基于半监督假设的半监督稀疏度量学习
2019-10-18王倩影
王倩影 李 炜
(河北经贸大学数学与统计学学院 河北 石家庄 050051)
0 引 言
度量学习[1]的本质是学习一个映射空间,使得同类样本间的距离更近,异类样本间的距离更远。近年来,度量学习在众多领域得到了广泛应用,如人脸识别[2-4]、图像检索[5-7]等。根据不同的训练样本,度量学习可以分为无监督度量学习、有监督度量学习和半监督度量学习。无监督度量学习的训练样本为无标记数据,有监督度量学习的训练样本给定了正负限制的样本对,但没有将无标记样本利用起来。因此人们尝试将大量无标记样本数据加入到有标记样本中一起训练来进行学习,由此产生了半监督度量学习[8]。
由于现实应用中存在大量无标记样本,半监督度量学习是当前的一个研究热点。Joachims等[9]依据半监督支持向量机(S3VM)提出了基于标记切换的组合优化算法,使S3VM在数据集上取得了不错的效果。Chapelle等[10-11]提出了半监督学习有关高维数据的三个假设:光滑假设、聚类假设和流形假设,并据此提出了低密度分割算法,得到了很好的分类效果。现今对半监督度量学习方法的研究只利用了三个半监督假设中的一项或两项,没有一个方法满足所有的三个半监督假设。而且在大数据时代,数据呈现出维度高的特点,常见的度量学习方法基于原始特征产生度量,使得度量矩阵很复杂。利用高维数据的潜在稀疏性建立稀疏正则化模型,可以有效地处理高维数据。文献[12]据此提出了基于L1正则化的模型lasso。但目前存在的稀疏正则化模型没有结合半监督度量学习中的三个半监督假设,把无标记样本充分利用起来。
为了充分利用无标记样本,本文从间隔损失函数入手,依据三个半监督假设,建立了半监督假设正则项,并结合稀疏正则项,提出了基于半监督假设的半监督稀疏度量学习算法。最后通过实验验证了本文所提算法的有效性。
1 间隔损失函数
1.1 问题描述
在学习一个度量时,样本对的限制是指两个给定的样本是否在同一类,若在一类则称为一个正约束,若不在一类则称为一个负约束。所要学习的度量是要使得属于同一类的两个样本距离更近,属于不同类的两个样本距离更远。三样本为一组的约束是对样本对约束的拓展。在三样本组约束(xi,xj,xk)中,(xi,xj)之间的距离要求比(xi,xk)之间的距离小。因此,若(xi,xj)是一个正约束,(xi,xk)是一个负约束,则(xi,xj,xk)就是一个三样本组约束。但反之不成立,即并不能由(xi,xj)之间的距离比(xi,xk)之间的距离小,得到(xi,xj)属于同一类,(xi,xk)属于不同类的结果。当给定一些三样本组约束时,我们将要学习一个满足如下条件的度量:如图1所示,对每一个三样本组约束学习的度量要使得(xi,xj)之间的距离小于(xi,xk)之间的距离。
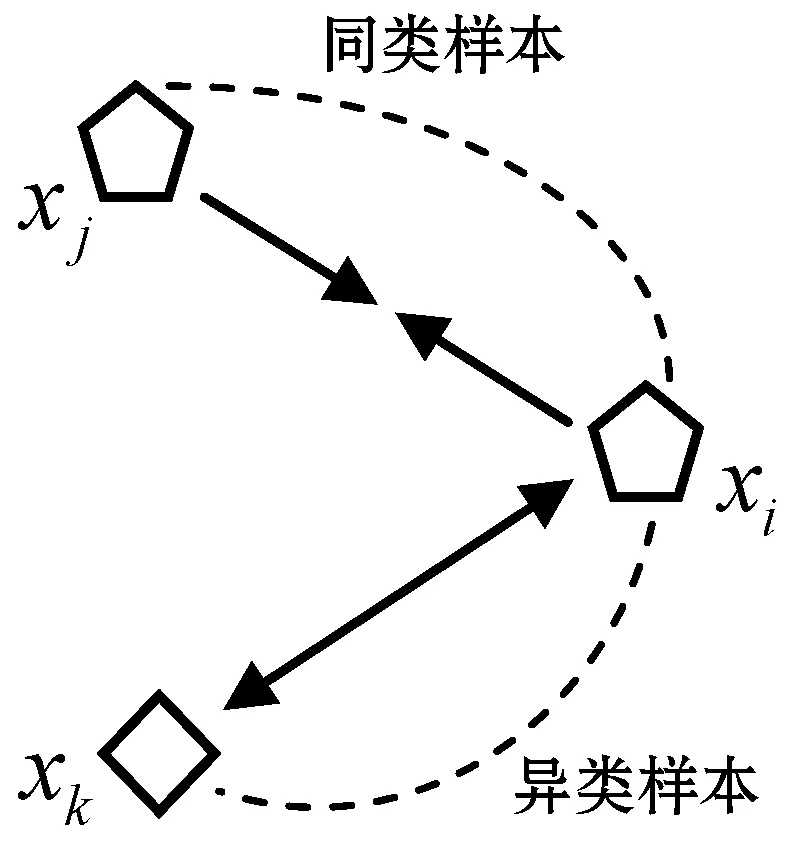
图1 三样本组约束示意图
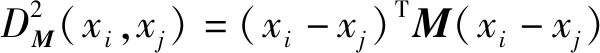
类标信息可以转化成三样本组约束。每个三样本组约束由三个样本(xi,xj,xk)组成,其中,xi是所要讨论的样本。希望学习得到这样的距离DM(xi,xj)和DM(xi,xk)满足:
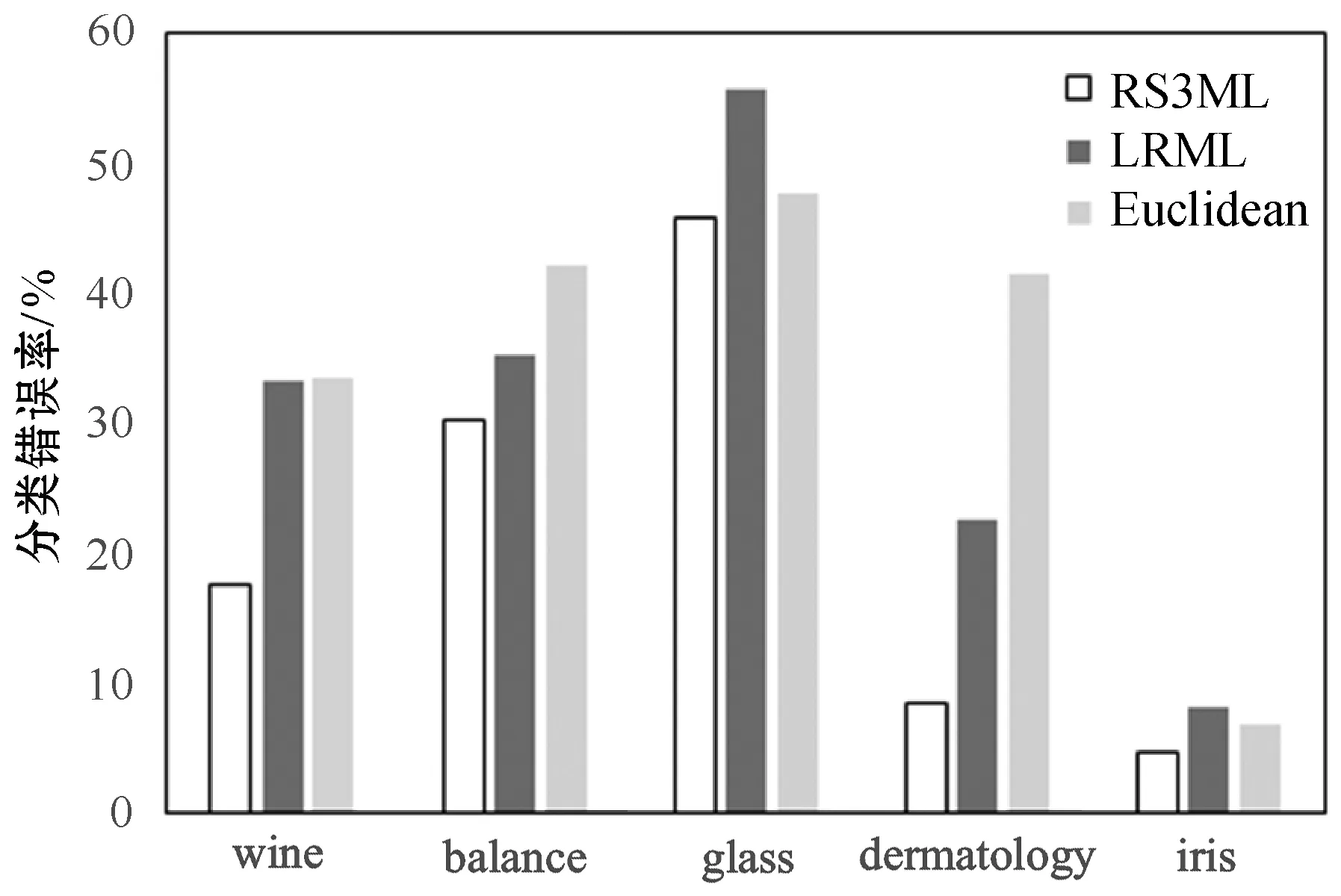
φ={(xi,xj,xk)|DM(xi,xj) (1) 本文参考LMNN的损失函数,对有标记样本的损失函数定义如下: (2) 文献[13-14]证明了该损失函数的有效性,但此函数在运用过程中对噪声数据较为敏感,容易出现过拟合现象,并且没有将无标记样本利用起来。为了解决这些问题,引入半监督假设正则项将无标记样本充分利用起来,过拟合通常发生在特征(参数)较多的时候,引入L1正则项,L1正则化会产生稀疏解,部分分量会变成0,相当于对原始特征做了特征提取。 数据分布可以由样本及其近邻所反映,因此我们可以通过样本间的相似度以及区域密度来描述样本及其近邻间的关系。若给定样本集X=[x1,x2,…,xn],以及与其相对应的相似矩阵S=[Sij],本文根据三个半监督假设来建立正则项。提出的正则项为: (3) 式中: (4) N(i)是xi由欧氏距离确定的邻域点的集合,在正则项中引入的Sij是xi和xj之间的相似度。根据聚类假设,引入密度指标βi∈R+,它是一个有关样本xi密度的函数。 结合间隔损失函数和提出的正则项,我们得到一个新的度量学习方法: (5) 式中:λ1用是来调整正则项的权重参数。 通常度量学习任务中的特征数量较多,在预测或分类时,难以对特征进行选择,但是如果代入这些特征得到的模型是一个稀疏模型,即只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,此时我们可以只关注这些对模型有贡献的特征。L1正则化有助于生成这样一个稀疏权值矩阵,进而用于特征提取。 目标函数变为: (6) 式中:λ2用是来调整正则项的权重参数。 学习一个度量,我们可以看成是学习一个映射,把特征空间中的样本映射到另外一个新的空间中,新空间中的欧式距离即为所求的度量。具体地,学习一个马氏矩阵M等价于学习一个线性映射LT:Rm→Rr,其中L=[l1,l2,…,lr]∈Rm×r。因此,我们可以这样计算两个样本间的距离: (xi-xj)TM(xi-xj)= (7) 式中:M=LLT是所要学习的度量。 为了简化目标函数,我们引入一个新的记号。对于要研究的样本xi,引入权重矩阵W(i),这是一个对角阵: 重新整理正则项: (8) 根据式(8)得: tr(XUXTLLT)=tr(XUXTM) (9) 目标函数最后变为下式: (10) 本文所提出的半监督稀疏度量学习方法有如下优点: (2) 聚类假设表明分界线(面)应该从低密度区域穿过,也就是说分布在高密度区域的样本点之间的距离应较小。式(6)正则项中的βi可以保证分布在高密度区域样本点之间的距离被最小化,如果这些样本之间存在较大的距离将会受到较大的惩罚。 (3) 根据流形假设,样本间的距离要沿着流形来测量。在受到半监督学习中基于样本图的启发后,我们在正则项中引入了相似度Sij,这个相似性是根据高斯核来计算的,它可以引导新的度量。 (4) 引入稀疏正则项,本文引入的的L1正则项使得度量矩阵具有稀疏性,有助于了解不同原始特征的重要程度,满足应用对可理解性的需求。 梯度下降法是一种常用的一阶优化方法,是求解优化问题最经典的方法之一。 Ft=λ2tr(M(t))+λ1tr(XUXTM(t))+ (11) 式中:|{φ(t)}|指集合{φ(t)}中元素的个数,M(t+1)则可以通过M(t)向Ft的梯度相反方向移动一个步长得到,即: M(t+1)=M(t)-γ▽Ft 重复此过程,直到满足了所有三样本组约束,或者达到预给定好的循环次数。算法描述如算法1所示。 算法1梯度下降算法 输入:有标记样本Xl 无标记本Xu 示性矩阵Y 输出:度量M 1.初始化三样本组约束的个数k,半正定矩阵M,最大循环次数T; 2. fort=1:Tdo 3. 根据M(t)、Y和Xl确定不满足约束的三样本组集合φ(t) 4. ifφ(t)为空集 then 5. break 6. else 7. 计算当前目标函数Ft的梯度 8. 更新M,M(t+1)=M(t)-γ▽Ft 9. 将M(t+1)投影到半正定矩阵子空间中得到半正定度量 10. end for 在本节中,将把本文提出的基于半监督假设的半监督稀疏度量学习算法(RS3ML)与S3ML、半监督判别分析(SDA)、LRML、基于核方法的半监督度量学习算法Kernel-A和Kernel-β进行分析比较,通过比较结果来测试本文所提方法的有效性。实验中,以欧氏距离作为比较的基准。 我们把类标信息分别转化为样本对约束和三样本组约束。本文所提出的算法的参数依据文献[15]进行设置。 从University of California Irvine(UCI) machine learning repository中选出五个数据集对各种算法进行1-NN的分类实验。五个数据集分别为Wine、Iris、Dermatology、Glass Identification(Glass)、Balance Scale(Balance)。其中:Wine数据集中记录的是意大利同一地区三种不同的葡萄酒品种的相关信息,Balance中记录的是天平的重量和距离,Dermatology数据集用于判定鳞状疾病的类型,Glass数据集记录的是不同类型的玻璃的氧化物含量的数据,Iris中包含的是不同种类鸢尾花的一些信息。各个数据集的基本信息如表1所示。 实验中,所有的数据都被随机分为有标记数据集Xl和无标记数据集Xu,并且每类只给了五个有标记样本,这些有标记样本用来训练度量和K近邻分类器。每个实验将会在同一数据集上重复30次,每次试验都随机地选取训练样本,实验结果给出了这30次实验结果的均值。 图2、图3和图4结合1-NN分类器给出了不同度量算法的识别结果。纵坐标均为重复30次实验所取得的平均分类错误率。可以看出,两个核方法Kernel-A和Kernel-β在数据集上的表现不太稳定。本文提出的RS3ML算法与S3ML、SDA等其他算法比较,在五个数据集上的分类错误率均为最低。实验结果表明,相比其他度量算法,RS3ML算法效果明显,学习性能更优。 图3 算法组2的错误率比较 图4 算法组3的错误率比较 本文基于三个半监督假设提出了一个半监督稀疏度量学习算法。与其他方法不同的是,本文所提出的方法结合了所有三个半监督假设,充分利用了大量的未标记样本,并利用L1范数使得度量矩阵具有稀疏性,从而减少计算机存储负担,提高学得模型的可解释性。最后在公开数据上的实验验证了本文提出的方法的有效性。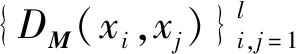
1.2 损失函数
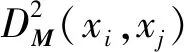
2 正则化的半监督度量学习
2.1 半监督假设正则项
2.2 稀疏正则项

2.3 问题优化
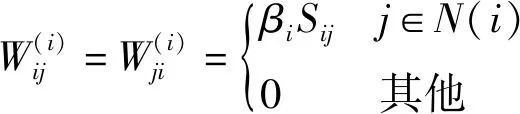


3 模型求解
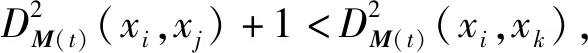
4 实 验
4.1 实验设置
4.2 实验结果

5 结 语
