基于近红外光谱对淀粉种类的定性鉴别及定量分析
2019-10-16李梦瑶翟晨王书雅谢云峰刘云国
李梦瑶,翟晨,王书雅,谢云峰,刘云国
(1.中粮营养健康研究院,营养健康与食品安全北京市重点实验室,北京 102209;2.新疆大学 生命科学与技术学院,乌鲁木齐 830002;3.国贸食品科技(北京)有限公司,北京 102209)
淀粉(starch)是农副产品的主要组成部分,被广泛应用于食品加工业和化学工业中。近几年,淀粉的生产和加工贸易取得了较大的发展[1-3]。目前,在牛肉酱、甜面酱等调味品加工方面,淀粉具有增加稳定性、改善口感和感官性状的功能;在食物烹调中,淀粉作为调味品具有勾芡等作用[4-7]。不同种类的淀粉,其结构及理化性质不同,功能和使用效果差别较大。由于原料及制备工艺不同,淀粉成本具有一定的差异,部分生产者通过添加低成本淀粉来赚取更高的利润。因此亟需研究一种简单、快速、无损的淀粉种类鉴别及定量分析技术。
目前,淀粉种类鉴别多采用传统感官评定方法和常规理化分析方法,这些方法受主观因素影响较大,准确度难以保证,并且费时费力,破坏样品,无法满足淀粉种类的快速准确定性及定量分析需求[8-10]。随着光谱技术和化学计量学的发展,近红外光谱(near infrared spectroscopy,NIRS)技术,作为一种快速、无损、绿色的检测技术,在农业、食品质量等方面得到了越来越多的重视和应用[11-14]。近年来,近红外光谱技术多用于食品中淀粉含量的分析,对于淀粉品种的鉴别及混合淀粉中成分的定量分析研究较少[15-17]。
本研究通过对市售的73份4个不同种类(马铃薯、玉米、小麦、绿豆)的淀粉样品进行光谱采集,通过主成分分析(principal components analysis,PCA),对不同种类淀粉建立了定性分析模型。对不同比例的马铃薯-小麦淀粉混合物进行光谱采集,优化光谱预处理方法,基于偏最小二乘法(partial least squares, PLS)建立小麦淀粉添加比例的预测模型。通过分析,该研究提出的快速、准确、无损定性定量预测方法可用于淀粉的种类鉴别及成分分析。
1 材料与方法
1.1 材料及仪器
市售马铃薯淀粉、玉米淀粉、小麦淀粉和绿豆淀粉等样品共73份:均购自当地超市;小麦淀粉纯品、马铃薯淀粉纯品:购自Sigma公司。淀粉的近红外光谱在德国Bruker公司的MPA型多功能近红外光谱仪上测定。本文所涉及的化学计量学方法均采用MATLAB和OPUS软件完成。
1.2 方法
1.2.1 淀粉近红外光谱信息采集
将淀粉填装至采样杯,振荡使样品均匀后采用积分球漫反射方式进行扫描,采集淀粉的近红外光谱。为保证试验的准确性,对淀粉样品进行 2 次平行采样,并对平均光谱进行分析。光谱扫描范围为4000~12000 cm-1,分辨率为16 cm-1,扫描次数为64次。
1.2.2 定性模型的建立与评价
对市售的17份马铃薯淀粉、12份绿豆淀粉、24份小麦淀粉和20份玉米淀粉进行近红外光谱采集。通过矢量归一化(vector normalization,SNV)、一阶导数(first derivative,FD)、二阶导数(second derivative,SD)、FD+SNV、SD+SNV等方法对原始光谱进行预处理,并对预处理的方法进行优化。在最佳预处理方法的基础上,利用主成分分析(PCA)得到样品的PCA得分,该计算过程通过MATLAB软件实现。
PCA是多元统计分析中用来分析数据的一种方法,它是用一种较少数量的特征对样本进行描述以达到降低特征空间维数的方法,通过找到几个彼此互不相关,且能够表征原来所有变量所具有信息的综合变量来代替原始变量,简而言之,这种用几个互不相关的代表性变量来代表原来很多变量的统计学分析方法就成为主成分分析[18]。
1.2.3 定量模型的建立与评价
将购自Sigma公司的小麦淀粉和马铃薯淀粉纯品制备成30组不同比例的混合物,按照Duplex法[19]以2∶1分为 2 组,其中校正集20个,预测集10个,样本中小麦淀粉添加比例的统计结果见表1,校正集的小麦淀粉添加比例分布在7.29%~90.69%之间,预测集的小麦淀粉添加比例分布在18.04%~89.69%之间。数据划分均匀,校正集的小麦淀粉添加比例范围大于预测集,有利于构建稳健的预测模型。

表1 马铃薯-小麦淀粉样本划分Table 1 Division of potato-wheat starch sample
采用OPUS分析软件对样品的光谱图进行多元散射校正(multiple scattering correction,MSC)、SNV、FD、SD、FD+SNV、SD+MSC等多种方式的预处理。在最佳预处理方法的基础上,利用偏最小二乘法(PLS)建立不同比例的小麦淀粉-马铃薯淀粉和光谱数据之间的相关性模型,并选择校正均方根误差(root mean square error of calibration,RMSEC)、预测均方根误差(root mean square error of prediction,RMSEP)、校正决定系数(RC2)、预测决定系数(RP2)和预测集相对分析误差(RPD)作为模型的评价指标[20,21]。
2 结果与讨论
2.1 定性判别分析模型的建立
绿豆淀粉、马铃薯淀粉、小麦淀粉和玉米淀粉的近红外光谱见图1a。

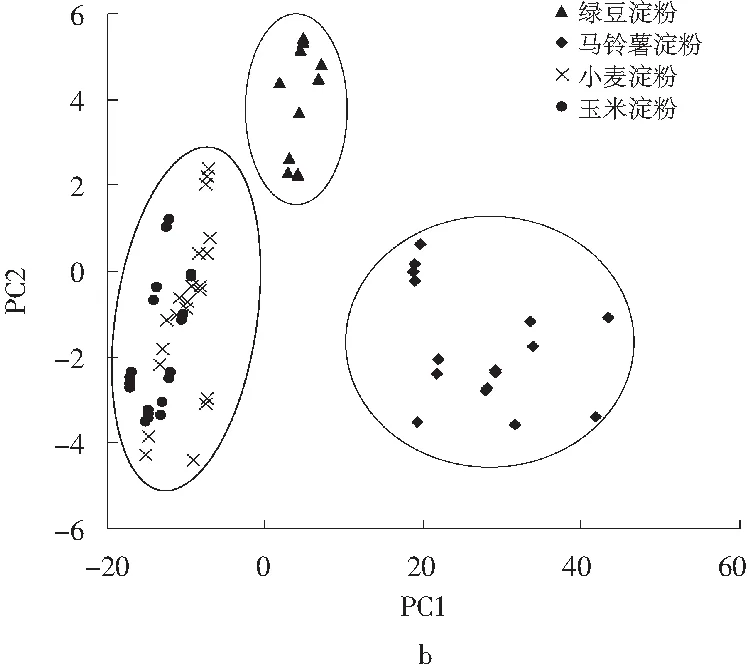
图1 不同品种淀粉的原始光谱图(a)和PCA散点图(b)Fig.1 Original spectrogram(a) and PCA scatter plot(b) of different starches
由图1a可知,不同种类的淀粉在12000~4000 cm-1范围内,峰形、峰位以及吸光度的差别较小,无法直接鉴别。首先对光谱进行预处理,然后进行主成分分析,通过OPUS分析软件得到的最佳预处理方法为SD+SNV,得到前两个主成分的累积贡献率为93.0%,基本包含了大多数的变量信息,选择第一主成分和第二主成分的得分作图(见图1b),进而对样品光谱进行分类。
由不同种类的淀粉样品的主成分分布图(见图1b)中可知,绿豆淀粉和马铃薯淀粉可以被完全区分开,且绿豆淀粉聚合度较好,但马铃薯淀粉的样品空间分布相对比较分散,可能是市售的马铃薯淀粉的原料品质及淀粉纯度差异较大的原因。玉米淀粉和小麦淀粉样品交叉重叠,区分不明显,可能与两种淀粉的理化性质相近有关,例如:小麦淀粉脂肪含量范围为0.07%~0.15%,玉米淀粉脂肪含量范围为0.1%~0.2%;小麦淀粉蛋白质含量范围为0.3%~0.5%,玉米淀粉蛋白质含量在0.35%~0.45%,脂肪和蛋白质含量范围交叉重叠[22,23]。近红外光谱信息反映了蛋白质和脂肪中由C、H、O、N等组成的特殊价键信息。因此导致两种淀粉光谱信息也存在交叉重叠现象,后期将进一步优化算法以进行玉米淀粉和小麦淀粉之间的区分。
2.2 定量分析模型的建立
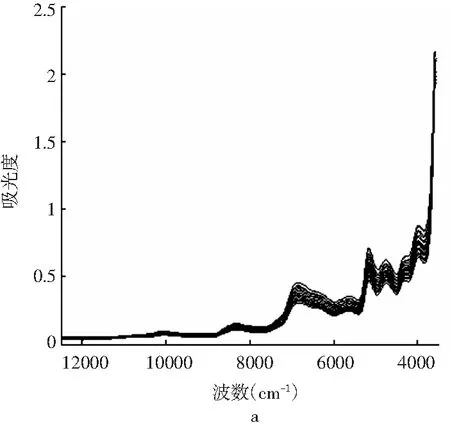
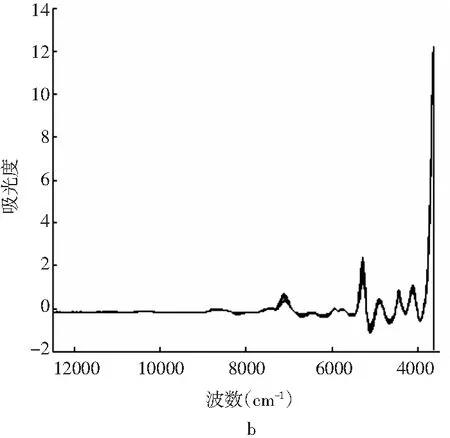
图2 马铃薯-小麦淀粉的原始光谱图(a)和马铃薯- 小麦淀粉的FD+SNV光谱图(b)Fig.2 The original spectrogram of potato-wheat starch(a) and FD+SNV spectrogram of potato-wheat starch(b)
不同比例的小麦淀粉和马铃薯淀粉的近红外原始光谱见图2a。为减少仪器噪声或基线波动产生的误差,以及消除大量冗余信息对有效光谱信息提取的干扰,首先对样品原始光谱图进行预处理,预处理方法包括:最小-最大归一化、SNV、MSC、FD、SD、FD+ SNV、FD+MSC、SD+SNV、SD+MSC等,然后基于PLS方法建立小麦淀粉比例的预测模型。不同预处理方法建立模型的评价数据见表2。
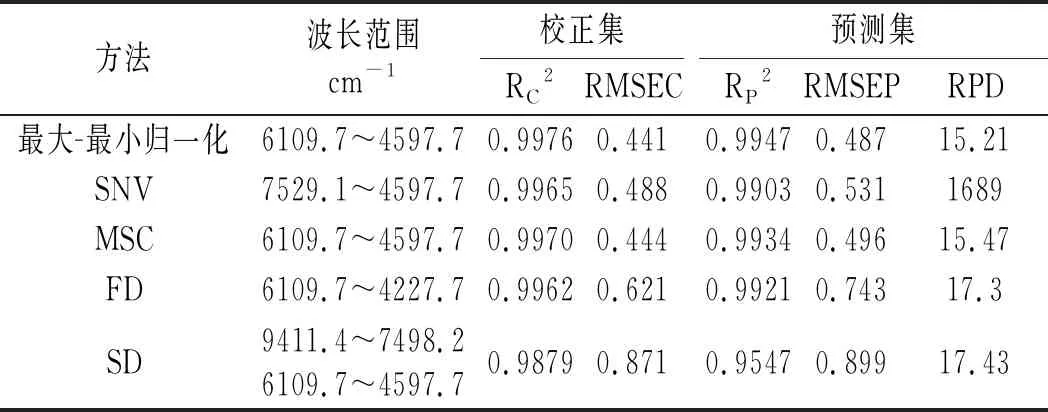
表2 不同处理方法对模型的影响Table 2 Effect of different processing methods on the model
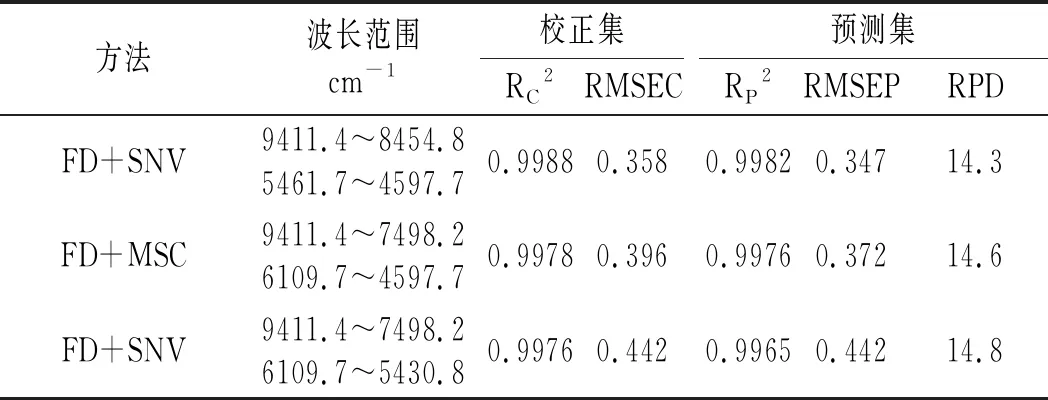
续 表
以预测均方根误差(RMSEP)和决定系数(R2)为检验指标选择最优预测模型。由表2可知,经FD+SNV预处理后,采用PLS法建立的马铃薯-小麦淀粉的定量模型效果最佳,其决定系数分别为0.9988和0.9982,且校正集的RMSEC和预测集的RMSEP值以及相对分析误差(RPD)最小,这一结果表明该模型校正集拟合效果和验证集的预测效果都较好。一阶导数+SNV预处理后的光谱见图2b。
以小麦淀粉添加比例的真实值及预测值为横、纵坐标,得到校正集和预测集的散点图(见图 3)。校正集决定系数R2=0.9988,回归方程为 y=0.9934x+0.374,验证集决定系数 R2=0.9982,回归方程为 y=1.0268x-1.48,相关性均达到极显著水平,表明近红外定量分析模型测定结果准确可靠。
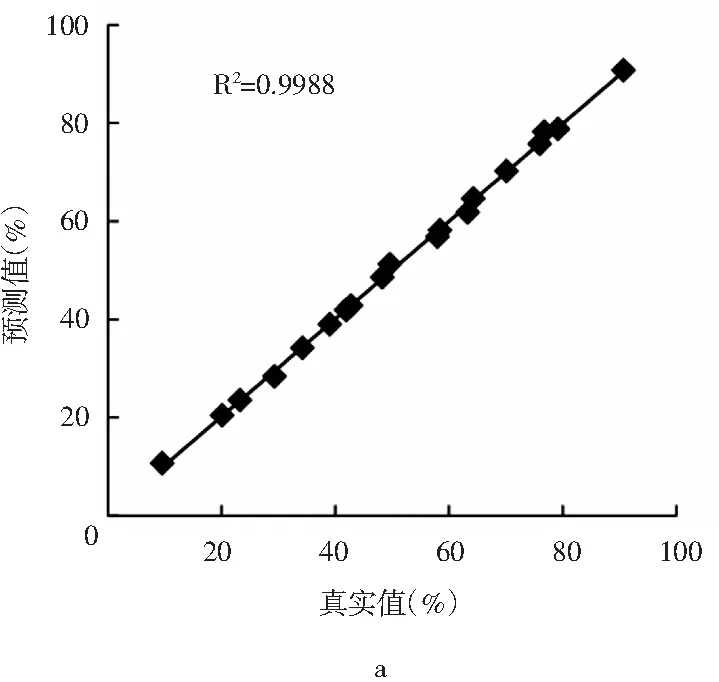
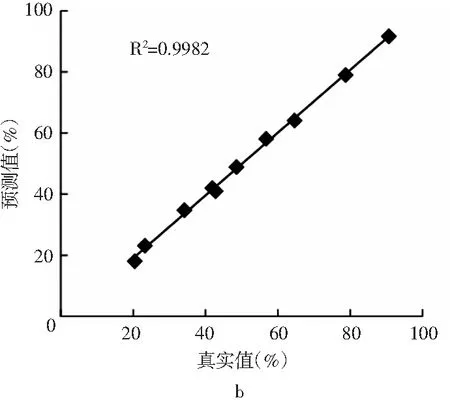
图3 马铃薯-小麦淀粉中小麦淀粉添加比例的校正集(a) 和预测集(b)的预测结果Fig.3 Prediction results of correction set(a) and prediction set(b) of wheat and starch addition ratio in potato-wheat starch
3 结论
本研究基于近红外漫反射技术,建立了一种淀粉种类的快速无损检测方法。通过对不同种类的淀粉进行光谱采集,结合不同预处理方法及主成分分析法(PCA),建立了不同种类淀粉的鉴别分析模型,通过分析,马铃薯淀粉和豌豆淀粉可被较好地鉴别,玉米淀粉和小麦淀粉界限不明显。基于定性分析结果,建立淀粉混合物的定量分析方法,以不同比例的马铃薯淀粉和小麦淀粉的混合物为检测对象,对混合物中小麦淀粉添加比例进行定量预测,采用多种光谱预处理方法,基于PLS建立混合物的预测模型,最优模型的校正集和预测集其决定系数分别为0.9988和0.9982,均方根误差分别为0.385和0.347,预测相对分析误差(RPD)为14.6。结果表明,该方法准确度高,且无需对样品进行处理,操作简单,可实现快速无损鉴别淀粉种类的目的。
