基于自动化测试的定向网络爬虫的设计与实现
2019-10-23朱丽英吴锦晶
朱丽英, 吴锦晶
(公安部第三研究所 物联网技术研发中心, 上海 201204)
0 引言
在过去几年中,人工智能出现了爆炸式的发展,其在交通和治安领域中的应用场景越来越多元化,其中车辆品牌、款系和年代识别功能不仅有助于套牌车辆筛查,而且正逐步发展成为刑侦工作中的重要技术手段。为实现车辆品牌、款系和年代识别功能,需要人工标注大量的训练样本,而人工标注过程中需要相应的车辆品牌图片进行参考。基于建立车辆品牌参考库的迫切需求,本文提出了一种基于自动化测试的定向爬虫程序的设计与实现。通过自动化测试技术模拟人浏览网页的方式,自动化地采集指定网页的车辆品牌外观图片,从而建立一个款系、年代分类别存储的车辆品牌参考库。
1 网络爬虫技术
网络爬虫技术[1]又被称为网络机器人、网路蜘蛛,是一种按照规则,自动抓取信息的程序或者脚本,是用户从互联网中获取信息资源的有效工具。通用网络爬虫[2]从一个或若干初始网页的URL开始, 获得初始网页上的URL列表;在抓取网页的过程中,不断从当前页面上抽取新的URL放入待爬行队列,直到满足系统的停止条件。通用网络爬虫的目标就是尽可能多地采集信息页面,而在这一过程中它并不太在意页面采集的顺序和被采集页面的相关主题。
然随着网络的不断普及,网络上的海量信息呈爆炸式增长,用户的需求也越来越个性化,定向网络爬虫应运而生。定向网络爬虫,顾名思义就是定向爬取目标网站,该种方法只对系统指定的网址进行数据采集,通过在系统中根据目标网站的特点设定的模板,可以使系统达到很高的数据精度。另外,对于网页更新速度快的数据源,采用增量式的采集方法也是尤为必要的[3]。增量式网络爬虫是指对已下载网页 采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面,可有效减少数据下载量,减小时间和空间上的耗费。
本文聚焦车辆品牌外观图片的爬取,网络爬虫的过程是以一个URL为初始点,获取该网页上的多个URL,放入URL列表进行循环获取,直到满足停止条件。为提高工作效率,通用网络爬虫会采取一定的爬行策略,常用的爬行策略[4]有深度优先策略、广度优先策略。本文采取深度优先策略,其基本方法是从根节点出发,依次访问下一级叶子节点的网页链接,直到不能再深入为止。爬虫在完成一个爬行分支后返回到上一链接节点进一步搜索其它链接。当所有链接遍历完后,爬行任务结束。URL爬行模型如图1所示。
2 自动化测试工具Selenium
自动化测试[5]是基于手工测试而存在的,主要通过相应的软件测试工具、脚本等来实现,具有较好的可操作性、可重复性和高效率等特点。Selenium是一个开源的、便携式的自动化软件测试工具,提供一套测试函数,用于支持Web应用程序的自动化测试,函数非常灵活,能够完成界面元素定位、窗口跳转、结果比较等,具体有如下特点:能在不同的浏览器进行测试,如IE、Mozilla Firefox、Mozilla Suite、Safari、Chrome、Android手机浏览器等;支持多种语言,如Java、Python、C#、Ruby等;支持多种操作系统,如Windows、Linux、IOS、Android等。
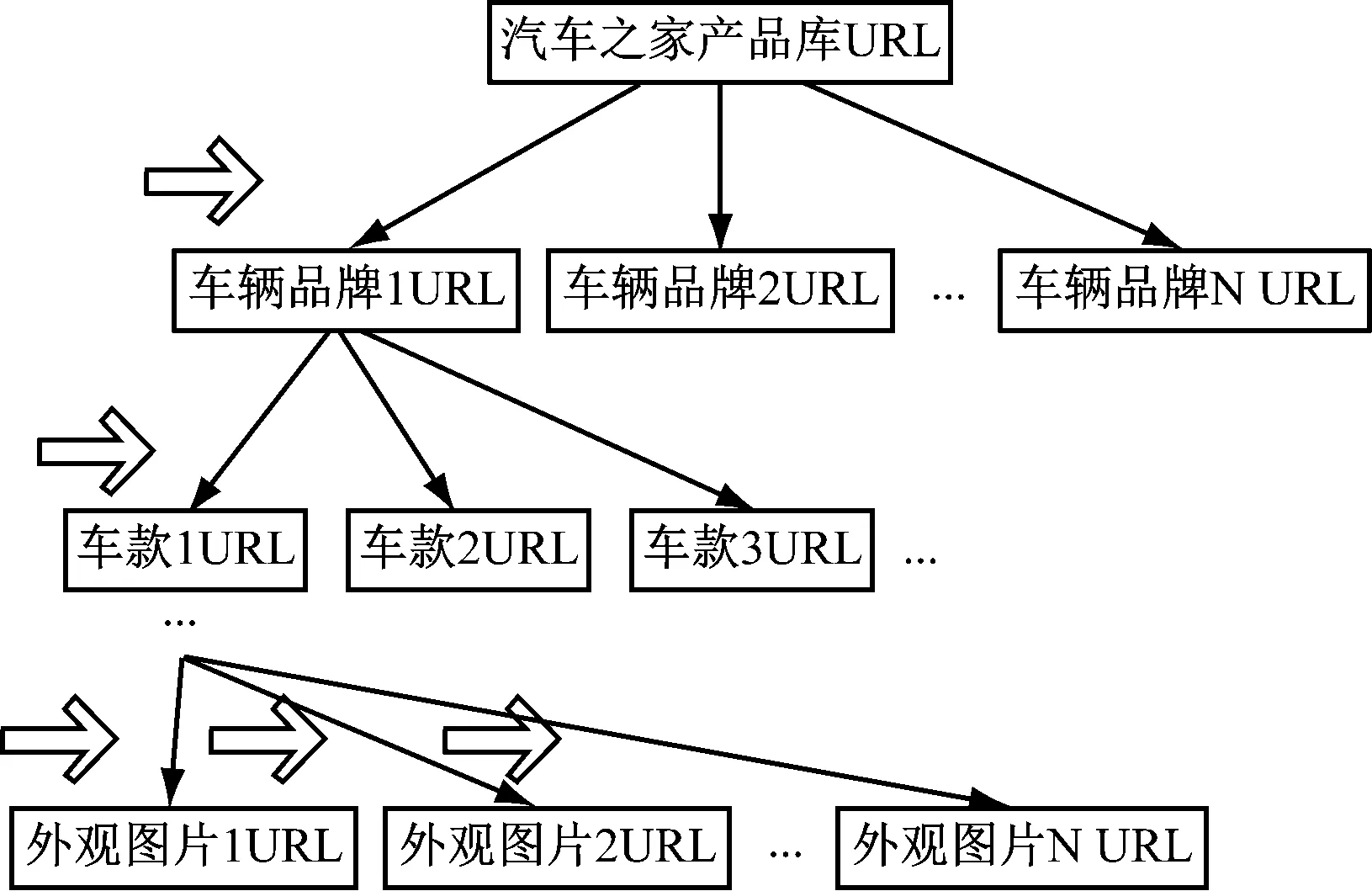
图1 URL爬行模型
目前网页广泛采用JS加载、Ajax 异步传输、前端MVC等动态技术,这些技术对于以静态页面分析为主的传统网页爬虫提出了新的挑战,解决这种问题唯一的办法是让爬虫自己变成一个没有界面的浏览器。基于Selenium的网络爬虫能够绕过某些页面对于爬虫的检测和限制[6],它具有简单、灵活、仿真性强等优点,且可进行基于无头浏览器的数据抓取和捕获,本文采用自动化测试框架Selenium,以Python语言编写网络爬虫程序,模拟人操做浏览器的方式,采集车辆品牌外观图片。
3 系统的设计与实现
车辆品牌爬虫的具体功能是对汽车之家品牌库内的所有品牌对应的外观图片进行抓取,存储到本地磁盘。图片存储时需按照图片对应的品牌、款系、年份等分类别存储,具体类别格式如“上汽大众 凌渡 2014款 概念版”、“上汽大众 凌渡 2015款 230TSI 手动风尚版”。另外,新车型不断上市,汽车之家的品牌库亦会不断更新,为获得新品牌图片,需要具有对网站新变动的部分进行数据分析提取功能,达到增量式爬取的效果。
车辆品牌爬虫整体流程如图2所示。
启动Selenium,以无头方式打开Chrome浏览起器,并加载汽车之家品牌库URL。
3.1 品牌款系URL提取
在页面解析,品牌款系URL、图片数量提取的过程中,利用了Selenium的如下特性。
1)元素查找
Selenium中元素查找共有八种方法,可通过id、name、className、tagName、linkText、partialLinkText、xpath、cssSelector定位元素,其中的xpath定位具有更大的灵活性,对于html文档树中某个节点既可以向前搜索,也可以向后搜索,且可采用绝对定位方式或相对定位方式。本系统中主要通过xpath、 id、linkText等方式寻找特定页面元素,如下述方法获取品牌树下的所有品牌链接:driver.find_elements_by_xpath("//div[@class='cartree']/ul/li/h3/a")。
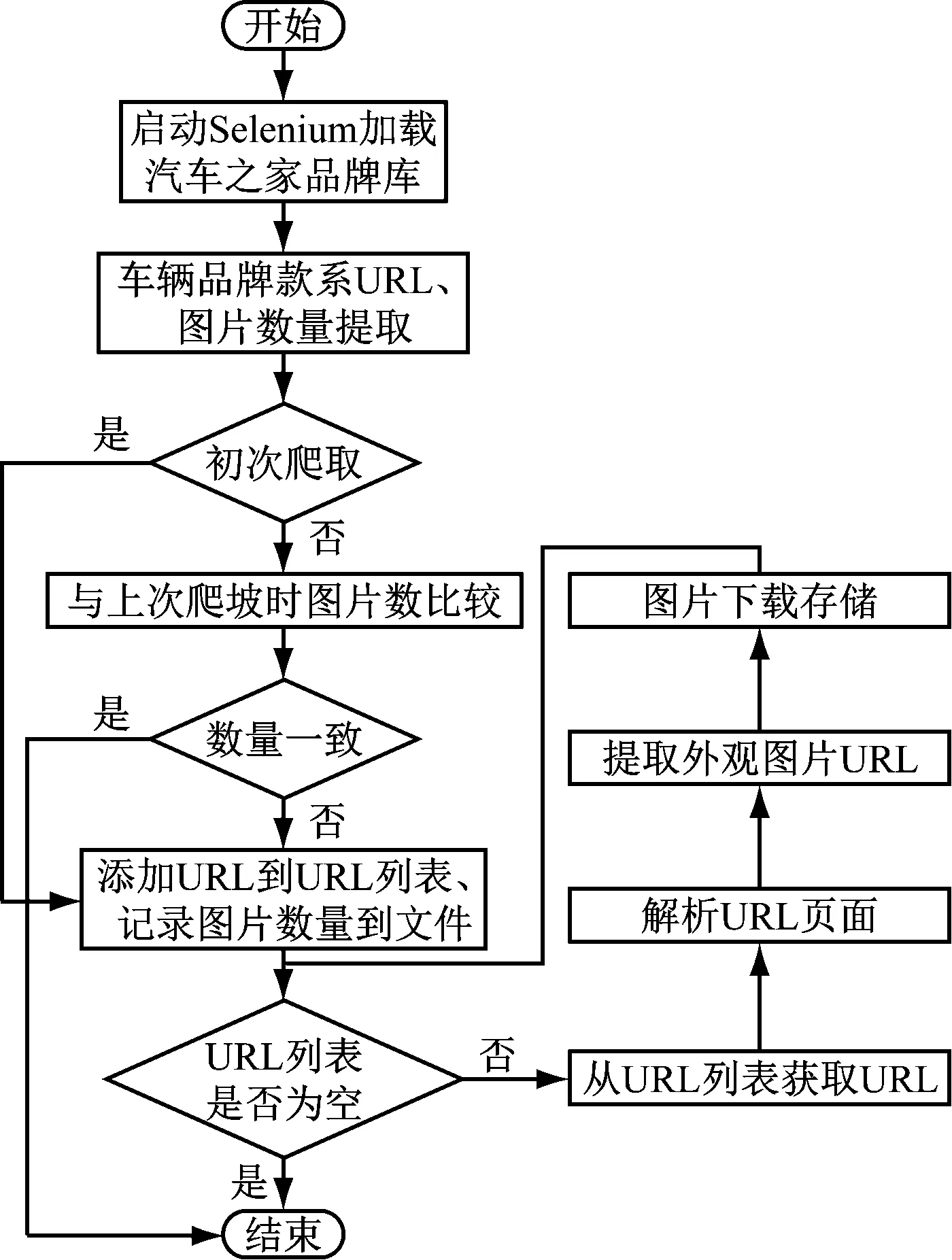
图2 整体流程
2)鼠标交互
通过Click操作页面元素。进入子品牌页面,“车身外观”、“下一页”、“查看停产车型”等的页面切换都是通过模拟鼠标点击操作完成。
3)异常处理
通过页面元素查找失败的异常捕获,来判断页面上元素是否存在。
4)属性获取
通过元素属性获取方法get_attribute可获得元素的各个属性,如通过son_brand_ele.get_attribute('href')获得品牌车款URL。
品牌款系URL提取的过程如图3所示。
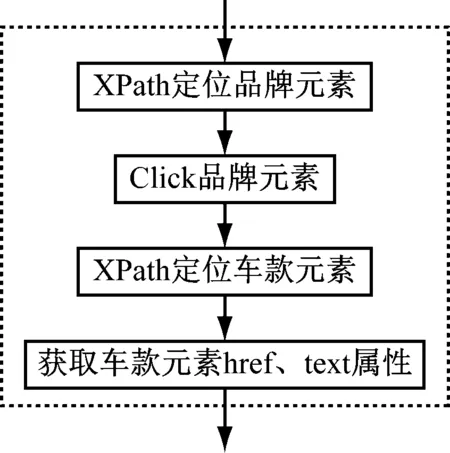
图3 品牌款系URL提取过程
3.2 增量式爬取
市面上新的车型不断上市,汽车之家网站的品牌库亦频繁更新,因此车辆品牌爬虫需不定期地爬取这一网站。为避免重复数据爬取,提高爬取效率,系统增加了对网站新变动部分的数据分析提取功能,在重复爬取时,仅对变动部分进行爬取。
车辆品牌爬虫系统在爬取过程中对品牌图片数量进行了记录。爬虫启动后,在车辆品牌款系URL提取时,同时提取了当前网站各车辆品牌款系存在的图片数量,而上次爬取时各车辆品牌款系的图片数量则从文件中读取,比较两者的一致性,当两者不一致时,才将车辆品牌款系URL加入到URL队列。
3.3 图片下载存储
每个车辆品牌的图片数量多寡不一,每种车款对应的“车身外观”页面,元素“下一页”、“查看停产车型”不一定存在,因此,通过页面元素查找失败的异常捕获,来判断页面上上述元素是否存在。并且,每一图片的URL是固定不变的,通过URL提取的图片名称也是固定不变的,因此,当重复爬取时,可通过与已抓取图片的名称比较,来判断该图片是否已被抓取,只有本地磁盘中不存在的图片才进行抓取,图片下载存储流程如图4所示。

图4 图片下载存储流程
4 总结
本文在充分观察了汽车之家网页结构之后,利用自动化测试工具Selenium,设计和实现了基于汽车之家品牌库的定向网络爬虫。通过增量式的爬取,使得该爬虫系统能够非常高效地抓取目标数据。通过本爬虫系统,为车辆品牌识别系统提供了相对完备的品牌参考库。
