循证医学数据库信息模型中证据强度模块的构建及验证
2019-10-14
近30年来,循证医学从其最初关注点——教育临床医生如何理解并使用文献以及系统综述科学,逐渐发展为强调证据评价与患者价值观和意愿选择相结合。其中,循证医学证据的质量对医学决策成功与否起着决定性的作用。证据质量越高,对诊断性质、预后和健康干预效果的估计就越接近事实[1]。因此,如何对证据进行评价和在爆炸式的医学文献中找出最佳临床证据,是医务人员进行循证医学的关键步骤,能够帮助医务工作者更高效地进行临床决策。
循证医学数据库能够有效帮助临床医务人员快速定位最佳临床证据,是获取最佳临床证据、更新临床知识、解决临床问题的重要信息源,而且证据强度信息对临床医生快速获取最有价值的信息至关重要。国外知名的循证医学数据库DynaMed不仅提供循证医学证据信息,还对证据信息来源进行分级评估。我国循证医学数据库建设尚处于起步阶段,目前还未建立起一个权威的、可靠的循证医学数据库。根据笔者之前的研究结果[2],笔者认为一个好的循证数据库信息模型应具备文献特征、诊疗过程和证据强度3个顶层结构模块,并且能够直接对证据进行分级和推荐强度信息,能够提供对证据强度方面的检索或分类功能。在徐维的研究中[3]还探索建立了表达临床证据的循证医学数据元,但是研究中证据强度模块的构建依据和反映证据强度的数据元还比较单一。本文根据国际上已有的随机对照试验报告撰写标准及严格评价标准,从循证医学数据库信息模型的证据强度模块入手,进一步细化该模块的信息模型,并探讨证据强度模块中数据元反映文献证据质量的效果,对证据强度进行初步判断。
1 证据强度模块的构建
1.1 报告标准的选取
在苏格兰校际指南网(The Scottish Intercollegiate Guidelines Network,SIGN)标准,牛津大学循证医学中心(Center for Evidence-Based Medicine,CEBM)标准,推荐分级的评估、制定与评价(Grading of Recommendations Assessment,Development and Evaluation,GRADE),以及中国循证医学中心分级标准等国际上使用范围较广的循证医学证据标准中,高质量的随机对照试验及与其相关的系统性综述、Meta分析均属于最高等级证据类型,被看作临床证据的“金标准”[4-7]。因此,为更好地评价随机对照试验,帮助医务人员判断证据质量,笔者对比分析了国际上权威的随机对照试验报告质量标准CONSORT 2010(CONsolidated Standards Of Reporting Trials)[8]以及部分权威的循证医学网站提供的严格评价工具,包括牛津大学循证医学中心制定的随机对照试验严格评价工作表(CEBM)[9]、牛津大学所属公司Better Value Healthcare Ltd(BVHC)开发的严格评估技术项目(Critical Appraisal Skills Programme,CASP)[10]、苏格兰校际指南网制定的随机对照试验严格评价说明和工作表(SIGN)[11]、澳大利亚Joanna Briggs Institute(JBI)循证卫生保健研究中心制定的随机对照试验的严格评价工具(JBI)[12]。
1.2 数据元的提取
对以上随机对照试验的报告标准及严格评价工具进行对比分析,统计其中共同出现的评价标准及其次数,其结果如下。
在CONSORT、CEBM、CASP、JBI及SIGN中均提及随机/顺序产生、分配隐蔽机制,两组样本是否相似或基线资料,除被分配的治疗外各组是否接受相同的处置、失访比例,是否将失访患者纳入ITT(Intention To Treat)分析、盲法等评价项目。CEBM、CASP及SIGN中均出现了“PICO是否明确”这一要求,在CEBM、CASP及CONSORT中均出现了对于置信区间的要求,在JBI和SIGN中均出现了结果统计方法标准、合理、可信的要求。
因此,结合随机对照试验报告质量标准CONSORT 2010及以上严格评价标准等要求,并考虑证据的表达性、标引和可读性等因素后,选用了Patients/Problems-Intervention-Comparison-Outcome(PICO)、顺序产生、分配隐蔽机制、样本一致、干预一致、失访比例、盲法、置信区间、结果、样本量、流程图等数据元,构成了循证医学数据库证据强度模块。其本体结构如图1所示。
将PICO这一元素细化为“疾病”“干预”“结局”3个数据组或数据元。其中“疾病”数据组可细化为“疾病名称”和“疾病对象”2个数据元,“干预”数据组又可分为“干预(试验)”和“干预(对比)”数据组并进一步细化为“手术名称”和“药物名称”2个数据元,“疾病”数据组和“干预”数据组均可复用在信息模型的诊疗过程模块。另外将“样本一致”和“干预一致”组成为“一致性”数据组。
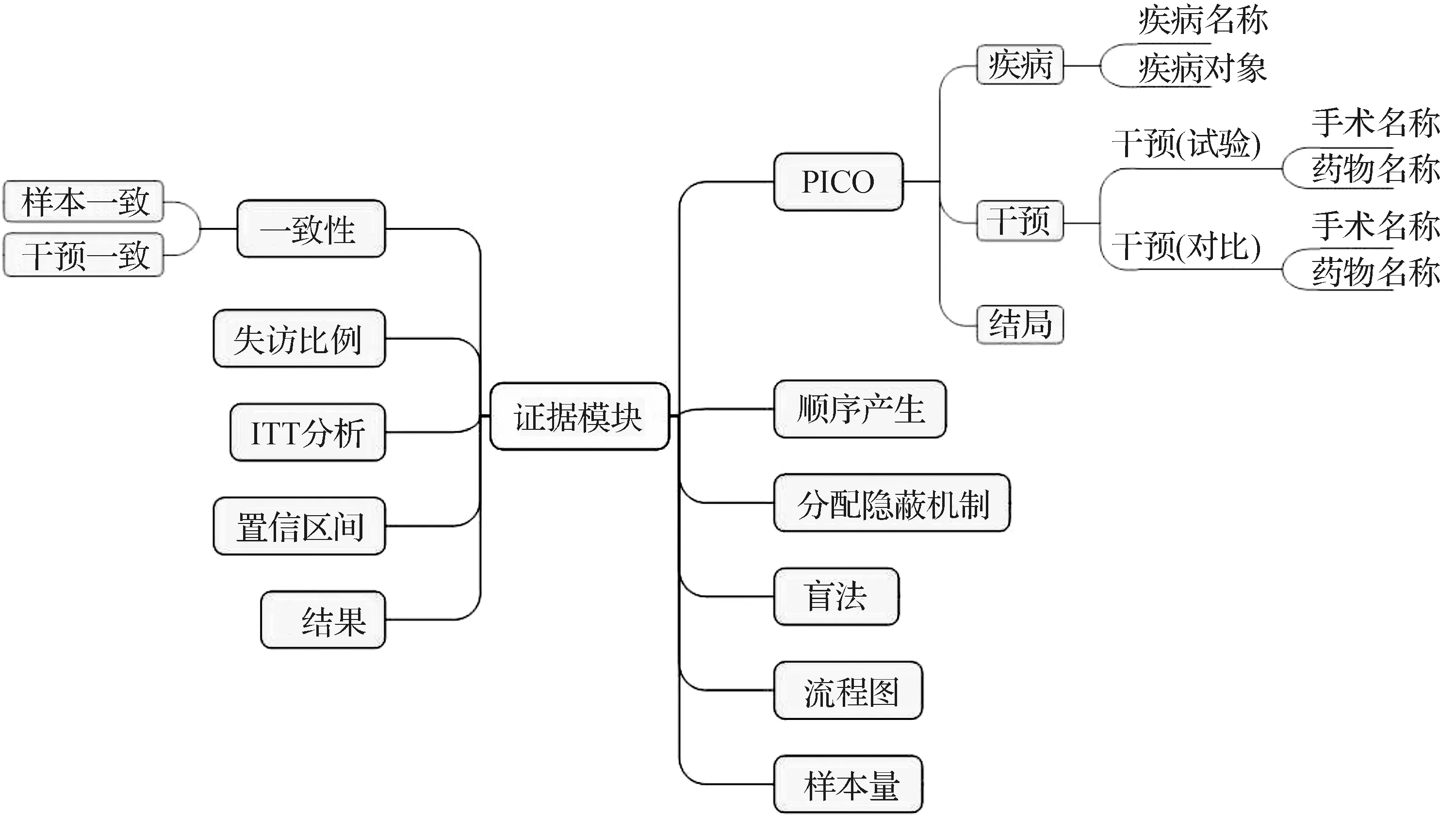
图1 循证医学数据库证据强度模块的本体结构
2 证据强度数据元满足度排序
在证据强度数据元中选出顺序产生、分配隐蔽机制、盲法、样本一致、干预一致、失访比例、ITT分析、置信区间、流程图等元素,作为质量评判以及排序的主要依据。虽然PICO、结果、样本量等数据元重要,但不便于质量评判,因此暂不评判。对选出的9个数据元进行相应的满足度计算,满足为1,不完全满足为0.5,不满足为0,共计9分。将该分值作为随机对照试验的主要排序依据,若分值相同则按照样本量进行降序。具体满足度评判依据如表1所示。

表1 证据强度模块各元素分值
3 证据强度模块的验证
为验证本文中证据强度模块及其评分量表的可行性,由1名研究人员在知名循证医学数据库DynaMed中筛选合适的随机对照试验文献,并由2名著录人员按本证据强度模块对其进行标引。本文选取了世界卫生组织(WHO)全球健康观察(GHO)数据中死亡原因前3位的疾病,即缺血性心脏病(Ischaemic heart disease)、中风(stroke)、慢性阻塞性肺疾病(chronic obstructive lung disease)[13]。在DynaMed中查看对应的主题“Coronary artery disease (CAD)”“stroke(acute management)”“COPD”,并选择其中有明确证据分级和文献链接的随机对照试验,筛选近10年来用手术或药物治疗以上疾病的相关文献29篇。将这29篇文献发给2名著录人员进行著录和评分。为对满足度分值与DynaMed的证据等级进行对比,以90%、70%作为1、2、3级之间的区分比例,初步设定分值大于或等于8.1为1级,分值大于或等于6.3且小于8.1为2级,分值低于6.3为3级。以“Acute Effects of Acu-TENS on FEV1 andBlood β-endorphin Level in Chronic ObstructivePulmonary Disease”[14]一文为例,著录结果如图2所示。
结果显示,22篇文献中的证据等级与DynaMed一致,另7篇文献与DynaMed不一致。具体评分结果如表2所示。通过SPSS软件对两组等级数据进行kappa检验,结果为0.510,为一般一致性。
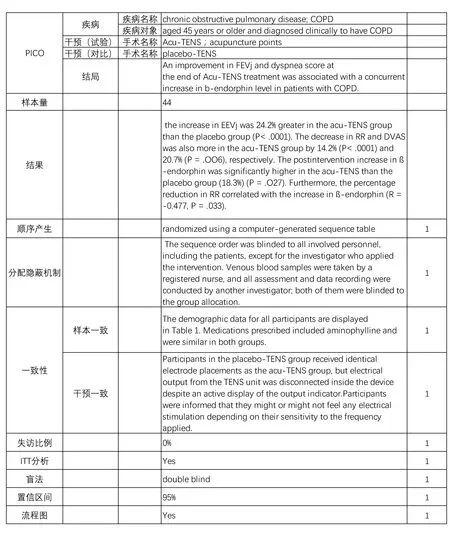
图2著录样例
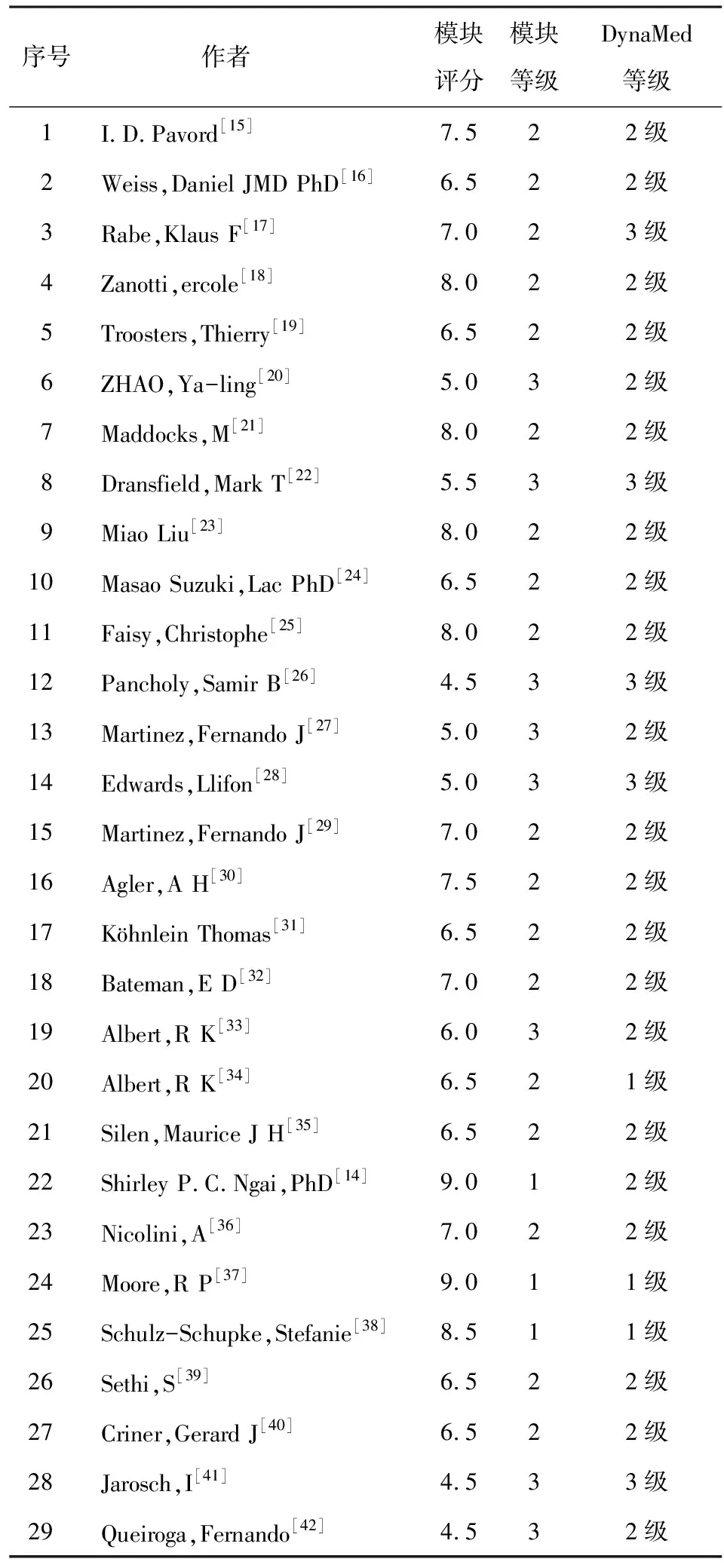
表2 29篇随机对照试验的评分与比较
4 讨论与结论
循证医学数据库信息模型的证据强度模块由疾病名称、疾病对象、手术名称、药物名称、结局、顺序产生、分配隐蔽机制、盲法、样本一致、干预一致、失访比例、ITT分析、置信区间、结果、样本量、流程图等数据元构成。其中对部分与证据评价密切相关的数据元进行满足度评价,如顺序产生、分配隐蔽机制、盲法、样本一致、干预一致、失访比例、ITT分析、置信区间、流程图,并通过DynaMed数据库中的随机对照试验进行验证。由表2可知,该模块中对于证据强度的评判与DynaMed基本一致,这些数据元的满足度能够在一定程度上反映证据质量。在今后的循证医学数据库构建中,可凭借随机对照试验的满足度对文献进行初步证据评价,按满足度由大到小的顺序将最佳证据推荐提供给医务人员,帮助医务人员用最少的时间获取最有价值的证据,支持临床循证的实施。在验证过程中,有少数文献的证据评价与DynaMed不完全一致。笔者分析后发现,有以下原因。首先,本模块评级只针对随机对照试验,而DynaMed的评级包括除随机对照试验在内的其他类型文献,因此在内容及标准上存在一定偏差;其次,DynaMed评价中考虑到样本量因素,多篇评价中提及“small sample size(小样本)”。笔者认为样本量的计算及评价较为复杂,“样本量”这一数据元暂不纳入目前的质量评价而是作为次要排序依据,在满足度相同时进行二次排序。
由于已经过评级的随机对照试验全文较难获取,本文中能够获取到的文章有限,进行验证的样本量不够大。下一步的研究将增加著录和评价的文献数量,并进一步使用更科学的统计学方法对该模块进行验证。在元素提取方面只针对随机对照试验这类文献不够完善,今后可增加系统综述的PRISMA标准与其他严格评价标准,提取与系统综述或Meta分析相对应的数据元,对证据强度模型进行补充和调整,并制定相应的评判标准,以充实和完善循证医学数据库的信息模型及其证据评价标准。
对于循证医学证据的评价需要循证医学实践者通过各种严格评价工具进行综合判断,这一点循证医学数据库本身还不能完全实现。希望本文的证据强度模块能够为整个循证医学数据库的构建打下基础,为医务人员提供高质量的证据。
