基于数据挖掘的反信用卡套现方案设计与实现
2019-10-15朱智君陈苏阳
朱智君,陈苏阳
(中山大学 南方学院,广东 广州 510000)
“互联网+”背景下,信用卡产业发展迅速并具备一定规模.根据中国人民银行统计,截至2018年一季度末,信用卡发卡量共计6.12亿张,人均持有信用卡0.44张;信用卡授信总额为13万亿元,平均每张卡授信额度2.15万元.信用卡在便利生活、促进销售、刺激需求等方面发挥重要作用[1],与此同时,由于风险意识、用卡环境不规范、风险管理技术水平落后等问题,信用卡套现风险不容小觑[2].
信用卡套现是指持卡人通过正常合法手续(ATM或柜台)以外的其他手段,将信用额度内的资金以现金方式套取,同时不支付银行提现费用的行为.信用卡套现的实施借助于“2主体+1中介+1手段”[3].其中,“2主体”是指现金存储双方,包括银行、个人.一般情况下,银行是现金流出主方,个人是现金流入主方,金钱流动方向是“银行→个人”;“1中介”是指POS机、网络商家、航空公司等.信用卡个人用户通过中介完成信用卡套现过程,在此过程中,中介往往收取部分手续费(提现费用);“1手段”是指在银行主体不知情的情况下,个人主体通过中介进行手段操作(个人主体可以通过POS机与商家进行虚假交易;个人主体进行虚假购票、错误购票,进行退票等服务).必须强调,这些手段具有欺诈、违法、犯罪等特性.
国内外现有文献研究重点聚焦于信用卡风险管理流程、信用卡风险管理困难、数据挖掘算法研究等方面[4-7].在信用卡风险管理实践中,年龄、职业、月收入、住宅所有权、是否有电话、居住现址与工作的时间长度、地方区别、是否在国家机关工作、之前贷款数量等因素为信用风险模型显著变量.伴随着银行间竞争日趋激烈化,导致信用卡审核标准降低、信用卡发行及管理混乱、信用卡管理及使用风险提高.现阶段,信用卡风险管理存在风险意识缺失[8]、用卡环境不完善[9]、风险管理技术水平落后等问题.
1 相关技术介绍
1.1 信用卡套现模型思路
首先,基于信用卡数据进行数据抽样.定义信息增益公式如下:
Gains(U,V)=Ent(U)-Ent(U/V).
(1)
该增益用于衡量信息,以消除数据抽样中存在的随机不确定性的程度.
其次,根据计算出的信息增益数值进行排序(排序顺序反映各个属性变量在决策时的相对重要程度),并将排序数据标准化:
(2)
其中i∈R,xi表示不同属性增益值.相对重要程度在进行反套现时只是反映某个属性的相对程度,不能具体反映各个属性数值所对应的风险程度,因此本文定义衡量数值对应风险程度的变量——信用风险程度值.具体公式如下:
Zj=(a1×xj 1+a2×xj 2+a3×xj 3+a4×xj 4)/(xj 1+xj 2+xj 3+xj 4),
(3)
其中xj 1、xj 2、xj 3、xj 4分别表示属性为j时,正常客户、需关注客户、嫌疑客户和套现客户的人数;a1、a2、a3、a4分别表示上述客户的风险系数.套现可能性与风险系数呈现出正相关关系.最后,对风险程度值Zj进行标准化处理,具体公式如下:
(4)
1.2 基于决策树算法的分类方式
1.2.1 预处理分类数据
1)数据规范化 在原始数据集合中,部分属性与分类的相关性较弱.因此,需要从众多属性中选择与分类目标相关性强的属性.在本文中,为了确保分类效果,选择了4种相关性强的属性,分别是:信用卡笔数、信用卡金额、信用卡笔数占比、信用卡金额占比.每条数据信息主要由客户代码、信用卡交易笔数、交易金额、金额占比和是否套现等构成.
一般而言,采取最小最大规范化方法需要预知具体值,容易受噪声数据影响.但是规范化方法可以消除属性之间值不同所导致的权重区别,并且能够将数据映射至所需数据区间.根据交易金额属性,最小值为1 500,最大值为4 845 300.采取规范化方法进行计算,所有交易金额数据均位于[0,1]区间.对整个数据集进行规范化后的结果如下表所示.
2)数据的泛化 由于决策树算法连续数值处理能力较弱,因此需要对规范化后的数据进行泛化处理,将其处理成离散数据.本文中规范化后的数据映射区间为[0,1],因此可以根据数值来进行low,medium和high的划分.划分依据如下:[0,0.36]区间为low,[0.36,0.70] 区间为medium,[0.71,100]区间为high.泛化后的数据如下表所示.
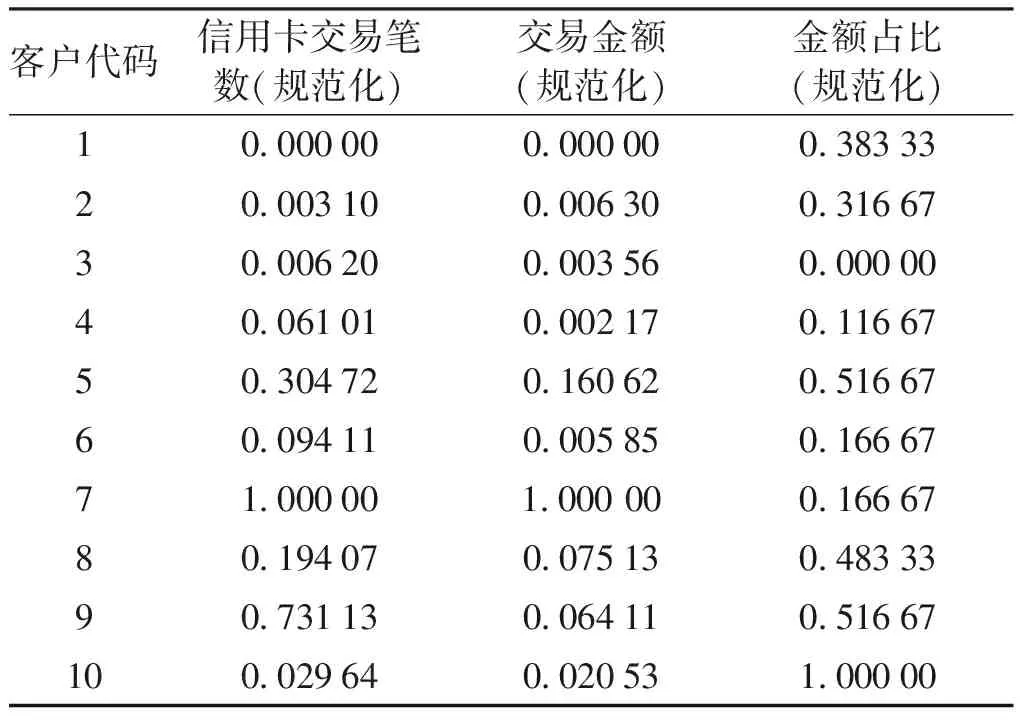
表1 完全规范化后的结果表
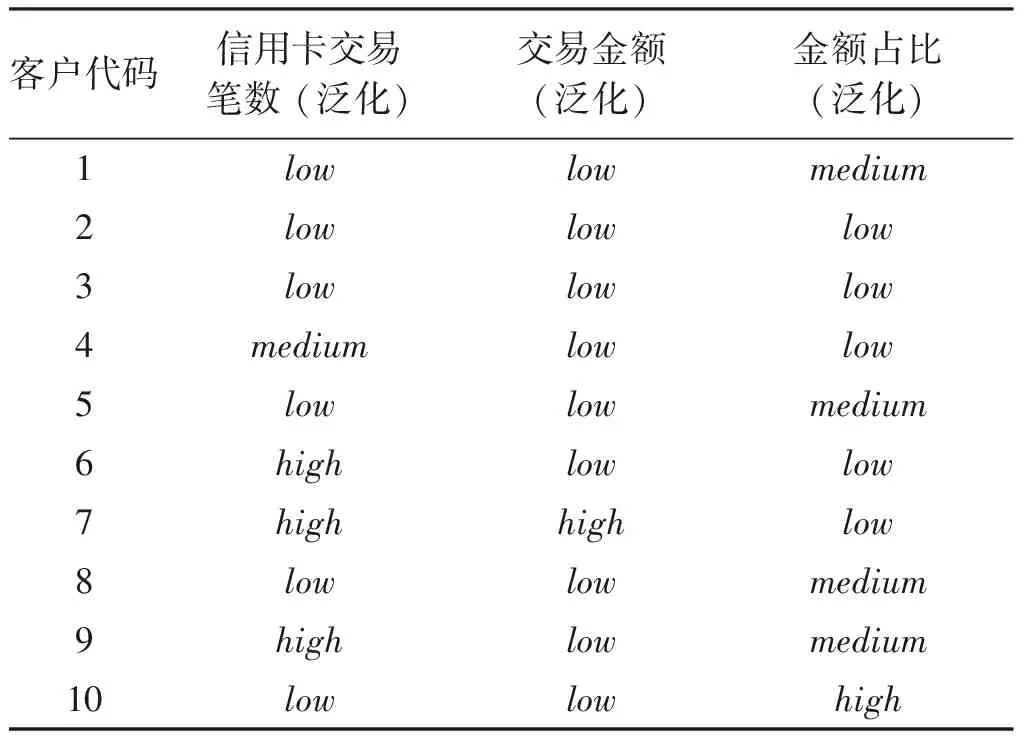
表2 数据泛化的结果表
1.2.2 属性选择度量
综合考虑属性情况、测试代价、收益情况,重新设计划分属性选择因子计算方法,以平均信息增益替代经典信息增益,提高分类能力.
假设训练集为T,节点划分属性因子的计算如下:
(5)
其中,Ai为属性集合A的第i个属性.Averag-egain(Ai)表示平均的信息增益.TC(Ai)normal表示测试的代价情况.Incr_UCB(Ai)表示属性Ai的增长情况.
1.2.3 决策树剪枝
为确保剪枝效果,本文采用最小项目数目方法进行剪枝[10].最小项目数目剪枝方法要求在剪枝之前设定每个分支最小项目的数目σ,然后自上而下对树进行扫描,具体方法如下:
1)假设子树tb的左右2棵子树的项目均小于σ,那么剪掉子树tb,且在tb的位置上用叶节点替代.
2)若子树tb左子树的项目小于σ,但是右子树的项目数目大于或者等于σ.那么将tb左子树的左子树剪掉,用右子树替代tb.
1.3 基于KNN算法的分类方法
1.3.1KNN算法的基本思想
KNN算法(k-nearest-neighbor)算法是选择特征空间中最邻近训练样本的数据进行分类.其基本思想是所需要处理的数据属于某一类取决于这个数据周围临近的k个点.
通常KNN算法要求样本属性值连续.本文采用欧氏距离计算不同样本之间距离,其二维公式如下:
(6)
若样本的属性为多维则公式如下:
(7)
其中xi1表示的是x1点的第i维的属性值,而xi2表示的是x2点的第i维的属性值.由上述公式不难看出,本算法在计算距离时,如果点和属性较多,那么计算开销将十分大,这对硬件性能提出较高要求.
1.3.2 数据的预处理
在计算过程中通常会出现样本特征值取值范围较大的情况.例如:特征A和B,若A的值区间在[0,1]之间,而B的取值范围在[0,100 000]之间,就会出现计算后的距离将十分远离A.另外,有些样本属性与分类无关,还存在不同量纲的情况,所以需要对数据进行预处理.本文采用的预处理方法是对属性值进行规范化.
2 改进算法分析
2.1 改进的决策树分类过程
2.1.1 改进的决策树算法步骤
为了简化模型同时不完全丢失熵模型优点,CART分类算法使用基尼指数进行样本属性选择;为了提高识别效果,本文采用随机森林模型提高反套现识别的准确率[11].在本文的随机森林模型中,将决策树模型和CART算法相结合,以确保模型具有良好鲁棒性和泛化能力.
改进后的决策树算法步骤如下:
Step 1 初始化ρmin=∞,最优子树集合ω={T},α=2;
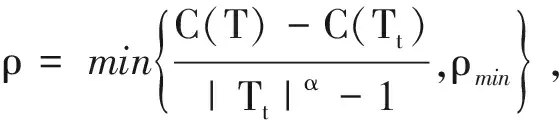
Step 3 得到所有节点的ρ值的集合M;
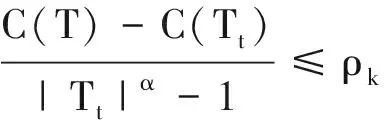
Step 5 最优子树集合ω=ω∪Tk,Mk=M-{ρk};
Step 6 如果M不为空,则回到步骤4,否则就已经得到了所有可选最优子树集合ω;
Step 7 采用交叉验证在ω中选择最优子树Tρ.
改进的决策树结果展示如下:
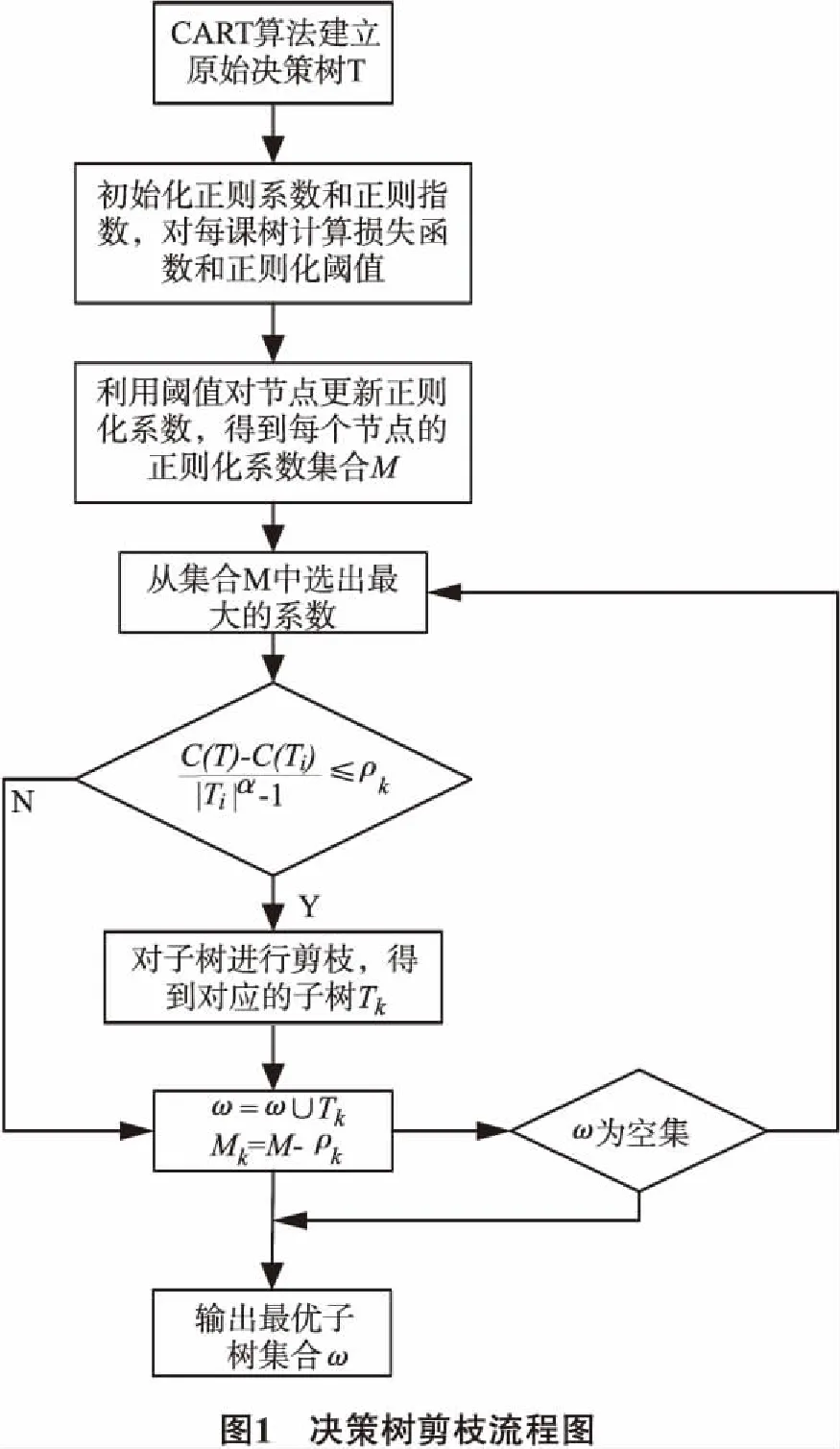
根据下图所示的结果,共有29根决策路径.其中有16根路径是为套现结果.将整个决策结果导入至Risk_Decision_Tree.
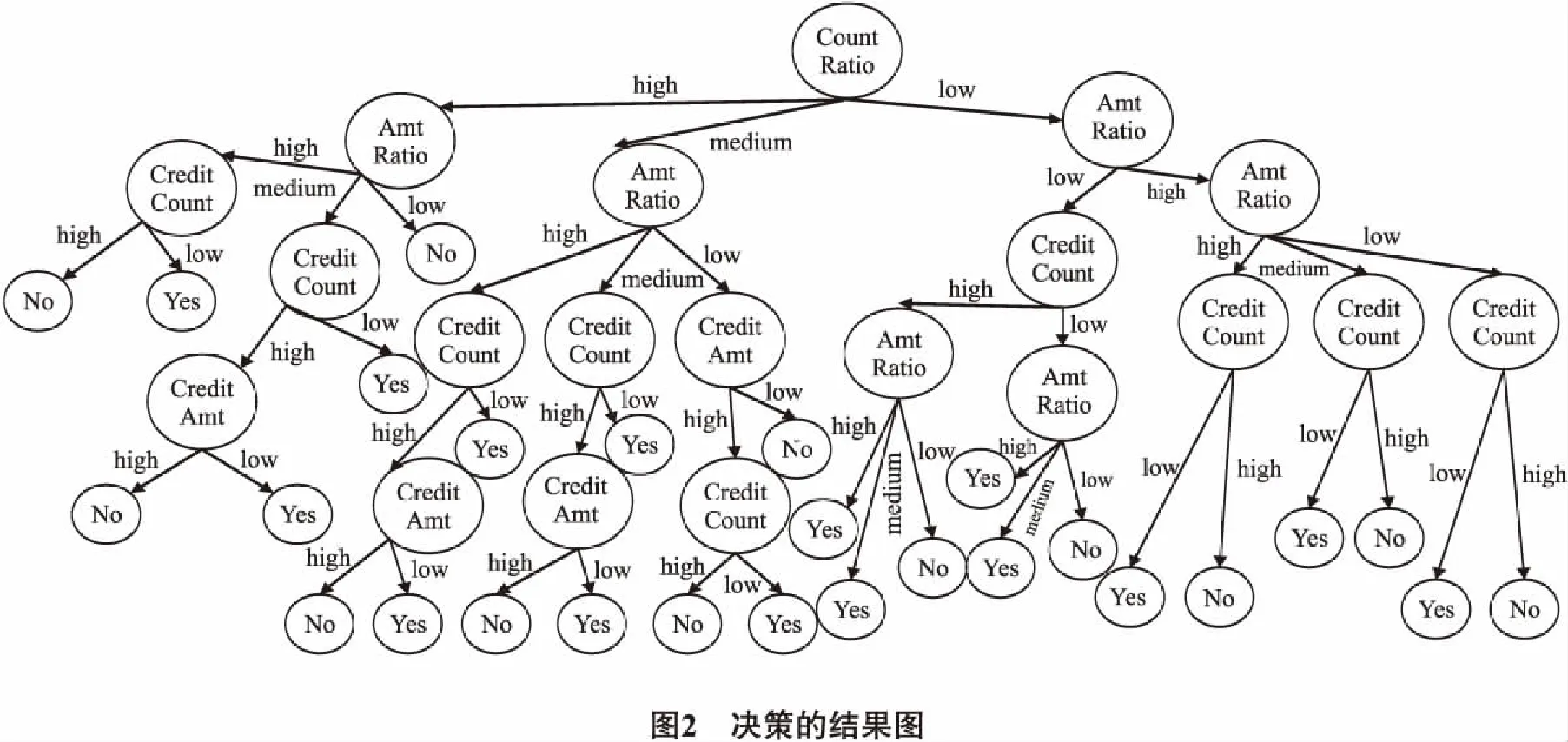
2.1.2 应用已训练的决策树
已知一个商户的4个特征属性:信用卡笔数占比(count ratio)、信用卡金额占比(amount ratio)、信用卡金额(credit amount)、信用卡笔数(credit count),采用下述方法判断客户是否为套现客户(fraud).统计发现,所有的测试实验数据中,12%的客户为套现客户,准确率超过80%.
2.2 改进的KNN算法分类过程
2.2.1 模型的改进和实现
对于某个样本,改进后的KNN算法基本步骤如下:
Step 1 对于样本中每个属性在不同类中的数目,计算单个属性的信息熵.
Step 2 计算测试样本与训练样本相同属性值的平均信息熵.测算它们之间的距离.
Step 3 设置对应的k值,选取彼此之间距离小的前k个样本作为近邻样本.
Step 4 计算这些近邻样本在不同类别中的个数,然后计算这些近邻样本在类别中的平均信息熵.最后根据距离和平均信息熵计算可信度.
Step 5 对可信度的大小进行对比,获取可信度较大的类别作为分类.
2.2.2 基于函数库的算法实现
在此过程中,与前面决策树分类过程相似.首先是根据商户的代码确定交易的总数量(上同),然后基于本文设定的交易记录属性(信用卡交易笔数、信用卡交易金额、信用卡笔数占比、信用卡金额占比)进行规范化处理(上同).因为KNN算法可以计算连续的数值,因此不需要对数据进行泛化(转换为low/medium/high).
函数名称:knn_classify
传入参数:k值,信用卡笔数,信用卡金额,信用卡笔数占比,信用卡金额占比
返回结果:1,0.是否套现.
2.2.3 函数的测试环节
本部分将对knn_classify(7,0.5,0.5,0.5,0.5)进行测试实验.若测试结果为0,那么判断客户不是套现客户.
2.2.4 分析分类的结果
对已进行预处理的交易数据进行实验发现,确定没有套现的客户数量占总数的比例为91.20%.改进后KNN算法和改进后决策树方式的分类结果相差无几.影响实验结果的因素主要包括数据规模、特征选取等,训练集规模越大,所获得的实验结果将会更好.
2.3 改进算法评价
2.3.1 改进的决策树算法评价
虽然决策树算法能够快速的完成分类,具有快速建模、训练时间短等优点.但是单颗决策树模型依然存在容易过拟合等问题.在ID3算法中使用了信息增益来选取特征,信息增益大作为优先特征.在C4.5算法中,采用了信息增益比来选择特征,以减少信息增益容易选择特征值多特征的问题.但是无论是ID3还是C4.5算法,都是基于香农信息理论的熵模型来定义和度量的,其中涉及大量对数运算.
因此为了简化模型同时不完全丢失熵模型优点,CART分类算法使用基尼指数进行样本属性选择;为了提高识别效果,本文采用随机森林模型提高反套现识别的准确率.在本文的随机森林模型中,将决策树模型和CART算法相结合,以确保模型具有良好的鲁棒性和泛化能力.
2.3.2 改进的KNN算法评价
传统的KNN算法通常采用欧式距离等方法测算对象间距离,当不同对象特征重要行不同或者相似度差异较大时,进行欧式距离测算会影响最终分类结果.
因此本文采用信息熵判定对象属性特征重要性,信息熵越小,属性对分类结果的重要性越大.同时基于一种模糊聚类的方式对KNN的类别进行约化,在聚类后n个簇中采用自适应权重的k邻近算法,以加快分类效率.
3 信用卡套现行为识别实现
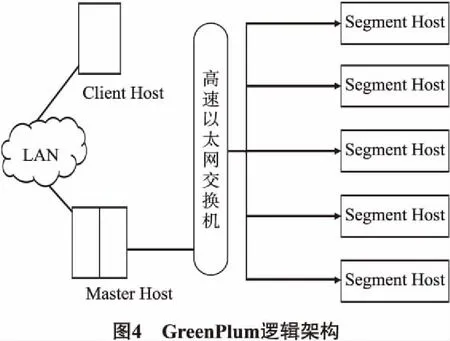
3.1 GreenPlum的设置
本文采取分布式数据库GreePlum,并采用五台服务器做为整体计算节点[12].其中,1台服务器做为控制主机master,剩下的4台服务器均为计算节点segment.控制主机master主要功能是对计算任务进行分配和计算结果进行收集,计算负载较低.而主要的计算负载均由剩余4台计算节点承担.当需要增加计算节点时,可以直接在交换机上进行连接,然后在控制主机中添加ID即可.控制主机master与后台交易数据库需要进行连接,确保正常的获取信用卡的交易记录.通常银行采用的数据库是oracle数据库,采用的处理方式是OLTP,此方式对数据记录的速度要求较高.而本文采用的greenPlum集群则采用OLAP方式,这种方式主要是对数据进行详细汇总.
3.2 数据的迀移
由于数据库处理方式存在区别,因此从后台的Oralce数据库对GreenPlum进行数据迁移十分复杂,并且缺乏相应工具.因此设计可以对SQL文件进行操作的程序,在设计中整个信用卡的交易信息汇总表并不能导入,只能借助于跟POS内容的有关交易流水表来实现.
其中:
Consumer_risk表示客户风险表;Consumer_risk_rd表示商户风险记录表;
Risk_total_stat表示行业风险汇总表;Risk_ Consumer _sett表示风险客户清算表;
Risk_sc表示风险得分表;Risk_ Consumer表示风险客户内容表.
3.3 信用卡交易数据的分析
本文所采用数据来自于银行后台系统,整个数据集总共包含了过去十年的交易情况,交易记录条数达到了6亿笔以上.近十年来POS的交易笔数直线上升,因此为了提高实验效率、降低对系统的运行影响.本文收集2012年份最后一个月的客户信息,完成数据处理后,共得到1 037条客户的交易记录.在这些记录中,已经确认套现的客户有94个,其余的均为正常客户.所以,本文的实验目标是将1 037客户数据作为训练集训练决策树,运用训练好的决策树模型分析其它未标记数据,判断其中客户是否是套现客户.
3.4 交易数据预处理
3.4.1 汇总POS的交易流水表
将交易流水表定义为RISK_ OPERATIN表.在该表中包含字段有:客户代码、信用卡的交易笔数、总体交易金额、笔数占比、金额占比.
3.4.2 标准化RISK_ OPERATIN 表
首先提取出每个属性的最大最小值.
完成计算后,整个交易笔数中最小的数值是0,最大的数值是41 521.26;整个交易中交易金额最小的数值是0,最大的数值是136 483 009.41.整个交易中笔数占比最小的数值是0,最大的数值是1;整个交易中金额占比的最小的数值是0,最大的数值是1.
3.4.3 泛化RISK_ OPERATIN
因为本文采用的决策树算法只能处理离散的特征值,因此需要将标准化后的数据进行离散化,本文按照[0,36],[36,70],[71,100]划分为3个等级:low,medium,high[6].首先自定义1个函数data_generalize().整个泛化阶段的部分SQL语句如下所示:Data_segment(amount_ratio) from riskstatistic
4 结语
“互联网+”使得通过技术手段干预控制信用卡套现可能性逐渐变为现实.技术人员在数据库中设置逻辑规则,采取数据挖掘方式从核心系统中提取交易数据进行甄别,罗列出疑似信用卡套现人员名单,在此技术上进行人工校核;或者在交易系统当中植入预警规则进行实时监控,使得工作人员基于交易数据进行判断,建立起严密反套现体系.“反套现模型+资金异常监控系统+文本挖掘”等依托于大数据实现的反套现措施以大量数据采集工作为前提,对系统算法提出更高要求.本文基于大量数据卡交易信息,将数据挖掘理论应用于信用卡反套现评估中,运用数据挖掘算法中的决策树、KNN模型实现对信用卡套现行为、套现客户的辨别.经过实验验证,模型具有良好的应用效果,能够优化银行反信用卡套现识别、改善银行工作效率.
