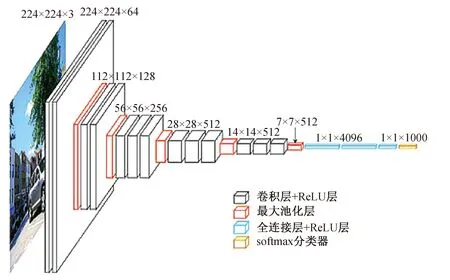
图2 VGG-Net结构图Fig.2 VGG-Net architecture
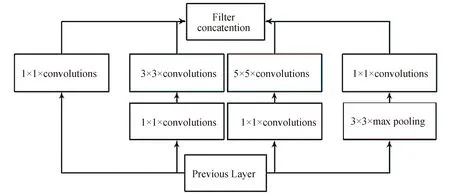
图3 GoogLeNet中的Inception模块Fig.3 Inception module in GoogLeNet
微软提出的ResNet[26]以96.4%的top-5准确率取得了2015年大规模视觉识别竞赛(ILSVRC-2015)的冠军。ResNet网络的深度达到了152层,并引入了残差单元(如图4所示)。残差模块通过identity skip connection解决了训练更深层网络时出现的性能退化问题。同时,identity skip connection也解决了梯度消失的问题。
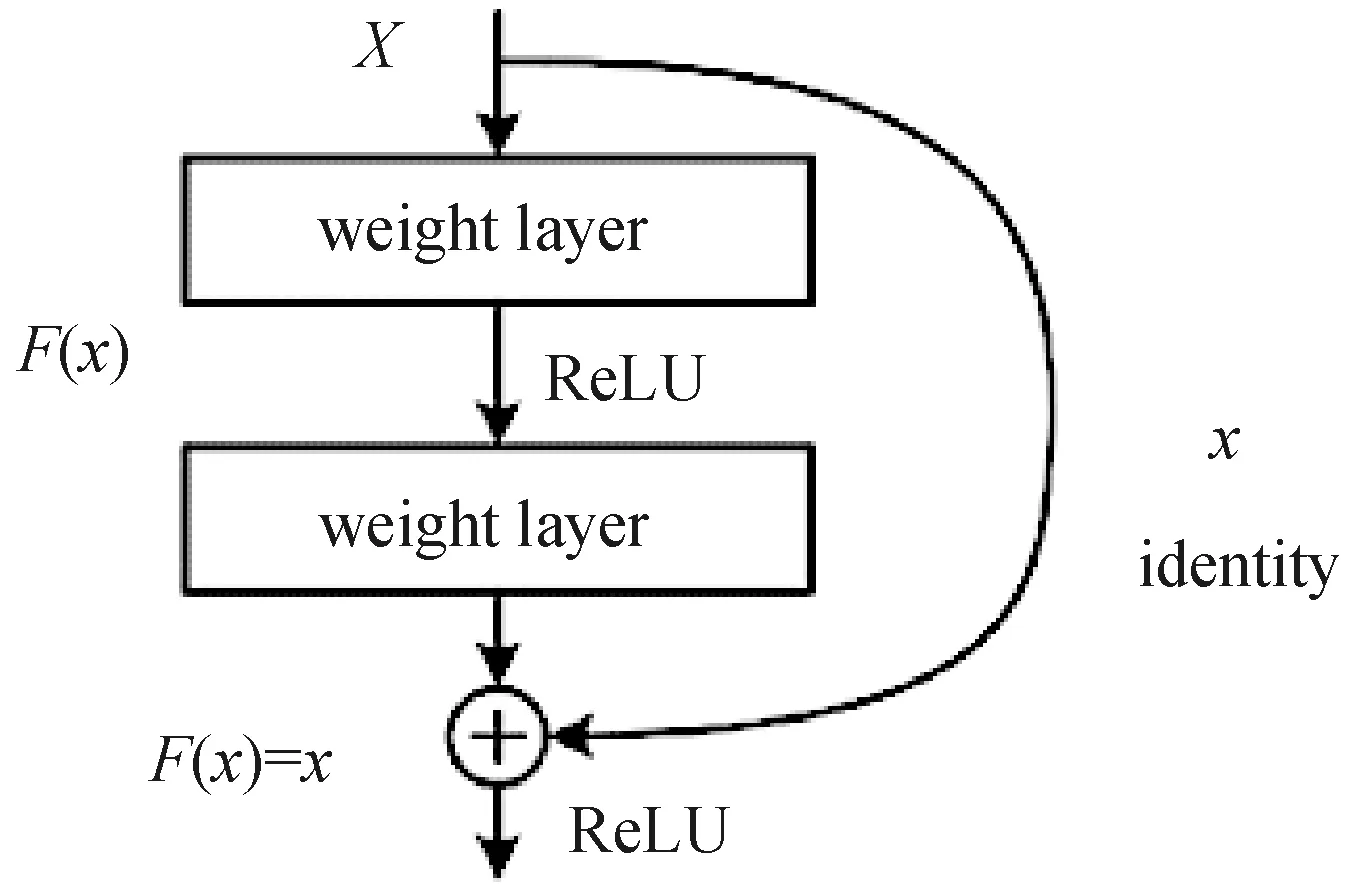
图4 ResNet中的残差单元Fig.4 Residual unit in ResNet
2017年大规模视觉识别竞赛(ILSVRC-2017)由自动驾驶创业公司Momenta提出的SENet[27](Squeeze-and-Excitation Networks)以97.749% 的top-5准确率夺冠。为提升网络性能,SENet考虑了特征通道之间的关系。该模型主要通过Squeeze(由图5中Global pooling实现)、Excitation操作(由图5中FC-FC-Sigmoid实现)自动获取每个特征通道的重要程度,然后依照其重要程度完成在通道维度上对原始特征的重标定。通过向现有网络中嵌入SE模块可以得到不同的SENet,图5展示了在Inception模块和ResNet中嵌入SE模块得到的SE-Inception模型和SE-ResNet模型。
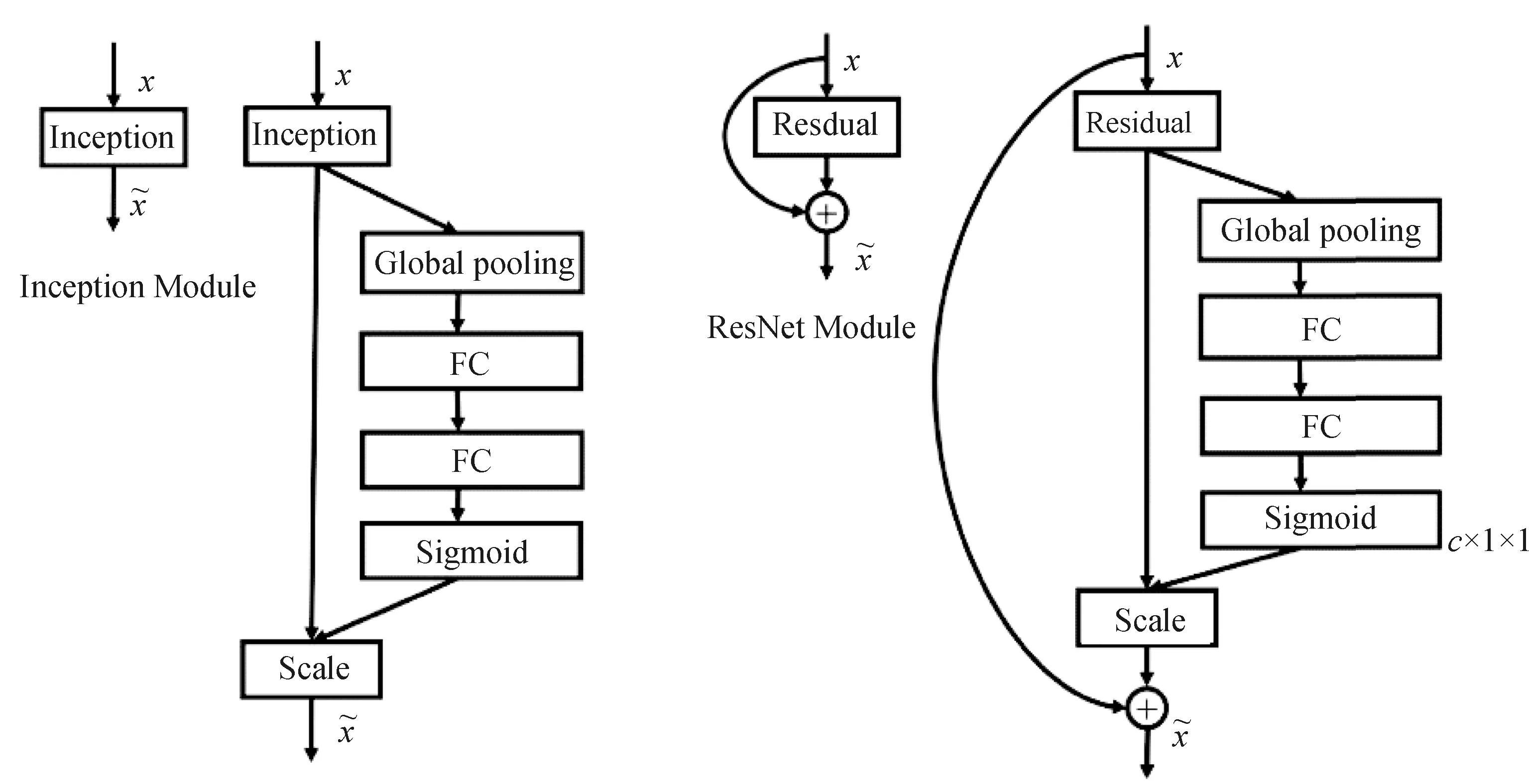
图5 SE-Inception模型(左)与SE-ResNet模型(右)Fig.5 SE-Inception module (left) and SE-ResNet module (right)
3 基于深度学习的语义分割算法
全卷积网络(fully convolutional network,FCN)解决了卷积神经网络中全连接层对语义分割的限制,因为全连接层输出是1维的,而图像分割要求2维平面每个像素的分类。同时,解决了输入图形尺寸受限的问题,全卷积网络不限制输入图像的尺寸,可生成任意大小的图像分割图。
除了全连接层,池化层也是限制卷积神经网络应用于语义分割的另一个因素。CNN靠池化层扩大感受野,以丢弃位置信息为代价聚合上下文信息。但是语义分割又要求将输出特征图恢复到原图大小,因此需要恢复位置信息。在FCN中,通过上采样恢复图像尺寸的方法克服这一局限,在保留像素级别预测结果的同时,得到了与原图大小相同的特征图[28],但上采样并不能将丢失的信息全部无损地找回来。为了更好地解决这一问题,自FCN之后出现的许多基于深度学习的语义分割算法,这些算法可以大致被分为基于编码器-解码器算法和基于整合上下文信息算法两大类。
3.1 基于编码器-解码器的算法
该算法的基本思路是通过由一系列卷积-池化操作组成的编码器结构,提取图像的主要特征信息,再通过上采样-转置卷积组成的解码器结构,逐步恢复图像的空间维度。采用该算法的网络通常选用一种卷积神经网络,如VGG-Net,然后将其全连接层替换为解码器结构。
BADRINARAYANAT等于2015年提出用于道路、车辆分割的SegNet模型[29]就是基于编码器-解码器算法的代表。如图6所示,该网络首先通过卷积层和池化层进行运算。不同于一般网络的池化层,SegNet中的池化层不仅记录最大值,还记录池化层最大值在原图中的空间位置。这就使得采用上采样方法恢复图像尺寸时,能够将相关值精准地映射到对应的位置,提高了恢复图像的精度。在解码时,使用反卷积对未被选择到池化层的像素的位置值进行填充。当被填充到与原图尺寸相同时,特征映射被输入到softmax分类器中得到最终的分割结果。SegNet记录了空间位置,使得其在上采样对图像进行恢复时,能够进行准确的恢复,然而,SegNet对于物体边界的分割精度仍然有待提高。
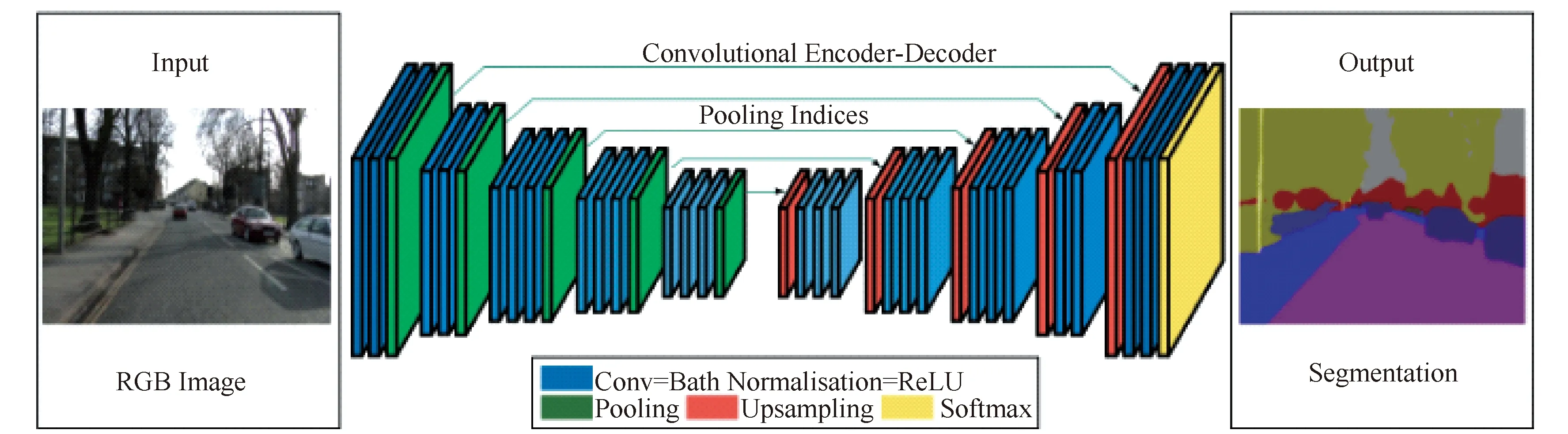
图6 SegNet结构图Fig.6 SegNet architecture
弗莱堡大学的OLAF R等于2015年提出的U-Net[13],向编码器到解码器之间引入快捷连接(shortcut connections),以增强解码器恢复局部细节的能力,其对生物医学图像的分割取得了很好效果。如图7所示,U-Net网络由一个收缩路径(图7左侧)和一个扩张路径(图7右侧)组成。其中,收缩路径遵循典型的卷积网络结构;扩张路径的每一步都包含对特征图进行上采样(upsample),同时级联收缩路径中同尺度的特征图信息,因此丰富了细节信息。
LIN等于2016年基于ResNet提出一种新的编码器-解码器架构RefineNet[30]。编码器是ResNet-101模块,解码器为RefineNet block组成的,每一个block结构,如图8所示,包含了残差卷积单元(Residual convolution unit)、多尺度融合(Multi-resolution fusion)、链式残差池化(Chained residual pooling)三部分,其连接/融合了编码器的高分辨率特征和先前RefineNet块中的低分辨率特征。RefineNet网络如图9所示,左侧将ResNet的预训练模型按特征图分辨率分为4个block,然后将这4个block通过4个可以融合不同分辨率特征图的RefineNet block 进行融合,得到融合后的特征图。RefineNet在2017年PASCAL-VOC分割竞赛上实现了83.4%的准确率。
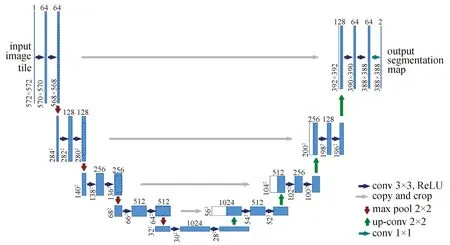
图7 U-Net结构图Fig.7 U-Net architecture
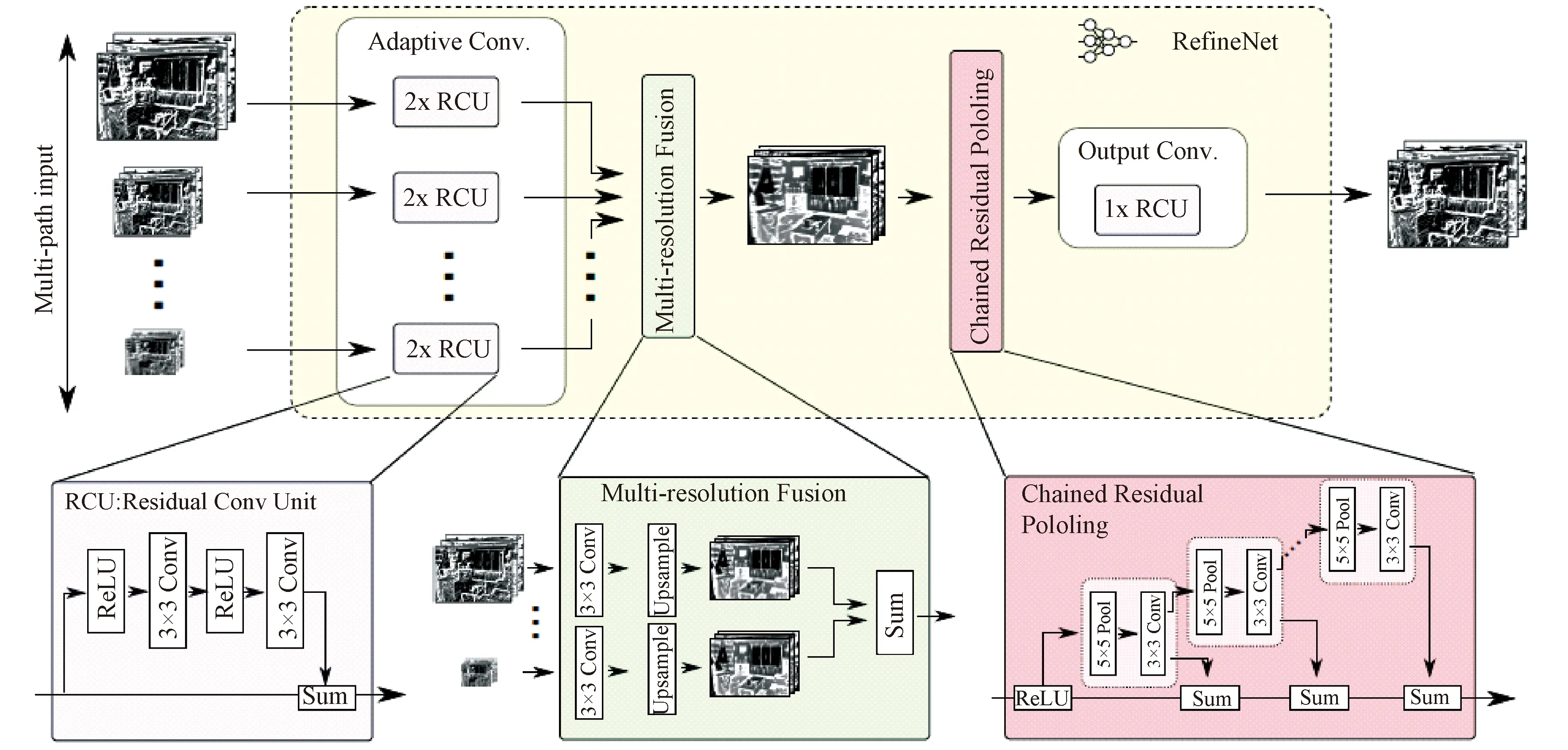
图8 RefineNet block结构图Fig.8 RefineNet block architecture
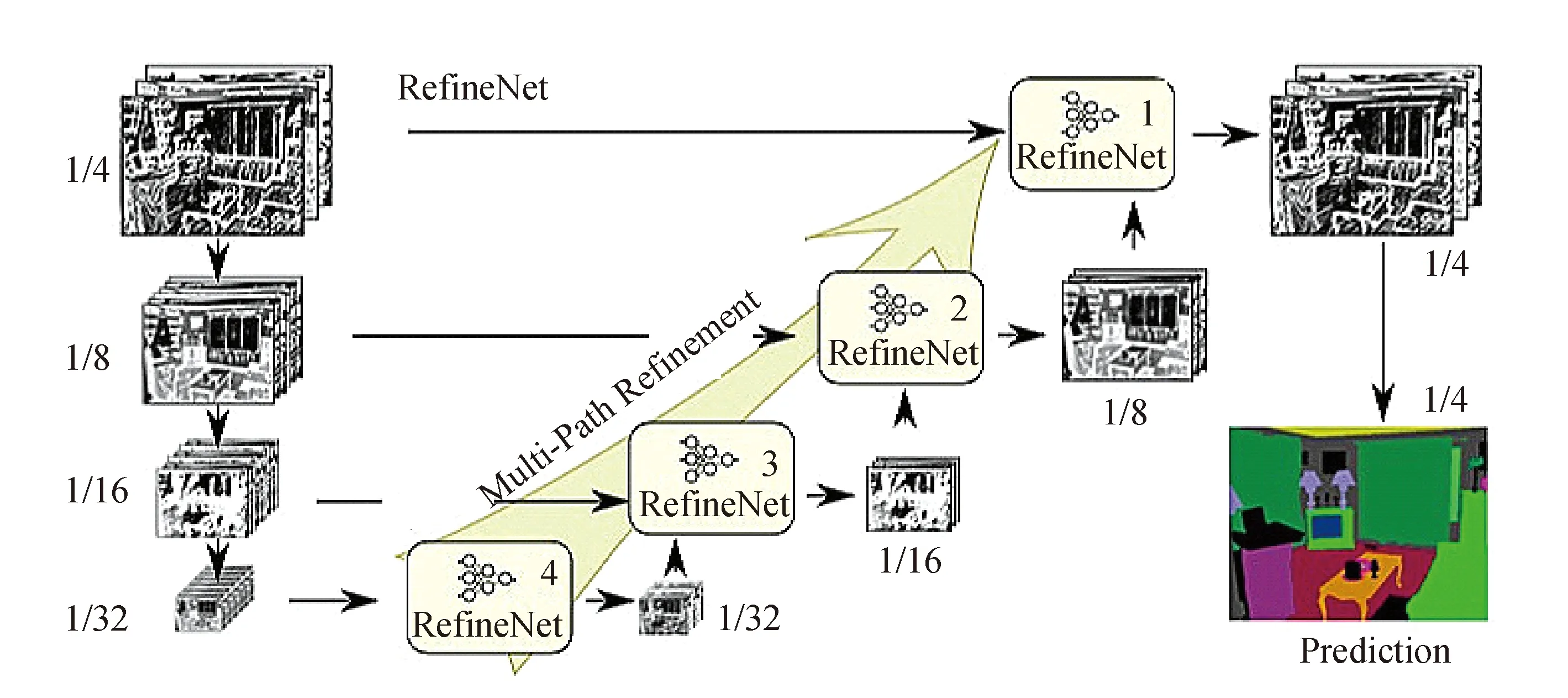
图9 RefineNet结构Fig.9 RefineNet architecture
3.2 基于整合上下文信息的算法
基于整合上下文信息算法的基本思路是整合不同尺度的特征以及在局部信息与全局信息之间寻求最优平衡。语义分割需要整合不同尺度的特征,也需要平衡局部信息与全局信息。一方面,局部信息对于提高像素级别的分类正确率很重要;另一方面,全局信息对于解决局部模糊性问题来说很关键。目前基于整合上下文信息的算法已经衍生出许多方法,例如:条件随机场[31]、带孔卷积[32]以及多尺度预测等。
(1)条件随机场
条件随机场(conditional random field,CRF)通常作为后处理的步骤单独执行。条件随机场在产生像素级标签时考虑了底层图像信息(如像素间关系),这对优化分割结果的局部细节非常重要。
CHEN等于2015年提出的DeepLab v1模型[14]使用了全连接的CRF模型作为其独立的后端处理步骤,对分割结果进行优化。该模型将每个像素建模为区域中的一个节点,无论相距多远,两个像素间的关系都会影响到像素标签的分类结果。这恢复了因CNN空间转化不变性导致的局部细节缺失。尽管全连接模型有非常大的计算量,但DeepLab v1模型采用了近似算法,大大降低了计算成本。图10展示了基于CRF后端处理对特征图产生的影响。为更好地提升CRF的处理效果, ZHENG等将CRF集成到模型内构成end2end训练[33],KOKKINOS将额外的信息(如图像边缘信息)合并到CRF内[34]。

图10 不同迭代次数的CRF下的输出Fig.10 Outputs under different interaions of CRF
(2)带孔卷积
带孔卷积又称空洞卷积,最早是由HOLSCHNEIDER等提出的一种用于信号处理的技术[32]。在卷积神经网络中,带孔卷积可以在不引入额外参数的情况下成倍增大感受野,因此,卷积神经网络不必采取大规模的池化操作以扩大感受野,避免了池化操作带来的细粒度信息丢失。带孔卷积通常与多尺度预测结合使用。
但是带孔卷积存在“gridding issue”现象,即带孔卷积在卷积核两个采样像素之间插入0值,如果扩张率过大,卷积会过于稀疏,捕获信息能力差,因为对输入的采样将变得很稀疏;且不利于模型学习——因为一些局部信息丢失了,而长距离上的一些信息可能并不相关。如图11(a)所示,通过3个3×3、扩张率为r=2的卷积核作用,对于中间像素点(红色块),其感受野为13×13,但是有贡献的像素点(蓝色块)只有49个,丢失了局部信息,信息利用率低。对此, WANG等人提出了混合带孔卷积架构(hybrid dilation convolution,HDC)[35]: 使用一组不同扩张率卷积串接构成一个block,即一个block由N个size为K×K的带孔卷积组成,其对应的扩张率为[r1,…,ri,..,rn]。HDC的目标是让最后的感受野全覆盖整个区域(没有任何空洞或丢失边缘),在扩大感受野的同时减轻“gridding issue”现象。如图11(b), 3个扩张率分别为1、2、3的3×3卷积核组成一组,在保持感受野大小不变的情况下提高信息利用率(图11(b)中蓝色标注区域大小和(a)相同,均为13×13,但贡献的像素点远远大于49)。
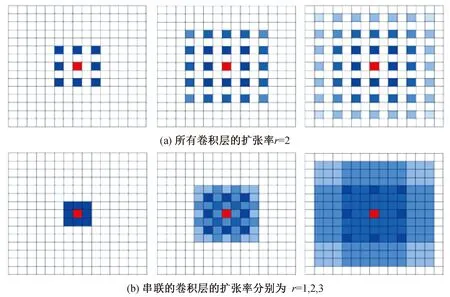
图11 Gridding issue示意图Fig.11 Illustration of the gridding issue
(3)多尺度预测
多尺度预测也是整合上下文信息的一种方法。在CNN网络中,特定尺寸的滤波器会检测特定尺寸的特征。多尺度预测的主要思想是增加多分辨率的感受野,通过融合不同尺度的特征更加有效地学习目标的特征信息,从而进一步提高目标的分割精度。
具有代表性多尺度预测算法是Deeplab v2[15]在Deeplab v1的基础之上提出的带孔卷积的空间金字塔池化(atrous spatial pyramid pooling,ASPP)。如图12所示。为了对中央的橙色像素进行分类,ASPP采用不同扩张率卷积核的带孔卷积提取不同尺度的特征,最后将不同尺度的特征进行融合,提高预测的准确率;EIGEN等提出了multi-scale convolutional architecture[36]。
图13所示的架构连接了三个不同scale的网络,并将原图作为其输入。scale1网络为粗特征提取网络,其输出与原图进行拼接后作为细特征提取网络scale2的输入,提高了分割的精度。scale2网络的输出与原图拼接后同样作为scale3网络的输入,进一步提升输出精度; ZHAO等于2016年提出了PSPNet[37]。它是在ResNet[26]基础上进一步改进,引入了空间金字塔池化,如图14所示。对于输入图像,首先通过ResNet网络提取图像特征(feature map)将得到的feature map输出到一个全局pool层,再通过一个Pyramid Pooling Module获得多个sub-region的特征表示,之后对不同维度的特征图进行上采样并拼接,得到特征表示向量,从而获得图像的局部和全局特征;最后将得到的特征表示向量输入一个卷积层,得到最后的预测结果。由于不同层级的特征表达的差异性,使用简单的叠加与连接操作进行特征融合,在分割精度提升方面的作用较小[38],因此,如何进行多尺度特征融合也是一个很有意义的研究方向。

图12 DeepLab中的ASPPFig.12 ASPP in DeepLab
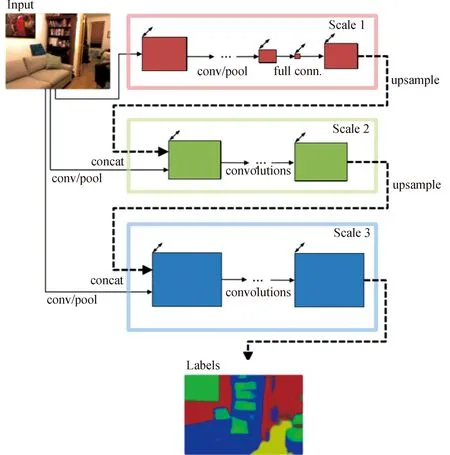
图13 EIGEN等提出的一种多尺度预测CNNFig.13 Multi-scale CNN architecture proposed by EIGEN et al.
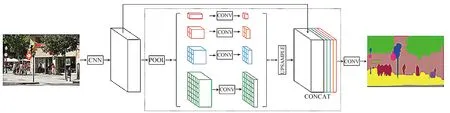
图14 PSPNet结构图Fig.14 PSPNet architecture
表2为本文提到的几种语义分割算法的比较。
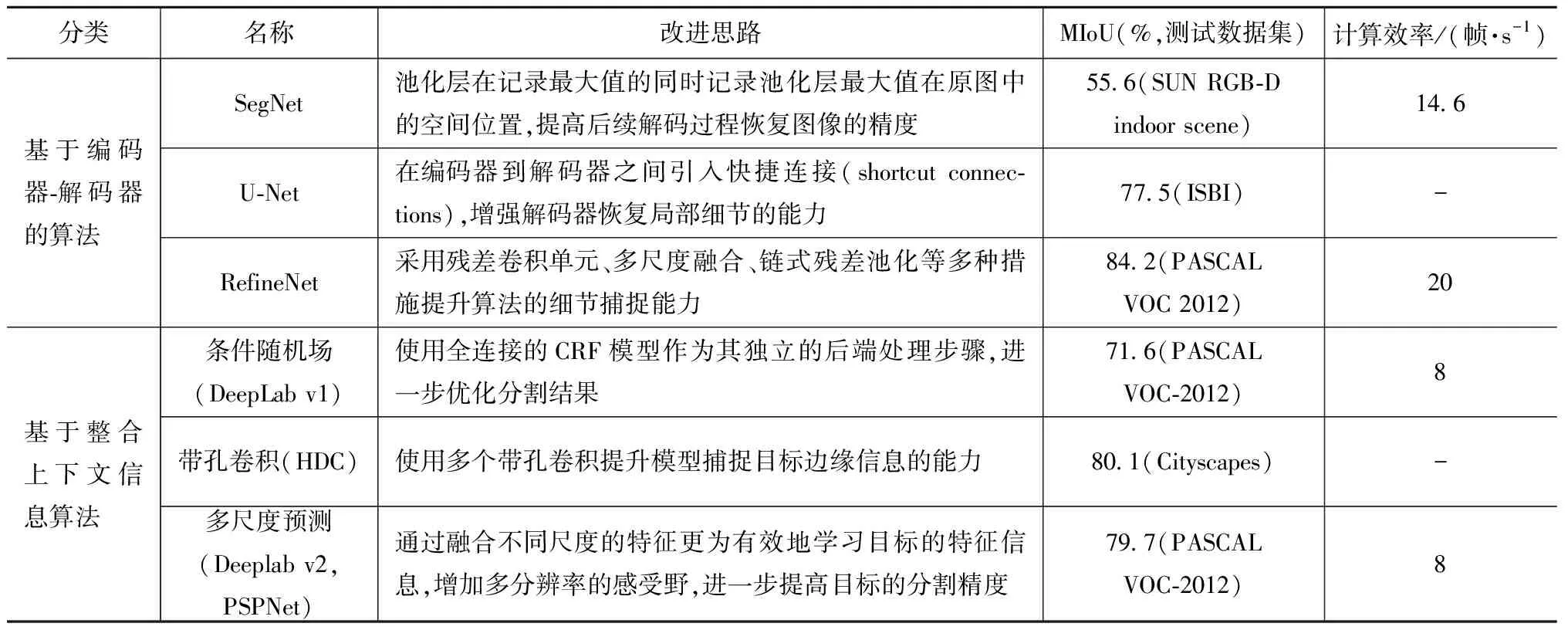
表2 语义分割算法比较
4 结束语
本文对基于深度学习的语义分割的常用网络、数据集、语义分割算法进行了综述。这里将语义分割算法分为两大类:编码器-解码器算法、整合上下文信息算法。但目前出现了很多新的方法,对这两种算法进行了各种方式的融合,如编码器-解码器架构中融入不同层级的特征,进行多尺度预测等。虽然语义分割的精度不断提升,该领域仍存在一些局限性:(1)现有语义分割方法大多是针对物体整体进行分割,通常具有较大的感受野。而很多应用场景需要对物体的零部件进行分割,称为部件分割,部件分割更关注局部细节,以获得更精确的分割边界。以在轨服务为例,要识别并定位航天器的局部部件,如螺栓孔、三角架等,直接使用已有的语义分割网络进行部件分割,效果不理想。现有的部件分割算法多数是针对人体进行设计的,在语义分割网络的基础上,借助人体姿势信息[39]或部件检测框[40]提升分割精度,网络框架复杂,迁移性差。(2)实时分割。现有方法在不断提升分割精度的同时,增大了模型的复杂度。如何降低模型的复杂度,将语义分割技术应用到对实时性有很高要求的任务中去,是未来的发展方向。(3)参数选取。选择合适的参数对于提高分割精度具有重要的作用,然而现有的方法只是依靠人工经验寻求较优参数,如何针对现有数据库的特点,自动优化网络参数,减少人为干预,也是未来的一个发展趋势。
