基于词语相似度的语义选择限制知识获取
2019-09-23贾玉祥赵倩倩李育光昝红英
贾玉祥, 赵倩倩, 李育光, 郑 一, 昝红英
(郑州大学 信息工程学院 河南 郑州 450001)
0 引言
谓语动词对其论元有选择倾向性,称为语义选择限制(selectional preference, SP).比如,“吃”这个动词的主语倾向于选择表示“人或动物”的名词,宾语倾向于选择表示“食物”的名词.可以用函数spr(v,n)表示语义选择倾向,v表示谓语动词,r表示论元类型,n表示论元,sp值为实数,值越大,表示n越适合充当v的论元r.比如,“香蕉”比“石头”更适合充当“吃”的“宾语”.语义选择限制知识获取就是学习函数spr(v,n),实现对任意(v,r,n)的打分.
语义选择限制是重要的词汇语义知识,除了可以用来判断句子的合法性之外,还具有数据平滑和消歧作用,因此被用于自然语言处理的多种任务,包括句法分析[1]、语义角色标注[2]、词义消歧[3-4]、机器翻译[5]、隐喻计算[6]等.语义选择限制是很多词汇知识库的重要组成部分,比如英语的VerbNet[7]、现代汉语语义词典SKCC[8]等.然而,手工构建的语义选择限制知识库很难满足自然语言处理的需求,需要从大规模语料中自动获取语义选择限制知识.
从语料库中自动获取语义选择限制知识,一般需要先对语料进行句法分析,然后抽取句法搭配(v,r,n),形成训练集.对于训练集中出现过的搭配,可以简单地用共现次数count(v,r,n)或条件概率p(n|v,r)来表示spr(v,n).关键是对训练集中没有出现过的搭配(v,r,n0)如何计算spr(v,n0),即如何根据v的已知论元计算未知论元的sp值,称之为论元扩展.
本文采用基于词语相似度的论元扩展方法,引入词向量进行词语相似度计算,词向量只需要在经过分词的语料上进行训练,不需要对语料进行句法分析.
1 相关研究
论元扩展可以借助名词语义分类体系来实现,比如英语的WordNet[9]与汉语的HowNet[10].先基于已知论元计算谓语动词对论元语义类的sp值,对于未知论元,只要它出现在某一个语义类中,就可以将该语义类的sp值赋予该论元.对于语义类sp值的计算,Resnik[11]使用一个基于KL距离(Kullback-Leibler divergence)的统计指标,Li[12]则基于最小描述长度(minimum description length, MDL)模型来进行.
论元扩展也可以基于词语在语料库中的分布来实现.基于隐含狄利克雷分配(latent dirichlet allocation, LDA)的模型[13]把自动学习的隐含主题作为语义类实现对未知论元sp值的计算.神经网络模型[14]将输入的v与n的词向量转化为sp值输出.向量空间模型[15]根据词语在语料库中的分布特征把词语表示成特征空间中的向量,通过向量运算得到未知论元与已知论元之间的相似度从而实现对未知论元sp值的计算.这里的向量还是传统意义上的稀疏向量,并非词向量(word embedding).
在词语相似度计算方面,词向量表示已被证明比传统向量表示效果更好[16].基于词汇知识库的方法也是词语相似度计算的常用方法,该方法利用词汇知识的语义网络表示或树结构来计算词语相似度[17].汉语构词及汉字的部首信息也可以用于汉语词语相似度计算[18].多种方法的融合会进一步提升词语相似度计算的效果[19].
汉语语义选择限制知识自动获取方面,贾玉祥等[20-22]实现了基于KL距离、MDL、LDA及神经网络的模型.本文考察基于词语相似度的语义选择限制知识自动获取,并引入词向量和词汇知识库进行词语相似度的计算.以往语义选择限制知识获取都需要对语料库进行句法分析,抽取句法搭配,以此为基础进行sp值的计算,本文方法中句法分析则不是必需的.
2 本文方法
2.1 基于词语相似度的SP获取方法
把SP知识获取分成两个步骤:第一步获取种子论元Seeds;第二步利用未知论元与种子论元之间的词语相似度进行论元的扩展并计算选择倾向sp.谓词v对一个论元n0的选择倾向sp定义为该论元n0与所有种子论元n的相似度的加权组合[14],如
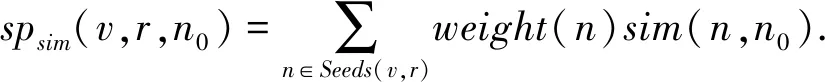
(1)
权值weight(n)可以用来区分不同种子论元的重要性,为简单起见,本文将权值统一设置为1.种子论元可以来源于搭配词典、标注语料,可以由人工直接给出,也可以从语料中自动抽取.本文将比较人工直接给出的种子论元与自动抽取的种子论元在SP获取中的效果.
词语相似度计算将比较基于词向量的方法与基于词典的方法.词向量是将词语表示为一个低维的稠密向量,以更好地表示词语的含义,并能缓解数据稀疏问题.使用两个词语的词向量的夹角余弦表示词语之间的相似度.词向量的训练采用Skip-gram模型及负采样方法[16].基于词典的词语相似度计算采用基于同义词词林的方法[17],词典使用同义词词林扩展版.
2.2 知识获取的评价方法
语义选择限制获取模型对谓词论元搭配进行打分,合理的搭配得分要高于不合理的搭配.伪消歧(pseudo-disambiguation)方法就是利用这种思想对选择限制获取模型进行评价.首先获取一些合理的搭配,视之为正例.对于每一个正例(v,n),以一定策略构造一个反例(v,n′),反例搭配的合理性要低于正例.如果模型打分spr(v,n)>spr(v,n′),则判断正确,记为win;spr(v,n)=spr(v,n′),记为tie;否则,判断错误.模型正确率acc的计算为
acc=(#win+#tie*0.5)/(#allsamples).
(2)
我们采用3种选择策略构造反例,得到3个测试集:名词按词频降序排列,选择直接前驱词作为反例,记作pre;名词按词频降序排列,选择直接后继词作为反例,记作post;随机选择,记作rand.对构造的测试集进行人工过滤,确保每一对样本中正例搭配的合理性高于反例.
3 实验与分析
本文实验以动宾关系为例,首先描述相关数据及实验设置,然后对实验结果进行分析,比较了两种相似度计算方法在SP获取任务中的表现,并考察了种子论元的获取对SP获取结果的影响.
3.1 数据与实验设置
使用ZPar[23]对60年(1946—2005)人民日报语料进行句法分析,抽取动宾搭配,构造动宾搭配集.对动宾搭配集中出现次数在50次以上的动词,对其宾语按照搭配频次降序排列,选择topN作为动词宾语的种子论元,考察了N为1、5、10、15、20、25的情况.
使用ICTCLAS[24]对60年人民日报语料进行分词处理,使用word2vec[16]训练词向量,词向量维度设为200,上下文窗口设为2.基于同义词词林的相似度计算方法参数采用缺省设置[17].使用NLPCC-ICCPOL2016中文词语相似度评测数据对两种相似度计算方法进行测试.结果显示,基于同义词词林的方法Spearman值为0.42,基于词向量的方法Spearman值为0.38,分别超过了24个提交系统中的第5名和第9名.
从1998年1月的人民日报语料中抽取动宾搭配作为正例,使用3种策略生成反例,正反例样本中动词和名词均为双音节词.对于正反例样本,由3位标注者进行确认,确保每一对样本中正例名词与动词搭配的合理性要高于反例名词.3位标注者标注结果一致的样本予以保留,最终得到3种反例生成策略下的测试样本个数分别为:pre/887个,post/820个,rand/865个.表1给出3个测试样本的例子,verb是动词,pos是正例名词,pre、post、rand为3种策略下的反例名词,可见正例的合理性均要高于反例.
3.2 两种相似度计算方法的实验比较
图1给出基于两种相似度计算方法(词向量emb、同义词词林cilin)的SP获取模型在3个数据集(pre、post、rand)上一共6种实验方案下的伪消歧实验正确率.可见,基于词向量计算词语相似度的结果要全面优于基于同义词词林计算词语相似度的结果.当只有一个种子论元时,词向量方法的正确率达到80%左右,同义词词林方法的正确率超过65%.随着种子论元个数增加,正确率逐渐提升.同义词词林方法在种子论元个数为5时正确率达到最高,超过75%.种子论元个数大于10时,词向量方法正确率均超过90%.种子论元超出一定数量后,正确率会下降.当种子个数为20时,基于词向量的方法在3个测试集上的结果均优于基于神经网络maxout[22]的方法.

表1 测试样本举例Tab.1 Examples of test data

图1 伪消歧实验结果Fig.1 Results of the pseudo-disambiguation experiment
从这里可以看出,面向任务的词语相似度计算的评价与单纯的词语相似度计算的评价是有一定区别的.在词语相似度测试集上,基于同义词词林的方法Spearman相关系数高于基于词向量的方法,但是选择限制获取中伪消歧实验的效果基于词向量的方法要显著好于基于同义词词林的方法.
以动词“把握”为例,SP获取的情况见表2.给定种子论元,个数分别为1和5,计算“把握”与(同义词词林中的)所有名词的选择倾向值sp,对名词按sp值从大到小排序.可见,基于词向量的方法得到的名词列表优于基于同义词词林方法得到的名词列表,后者前10个名词中存在不正确的搭配(斜体词语),如福音、手下、手头等,并且种子词也没有排在前列.
需要指出的是,直接从动宾结构中获取论元也是一种可行的方法,但是该方法一方面需要对语料进行句法分析,另一方面语料的规模总是有限的,对于没有出现在所抽取的动宾结构中的名词,是无法给出选择倾向性的.因此,论元扩展是必要的.
我们将基于词向量方法的结果与基于同义词词林方法的结果进行一致性分析,得到表3所示的一致性矩阵.可见,对于基于词向量方法判断错误(emb#lose)的部分样本(个数分别为33/34/42,表中黑体),基于同义词词林的方法做出了正确的判断(cilin#win),即两种方法有一定互补性,可以将两种方法结合起来,进一步提升SP知识获取效果.

表2 动词“把握”宾语论元获取情况Tab.2 Acquired object candidates for the verb “grasp”

表3 基于词向量方法与基于同义词词林方法的结果一致性矩阵Tab.3 Consistency matrix between the word embedding based model and cilin based model

图2 不同种子来源的对比实验(种子个数为5)Fig.2 Comparison between different seed sources (seed number: 5)
3.3 种子论元对SP获取结果的影响
种子论元的获取有不同的方式,3.2节给出的是自动获取种子论元的实验结果.本节对自动获取种子论元与人工给出种子论元两种方式进行实验比较.人工给出种子论元的方式是:提供给标注者一个动词列表,标注者为每一个动词提供一组适合做其宾语的名词,可以借助搭配词典等资源.图2是种子个数为5时,6种实验方案(1:pre-emb、2:post-emb、3:rand-emb、4:pre-cilin、5:post-cilin、6:rand-cilin)下,不同种子论元获取方式的实验结果,其中,auto是自动获取种子论元的结果,anno1是标注者1给出种子的实验结果,anno2是标注者2给出种子的实验结果.可见,自动获取种子的结果优于人工给出种子的结果.自动获取种子的方式既节省了人力,效果又更好,因此是可行的.
仍然以动词“把握”为例,自动获取的种子和人工给出的5个种子分别如下:
auto:规律 方向 机遇 趋势 导向;anno1:机遇 机会 命运 要求 特征;anno2:机会 时机 本质 方向盘 机遇
可见,自动获取的种子和人工给出的种子有一定的重合度.“把握”是一个多义词,目前以隐喻义为主,自动获取的种子全部对应于隐喻义,而人的观念里还是有本义存在,会给出本义对应的种子,如“方向盘”.伪消歧实验里没有区分动词义项,在构建语义选择限制知识库时则需要以动词义项为单位.
当然,自动获取的种子会由于句法分析的错误而存在问题,这也是下一步可以需要的地方.例如,以下动词的论元种子中,粗斜体的词就存在搭配错误.这些错误的一个主要原因是“动词+名词”结构歧义,比如,负责+同志、负责+干部、负责+领导均是偏正关系,不是动宾关系.
负责同志工作 事务干部 领导
导致 后果 战争原因结果 危机
防止建议战争 事故 现象 倾向
4 总结与展望
本文考察了基于词语相似度的语义选择限制知识自动获取方法,把知识获取过程分成两个步骤:种子论元的获取及论元扩展.基于词语相似度的论元扩展与基于词向量的词语相似度计算方法和基于同义词词林的词语相似度计算方法相比较. 实验表明,前者的效果显著优于后者,且二者有一定互补性,可以结合起来进一步提升知识获取效果.在种子论元获取方面,自动获取的种子论元效果优于人工给出的种子论元.伪消歧实验显示,本文方法的正确率超过了目前最好的神经网络方法.
我们将从以下方面对本文工作进行改进:1) 本文种子论元的获取、词向量训练语料及测试集均来自于人民日报语料,测试结果有一定的领域局限性,下一步将构建一个新的测试集,考察模型的领域迁移效果.2) 将不同的词语相似度计算方法融合起来,进一步改进语义选择限制知识获取的效果.3) 设计合理的实验,对语义选择限制知识获取的不同方法进行对比分析,以选择最优的方法.
