Transformer-CRF词切分方法在蒙汉机器翻译中的应用
2019-10-21苏依拉仁庆道尔吉牛向华赵亚平
苏依拉,张 振,仁庆道尔吉,牛向华,高 芬,赵亚平
(内蒙古工业大学 信息工程学院, 内蒙古 呼和浩特 010080)
0 引言
由于人工翻译成本较高,随着科学和信息技术的发展进步,机器翻译已经逐渐取代人工翻译。1954年1月7日,在IBM纽约总部,Georgetown-IBM实验启动,IBM的701型计算机将60个俄语句子自动翻译成英语,这是历史上首次实现的机器翻译。经过六十多年的发展,机器翻译技术日趋成熟。目前,基于深度学习的神经机器翻译和统计机器翻译成为机器翻译的主要研究方向和主流技术。
Cho K等[1]提出基于深度学习的神经网络端到端框架,它还有另一个名称,即编码器—解码器框架,编码器和解码器分别是两个神经网络结构,编码器实现源语言的统一编码,解码器把编码器输出的隐层状态解码成对应的目标语言,实现双语的近似同义转换。Cho K的实验使用循环神经网络(recurrent neural network,RNN),RNN神经网络不能对信息进行长期记忆,会造成一定程度的梯度消失和提取的特征信息片面性或丢失问题。Sundermeyer M等[2]提出了一种长短期记忆神经网络模型(long short terms memory,LSTM)。但是,这种编码器—解码器框架有一个致命的缺陷,即无论源语言句子有多长,编码器始终都生成一个固定维度的隐藏层向量,这对较长的句子来说,很难捕获长距离的依赖关系,而且LSTM神经网络的序列递归特性难以并行化计算。

蒙古语属于黏着语,汉语则是一种独立语。目前汉语分词方法对机器翻译质量的提高发挥着积极作用,而对于蒙古文的词切分处理方法的研究还相当匮乏,蒙古文词切分算法的不足导致蒙汉机器翻译中一个蒙古文句子对应多个汉语词语的一对多的映射关系,影响了蒙汉机器翻译的发展。因此,蒙古文词切分算法和语料预处理对于蒙汉机器翻译的优化越来越重要。
利用LSTM神经机器模型能够对重要向量信息进行记忆,防止由于梯度消失造成信息丢失,有利于缓解蒙汉双语语序差异较大的问题。但是由于LSTM是在RNN的架构上引入记忆单元进行改进,而RNN固有的单层的序列结构形式导致其难以并行化计算的缺点,乌尼尔[9]提出了基于CNN词根形态选择模型的改进蒙汉机器翻译研究,然而卷积神经网络不擅长处理序列较长的文本,难以充分利用上下文相关信息进行翻译。所以LSTM和CNN的神经网络对上下文关系的建模依然存在局限性,并且传统的蒙汉机器翻译由于输入词汇特征单一,依然存在词汇受限、译文忠实度低等问题。
本文根据Tensor2Tensor神经网络的结构[10],对蒙汉神经机器翻译模型进行建模,利用Transformer模型的self-Attention、Multi-head Attention等技术对指代信息丰富的上下文进行建模。首先,我们利用了词性标注的分词工具THULAC[11]配合一种字节对编码(byte-pair Encoding,BPE)算法来获得子词单元,然后本文对基于Transformer-CRF的蒙古语词切分算法进行研究,通过对蒙古文词切分算法的研究来帮助翻译模型得到较好的输入数据。其次,我们构建了基于Tensor2Tensor神经网络的蒙汉翻译编码器—解码器架构。最后,通过对模型进行参数的初始化和参数训练,得到用于实验的训练模型,对实验模型进行相应的测试和对比,分析了本文基于Tensor2Tensor神经机器翻译模型的翻译质量和特性。
1 基于Transformer-CRF的蒙古语词切分算法研究
本文采用的语料来自内蒙古工业大学蒙汉翻译课题组的项目《基于深度学习的蒙汉统计机器翻译的研究与实现》构建的120万句对蒙汉平行语料库和内蒙古大学开发的67 288句对蒙汉平行双语语料,用UTF-8编码格式作为蒙汉双语语料的编码格式。采用了分布式表示(distributional representation)的词向量方法。
1.1 CRF词切分算法
条件随机场(CRF)是一种基于概率计算的框架,它主要用在文本标记和对结构化数据(例如,序列、树和格子)进行切分时,经过条件概率计算得到一种概率分布。 CRF的基本思想是在给定特定观察(输入)序列x=x1,x2,…,xm的情况下定义标签序列y=y1,y2,…,yn上的条件概率分布,而不是在标签和观察序列上的联合分布。
例如,给定句子中的未标注字的序列为x=x1,x2,…,xm,对应的已标注字序列为y=y1,y2,…,yn,则状态序列线性链CRF的条件概率计算方式如式(1)所示。
(1)
其中,wj表示特征函数对应的权重,ξj则表示特征函数,i为当前时刻待标注字位置,T(x,w)表示归一因子。T(x,w)的计算式如式(2)所示。
(2)
CRF优于隐马尔可夫模型的主要是它的条件性质,放松了隐马尔可夫模型(Hidden Markov Models, HMM)所需的独立性假设,以确保易处理的推理。另外,CRF避免了标签偏差问题,这是基于有向图形模型的最大熵马尔可夫模型(MEMM)和其他条件马尔可夫模型所表现出的弱点。 CRF在许多领域的许多实际任务中都优于MEMM和HMM,包括生物信息学、计算语言学和语音识别。
虽然CRF词切分方式借助语言特征可以识别出词典内部词汇和一部分集外词,但是在处理边界词歧义以及长字词问题时同样会因为无法进行深层语义挖掘和缺乏拟合能力而导致标注偏差等问题,有研究者提出基于BiLSTM-CRF[12]的词切分算法,但LSTM固有的梯度消失问题和难以并行化计算的缺陷仍无法克服,因此本文提出了一种基于Transformer-CRF的蒙古文词切分算法。
1.2 基于Transformer-CRF的词切分算法
基于Tensor2Tensor模型通过建模海量数据中的实体概念等先验语义知识,学习真实世界的语义关系[13]。具体来说,Tensor2Tensor模型通过对词、实体等语义单元的掩码,使得模型能够学习完整概念的语义表示。例如,给模型输入一个句子“呼和浩特是内蒙古自治区的省会城市”,ERNIE(1)https://github.com/Paddle Paddle/ERNIE通过学习词与实体的表达,使模型能够建模出『呼和浩特』与『内蒙古自治区』的关系,学到『呼和浩特』是『内蒙古自治区』的省会以及『内蒙古自治区』是个省份名词。
基于Tensor2Tensor架构的Transformer模型是一种完全基于注意力机制的可以高度并行化的网络,由于每个词语在句子中都有上下文依赖关系,所以我们需要神经网络隐藏层捕捉层次化的信息,这就需要建立一个很深层的神经网络,而不是一个单层的序列的LSTM的网络。并且我们需要能够对指代信息丰富的上下文进行建模,这需要Self-Attention、Multi-head Attention这样的技术。本文借鉴CRF思想,使用Tensor2Tensor结构结合CRF层进行序列的词切分标注。基于Transformer-CRF的词切分算法结构图如1所示。

图1 基于Transformer-CRF的词切分算法结构
图1中,输入层的基本单元是汉语语料中的字对应的向量形式,Transformer的神经网络架构基于Tensor2Tensor,多头自注意力机制能够对每个词语的指代信息进行丰富的上下文关系建模[14],而且能够对非线性特征进行拟合,从而克服CRF词切分算法难以进行上下文提取的缺点,又克服了BiLSTM-CRF词切分算法容易梯度消失和难以并行化计算的缺点。接着通过一个RELU层进行输出,并将字向量的信息传递给CRF层来进行序列标注。
1.3 Transformer-CRF词切分模型构建
蒙古语属于黏着语,其构词规则如图2所示,一个蒙古语词由一个词根与多个词缀组成[15]。

图2 蒙古文词汇构成
语料词切分时需要对语料中的每一个字或字符进行单点标注,设定单点标注集为四元组,包括“P(prefix): 词根(头);W(Word suffix): 构词后缀;C(Configuration suffix): 构型后缀;E(End suffix): 结尾后缀”四种类型。本文利用Tensor2Tensor神经网络结合上下文特征,同时根据CRF来考虑句子前后的标签,进行序列的词切分标注。我们将蒙古文单词的词根(词首)称为左边界L,最后一个字符(结尾后缀)称为右边界R.如果我们将L和R视为随机事件,那么就可以从它们中导出4个事件(或标记):


以Transformer-CRF算法处理句子时,通过分析其序列中词语的依存关系来进行词语的切分。句子中的词语之间的主要依赖关系是: “呼和浩特”和“内蒙古自治区”相关联,“呼和浩特”和“省会城市”相关联,“呼和浩特”和“城市”相关联,所以“呼和浩特”在这句话中的依赖关系是多元、交叉的,多头自注意力机制可以帮助每个词语和其他词语建立多元的上下文依赖关系。这一发现表明Transformer模型对语料的上下文语义信息的提取和关联分析具有重要意义,具体切分流程如图3所示。

图3 蒙古文词语切分过程
1.4 数据实验及结果分析
本文利用GitHub中的TensorFlow等开源工具实现了基于Transformer-CRF模型的实验,采用Word2Vec工具进行字符向量的训练,字符向量的维度分别设定为250维和500维,标注集的类型采用四元组形式,即{P,W,C,E},数据的训练集中字符数量为1 183 112。本文的词切分模型将与传统的HMM词切分系统[16]、CRF模型和LSTM-CRF模型进行实验对比,利用词切分准确率P和F值作为评估指标,同时在模型训练过程中,Dropout分别设定为0.3和0.6,并在不同参数下观察实验结果,具体如表1所示。
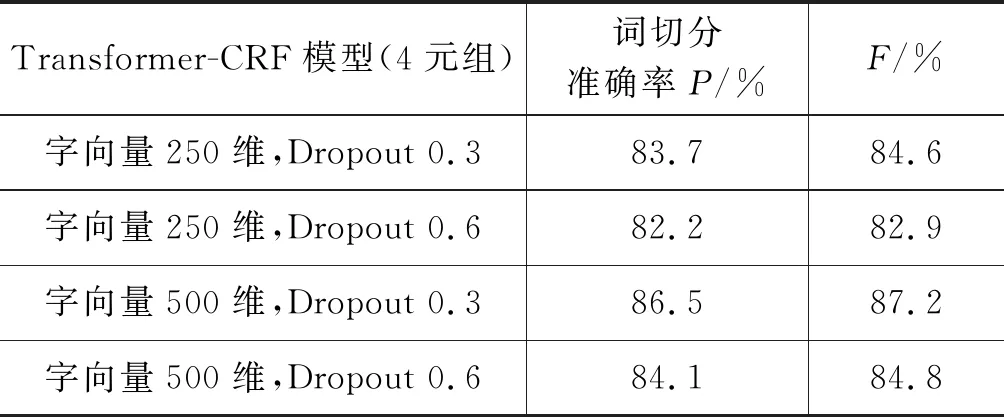
表1 不同参数的分割效果
通过表1可以看出,在字向量的维度设定为500维,且神经网络训练Dropout设定维0.3时,词切分准确率达到了86.5%,F值也达到了87.2%,所以模型拥有很好的词切分质量。
模型的实验对比将和传统的HMM词切分模型和CRF词切分模型进行比较,参数设定为500维向量和0.3的Dropout。通过实验的结果来分析模型的质量,结果如表2所示。

表2 实验结果比较
根据对比实验可以看出,标注集为四元组的Transformer-CRF模型较HMM算法、CRF算法和LSTM-CRF算法的词切分模型,准确率和F值均有一定的提升。充分说明利用Transformer神经网络进行语料语义提取的重要性,对句子的上下文的获取以及高质量的词语切分提供了基础。
2 基于Tensor2Tensor蒙汉机器翻译的词素编码的研究
2.1 基于蒙文词切分预处理的Tensor2Tensor编码器模型构建
2.1.1 蒙古语词素四元组切分

词素切分以蒙古文词根、词缀词典库为基础。在进行切分时,首先利用词频统计工具OpenNMT.dict生成蒙古语语料的词典,并结合本项目组构建的15万词典库以及蒙汉专有名词词典库包含11 160组地名库、15 001组人名库、2 150组农业名词库、308 714组医学名词、5 000组物理名词。词典生成后,搜索词典内词干来进行汇总,生成词干表。词干表以外的部分是相应的词缀表部分。本文以词干表和词缀表为基础,利用堆栈算法和逆向最大匹配算法对蒙古语的每个词语进行词素切分,其切分流程如图4所示。

图4 词素四元组切分流程图
2.1.2 基于Tensor2Tensor的词素编码器构建过程

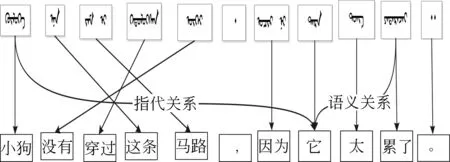
图5 指示代词指代关系示例图(a)

图6 指示代词指代关系示例图(b)
图5、图6展示了self-attention通过结合上下文相关信息,强化对齐关系,有助于机器学习(神经网络)学习到更加复杂的语义关系。在我们的编码器网络架构中,我们利用蒙古语的词素信息进行编码,如图7所示。

图7 蒙古语词素输入过程
在我们的基于Tensor2Tensor的蒙汉神经机器翻译系统中,编码器包含Self-Attention层。 在Self-Attention层中,所有键(key)、值(value)和查询(query)都来自相同的位置,在这种情况下,是编码器中前一层的输出。 编码器中的每个位置都可以处理编码器前一层中的所有位置。

2.2 注意力机制(Attention)


图8 蒙汉平行语料的对齐机制

图9 蒙汉平行语料词与词之间的关联关系

我们在Transformer中提出一种扩展性更高、并行度更高的Attention计算方式,它把Attention看作一个基于内容的查询的过程,它会设置3个向量: Query Vector、Key Vector、Value Vector。并且每一个Vector都是通过它的input embedding和权重的矩阵相乘得到的。我们利用这个Q、K、V向量进行各种数值的计算,最终得到Attention得分。这个计算过程是相对复杂的。
“Multi-head Attention”的方式,就是“多头”Attention,我们设置多个Q、K、V矩阵和它实际值的矩阵。我们这样设计有两种好处,第一,它的可训练参数更多,能提升模型能力,去考虑到不同位置的Attention;另一个好处是对这个Attention赋予了多个子空间。从机器学习的角度来说,首先参数变多了,拟合数据的能力变强了。从语言学是这样的,不同的子空间可以表示不一样的关联关系,比如一个子空间表示指代的Attention,另一个子空间表示依存的Attention,第三个子空间表示其他句法信息的Attention,它能够综合表示各种各样的位置之间的关联关系,这样极大地提升了Attention的表现能力,这是传统的RNN、LSTM系统中所不具备的,也是最终实验时会对性能有巨大影响的一项工作。
2.3 Tensor2Tensor解码器模型构建
模型的结构为编码器—解码器神经网络结构,编码器为了更好地获取蒙古语的语义信息,采用完全依赖于注意力机制来绘制输入和输出之间的全局依赖关系。其具体结构如图10所示。
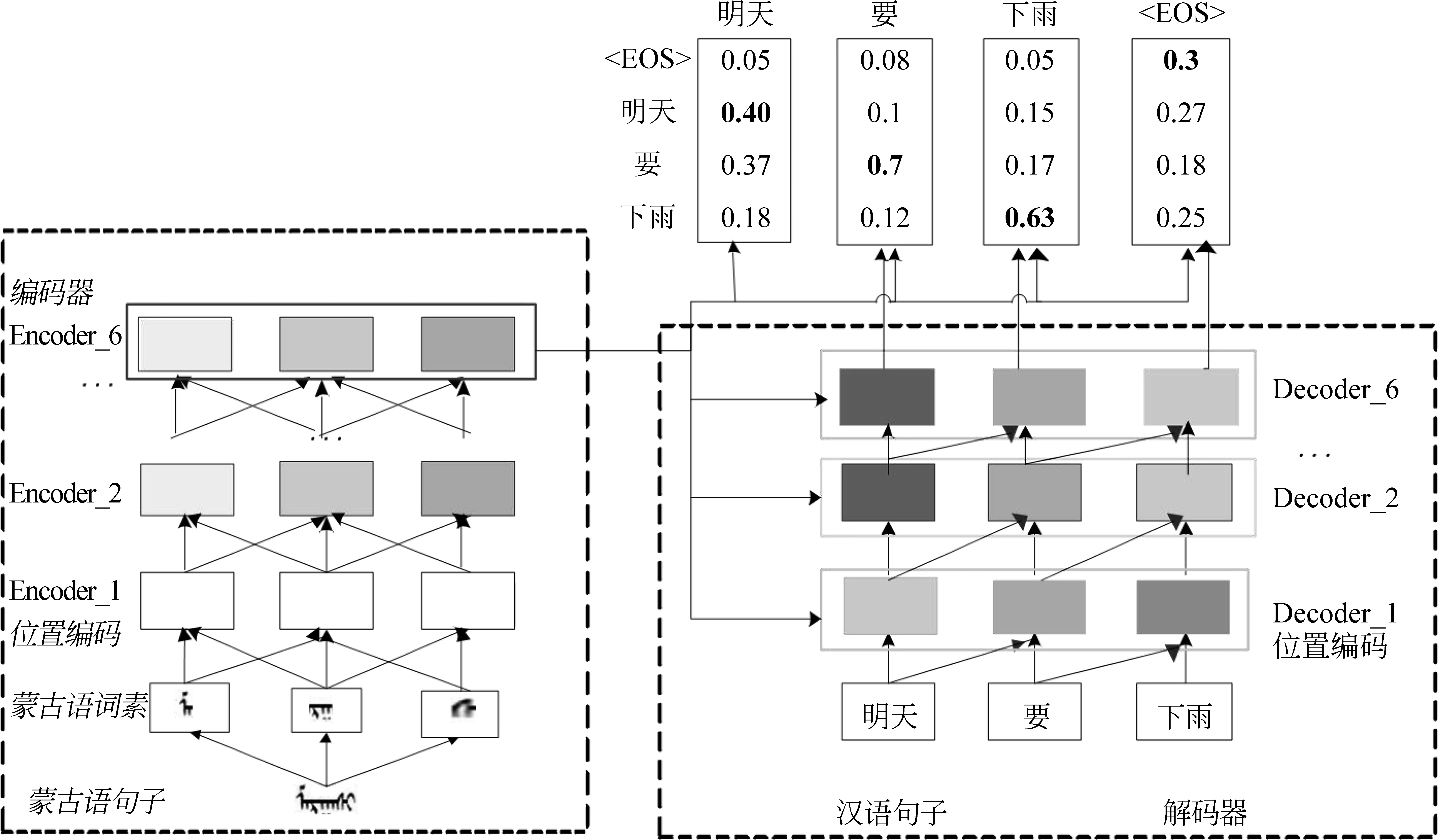
图10 解码器模型结构
与编码器类似,解码器中的自注意力层允许解码器中的每个位置参与解码器中的所有位置直到并包括该位置。 我们需要防止解码器中的向左信息流以保持自回归属性。我们实现保持自回归属性的目标在缩放点乘积注意的内部。我们实现点乘积注意力,通过屏蔽(设置为-∞)softmax[]输入中与非法连接相对应的所有值。当出现未登录词时,解码器自动到专有名词词典库进行多头查找,当匹配到相应的蒙古文专有名词时,进行基于词典的翻译,这个计算过程虽然会增加解码消耗的时间,但是我们的Transformer网络具有高度并行化计算的特点,而且这样处理后,翻译质量和译文忠实度有了较明显的改善,一般可以提高两个BLEU值[13]。
3 数据实验及结果分析
3.1 数据集划分及训练参数设定
模型训练的数据集使用内蒙古工业大学蒙汉翻译课题组的项目《基于深度学习的蒙汉统计机器翻译的研究与实现》构建的120万句对蒙汉平行语料库和内蒙古大学开发的67 288句对蒙汉平行双语语料,另外使用了由一些专有名词组成的词典库,用来校正我们的蒙汉翻译系统,蒙汉平行词典库包含11 160组地名库、15 001组人名库、2 150组农业名词库、308 714组医学名词、5 000组物理名词。实验数据采用留出法进行语料的划分。留出法主要将数据集语料分为三个部分: 训练集、验证集和测试集。模型的数据集划分如表3所示。

表3 实验数据集划分
采用了分布式表示(distributional representation)[14]的词向量方法。我们用UTF-8编码格式作为蒙汉双语语料的编码格式。
3.2 硬件和时间表
我们在一台配备1个NVIDIA GTX 1070Ti GPU的机器上训练模型。 对于使用本文所述的超参数的基本模型,每个训练步骤大约需要28秒。 我们对基础模型进行了总共200 000步大约12小时的训练。
3.3 优化器
我们使用Adam优化器,β1=0.9,β1=0.98和ε=10-9。根据式(3),我们在训练过程中改变了学习率:
(3)
这对应于为第一个warmup_steps训练步骤线性地增加学习速率,然后与步数的反平方根成比例地减小它。 我们用了warmup_steps=4 000。
3.4 正则化
我们将dropout应用于每个子层的输出,然后将其添加到子层输入并进行归一化[15]。 此外,我们将dropout应用于编码器和解码器堆栈中的嵌入和位置编码的总和。对于基本模型,我们使用的速率为Pdrop=0.1。
3.5 实验结果对比和总结
我们首先采用传统的句子级蒙古文和汉语分词预处理后的平行的蒙汉双语语料作为翻译系统的输入信号,接下来,搭建基于长短期记忆神经网络LSTM的蒙汉翻译模型,并记录相关的实验结果作为后期对比实验的基准模型,然后用同样的输入进行Transformer蒙汉翻译模型的实验并记录实验结果,最后我们使用模型做了n组对比实验。实验结果表明,与不进行蒙语词素切分的Transformer翻译模型和LSTM蒙汉机器翻译基准系统相比,该方法基于汉语词语级别评测的BLEU值得到一定的提升。为了更好地缓解低资源语言语料数据稀缺和语料内容覆盖面有限的问题,我们在生成未登录词时对语料库进行基于词典的词语近似替换,来更好地缓解蒙汉翻译中的数据稀疏和没有充分理解原文语义关系的问题。
实验的对比利用Google的seq2seq框架下的LSTM神经机器翻译系统作为基准实验,同时与Google的基于Tensor2Tensor的神经机器翻译模型Transformer和不加词干词缀、词性标注信息以及名词泛化的Tensor2Tensor机器翻译模型进行对比。
本实验的模型在训练生成的10个检查点模型中进行质量评测并记录数据,根据模型的数据进行研究,表4、表5为在相同测试集及参考译文的条件下,最后5个检查点模型对应的BLEU值指标。

表4 译文质量Accuracy评分
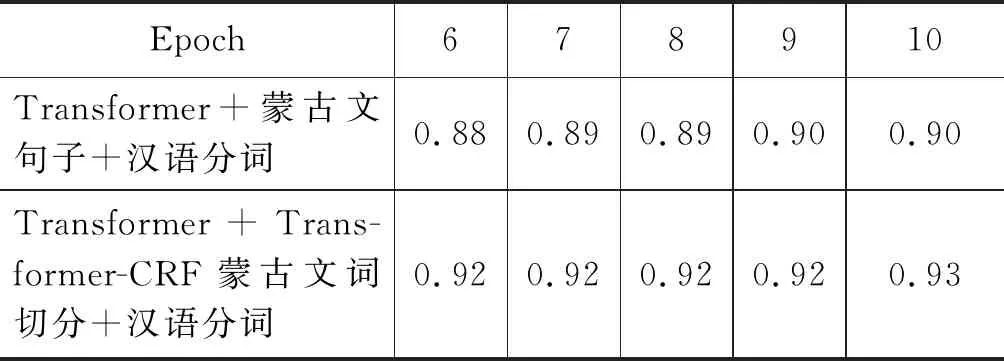
续表

表5 测试集BLEU值评估表
通过表4和表5可以看出,Transformer翻译架构明显比LSTM神经网络的翻译质量好。另外,经过实验对比,发现应用了Transformer-CRF的词切分算法对蒙古文进行词素切分后作为源语言输入比句子级蒙古文输入的翻译效果好,避免了一个源语言句子向量对应多个目标语言多个词语向量的输入和输出向量数量不对称的矛盾,这种方法为资源稀缺的语种之间的翻译提供了一定的参考价值。Transformer-CRF蒙古文词切分方法应用在基于Tensor2Tensor架构的蒙汉机器翻译中,它的翻译率0.93Accuracy和BLEU值49.47评估比对比实验中的其他词切分方法效果好,比使用句子级蒙古文句子作为源语言的Tensor2Tensor翻译模型BLEU值高出2.99个词语级别的BLEU值。
4 结论和未来展望
本文利用基于Tensor2Tensor架构的Transformer模型构建了翻译模型的编码器—解码器结构,该架构是一种完全基于注意力机制的可以高度并行化的网络,它能够捕捉层次化的信息,这就需要建立一个深层的神经网络,而不是一个单层的序列的LSTM的网络,使其能够对指代信息丰富的上下文进行建模。另外,本文以有向图判别式结合Transformer神经网络的算法对源语言语料进行词干和附加词缀的切分,同时将切分完成的蒙古语词干词缀进行词性标注,词切分和标注过程采用Transformer-CRF算法。
实验结果表明,以词根、构词词缀、构型后缀和结尾后缀四元组作为最小单元进行的词素切分作为编码输入的Tensor2Tensor蒙汉机器翻译模型的翻译质量,比LSTM基准系统和不经过Transformer-CRF词素和汉语分词切分的单一粒度的Tensor2Tensor模型的BLEU值有了一定的提高。
基于深度学习的神经机器翻译方法主要利用逐层传递的复杂的函数来建立双语语料之间的映射关系。神经网络通过复杂的函数嵌套关系学习权重矩阵,然后建立翻译模型,从而实现机器的智能翻译。这种模型的训练建立在大规模语料的基础上,单纯利用很小规模的语料很难训练出好的翻译模型。然而,随着机器学习理论和技术的发展和成熟,目前在较难获取大规模语料资源的语言上可以使用迁移学习、无监督学习、多任务学习结合弱监督学习等一些方法来缓解这种资源稀缺的问题。
