基于LSTMP语音识别方法的研究与改进
2019-10-21孙由玉孙宝山卢阳
孙由玉 孙宝山 卢阳
摘 要:当前LSTMP是基于LSTM增加了Projection层,并将这个层连接到LSTM的输入,通过循环连接投影层,对高维度的信息進行降维,减小细胞单元的维度,从而减小相关参数矩阵的参数数目。但LSTMP网络结构的缺点在于Projection层的输出需要完成两个功能,既需要充当历史信息,又需要作为下一层的输入。针对以上问题,笔者提出了一种Re-dimension的方法,让网络自己选择一部分参数作为历史信息,并获得了一定程度的提升。采用该方法后,能提高语音识别率相对4-5%左右。
关键词:长短时记忆LSTM;降维;语音识别
Abstract:Currently,LSTMP is based on LSTM,which adds a project layer and connects this layer to the input of LSTM. By circularly connecting the projection layer,it reduces the dimension of high-dimensional information,reduces the dimension of cell units,and thus reduces the number of parameters of the related parameter matrix. However,the disadvantage of LSTMP network structure is that the output of the Projection layer needs to complete two functions,which need to act as both historical information and input of the next layer. In view of the above problems,the author proposes a Re-dimension method,which allows the network to select some parameters as historical information,and has achieved a certain degree of improvement. With this method,the speech recognition rate can be improved by about 4-5%.
Keywords:LSTM for long-term and short-term memory;dimensionality reduction;speech recognition
0 引 言
随着移动互联网的兴起,语音识别技术正在走进人们的生活,这给人们的工作、学习和生活提供了一种快捷识别的方式。近年来,基于深度全连接前馈神经网络的声学模型已被证明是语音识别的成功范例。最近,将循环神经网络作为一种强大的模型进行了探索,循环神经网络在不同的顺序数据建模任务中取得了最先进的性能,例如:手写字符识别,机器翻译以及语音识别[1]。
基于长短期存储器(Long Short-Term Memory,LSTM)的存储器块通过输入门[2],输出门、遗忘门和存储器单元的集成来运行。通过该LSTM,循环神经网络可以利用自学习机制用于远程时间上下文,这有助于改善语音识别中的噪声鲁棒性[3],其中较长窗口内的一部分帧被噪声掩蔽。已经实施LSTM网络以在不同的语音识别任务中实现竞争性能,提出了具有各种架构的LSTM网络的一些扩展以改善语音识别性能。LSTM循环投影作为统一框架引入,通过添加基于LSTM单元输出的循环信息的前馈层并进一步将信息投影到输出层。同时,通过LSTM单元细胞之后或之前安排全连接前馈神经网络来调整LSTM结构。LSTM架构是一种非常特殊的循环神经网络,用于对语音等顺序数据进行建模。它最近被广泛用于大规模声学模型估计,并且比许多其他神经网络表现更好。但是由于LSTM的运行速度很慢,所以有人提出了LSTMP网络结构。
LSTMP是LSTM with recurrent projection layer的简称,是在原有LSTM基础之上增加了一个Projection层,并将这个层连接到LSTM的输入,Projection层的加入是为了减少计算量,它的作用和全连接层很像,就是对输出向量做一下压缩,从而能把高维度的信息降维,减小细胞单元的维度,以减小相关参数矩阵的参数数目。但是Projection层的输出需要完成两个功能,既需要充当历史信息,又需要作为下一层的输入。
针对这种情况,本文提出了一种Re-dimension的方法,让网络自己选择一部分参数作为历史信息,并获得了一定程度的提升。通过采用改进的LSTMP方法,提高了LSTMP的性能,使语音识别率相对提高了4-5%左右。
1 LSTM网络
LSTM(Long Short-Term Memory)长短期记忆网络,是一种时间递归神经网络(RNN)[4],主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。所有RNN都具有一种重复神经网络模块的链式的形式。在标准的RNN中,这个重复的模块只有一个非常简单的结构即一个tanh层[5]。如图1所示。
LSTM与之不同的是其有四个神经网络层,并且以一种特殊的方式进行交互。其关键就是细胞状态,并且精心设计了“门”结构来控制细胞状态。其内部主要有三个阶段:第一阶段是由忘记门来决定丢弃什么样的信息;第二阶段是选择何种新信息进入细胞状态,称为选择记忆阶段;第三阶段是决定输出什么样的值。四个神经网络层,如图2所示。
2 LSTMP网络基本思想
2.1 LSTMP基本结构
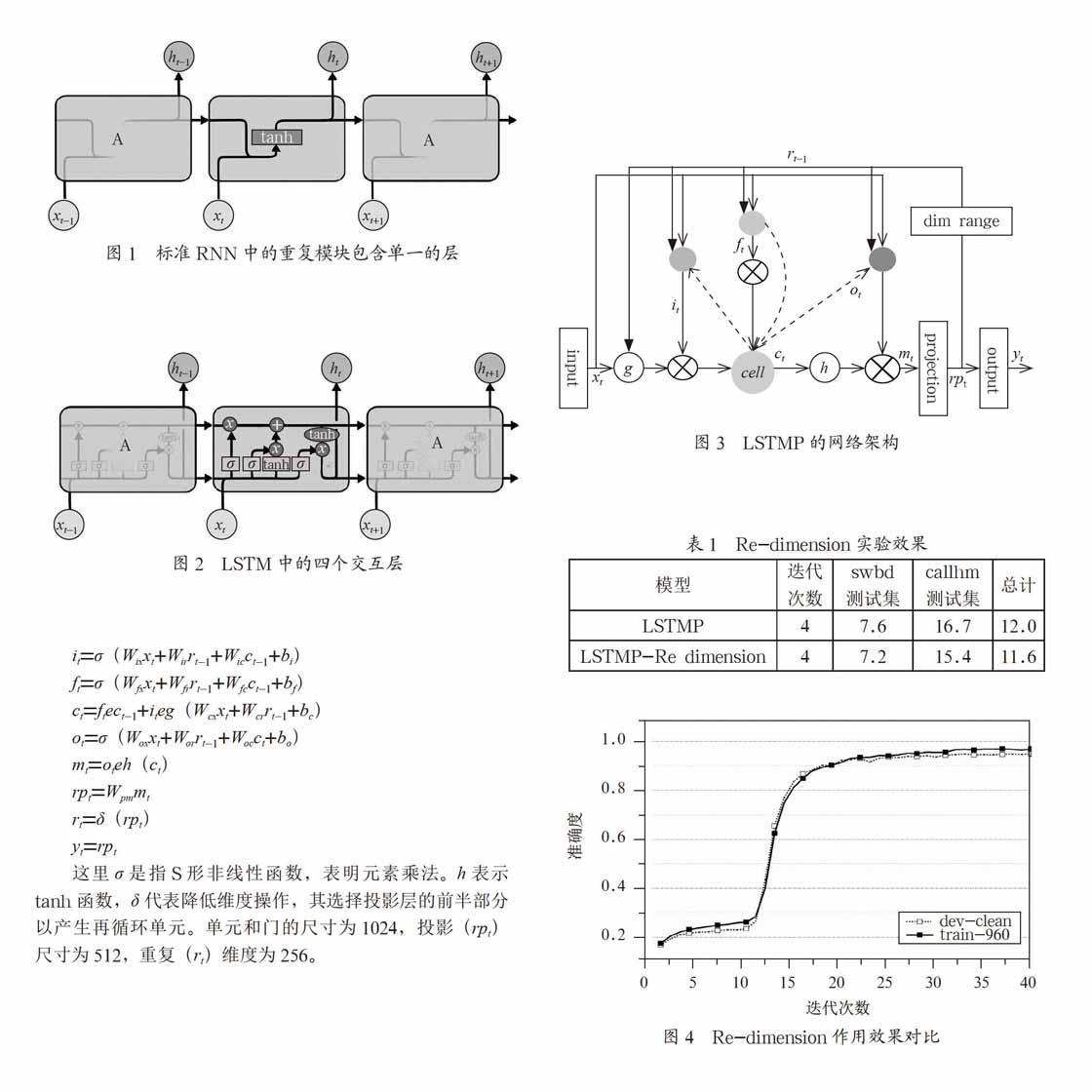
LSTMP结构是在LSTM层之后具有一个单独的线性投影层,并且该投影层产生循环连接。在实施中,使用暗视距节点选择半隐藏单元来分配循环连接。LSTM中的Projection layer是为了减少计算量的,它的作用和全连接layer很像,就是对输出向量做一下压缩,从而能把高纬度的信息降维,减小cell unit的维度,从而减小相关参数矩阵的参数数目[6]。此时的网络结构表述如下。
2.2 改进的LSTMP方法
笔者在改进长短时记忆结构的基础上,又进行了改进。由于LSTMP网络结构在Projection层的输出需要完成两个功能,既需要充当历史信息,又需要作为下一层的输入,对整体架构的实现具有一定的复杂性[7]。因此,本文提出一种Re-dimension的方法,让网络
自己选择一部分参数作为历史信息。这个过程就是dim range部分,如图3所示。
3 实验设计与结果分析
3.1 实验工具
本实验使用Kaldi语音识别工具包进行实验[8]。Kaldi是一个免费、开源的非常强大的语音识别工具库,它提供基于有限状态变换器(Finite-State Transducer,使用OpenFst)的语音识别系统,以及详细的文件和脚本用于构建完整的识别系统。Kaldi包含的重要特性有:集成Finite State Transducer(编译OpenFst工具箱,作为一个库);扩展的线性代数支持;可扩展设计;开源的license;完整的方法和周密的测试。
3.2 实验设计
在本实验中,此网络的输入层大小为39,前后隐藏层各有128个块,输出层大小为40(39个音素加空白)。逻辑sigmoid函数在[0,1]范围内。输入层完全连接到隐藏层,隐藏层完全连接到自身和输出层。权重总数为183,080。
此网络的训练是通过梯度下降和每个训练样本后的权重更新完成的。在所有情况下,学习率为10-4,动量为0.9,权重在[-0.1,0.1]范围内随机初始化,并且在训练期间,将标准差为0.6的高斯噪声添加到输入中以改善泛化。对于前缀搜索解码,使用了0.9999的激活阈值。性能测量为目标标签序列与系统给出的输出标签序列之间的标准化编辑距离(标签错误率LER)。
3.3 结果分析
本实验在LSTMP的基础上增加Re-dimension方法后,让网络自己选择一部分参数作为历史信息。经过反复的训练,从表1中可以看出,网络能更好地学习到历史信息,同时也获得一定程度的性能提升,如图4所示。
4 结 论
本文通过深入研究LSTMP结构,提出一种Re-dimension方法,让网络自己选择一部分参数作为历史信息,采用基于改进的LSTMP方法进行实验,使语音识别率相对提高了4-5%左右。可见该方法可以使网络获得一定的性能提升。
参考文献:
[1] 戴礼荣,张仕良,黄智颖.基于深度学习的语音识别技术现状与展望 [J].数据采集与处理,2017,32(2):221-231.
[2] 陈晓宇.基于数据驱动的涡扇发动机故障预测研究 [D].阜新:辽宁工程技术大学,2018.
[3] 李杰.基于深度学习的语音识别声学模型建模方法研究 [D].北京:中国科学院大学,2016.
[4] 胡鑫,程玉柱,吴祎,等.长短期记忆网络的林火图像分割方法 [J].中国农机化学报,2019,40(1):103-107.
[5] 沈旭東.基于深度学习的时间序列算法综述 [J].信息技术与信息化,2019(1):71-76.
[6] Peddinti V,Wang Y,Povey D,et al. Low Latency Acoustic Modeling Using Temporal Convolution and LSTMs [J].IEEE Signal Processing Letters,2017(99):1.
[7] Chan W,Jaitly N,Le Q,et al. Listen,attend and spell:A neural network for large vocabulary conversational speech recognition [C]// IEEE International Conference on Acoustics,Speech and Signal Processing. IEEE,2016:4960-4964.
[8] R. Prabhavalkar,T. N. Sainath,et al. Minimum Word Error Rate Training for Attention-based Sequence-to-sequence Models [J].IEEE Conference on Acoustics,Speech,and Signal Processing(ICASSP),2018.
作者简介:孙由玉(1995-),女,汉族,山东滨州人,硕士研究生,研究方向:自然语言处理;孙宝山(1978-),男,汉族,天津人,副教授,工学博士,研究方向:自然语言处理;卢阳(1992-),女,汉族,天津人,硕士研究生,研究方向:自然语言处理。
