基于数据的铁路工程车辆速度估计模型
2019-10-25程梦周纯杰卢明舫陈斌
程梦,周纯杰,卢明舫,陈斌
(1. 华中科技大学 控制科学与工程博士后科研流动站,湖北 武汉 430074;2. 中国铁路武汉局集团有限公司 博士后科研工作站,湖北 武汉 430061;3.金鹰重型工程机械有限公司,湖北 襄阳 441000)
0 引言
我国高速铁路运营里程的不断增加对工务基础设施的维修养护提出了严峻挑战[1-3]。作为维护工务基础设施安全运转的重要部件,铁路工程车辆在保证铁路运输安全、畅通、高效方面发挥了关键作用。铁路工程车辆的作业具有地点分散、时间受限的特点,以GMC-96x型钢轨打磨车为例,南至昆明、西至青藏高原,都留下了打磨作业的大量记录[4-6]。铁路工程车辆作业需要开天窗进行,能否在时限内以良好状态保质保量完成作业任务,关系着该线路甚至其旁线的可用性与有效性。因此,铁路工程车辆作业过程中出现的故障必须进行及时有效处理,以避免对施工任务造成影响[7-8]。
为提高处理铁路工程车辆故障的效率,常见的解决方案是建立一套针对铁路工程车辆作业状态的监测系统[9-12]。监测对象通常包括铁路工程车辆各子系统和各部件的状态参数,还包括车载设备的使用与人员操作日志等。监测系统能够详细记录铁路工程车辆的工作情况,辅以准确及时的故障记录,即可形成铁路工程车辆的故障率统计报表,从宏观上了解铁路工程车辆的生命周期,优化修程计划。另外,结合专家系统,不仅能够对故障处理提供实时指导,还可从故障时间点进行回溯,探索故障前的异常工况,排查故障原因,改进铁路工程车辆的设计制造工艺。
然而,以上都是故障发生后的诊断处理与补救,建立监测系统的一个更理想化的目的是实现故障预测。故障预测与健康管理(Prognostic and Health Management,PHM)技术是航空航天与军事领域的一种先进技术[13-15],近年来被引入到铁路工程车辆、动车组等陆地交通工具的管理中。PHM技术将复杂系统从最初输入到最终决策的一整套信息通过科学严格的步骤管控起来,形成信息流动的闭环,对于铁路工程车辆的故障预测具有较大启发。
1 故障预测方法分析
故障预测根据方法的不同主要分为基于原理的预测和基于数据的预测[16-18]。基于原理的预测适合于简单对象,根据具有因果关系的各变量之间所遵循的物理或数学法则,推导出预测量的表达式,达到预测的目的。但当预测量由多个性质未知的变量共同决定时,基于原理的预测方法很难全面找出变量间的因果关系。近年来,基于数据的预测方法随着大数据的兴起而进入研究人员的视野。这一方法大量应用于金融领域,如从多年的股价数据中发现季节性与非季节性因素[19]。在工业领域,如对机床切削部件的振动情况进行时间序列分析,建立可识别的故障模式[20],也属于基于数据的预测方法。计算机软硬件高速处理与海量存储的技术日益成熟,包含着大量宝贵信息的可供挖掘的数据越来越多,铁路工程车辆监测系统所提供的数据正是满足这一要求的数据集。
以铁路工程车辆作业时的走行速度作为衡量系统健康状况的关键指标。以GMC-96x型钢轨打磨车为例,其发动机提供的最大额定速度为80 km/h,作业状态下设定速度最大为24 km/h,通常会设置为16 km/h,实际作业速度一般不高于设定速度。当铁路工程车辆处于作业状态时,其液压走行系统的动能并未发挥到100%,即系统动能存在冗余,这时液压走行系统的变量与速度之间存在对应关系。车辆健康状况不佳时,这一对应关系将被打破,因此可利用铁路工程车辆监测系统采集的数据集建立铁路工程车辆作业时的理论速度估计模型,该速度估计模型可起到分类器的作用,当实时采集的走行速度值与模型计算出的理论值差异较大时,可认为车辆健康状况不佳,从而为进一步故障预测与健康管理打下基础。PHM系统监测的变量不仅反映了车辆本身的状态,还隐含着一些通过原理分析无法涵盖的因素造成的影响,如司机操作习惯、车辆实时载质量、作业地点地理状况(坡道、弯道或平直道)等。
2018年 9月1—30日,2辆 GMC-96x型钢轨打磨车分别在兰州和济南局集团公司管内的作业速度统计见图1(2辆车出厂时间相差小于30 d),可以看出,济南局集团公司钢轨打磨车操作人员更倾向于以16 km/h的速度进行打磨作业,兰州局集团公司钢轨打磨车操作人员在12、14、16 km/h的速度下均有较多作业记录。

图1 GMC-96x型钢轨打磨车在不同地点的相同月份内作业状态下的走行速度统计
上述2辆钢轨打磨车在相同月份进行打磨作业时在各自作业地点所遇到的走行压力值统计见表1,可以看出,工号6499打磨车遇到的平均走行压力小于工号6509打磨车,且前者的走行压力变化较为和缓,后者的走行压力变化较为剧烈。走行压力的瞬时变化与车辆自身载质量、司机操作习惯、作业地点地理状况(坡道、弯道还是平直道)都有关系。

表1 GMC-96x型钢轨打磨车9月份打磨作业走行压力统计 MPa
如果仅依靠机械与车辆原理建立相关变量与铁路工程车辆作业速度间的函数表达式是相当困难的,因为类似于司机操作习惯、作业地点地理状况等影响速度的变量很难量化或精确表示。但这些变量的影响隐含在铁路工程车辆各部件加装的传感器所实时测量并记录的数据中,因此基于数据的预测方法在这一场景下应与基于原理的预测方法结合起来,共同推导建立铁路工程车辆作业时的走行速度估计模型。
2 铁路工程车辆PHM系统架构
为获取铁路工程车辆的作业数据,搭建1个针对铁路工程车辆的PHM系统(见图2)。在系统底层,由铁路工程车辆出厂前即已安装在系统各部件上的传感器采集铁路工程车辆上线作业时的实时工况,汇聚至车载可编程逻辑器件(Programmable Logical Chips,PLC),连同定位系统采集的车辆位置信息及人员操作信息,按照提前设置的通信协议一同通过由车-地无线传输和地面网络传输两部分构成的传输通道回传至地面数据中心;地面数据中心的数据存储平台对接收到的工况数据、系统配置数据、后台管理数据进行分类存储,智能化分析平台运用存储数据提供故障诊断、故障预测、健康管理等功能,平台得出的评判预测结果可为管理、维修决策提供支持。
作为数据来源的PHM系统中的打磨车共有8台,分布在5个铁路局集团公司管内。这些打磨车距离出厂时间最长5年,最短仅半年。车辆上线开始作业时,即启动传感器进行数据采集与回传,数据上报周期为1条/s,地面数据中心至少存储每辆车最近半年内的作业数据。受限于某些技术原因,传感器仅能采集牵引动车的工况数据,无法采集作业机构的相关数据。

图2 铁路工程车辆PHM系统架构示意图
由于铁路工程车辆的速度主要受控于液压走行系统,介绍与速度相关的作业数据分析过程,并根据车辆机械原理确定走行四元组,进行相关性分析与特征提取,进而建立估计模型。
3 铁路工程车辆作业数据分析
3.1 数据采集与处理
车载数据收集模块对铁路工程车辆作业时的实时状态数据进行采集和转换,将各种连续或离散的物理量转变为可处理且方便传输的数字信号,其监测对象包含发动机转速、车速、发动机工作时间、累计行驶里程、发动机故障代码、蓄电池电压、发电电流、燃油箱油量等。数据收集模块与数据处理模块间的通信协议见表2。
表2 车载数据收集模块与数据处理模块间的通信协议

参数类型 参数名称 序号 说明数据采集器Life信号 Life信号 0 0~255数据帧格式 帧格式命令 1 55(十进制)发动机参数 2~39预留 40~47 8字节预留校验和 累加校验和 48
受限于客观条件,采用的传感器无法直接测量油泵和马达排量,退而测量控制油泵或马达排量的电压读数,根据控制电压与排量间的线性对应关系,间接获取油泵和马达的排量。一般油泵的控制电压与其排量成正比,而马达的控制电压与其排量成反比。控制电压的量程一般为[0,10]V,电压传感器量程为[0,27 648],也即当电压传感器取值为最大值27 648时,意味着控制电压取到最大值10 V。
将采集到的每条作业数据看作一个样本,则一次时长约2 h的作业中将产生7 000多个样本。样本中的每一列即每个监测物理量称为特征,则根据协议的不同,样本中的特征少则几十个,多则上百个。将样本中与速度相关的特征抽取出来,按照时间顺序组成一个数据集,也可看作一个数据矩阵:依次以作业时间为行索引,以所关注的特征为列索引。删除重复与空白数据,对离群点进行平滑处理,即执行数据校验与清洗步骤。
3.2 相关性分析
铁路工程车辆在作业状态下,有时需要在前进与后退2个方向上来回作业。前进时,I位走行系统工作,II位走行系统关闭;后退时则相反。PHM系统采集到的瞬时速度值,用数值前的正号表示前进、负号表示后退。为分析方便,只关注铁路工程车辆一边前进一边作业下的速度。根据加速度a表达式a=dv/dt和牛顿力学定律(a=F/m)可知,速度由物体受到的力间接决定。铁路工程车辆在作业时除了受到马达提供的牵引力作用外,还受到由自身重力及地理环境、路轨状况和司机驾驶习惯共同造成的走行压力。
根据机械和车辆原理,油泵是一种将机械能转化为液压比的动力元件,而油马达是一种将液压能转化为机械能的执行元件[21]。马达背压由马达出口背压阀的控制电压决定,马达背压与走行压力形成压差,压差与马达排量共同决定马达的输出扭矩。因此,在所取得的传感器数据样本中,除了设定速度与实际速度外,还应关注的特征有走行压力、马达背压控制电压、油泵排量控制电压、马达排量控制电压。这4个特征构成影响铁路工程车辆作业速度的走行四元组。
为了检验所选取的特征与铁路工程车辆作业速度间的相关性,计算各个特征分别与作业速度间的Pearson's R值。Pearson's R值是统计学的一个概念,用来表示2个向量间的相关程度[22],R的取值范围为[-1,1]。当R值为0时,表示2个向量不具备线性相关性;当R值为正时,表示2个向量正相关,R值越大正相关性越强;当R值为负时,表示2个向量负相关,R值越小负相关性越强。同时对于计算得到的Pearson's R值进行显著性检验,得到显著性检验的P值。走行四元组与作业速度间的Pearson's R值和相应的P值计算结果见表3。
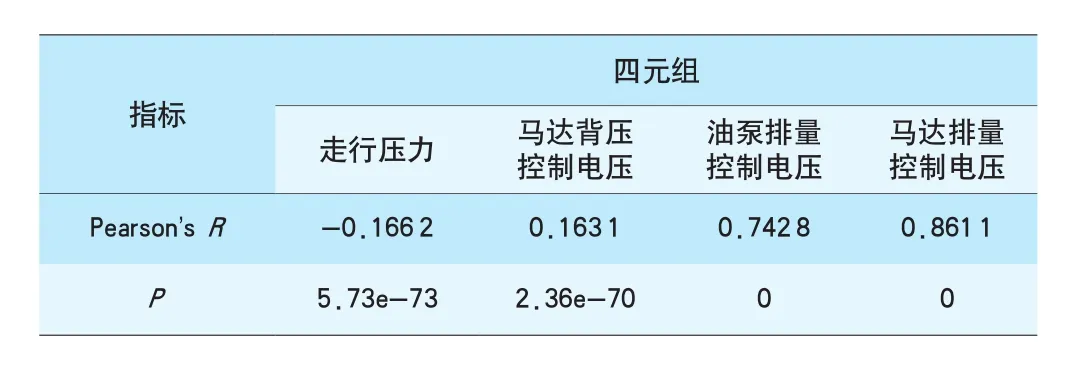
表3 走行四元组与铁路工程车辆作业速度的相关性
4 基于铁路工程车辆作业数据的速度估计模型
4.1 模型框架
令走行压力为M,马达背压控制电压为B,油泵排量控制电压为O,马达排量控制电压为Q,则建立速度估计模型就是要得出如下表达式:
v=f(M,B,O,Q)。 (1)速度与这些特征的排量组合存在隐含关系,即:v=px+q, (2)式中:x为g(M,B,O,Q);p和q为有待通过数据确定的参数;f(*)和g(*)均为形式未知的函数。
首先,利用PHM系统提供的数据对走行压力M和作业速度v进行可视化,结果见图3。图3(a)所示为按照时间先后顺序展示在铁路工程车辆作业过程中v和M的变化情况,可见,当铁路工程车辆将速度保持在固定值进行作业时,仍会经历走行压力的随机波动,这一波动可能是由铁路工程车辆作业的地理状况引起的。图3(b)中的每一个点代表一个样本,当M小于20 MPa时,铁路工程车辆可能遍历所有的作业速度值;当M大于20 MPa后,铁路工程车辆倾向于采用较低的作业速度。图3(c)所示为将走行压力相同的所有样本抽取出来,对这些样本的作业速度取均值,得到该走行压力下的平均作业速度,可以看出,当M小于20 MPa时,铁路工程车辆以约13 km/h的平均速度作业;随着M大于20 MPa,铁路工程车辆的平均作业速度立即降低;当M大于25 MPa时,铁路工程车辆以约1 km/h的平均速度作业。

图3 铁路工程车辆走行压力与作业速度变化情况
结合图3和表3的结果可知,走行压力M与作业速度v之间呈相关系数较低的负相关,因此可将其从走行四元组中剔除,而是作为一个外部的速度估计辅助条件。
4.2 特征提取
与铁路工程车辆作业走行速度相关的另外3个特征变量B、O、Q都是系统的控制电压,分别控制马达背压、油泵排量和马达排量。为了找出这3个控制电压与走行速度间的关系,首先对这3个特征进行维度规约,即从这3个特征中提取出1个控制电压的新特征。将B、O、Q的样本构成的数据集记为{xn},其中n=1,…,N(N为样本个数),即为从PHM系统中取出的工况条数,xn是一个d维变量,这里d=3,xn=[xB、xO、xQ]。接下来利用主成分分析(Principal Component Analysis,PCA)方法将数据投射到一个k(k<d,这里k=1)维空间里,使得投射后的数据方差最大,PCA是机器学习算法中的一种非监督学习方法[23]。k维空间的方向由一个d维向量u1定义,且u1Tu1=1,则 xn的每个数据点都被投射到一个标量u1Txn上。投射数据的均值为为数据集的均值)。投射数据的方差计算如下:

式中:S为数据集的协方差矩阵。优化目标是最大化投射数据的方差,即求令式(3)最大的向量u1。因为||u1||=1,引入一个拉格朗日乘子λ1,使得最大化目标由式(3)转化为:

将式(4)置0,可得1个平稳点:

这意味着u1必须是S的一个特征向量。式(5)两边同时左乘根据可以看到投射数据的方差为因此,想要最大化投射数据的方差,u1必须取S具有最大特征值λ1的特征向量,即所谓的第一个主成分。
将B、O、Q的样本数据代入上述PCA分析过程中,N=11 659,得到主成分 u1=[-0.168 5,-0.245 9,-0.954 5],将投射到u1上得到的新特征记为xBOQ,则xBOQ与v的可视化结果见图4。
由图4(a)可以看出,从马达背压、油泵排量、马达排量这3个物理量所对应的控制电压中提取出来的新特征与作业速度呈现一种分段的线性对应关系。当xBOQ小于6时,斜率较平缓;当xBOQ大于6时,斜率较陡。在xBOQ的整个值域内,铁路工程车辆作业速度都跟它呈线性负相关。对数据求滑动平均,并利用最小二乘法进行拟合后,得出作业速度v的表达式(2)可具体写为:

图4 铁路工程车辆控制电压新特征与作业速度变化情况

式中:x=xBOQ。由PCA分析过程可知式(6)可进一步写成:

利用式(7)可在已知走行系统提供的马达背压、油泵排量、马达排量等物理量控制电压的情况下,估计出该时刻系统的理论速度值。进行简单计算可得,在训练数据集上运用该解析式得到的理论速度值与实际值相比,均方误差(Mean-Square Error,MSE)为0.454 2,MSE是一种常用的统计参数,指预测数据与原始数据对应点间的误差平方和的均值。铁路工程车辆作业速度与走行压力、控制电压新特征间的关系见图5。

图5 铁路工程车辆作业速度与走行压力、控制电压新特征间的关系
4.3 模型验证
为了验证铁路工程车辆作业速度估计模型的有效性,选取训练数据集的来源铁路工程车辆,取得它在比所取得的训练数据更新的月份中的作业工况作为测试数据集。特征提取时使用的训练数据集是工号6509钢轨打磨车在9月份的作业数据(共422 339条),模型验证的测试数据集选取的则是该钢轨打磨车在11月份的作业数据(共303 649条),对测试集数据进行一系列常规数据处理步骤后,将所提出的速度估计模型应用到测试集上,得到估计的理论速度值与实际值间的关系(见图6)。作业速度估计模型在测试集上的MSE为0.541 2。
从验证结果来看,基于训练集数据建立的作业速度估计模型,在测试集上有较好的估计精度,但略差于在训练集上的表现。原因可能是多方面的,如测试集数据比训练集数据晚2个月,在这2个月的时间内车辆各子系统性能发生了非线性退化,且气温、湿度等也有较大变化,都会对走行系统的各项参数造成影响。对于PHM系统而言,针对具体铁路工程车辆的速度估计模型应不断进行周期性迭代,围绕新采集的数据进行特征提取,对模型持续修正,以提高估计精度。

图6 铁路工程车辆速度估计模型验证结果
5 结束语
保证铁路工程车辆的正常作业是提高铁路运输效率与安全性的必要条件,而铁路工程车辆故障预测的实现依赖于对作业速度进行有效估计。然而单纯依赖车辆和机械的基本原理对速度建立估计模型,却因无法将司机操作习惯、作业地点地理状况等隐性因子考虑在内而效果不佳。未知或难以量化的隐性因子隐藏在铁路工程车辆的作业数据中,针对这种情况,提出一种基于铁路工程车辆作业大数据的速度估计模型,并以GMC-96x型钢轨打磨车的40多万条数据为例,经特征提取后拟合得出模型,在测试集上估计结果的MSE仅为0.541 2,这一速度估计模型将进一步服务于铁路工程车辆的健康管理。在后续研究中,随着PHM系统积累数据量及铁路工程车辆故障数量的增加,可进一步训练分类模型,性能指标也应从作业速度向其他物理量扩展。
