基于灰色模糊推理的油料消耗预测
2019-09-25
(陆军勤务学院 油料系,重庆 401331)
0 引言
军用油料(petroleum, oil and lubricants, POL)作为武器装备的重要动力能源,在部队遂行军事行动过程中发挥重要作用。油料消耗预测是组织油料保障的基础环节,科学准确地预测部队油料消耗,对油料保障任务的完成,乃至对部队成功遂行军事行动都有比较重要的意义。
目前,军内外学者的研究主要集中在单一兵种部队消耗油品数量的预测上,通常采用的预测模型和方法包括神经网络预测模型、灰色预测模型、基于时间序列的预测模型、马尔科夫预测法以及将这些模型和方法中的两种或三种进行组合预测的方法[1-2]。相对于单一的预测模型,组合预测模型的预测精度较高。但是由于军事行动的突发性和对抗性,当影响武器装备油料消耗的偶然性和不确定因素增多,油料消耗的历史数据的随机波动也随之增大,呈现出半结构性和非结构性的特征,其规律性越来越弱,上述方法预测的准确度就会出现较大波动,就不再适用了。基于案例推理(case-based reasoning,CBR)适用于因果关系难以把握,且未完全公式化的情况,在通用问题求解、法律案例分析、设备故障诊断、辅助工程设计、辅助计划制定等领域得到广泛应用[3-4]。由于CBR在处理非结构性数据上存在较大优势,后来也被应用到应急物资需求预测领域[5]。灰色关联分析(grey relational analysis,GRA)是衡量系统间各因素之间的关联程度一种方法[6],那么在CBR的案例检索过程中,就可以利用灰色关联模型来计算目标案例与源案例之间的相似度。模糊集(fuzzy sets)在处理不确定信息方面很强的表达能力[7],将模糊集与CBR相结合,在案例检索中处理案例的不精确属性将变得容易。基于此,本文将建立基于灰色关联和模糊集的组合检索模型对军事行动油料消耗预测进行研究。
1 基于加权灰色关联分析的案例检索模型
CBR是一种重要的机器学习方法,它将目前面临的新问题称为目标案例,将过去解决过的问题称为源案例。案例检索是CBR的关键环节,即从案例库中检索出与目标案例相似度最高的源案例。灰色关联是指事物间的不确定关联,灰色关联分析是一种通过灰色关联度来分析和确定系统因素间的影响程度的一种方法。其基本思想是:以因素的数据序列为依据,根据序列曲线几何形状的接近程度来判断因素间的关联程度。因此,在案例检索中就可以利用案例间的灰色关联度来确定案例间的相似度[8]。
本文采用案例的特征属性表示法,将案例的特征属性组成一个集合,即Case={Attribute 1,Attribute 2,…,Attribute n}。设案例库中有n个源案例,每个案例有m条特征属性,目标案例特征属性数值序列XT=(xT(1),xT(2),…,xT(m)),源案例特征属性数值序列:
X1=(x1(1),x1(2),…,x1(m))
X2=(x2(1),x2(2),…,x2(m))
Xi=(xi(1),xi(2),…,xi(m))
Xn=(xn(1),xn(2),…,xn(m))
那么,在案例的第j条特征属性上,目标案例与源案例的灰色关联系数可以表示为:
γ(x0(j),xi(j))=
(1)
其中:ξ∈(0,1)为分辨系数,通常取ξ=0.5。则目标案例与源案例的灰色关联度可以表示为:
(2)

(3)
显然,γ(XT,Xi)满足灰色关联理论的四个公理,即规范性、整体性、偶对对称性和接近性。
文献[9]给出了基于灰熵的灰色关联系数权重确定方法,但是该方法计算过程较为繁琐,且当因素序列中点较多时,求解高阶线性方程组的计算量将会非常大。本文结合案例检索的具体特点给出一种较为简洁的算法。
事实上,目标案例与源案例在特征属性上的灰色关联系数仅与特征属性有关,那么可以认为特征属性的权重即为对应的灰色关联系数的权重。根据信息熵理论,特征属性取值分布差异越大,即该特征属性蕴含的信息熵越高,对案例分类的判定作用越大,该特征属性的权重就越大;反之,则权重越小。
1)归一化特征属性。第j条特征属性的归一化方程为:
j=1,2,…,m
(4)
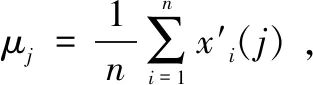
3)确定标准差权重。第j条特征属性的权重,即:
(5)
2 基于模糊集的案例检索模型
最近相邻法是比较常用的一种案例检索方法,是一种基于距离的度量方法。在将特征属性数值化后,并确定特征属性权重,即可求出目标案例与案例库中源案例特征属性之间的距离。根据距离的大小来确定案例间的相似度,即距离越小,相似度越大。但是在实际应用中,特征属性的类型各异,存在部分不精确和数值化较为困难的属性[10]。因此,单独使用最近相邻法进行案例检索,其准确度将无法得到保证[11]。本文将模糊集理论和最近相邻法结合起来,对案例进行模糊化描述,用模糊集间的贴进度来表示案例间的相似度,构建案例检索模型。
2.1 案例的模糊化描述
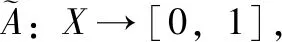
(6)
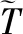
(7)
2.2 模糊集间的贴近度
计算目标案例与源案例之间的贴近度,用贴近度表示案例间的相似度,实现目标案例与源案例的模糊匹配。
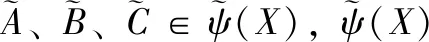


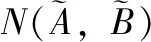
(8)
若X为有限集合X{x1,x2,…,xl}时,那么:
(9)
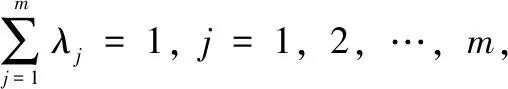
(10)
2.3 特征属性的权重。
本文引入改进的层次分析法(analytic hierarchy process,AHP)方法,其具体步骤如下:
1)通过专家打分法得到特征属性权重的判断矩阵;

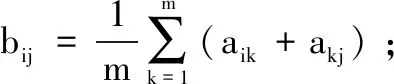
3)将最优传递矩阵B转换为一致性矩阵C,其元素cij=ebij;
4)计算出一致性矩阵C的特征值,最大特征值所对应的特征向量即为特征属性的权值向量。
2.4 案例间的相似度
i=1,2,…,n,j=1,2,…,m
(11)
3 组合检索模型和油料消耗预测模型
加权灰色关联分析检索模型完全以影响案例灰色关联度的客观因素为基础,而模糊案例检索模型在客观数据的基础上,引入了相当部分的主观因素,即专家知识和经验。军事行动油料消耗受到较多不确定因素的影响,因此专家知识和经验在油料消耗预测中发挥着一定因素。所以,单纯以客观因素确定灰色关联度,难免会有所偏差;相反,引入过多的主观因素,相似度的准确度也会出现较大波动。本文尝试将两种模型进行组合,充分利用两者的优点,弱化两者的缺点,即将加权灰色关联度和相似度进行赋权组合,得到一个新的表征参数,即组合相似度。设组合相似度序列为SCOM。
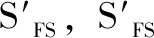

i=1,2,...,n
(12)
令最优序列SMAX的元素:
(13)
式(13)表示取加权灰色关联度和相似度中的较大值作为SMAX的元素。
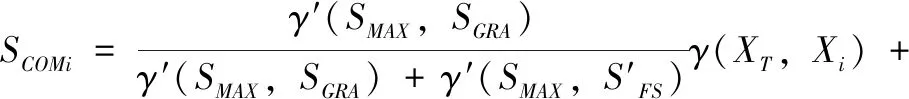
i=1,2,…,n
(14)

综合基于加权灰色关联分析的检索模型、基于模糊集的检索模型和组合检索模型的检索结果,可以确定与目标案例相似度最高的源案例,进而求出目标案例的油料消耗。设最佳相似案例的油料消耗量为φh,关键特征属性值为Rh,目标案例的关键特征属性值为RT,那么根据相似性原理,目标案例的油料消耗量为:
(15)
基于加权灰色关联分析和模糊案例推理组合检索的油料消耗预测方法的基本流程图如图1所示。其中,最优相似案例即为与目标案例相似度最高的源案例。

图1 油料消耗预测流程图
4 算例仿真
军事行动油料消耗案例的特征属性由影响油料消耗的各项因素构成,如表1所示。其中,行动样式为无序枚举型属性值,地理环境和用油装备使用强度为有序枚举型属性值,持续时间、基数量、油料战损率以及油料自然损耗率为数字型属性值。
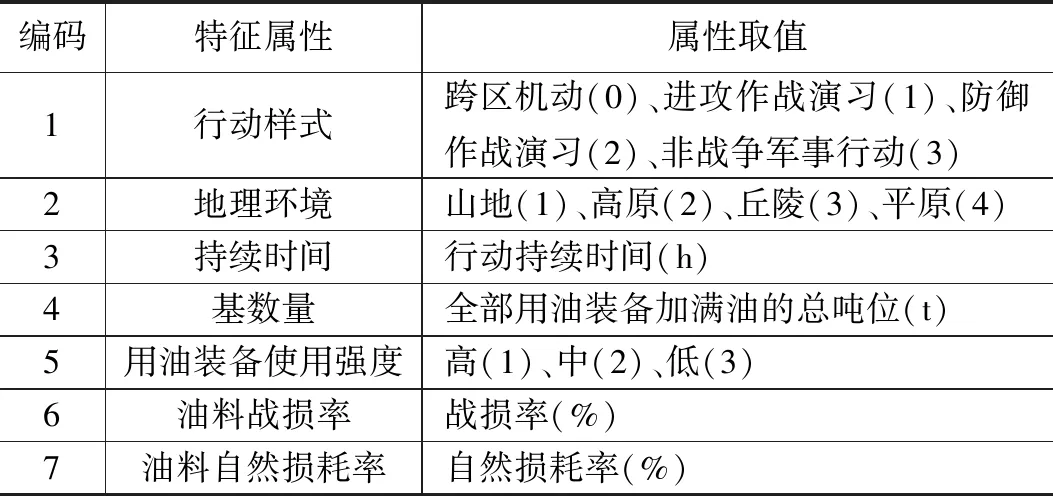
表1 军事行动油料消耗案例特征属性


表2 案例的特征属性值
具有丰富的旅级部队油料保障经验的专业技术人员和指挥决策人员,对案例的特征属性进行处理,并且构造合适的隶属度函数,得到目标案例和源案例特征属性的模糊矩阵,如表3所示。这是求解相似度序列的基础。
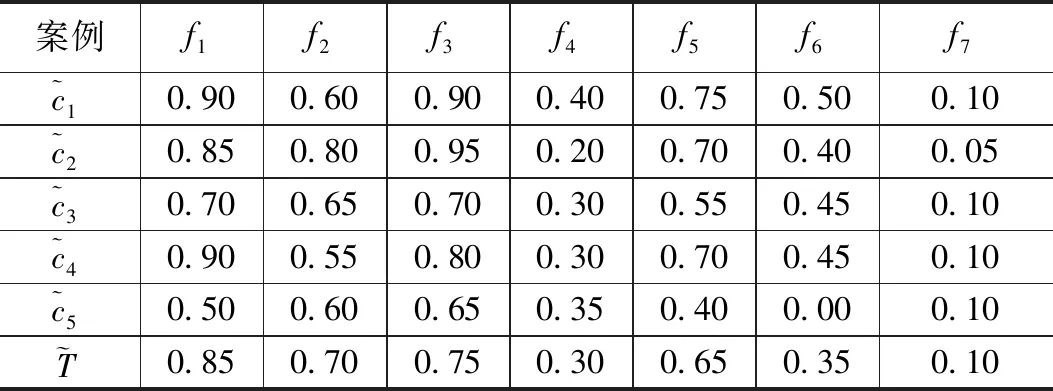
表3 特征属性对案例的隶属度
4.1 案例组合检索
(1)求解加权灰色关联度序列。对于无序枚举型特征属性,在计算灰色关联系数时,属性值相同时,灰色关联系数为1:不同时,系数为0。对于有序枚举型特征属性,按照处理数字型特征属性的方式进行处理,按照上文给出的方法求解灰色关联系数。依据式(1)、(3)、(5)以及表2,可得灰色关联度序列:
SGRA=(0.6598, 0.6312, 0.7545, 0.8593, 0.3595)。
(2)求解相似度序列。依据改进的AHP、式(11)以及表3,可得相似度序列:
SFS=(0.8341,0.8471,0.8588,0.9048,0.6942)。
(3)求解组合相似度序列。依据式(12)、(13)、(14)以及加权灰色关联度序列和相似度序列的结果,可得归一化后的相似度序列和组合相似度分别为:
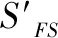
SCOM=(0.6770,0.6806,0.7521,0.8593,0.3595)。

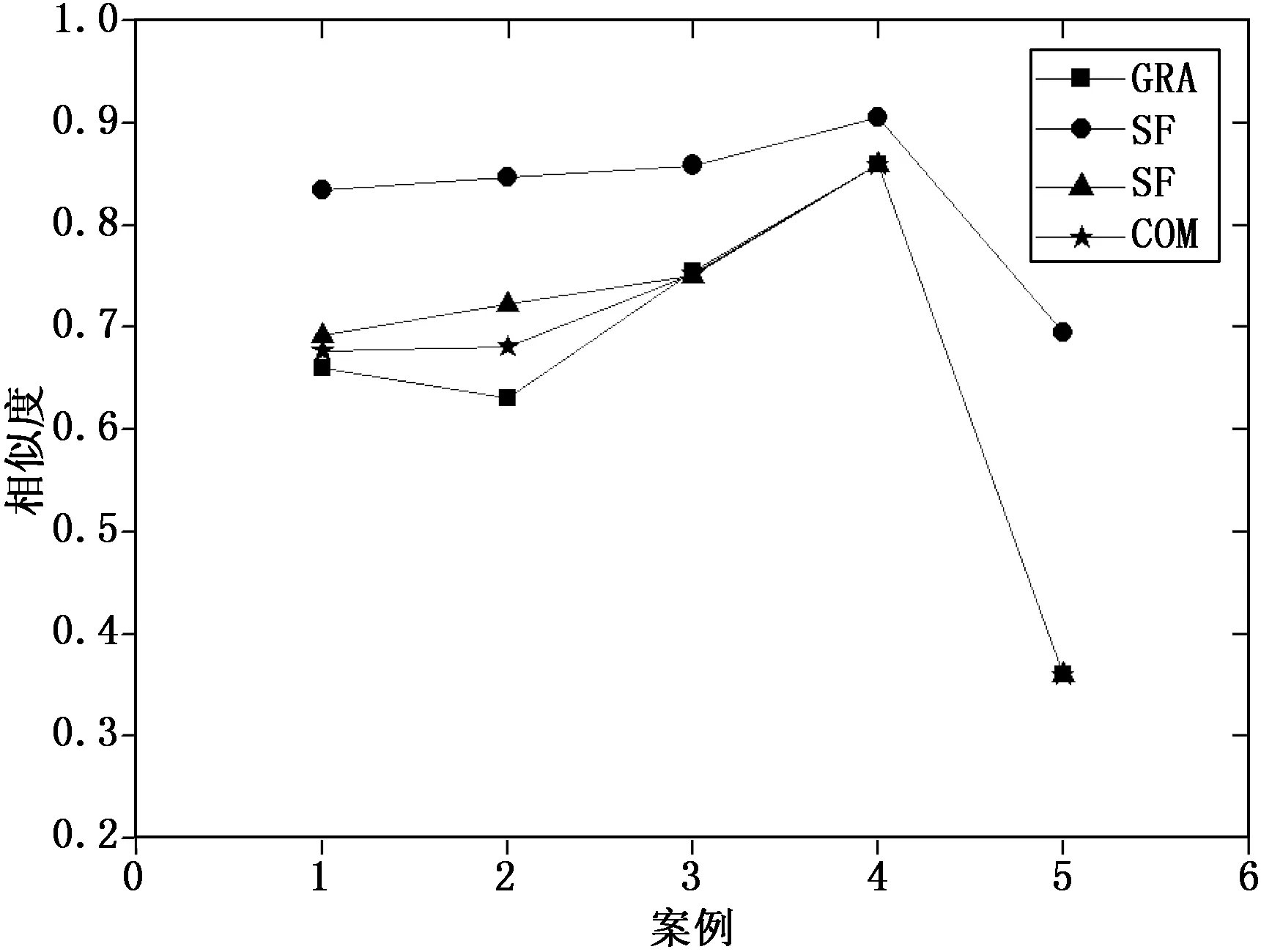
图2 案例检索结果对比
4.2 油料消耗量预测
上文求得案例4与目标案例的相似度最高,选取基数量作为军事行动油料消耗的关键特征属性,由表2可得,案例4的油料消耗量φ4=340.02 t,基数量R4=152 t,目标案例的基数量RT=158 t,那么,依据式(15)可得目标案例的油料消耗量
φT=353.44t。
这里预测的是军事用油装备主油的总消耗量,如果需要预测主油中各油品以及附油的消耗量,依据此法也可求得。
4.3 预测结果的对比
为了方便对比,将神经网络、灰色理论、时间序列、灰色神经网络、时间序列和灰色理论等预测方法与本文预测方法的准确率,共同列于表4中。
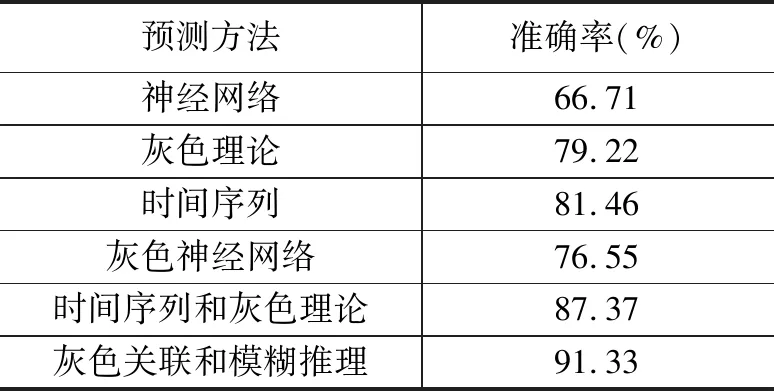
表4 预测准确率的对比
通过对比和分析,可以得出结论:基于灰色关联和模糊推理的预测方法准确率要更高;在传统预测算法中,组合预测算法准确率比单一算法要高;传统预测算法准确率的波动性较大。这主要是由于算例中的历史数据偏少,数据的结构性特征减弱,随机性增强,有些算法如果能够获得数据的结构性特征,就表现出较高的准确率;反之,准确率就很低。
5 结论
灰色关联分析和模糊集理论在处理受不确定因素影响的问题上都存在着一定的优势。基于加权灰色关联分析的案例检索模型,在客观数据的基础上,以案例间的加权灰色关联度为依据进行案例检索。基于模糊集的案例检索模型,在客观数据以及专家知识和经验的基础上,以案例间的模糊相似度为依据进行案例检索。为了充分利用上述2种检索模型的优点,依据上述2种检索模型的检索结果,运用灰色关联分析等方法,构建了组合检索模型。综合3种检索结果,得到与目标案例相似度最高的源案例,再运用油料消耗预测模型,最终得到目标案例的油料消耗量。上述预测方法,充分利用客观数据以及专家知识和经验,3个检索结果相互印证,提高了案例检索的精度,保证了油料消耗预测结果的准确度。专家知识和经验等主观因素引入对提高检索结果的可靠性有一定帮助,但如何控制主观因素的准确度,以及客观因素与主观因素的比例是今后值得研究的问题。
