面向小目标检测结合特征金字塔网络的SSD改进模型
2019-09-23张建明刘煊赫吴宏林黄曼婷
张建明, 刘煊赫, 吴宏林, 黄曼婷
(1.长沙理工大学 综合交通运输大数据智能处理重点实验室 湖南 长沙 410114;2.长沙理工大学 计算机与通信工程学院 湖南 长沙 410114)
0 引言
目标检测在计算机视觉领域一直是研究热点,通用类的目标检测是智能监控、智能机器人等大量应用投入实际使用时所需要的支撑技术.人脸检测[1]和行人检测[2]这两个单一类别目标检测技术已经相当成熟;但通用类的目标检测精度一直不是很高,检测的效果还有很大提升空间.通用类目标检测的难点在于待检测的目标物体的尺寸、形状、颜色等特征千变万化,并且很难找到其中的共性,所以传统的机器学习手工设计待检测目标的特征对通用类的目标检测来说,难度很大.近来,越来越多的研究者转向深度学习,涌现出了很多优秀的基于深度学习的检测算法.
2012年至今,许多深度学习的算法被提出来,如AlexNet[3]、ZFNet[4]、VGGNet[5]、Google-Net[6]、R-CNN[7]及Faster R-CNN[8]等,但这些方法都是分阶段的,检测速度慢,不能达到实时性的要求.鉴于分段式目标检测方法的缺陷,2016年,Redmon等人提出了YOLO(you only look once:unified,real-time object)[9]网络模型,同年,Liu等人提出了SSD(single shot multibox detector)网络[10].YOLO和SSD与之前的深度模型不同,它们是基于回归得到输入图片边界框和类别概率的神经网络框架.这种一站式完成提取特征和检测任务的神经网络实现了端到端的优化,提升了框架的速度,但SSD对小目标检测的精度较低,因为小目标检测需要高分辨率,而原始的SSD模型不能对浅层的特征图进行充分利用.本文借鉴SSD网络结构,结合特征金字塔网络[11]进行改进,充分利用浅层的高分辨率的特征图,以便提升原模型的精度.
本文以SSD为基本的框架模型,针对小目标检测问题,用特征金字塔网络对原始SSD框架进行改进.原始的SSD是基于金字塔特征层对各层不同大小的特征图进行回归,产生默认框的位置信息和类别信息,但原始的SSD对小目标的识别能力不足.本文将采用特征金字塔网络,将原始的SSD更深层的特征图与浅层的特征图进行融合,目的是将深层特征图更抽象的语义信息赋予浅层特征图,然后对融合后的特征图进行回归,得到默认框的位置信息和类别信息.实验表明,在PASCAL VOC数据集上的检测精度比原始的SSD有所提升.
1 预备知识
1.1 SSD模型
SSD模型有3个关键的特征:① 多尺度特征图预测.分别从Conv4_3层、Conv7层、Conv8_2层、Conv9_2层、Conv10_2层和Conv11_2层引出特征图,用这些大小不同的特征图做预测;② 卷积层预测.每个特征层,都可以通过一组卷积滤波器得到一组固定的预测结果;③ 默认框和长宽比.每个特征图上的像素点都会对应一系列的框,再根据不同的长宽比,生成更多尺寸不同的框,这些不同尺寸的框可以用来预测不同尺寸和形状的目标.
对于一个给定的像素点位置,有k个默认框,每个默认框要预测出c个类别分数和4个相对原始默认框的偏移值,即每个框要预测(c+4)个值.这样对于一个给定的位置需要k×(c+4)个值,就需要k×(c+4)个卷积核来实现.所以对于一个m×n大小的特征图,共有m×n×k×(c+4)个输出.


1.2 特征金字塔网络
金字塔是种“形近”的表达,如图1所示,深度学习中有各种各样的金字塔,示意图中灰色部分黑色边框为输入的图片,白色部分黑色边框为通过神经网络得到的特征图.图1(a) 神经网络的输入为尺寸单一的图片,经过不同的卷积层和池化层(通过卷积和池化操作,特征图逐渐变小,也形似金字塔),仅根据最后一层的特征图进行预测,这是单特征图(single feature map).图1(b) 对图片进行不同比例的放缩,输入到模型,然后对不同尺度的图片进行处理预测,最后对各个预测结果进行综合判定,这是特征化图像金字塔(featurized image pyramid).图1(c) 输入为尺寸单一的图片,不同的卷积池化层,对不同大小的特征图分别进行预测,然后再对所有的预测结果进行综合判定,这是金字塔特征层(pyramidal feature hierarchy).原始的SSD就是采用多层卷积特征图进行综合预测的.图1(d) 对一张图片进行一个尺寸的单一输入,经过不同的卷积层和池化层,得到尺寸大小不一的特征图,再对这些大小不同的特征图分别进行预测,然后再对所有的预测结果进行综合判定.但是不同的是,它选用的用来预测的特征图是将当前层的更深一层的特征图进行上采样后,再和当前层的特征图进行融合得到的特征图,这是特征金字塔网络(feature pyramid network,FPN).

图1 各种类型金字塔Fig.1 Various types of pyramid
2 FPN-SSD模型
SSD是从多层不同尺度大小的特征图去做预测.不同层级的特征图上有着不同的语义信息,浅层的特征图分辨率高,但只是一些浅层特征,表达特征的能力有限,会影响检测性能.SSD利用了深层特征,但却没有充分利用浅层特征,而是增加网络深度,抛弃浅层特征图所携带的细节信息,这会影响小物体目标的检测.FPN的思想是将浅层和深层的特征图进行融合,使得到的浅层特征层也拥有深层的语义能力,且又不影响小物体的检测.FPN能够利用各个层级特征图的特点,来提高SSD网络的综合检测能力.结合FPN思想,提出了FPN-SSD检测器(feature pyramid network for single shot multibox detector,FPN-SSD).
2.1 FPN-SSD模型的处理流程
一张图片输入到FPN-SSD模型中,处理过程如图2所示. 首先图片尺寸会被更改为300×300的大小,再依次通过VGG16的Conv5_3部分及Conv6、Conv7、Conv8_1、Conv8_2、Conv9_1、Conv9_2、Conv10_1、Conv10_2、Conv11_1、Conv11_2这些卷积层进行处理.然后,对Conv11_2的1×1大小的特征图,由c10_2进行上采样操作,得到尺寸为3×3的特征图.用t10_2减少Conv10_2的特征图的通道数,得到3×3大小的特征图.然后由co10_2将这两个3×3的特征图进行相加操作(融合),得到融合后尺寸大小为3×3的特征图;然后再对融合后得到的特征图,经过c9_2的上采样操作,再与t9_2横向连接层得到的特征图进行融合,得到融合层co8_2的特征图,依次进行同样的操作得到所有融合层的特征图,最后用p4_3、p7、p8_2、p9_2和p10_2处理融合层的特征图,得到预测层的特征图,再用非极大值抑制进行预测.其中,p11_2处理的特征图是由Conv11_2直接得到,不来自融合层.
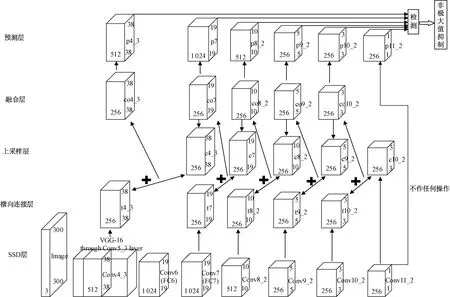
图2 基于特征金字塔网络的网络模型图Fig.2 Network model map based on feature pyramid network
2.2 FPN-SSD模型分层介绍
FPN-SSD模型分为SSD层、横向连接层、上采样层、融合层和预测层.SSD层是原始的SSD模型,详细的参数见文献[10].其余的横向连接层、上采样层、融合层和预测层是本文的设计,各层详细的参数和作用如表1所示.表1展示了横向连接层的各个层由该层到下层的卷积核的大小、通道数量、进行卷积操作时的步长和填充及经过卷积后得到的特征图的大小.该层目的是减少通道数,为后续的融合做准备.因为只有被融合的两层有相同的通道数,才能进行融合.

表1 横向连接层参数Tab.1 Lateral connection layer parameters
上采样层将特征图进行放大,放大到原来的两倍.在特征图放大的过程中,会出现很多没有像素值的空位,空位采用最邻近插值进行值的填充,特征图数量均为256,上采样层c4_3、c7、c8_2、c9_2、c10_2的输出特征图尺寸分别为38×38、19×19、10×10、5×5、3×3.上采样是为了得到融合时所需要尺寸的特征图.
融合层co4_3、co7、co8_2、co9_2、co10_2的输出特征图尺寸分别为38×38、19×19、10×10、5×5、3×3,该层实现了将横向连接层得到的特征图和上采样层得到的特征图进行相加的操作,之前已经将它们的通道数全部转换为256,只有通道数相同且特征图大小一致,才能完成特征图的融合.
表2展示的是预测层的参数,该层由融合层执行卷积操作得到,目的是将融合层的特征图进行去模糊化操作.因为特征图经过放大都是根据临近位置的像素值进行填充的,这就可能会造成成块的像素值大小相近,目标物体的轮廓不明显,使目标变得模糊,所以就需要这步操作.

表2 预测层参数Tab.2 Prediction layer parameters
3 实验环境与实验结果
3.1 实验环境
本文实验环境是14.04.1-Ubuntu系统,处理器的型号为Intel(R) Xeon(R) CPU E5-2670 v3 @ 2.30 GHz×12,显卡的型号为NVIDIA GeForce GTX TITAN X,显存为12 G,内存为128 G.
本文实验是在PASCAL VOC数据集上进行,实验的模型框架是FPN-SSD,预测层是p4_3、p7、p8_2、p9_2、p10_2和p11_2,训练采用的是随机梯度下降,批次大小是32,权重衰减是0.000 5,动量是0.9,学习率衰减因子是0.94.其中,权重衰减是正则化的系数,防止过拟合;动量的作用是摆脱局部最优达到全局最优.
3.2 实验结果
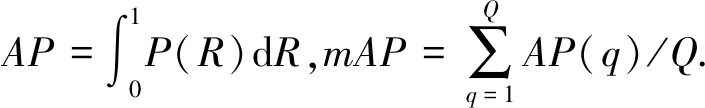
表3是在PASCAL VOC 2007 train+val数据集上进行训练,并在PASCAL VOC 2007 test数据集上进行测试得到的结果.其中,Fast是指Fast R-CNN网络;Faster是指Faster R-CNN网络;SSD300是指SSD网络输入的图片尺寸首先更改为300×300;前3行引自文献[10].可以看出,原来的SSD300还没Faster的mAP高.改进后的FPN-SSD,mAP由SSD的68.0%上升到了69.8%,与Faster基本持平,并且大多数的类别也有明显的提升.其中,加粗的是与SSD相比较有提升的类别(表3列举出了大多数类别).
表4是在PASCAL VOC 2007和2012 train+val数据集上进行训练,并在PASCAL VOC 2007 test数据集上测试得到的结果. 可以看到mAP由原来SSD的74.3%提升到75.8%,并且精度在大多数的类别上都有所提升,尤其以盆栽植物这类原SSD模型不能很好检测的密集小目标,也有较好的提升.其中,加粗的是与SSD相比较有提升的类别.
在PASCAL VOC 2007和2012 train+val数据集上训练,YOLOv1在PASCAL VOC 2007 test数据集上的mAP为63.4%.相同条件下,YOLOv2 288的mAP为69.0%;YOLOv2 352的mAP为73.7%;本文方法的mAP为75.8%.其中,YOLOv1是指YOLO的第一个版本,YOLOv2 288是指YOLO的第二个版本且输入首先resize为288×288,YOLOv2 352同理.可以看出同为端到端的模型,本文模型在精度上具有一定的优势.
不同模型的检测结果如图3所示.第一行是SSD模型,第二行是本文的FPN-SSD模型.第一幅盆栽,FPN-SSD正确检测到了所有的盆栽植物,而SSD模型有一个盆栽没有检测到,并且还有一个多余的检测框;第二幅飞机,FPN-SSD有2架飞机漏检,而SSD模型有5架飞机漏检;第三幅瓶子,FPN-SSD检测到9个瓶子,而SSD检测到5个瓶子.这些都是密集类小目标的检测,可以看出,对于这类目标,本文设计的FPN-SSD的网络确实比原始的SSD有一定的提升.

图3 不同模型的检测结果对比Fig.3 Comparison of detection results of different models
4 结束语
本文选用了端到端检测的经典模型SSD,相比于YOLO模型,SSD模型是利用多层不同尺度大小的卷积特征对目标物体进行预测.同时借助于特征金字塔网络可以将深层的特征图所携带的语义信息与浅层的特征图进行融合,且融合后的特征图有更强的语义信息和更丰富的细节信息,对小目标的物体检测有所帮助.将特征金字塔网络的思想用于SSD模型的改进,实现了FPN-SSD模型在PASCAL VOC数据集上的检测能力有所提升.但是改进后的模型也还是有很多不足,如实验结果中展示的漏检的飞机和瓶子,这种密集小目标的检测虽然有所提升,仍然还有漏检.就检测精度而言,对用于真实场景下的检测[12],还有一定的提升空间.
