基于深度强化学习的交通路径诱导研究
2019-10-14
(沈阳理工大学信息科学与工程学院 辽宁 沈阳 110159)
引言
科技社会的发展使城市交通拥堵日益严重,智能交通系统作为一种解决城市日益拥堵所带来的问题的有效途径,特别是交通诱导可以有效的缓解交通拥堵,提高人们的出行效率。
深度强化学习不仅具有深度学习的感知能力,可以有效的提取复杂的特征。还具有强化学习的决策能力,通过不断与环境进行交互反馈,对决策进行调整改进。因此本研究采用深度强化学习构建交通路径诱导系统。首先选择合理有效的路径诱导特征,通过构建深度强化学习网络模型,建立双网(DoubleDQN),采用玻尔兹曼概率行为选择策略,诱导路网中的车辆行驶。
一、模型介绍
本研究主要使用的是DQN[1]。传统的DQN通常会高估Action的Q值。如果这种高估是不均匀的,可能会导致本来次优的Action总是被高估而超过了最优的Action,造成过估计。而DoubleDQN[2]不是直接选择targetDQN上最大的Q值,而是在主DQN上通过其最大Q值选择Action,再去获取这个Action在targetDQN上的Q值。主网络负责选择Action,而这个被选定的Action的Q值则由targetDQN生成。被选择的Q值,不一定是最大的Q值,这样就解决了过估计的问题。DoubleDQN的学习目标可以写成下面的公式:
Target=rt+1+γ.Qtarget(st+1,argmaxa(Qmain(st+1,a)))
二、路径诱导系统分析
(一)路径诱导的特征选择
路径诱导的特征选择十分关键,如何选择合理有效的特征对路径诱导的效果起到了至关重要的作用。路网中的车辆行驶过程如下图所示:
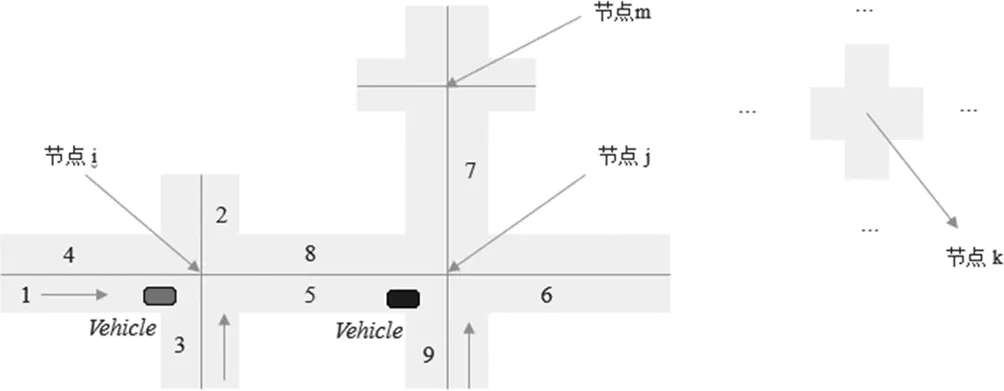
图1 车辆从节点i经5号边行驶到节点j
假设车辆从节点i经过5号边行驶到节点j。本研究的目的是对交通路网中的车辆通过算法进行路径诱导。考虑选取的特征为:当前节点j的坐标和目的节点的k坐标;车辆行驶在当前节点的相邻节点为i;车辆从节点i到节点j通过 5号边的所花费的真实行驶时间;以及综合考虑整个路网的各个节点的车流量密度。
(二)选择策略
本研究采用玻尔兹曼概率选择策略[3]。玻尔兹曼概率选择策略是Softmax选择策略的一种,根据不同的行为选择策略把不同的Q值对应不同大小的选择概率,最优Q值具有最大的选择概率:
τ是温度参数,随着温度参数的值逐渐变大,不同的Q值对应的行为选择的概率大小就越近似。随着温度参数的值逐渐变小,玻尔兹曼概率分布策略和贪心策略就越来近似。
(三)诱导系统的组成部分
一部分是导航过程,主要负责当车辆运行到交叉口时,下一步应该选择走哪一条路线,即对车辆进行的诱导。另一部分是训练过程。
导航过程,通过SUMO仿真器获得车辆当前路网的状态:当前节点坐标值,目的节点坐标值,相邻节点坐标值,整个路网的密度车流量密度。然后通过Socket发送数据。并把接收到的state作为神经网络的输入。根据神经网络得到四个Q值。并通过玻尔兹曼概率选择策略得到动作,该动作即车辆到达交叉口下一步要选择的动作。并返回该action。
训练过程,通过仿真器收集数据state,action,reward。把通过Socket得到的数据组合成强化学习的的四元组(s,a,r,s’)。把强化学习的的四元组(s,a,r,s’),也就是样本存储到经验池中,当满足批处理的数量时,把该数据作为神经网络的输入,对神经网络进行训练。
三、实验分析
(一)仿真器
本研究使用SUMO(SimulationofUrbanMobility)仿真器进行仿真。SUMO仿真器由德国宇航中心研发,把真实的城市作为模拟的依据,实现对现实中的城市的路网、道路、交叉口、车辆、行人,交通设施等的仿真,并可以通过接口与java程序进行交互。本研究课题通过搭建SUMO仿真器,设置SUMO仿真器中的路网结构文件,并写出SUMO仿真器运行需要的相应程序,采集实验数据。
(二)实验结果
通过SUMO仿真器模拟对车辆进行诱导,运行交通路径诱导系统,并进行实验。实验的评价指标为:路网中的实际车辆数量和车辆在路网的平均行驶时间。路网中的车辆的数量越少,车辆的平均行驶时间越短,说明路径诱导的效率越高。
对已经设置的路网结构,分别使用基于传统的Sarsa方法和深度强化学习方法对交通路网中的车辆进行诱导实验。根据实验的评价指标,通过实验得出实验结果。使用Sarsa方法诱导时,路网中的平均车辆数量为155.8788,平均行驶时间为111.9692。使用深度强化学习对路网中的车辆进行进行诱导时,路网中的平均车辆数量为127.5253,平均行驶时间为97.1384。通过与传统强化学习Sarsa学习算法进行对比实验,深度强化学习的诱导效果优于传统的Sarsa学习诱导。
四、结论
实验结果表明基于深度强化学习的路径诱导可以有效缓解路径中交通的拥堵,为交通路径诱导提供了一种有效的解决方式。
