用于敏感属性保护的(θ,k)-匿名模型
2019-09-23程楠楠刘树波熊星星蔡朝晖张家浩
程楠楠, 刘树波, 熊星星, 蔡朝晖, 张家浩
(武汉大学 计算机学院 湖北 武汉 430072)
0 引言
信息化的快速发展加速了数据表在网络上的发布,为信息共享带来极大便利.但各类数据表中可能包含大量涉及用户隐私的敏感信息,如身体疾病信息、生活轨迹信息等.因此,需要在数据表发布前对表中信息加以处理,以避免发布过程中的信息泄露.1999年,匿名概念首次被提出[1].随后,有学者提出k-匿名模型[2],模型要求等价类中的k条记录匿名化处理后不可区分,从而实现用户的隐私保护.但该模型在划分等价类时没有对记录的敏感属性做出约束,数据表易遭受攻击.针对k-匿名模型的不足,文献[3]提出l-diversity模型,要求等价类中至少含有l个不同的敏感属性值;文献[4]提出t-closeness模型,要求等价类中敏感属性值分布与原始数据表的分布规律相似;文献[5]和文献[6]分别提出(a,k)-匿名模型与(p,k)-匿名模型,以上模型在抵制某种特定攻击时效果良好,但在同时抵制背景知识攻击[7]与相似性攻击[8]方面效果不佳.为了给用户隐私提供更有效的保护,达到同时抵制背景知识攻击与相似性攻击的目的,本文提出一种分组的(θ,k)-匿名隐私保护模型,模型依据敏感属性值间存在的语义关系将等价类分组,使组内记录的敏感属性值保持较高的相似性,组间记录的敏感属性值保持较高的相异性.同时,本文考虑数据可用性问题,采用距离度量方法减少信息损失,提高了数据可用性,并通过实验证明了(θ,k)-匿名模型的有效性.
1 相关概念及技术
1.1 基本概念
待发布的原始数据表通常包括标识符、准标识符、敏感属性三种属性信息[9],发布前需要对数据表进行处理.
定义1等价类:对于一个数据表T(A1,A2,…,An),n代表数据表中的属性个数,等价类为数据表T中具有相同准标识符投影的记录集合,这些记录通过准标识符不可区分[10-12].
定义2k-匿名模型:等价类中至少包含k条在准标识符上不可区分的记录.
定义3(p,k)-匿名模型:数据表T在满足k-匿名模型的前提下,每个等价类中至少含有p个不同的敏感属性值.
例如,表1为原始数据表,经过(p,k)-匿名泛化后得到表2的匿名数据表(p=6,k=6).若攻击者已知被攻击者属于表2的等价类,由于该等价类中胃部疾病比例高达50%,因此攻击者可认为患者大概率患有胃部疾病,这种攻击称之为相似性攻击.若攻击者根据背景知识得知被攻击者患有骨科疾病,但不能明确具体的疾病值,根据表2中记录,由于只有骨折为骨科疾病,因此攻击者可推测出患者所患疾病为骨折,这种攻击称之为背景知识攻击.划分等价类时若记录敏感属性值语义相似的个数较多,等价类易受相似性攻击;若语义相似的个数较少,等价类易受背景知识攻击.对记录敏感属性值约束不足,导致数据表泛化后同时抵制两种攻击的性能不佳.本文提出(θ,k)-匿名保护模型,旨在通过分组优化模型的抗攻击性能.

表1 原始数据表Tab.1 A raw data table
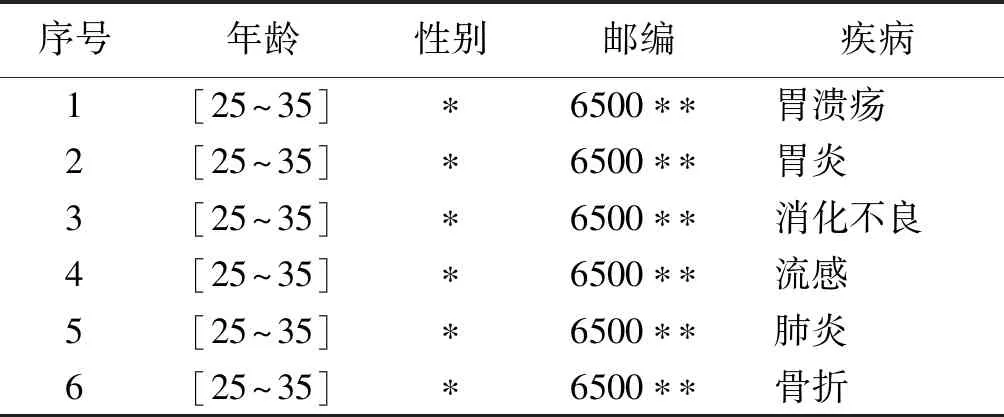
表2 (p,k)-匿名数据表Tab.2 A (p,k)-anonymous data table
定义4语义层次树[13]:对数据表中的属性值进行语义分析得到语义层次树,树中根节点为属性值全集,父节点为其叶子节点的泛化,叶子节点为父节点的子类.
图1为简化后的疾病语义层次树.根节点是疾病全集,父节点是其子节点疾病值不同程度的泛化,叶子节点代表具体的疾病值.属性的相似或相异度可通过层次树中叶子节点到其最小公共父节点的距离进行度量.图1中胃炎与胃溃疡到最小父节点胃部疾病的距离相等且均为1,属于相同类型疾病,相似程度较高;胃炎与流感的最小父节点是根节点,两者到公共父节点的距离均为3,属于不同类型疾病,相异程度较高.
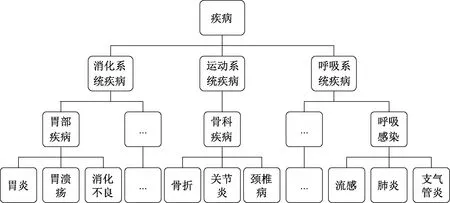
图1 疾病语义层次树Fig.1 Disease semantic hierarchy tree
定义5(θ,k)-匿名模型:将等价类中k条记录分为θ组,使同组记录的敏感属性值具有较高的相似性以抵制背景知识攻击,不同组记录的敏感属性值具有较高的相异性以抵制相似性攻击,以此避免等价类中记录敏感属性相异程度过高或相似程度过高的情况,达到同时抵制背景知识与相似性双重攻击的目的.
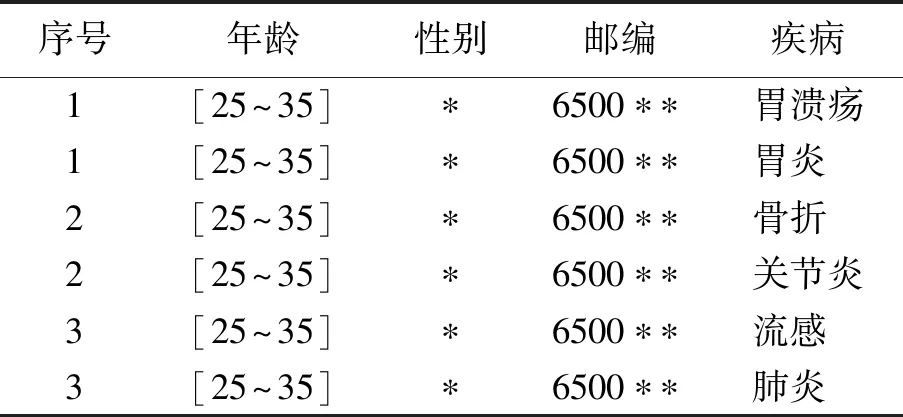
表3 (θ,k)-匿名数据表Tab.3 A (θ,k)-anonymous data table
表3是一个经(θ,k)-匿名方法处理得到的数据表(θ=3,k=6).表中等价类分为三组,序号表示记录组号.三组记录之间敏感属性所属疾病类型相异,可达到抵制相似性攻击的目的;每组包含两条敏感属性值相似的记录,可达到抵制背景知识攻击的目的.数据表抗攻击性能得到改善,用户隐私得到更有效的保护.
1.2 距离度量与信息损失计算
k-匿名通常将等价类中记录的准标识符泛化,以达到保护用户隐私的目的.进行泛化必然导致数据信息损失,因此在保护用户隐私的前提下减少信息损失是本文的关注点之一.在满足(θ,k)-匿名模型的前提下,若划分到同一等价类中记录的准标识符具有较高的相似性,可有效减少泛化时的信息损失.本文采用距离度量方法衡量记录准标识符之间的相似性[14-15].
准标识符通常包含数值型属性与分类型属性两类,不同类型需采用不同的距离度量公式.数值型属性之间存在序关系,相对容易计算;部分分类型属性的度量方式为:若两条记录的某一属性值相同,则该属性距离记为0,否则记为1.该度量方式没有考虑分类型属性的语义关系,泛化时易造成较高的信息损失.本文对分类型属性进行语义分析,得到属性的语义层次树,并根据属性值在语义层次树中的距离定义记录之间的距离.
数据表T的准标识符集合为QI={N1,N2,…,Nm,C1,C2,…,Cn},其中Ni(i=1,2,…,m)为数值型属性,Cj(j=1,2,…,n)为分类型属性.
定义6数值型属性距离度量:若某一属性的值域为有限域D,|D|表示D中最大值与最小值的差值,则两个属性值vi、vj之间的标准距离定义为δN(vi,vj)=|vi-vj|/|D|.
定义7分类型属性距离度量:设TD为某一属性值域D上的语义层次树,H(TD)代表层次树的高度,∧(vi,vj)代表两个属性值vi、vj在层次树上的最小公共父节点,则vi、vj之间的标准距离定义为
δC(vi,vj)=H(∧(vi,vj))/H(TD).
定义8记录距离度量: 结合数值型与分类型属性的距离度量公式,两条记录r1、r2之间的距离为
式中:ri[A]表示第i条记录在属性A上的值.
定义9信息损失:设e={r1,r2,…,rk}是使用(θ,k)-匿名泛化后的一个等价类,泛化处理的信息损失为

2 (θ,k)-匿名模型
现有k-匿名模型及其改进模型在等价类划分过程中对敏感属性约束不足,导致模型同时抵制背景知识攻击与相似性攻击的性能不佳.本文提出(θ,k)-匿名模型,在数据表发布前对表中敏感属性进行语义分析得到敏感属性语义层次树,划分等价类时依据层次树对等价类分组,使分组后的等价类满足记录在组内保持敏感属性值相似,在组间保持敏感属性值相异,达到降低敏感信息泄露概率和保护用户隐私的目的.为提高数据可用性,减少不必要的信息损失,本文在划分等价类时采用距离度量方法,使同一等价类中记录的准标识符具有较小的距离,以减少因泛化带来的数据信息损失.
2.1 (θ,k)-匿名模型算法的思想
(θ,k)-匿名模型算法的基本思想:① 对需要保护的敏感属性进行语义分析并构建相应的语义层次树,利用哈希技术将记录根据敏感属性值在语义层次树中所属类别分成若干个hash桶,同一hash桶中记录的敏感属性类别相同.同时,根据桶中记录个数多少对hash桶降序排列. ② 定义组数θ,将包含k条记录的等价类分为θ个组,每组应包含k/θ条记录,由于记录数应为整数,故对结果值向下取整为⎣k/θ」.从降序序列的前θ个桶中分别选取⎣k/θ」条敏感属性互不相同且具有最小距离的记录组成一个等价类.从θ个桶中选取记录并确保记录属于不同类别,以保证记录的组间相异性;每个桶中取⎣k/θ」条敏感属性不同的记录以保证组内相似性;规定所选记录满足最小距离,目的在于减少泛化带来的信息损失. ③ 重复上述过程,直至无法创建新的满足(θ,k)-匿名模型的等价类,并将剩余记录插入到与它距离最近的等价类中. ④ 泛化满足(θ,k)-匿名模型的等价类,产生可用的匿名表.
2.2 (θ,k)-匿名模型算法的实现
算法: (θ,k)-匿名模型算法.
输入:原始数据表T,hash桶个数m,等价类k值,组数θ;输出:匿名数据表T′,T′中等价类满足组内敏感属性相似,组间敏感属性相异.
(1) 通过语义分析,确定敏感属性有m个不同的类别,将数据表T依据语义层次树划分到m个hash桶中,每个hash桶代表不同的类别;
(2)E={ },j=1;whilem≥θ{
(3) 根据hash桶中包含记录个数将hash桶降序排列;
(4) 选取降序序列中前θ个hash桶构成集合H={h1,h2,…,hθ};
(5) 从h1中随机选择一条记录r;ej={r};h1=h1-r;
(6) 从h1中选出距离r最近的一条记录,并与ej中记录比较,若属性值不同,则将本条记录加入到ej,并将其从h1中删除,若相同则不做任何处理;重复此过程,直至从h1中选出⎣k/θ」条记录;
(7) 在桶h2~hθ中重复(6),依次从每个桶中取⎣k/θ」条记录加入ej,并将记录从原hash桶中删除;
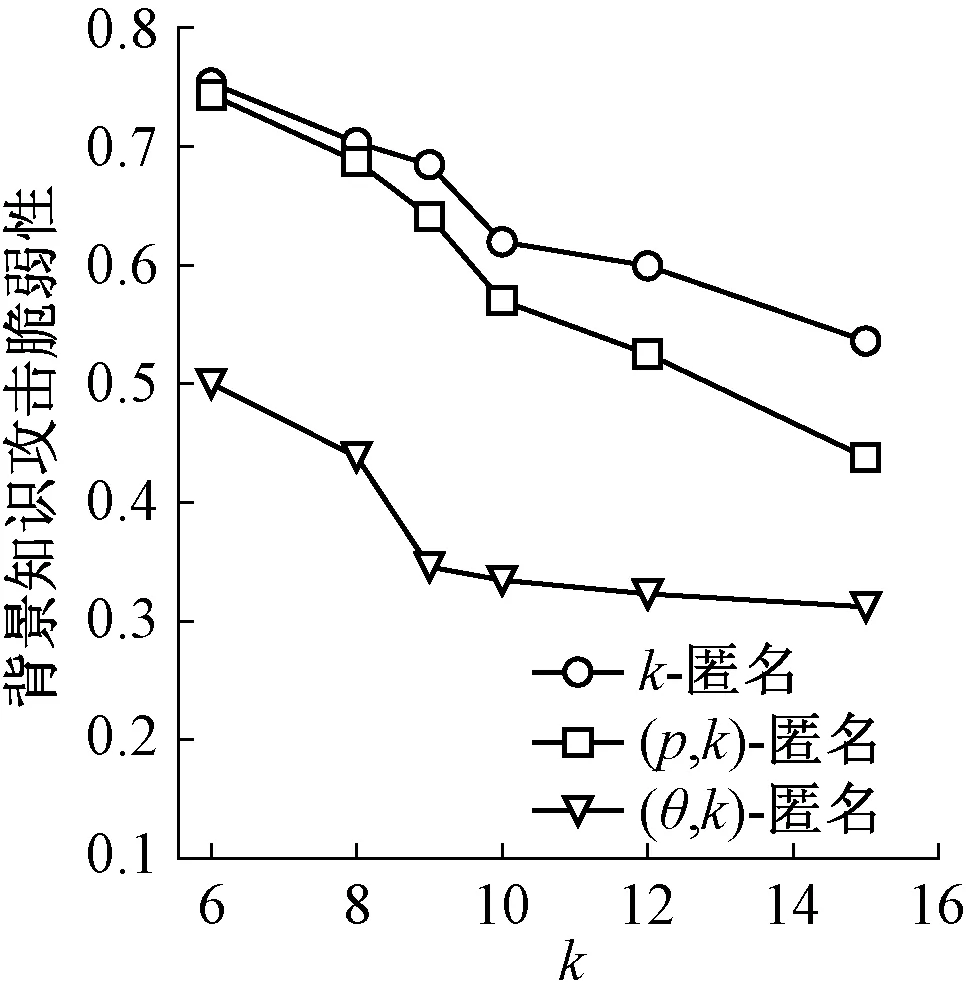
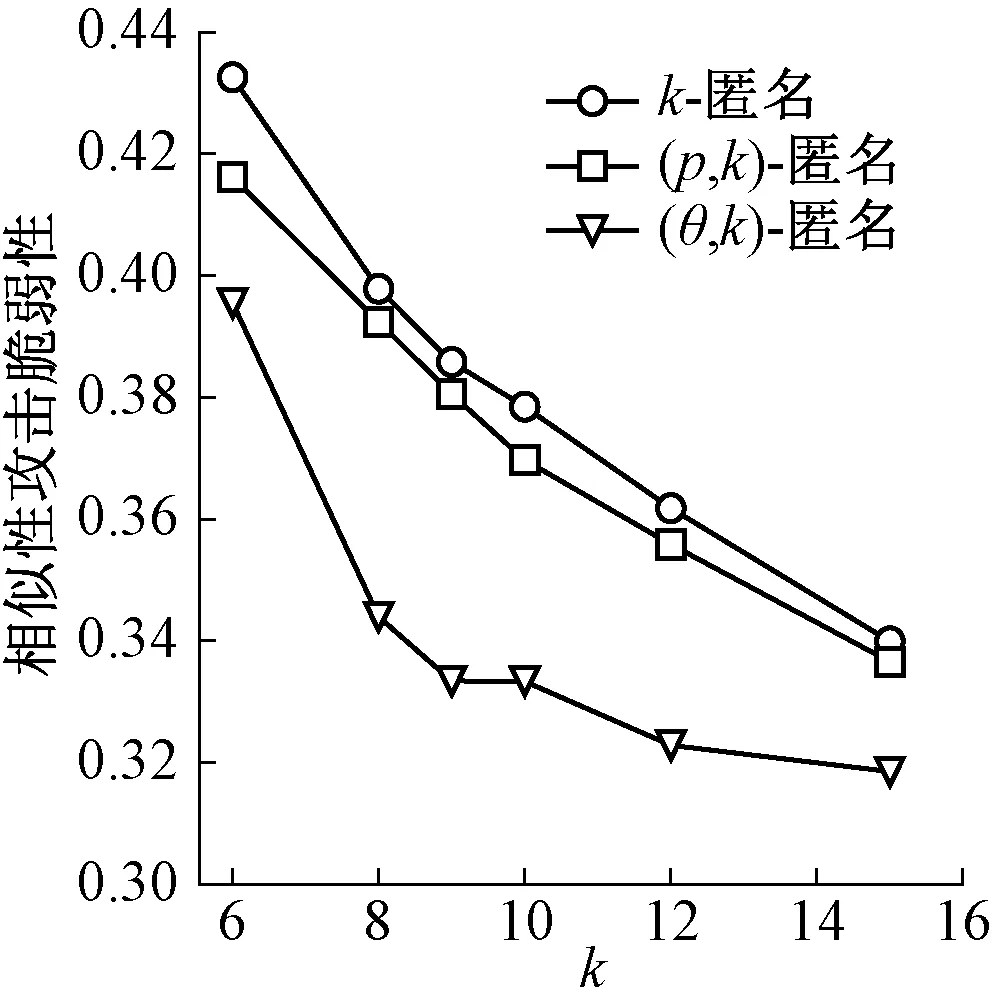
(8) 若θ*⎣k/θ」 (9)E=E∪ej (10)j++ } end while (11) 将hi中剩余记录插入到距离它最近的等价类中; (12) 对等价类集合E中的每个等价类ej进行泛化,得到匿名数据表T′. (θ,k)-匿名模型作用于具有敏感属性的待发布数据表,目的是保护敏感数据,避免用户隐私泄露.发布前,需要将数据表划分为若干个等价类,以避免数据表发布后可能遭受的背景知识攻击与相似性攻击.当前的匿名模型存在等价类中敏感属性值相似的记录分布不均现象,若敏感属性值相似的记录过多,则数据表难以抵制相似性攻击;若记录过少,则数据表难以抵制背景知识攻击.数据表同时抵制两种攻击的关键是一个等价类中敏感属性值相似的记录个数既不过多,也不过少.为满足等价类中敏感属性的这一要求,本文提出的(θ,k)-匿名模型在划分时将等价类分组,使记录满足在组内的敏感属性值相似,在组间的敏感属性值相异,达到同时抵制背景知识攻击与相似性攻击的目的. 模型不仅适用于敏感属性为具有语义关系的分类型数据,也适用于数值型数据.对于数值型敏感属性,可通过划分数值区间模拟分类型敏感属性的语义关系从而构造语义层次树;对于分类型敏感属性,通过语义分析构建相应的敏感属性语义层次树. 实验的硬件环境为Intel(R) Core(TM) 3.70 GHz,i3-4170 CPU,16.0 GB RAM,软件环境为Windows 7 64位旗舰版操作系统,虚拟机为vmware workstation,操作系统为ubuntu 14.04,算法开发语言为python 2.7.实验数据来自北京市某医院医疗数据库系统,实验中随机选取符合要求的30 000条记录进行实验,选取{年龄,患病年限,性别,家庭住址,有无过敏史,婚姻状态}作为准标识符,选取{疾病}作为敏感属性.通过比较(θ,k)-匿名模型算法与传统k-匿名模型算法、(p,k)-匿名模型算法对同一数据表的处理结果,对不同算法的抗攻击性能、信息损失率、执行效率进行分析,实验中取p=3,θ=3. 三种模型算法遭受背景知识攻击与相似性攻击的脆弱性如图2、图3所示.本文采用(θ,k)-匿名模型划分等价类,分组后的等价类中记录的敏感属性包含数个不同的类别,每个类别下包含不同的敏感属性值.在k值较小时,相对另外两种模型,本模型效果优势明显,由于k值小意味着每个等价类中包含的记录个数较少,因此敏感属性值的类别也相应较少,等价类易遭受背景知识攻击,此时若等价类中包含敏感属性值相似度较高的记录,则等价类易遭受相似性攻击.(θ,k)-匿名模型对等价类分组,使等价类中敏感属性值均匀分布,可更好地抵制两种攻击.k值增大意味着等价类中包含的记录个数增多,因此敏感属性值的类别也相应丰富,此时三种匿名模型的背景知识攻击脆弱性与相似性攻击脆弱性均降低,代表其抵制攻击的性能增强,尽管(θ,k)-匿名模型的脆弱性相比其他两种模型仍然较低,但与另外两种模型的差距有变小的趋势.总的来说,相比于k-匿名模型与(p,k)-匿名模型,(θ,k)-匿名模型抵制背景知识攻击与相似性攻击的性能均有所提升,且在k值较小时效果更好. 图2 背景知识攻击脆弱性Fig.2 Vulnerability of background knowledge attack 图3 相似性攻击脆弱性Fig.3 Vulnerability of similarity attack 图4、图5反映了三种模型算法在k值改变时执行效率与信息损失率的变化趋势.可以看出,三种模型的耗时均随着k值的增大而增多.一方面,k值增大,划分等价类时需要处理的记录个数增多,导致模型的耗时增多;另一方面,记录增多导致泛化层次的增加,也导致模型的耗时增多.本文提出的(θ,k)-匿名模型由于需要在不同的hash桶中寻找满足匿名要求的记录,因此与k-匿名模型和(p,k)-匿名模型相比,耗时更多.同时,k值增大,记录个数增多,等价类中需要泛化的准标识符数增多,泛化层次相应增加,故三种模型算法的信息损失率均随着k值的增大有所增加.(θ,k)-匿名模型在划分等价类时增加分组操作,因此需要更长的执行时间.但模型采用距离度量方法,保证同一等价类中满足(θ,k)-匿名模型要求的记录准标识符距离最小,更易于等价类中准标识符的泛化,可以有效减少不必要的信息损失.与k-匿名模型和(p,k)-匿名模型相比,(θ,k)-匿名模型信息损失的增长不超过2%. 图4 三种算法的执行效率Fig.4 Execution efficiency of three algorithms 图5 三种算法的信息损失率Fig.5 Information loss of three algorithms 为更好地防止数据表发布后可能存在的隐私泄露,本文在现有k-匿名模型及其改进模型的基础上提出了(θ,k)-匿名模型.将等价类中记录分组,旨在对等价类中记录的敏感属性做出约束,保持等价类组内记录敏感属性值相似,组间记录敏感属性值相异,使经过模型处理后的数据表具备同时抵制背景知识攻击与相似性攻击的能力,从而降低用户敏感信息泄露概率.模型不仅适用于敏感属性为具有语义关系的分类型数据,也适用于可通过划分区间模拟分类型数据语义关系的数值型数据.为提高数据可用性,在划分等价类时对记录准标识符进行距离度量,在满足(θ,k)-匿名模型的前提下,使等价类中记录之间的距离最小,以降低泛化时的信息损失.实验结果表明,在以保护隐私为主要目的的前提下,虽然(θ,k)-匿名模型牺牲了部分时间和信息损失,但同时抵制背景知识攻击与相似性攻击的性能得到改善.此外,由于本文只考虑了单一敏感属性的隐私保护情况,如何保护具有关联关系的多敏感属性是下一步研究的方向.2.3 (θ,k)-匿名模型算法的分析
3 实验结果与分析
3.1 抗攻击性能比较
3.2 执行效率与信息损失率分析


4 结束语
