自行火炮发动机多状态参量融合故障诊断方法研究
2019-09-23李旭,孟晨,刘敏,王成
李 旭,孟 晨,刘 敏,王 成
(陆军工程大学石家庄校区,河北 石家庄 050003 )
发动机是自行火炮底盘的“心脏”,状态运行参数之间存在高度的非线性耦合,故障具有复杂、非线性等特点[1]。单一的信息源己远不能满足故障诊断的需要,对多源信息进行优化组合以降低不确定度和提高诊断精度成为发展趋势。沈寿林等探索了基于多传感器信息融合的自行火炮发动机故障诊断理论和方法,在一定程度上克服了因发动机本身可测试性差、故障层次多,用单传感器故障诊断方法可靠性低的缺点[2]。张英堂等通过用润滑油光谱信息来分析发动机磨损状态以及缸盖振动信息分析发动机中有工作时序关系的运转机构状态,提出了将发动机磨损状态信息和振动信息相综合,实现两种信息对发动机故障的综合诊断推理[3]。Basir等研究了基于D-S证据理论的发动机多传感器信息融合诊断方法[4]。在使用传统的神经网络学习方法时,虽然容易产生局部最优解,但是由于其黑箱性的特点,网络学习和决策过程很难理解。证据理论不仅能够体现人类对事物估计时的主观性,还能保持事物本身客观性的特点,在对不确定问题进行处理方面具有很完整的理论基础。然而,由于证据理论需要独立数据的特殊条件,其合理性也存在争议。鉴于此,马超等采用证据理论和极限学习机相融合的发动机诊断方案[5]。考虑到量子粒子群优化算法的较强寻优能力,将量子粒子群优化算法应用于极限学习机,用以确定网络节点的输入权重和阈值,替代原本的随机取值方式,笔者提出了提出了量子粒子群优化的核极限学习机(Quantum Particle Swarm Optimization-Kernel Extreme Learning Machine,QPSO-KELM)和D-S证据理论证据理论的融合诊断方案。
1 信息融合诊断模式对比
依据信息融合系统中数据抽象层次,融合可以划分为3个级别:数据级融合、特征级融合和决策级融合[6-7]。
在选择使用的时候,可以根据应用环境的不同和方案本身的侧重点来取得最适合的方案。3种融合模式的对比如表1所示。

表1 3种融合模式的对比
2 特征参数
2.1 特征参数的选取
特征参数的选取应满足以下3条原则[8-10]:能够反映发动机的动力和经济性能;能够反映发动机技术状况变化过程;在技术上能实现不解体检测且具有一定的抗干扰性。经查阅文献、调研发动机制造厂,根据各性能参数对其整机性能表征能力的不同,选取以下对发动机性能评价能力较强的参数作为发动机整机性能状态融合与识别的状态参量:转速、尺杆位移、进气压力、喷油压力、水泵后压力、机油滤前压力、机油滤后压力、以及油液元素铁、铜、铝和铬4种元素的浓度梯度。转速、齿杆位移和进气压力作为衡量发动机整体动力性能的参数参与发动机整机状态识别。通过在发动机正常状态的不同工况下进行发动机状态参数测试试验,建立发动机转速、尺杆位移和进气压力之间对应关系的脉谱图,通过建立数学模型获得3个参数之间数学关系的拟合曲线公式。在后续测试评估过程中,通过检测发动机当前运行状态下的转速和尺杆位移,并将其代入拟合公式获得发动机在此工况正常状态下进气压力的正常值,然后与实测值相比较,计算实测值与拟合值的相对偏差,即进气压力偏差;计算机油滤前压力和机油滤后压力的差值,即机油滤前后压力差作为融合分析参量;计算油液中铁、铜、铝和铬元素的浓度梯度作为融合分析参量;将喷油压力、水泵后压力的实测值作为融合分析参量。对于以上参量,分别确定其正常状态阈值,当实测参量超出阈值时即判定发动机整机状态可能出现异常。鉴于此,笔者最终确定用于融合分析与识别发动机整机状态的性能状态参量为:进气压力偏差、机油滤前后压力差、喷油压力、水泵后压力、铁元素浓度梯度、铜元素浓度梯度、铝元素浓度梯度和铬元素浓度梯度。
2.2 特征参数的曲线拟合
试验在SG150型发动机上进行,控制发动机转速分别为800、1 000、1 200、1 400、1 600、1 800、2 000、2 200 r/min,空载状态下记录油门齿杆、压后压力和扭矩;步增加齿杆位移,每次增加量为2 mm,记录转速、油门齿杆位移和压后压力数据。
选择1 400~2 200 r/min高速工况下的试验数据进行拟合分析。基于“最小二乘法”对3个参数之间的函数关系进行拟合,3次拟合运算后获得的“转速-齿杆位移-进气压力”拟合曲线表达式为
p=110.133 6-54.482 5x-0.059 5n+
0.028 6xn+24.097 5x2-
0.001 2x2n-0.068 4x3,
(1)
式中:p表示进气压力;x表示齿杆位移;n表示转速。
根据式(1)分析定转速工况下的“齿杆位移-进气压力”关系曲线如图1所示。
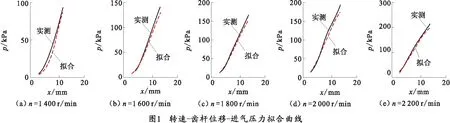
由图中可以直观地看出,在高速工况下获得的“转速-齿杆位移-进气压力”拟合曲线的拟合效果良好,实测进气压力与拟合进气压力曲线基本重合。
通过比较进气压力实测值与拟合值可知:拟合值与实际值相比偏小。根据计算可得到各工况下的“转速-齿杆位移-进气压力”的拟合偏差。由计算结果可知,各工况下的进气压力拟合误差均在5%左右,且集中分布于5%以下,拟合效果较好。根据计算结果可得式(1)的平均拟合误差为2.46%,即拟合进气压力小于实际进气压力,且平均偏差范围在2.46%以内,此误差较小,满足状态评估时的进气压力拟合精度的要求。将式(1)输入发动机多参数信息融合诊断系统,以利用各工况下的转速和齿杆位移对相应工况下的进气压力进行拟合计算。
2.3 特征参数阀值确定
根据该型发动机研制生产单位调研结果,给定发动机各状态参量的阈值范围,如表2所示。

表2 发动机整机性能状态参量阈值
3 诊断模型
3.1 诊断原理
笔者采用了特征层与决策层多层融合方式[11-13],以获得更高的识别准确率。选择QPSO-KELM发动机整机性能状态参量特征层融合分析方法,D-S证据理论作为决策层融合分析方法。其具体过程如图2所示。
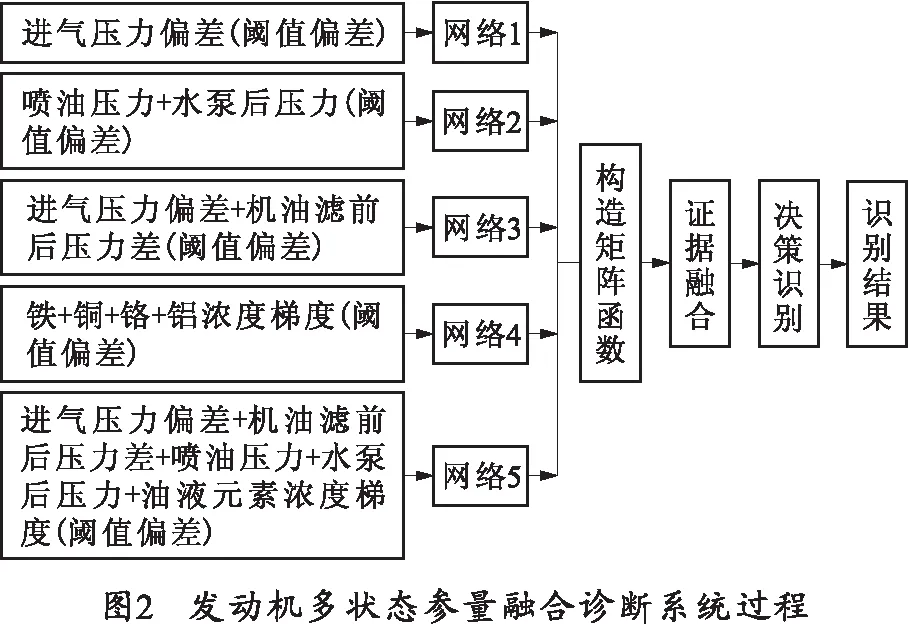
发动机多状态参量融合诊断系统通过采集发动机油滤前后压力、喷油压力、水泵后压力等状态参数,并计算图2所示进气压力偏差等相应特征作为整机性能评价参数;然后基于QPSO-KELM网络构建5个弱分类器,并将上述特征分别输入各分类器,在特征层实现发动机性能状态的初步识别;最后利用各分类器识别结果构造信度函数矩阵,输入D-S证据理论模型,在决策层实现整机性能综合评价,最终得到高置信度的性能识别结果。
3.2 发动机整机状态识别方法实现方案
首先在发动机上进行异常状态模拟试验,采集相应状态参数,建立原始测状态参数数据库;然后利用MATLAB软件构建极限学习机网络,利用采集的试验数据对极限学习机网络进行训练与测试,直到获取满意的识别精度;利用不同状态参量所对应建立的极限学习机网络的隐层权值矩阵、隐层节点阈值和输出层权值矩阵中的权值参数作为各状态参量在信息融合分析评估公式中的权重。此方法避免了在软件中直接建立复杂的分类网络和进行复杂大量的网络训练与测试,而是利用网络训练权值作为权重直接参与状态融合评估分析公式,从而将复杂的网络问题转换为了状态评估公式问题,同时又能够满足状态识别精度要求。
基于MATLAB软件,在极限学习机状态识别分类网络之后,利用D-S证据理论对多个不同的分类子网络的识别结果进行综合分析判断,得出更加准确可靠的发动机联合状态识别结果。在软件中直接将以上分析得到的各参数对应的证据理论置信度作为状态识别参量置信度输入状态识别公式,进行融合分析。
综上所述,基于信息融合的发动机状态识别公式由三部分组成:状态参量权重,识别结果置信度和识别标识符。此公式可以表示为
χ=(αq+βq)γqδq+(αj+βj)γjδj+
(αh+βh)γhδh+(αm+βm)γmδm+
(αp+βp)γpδp,
(2)
式中:α表示各状态参量的阈值偏差;β表示各状态参量的融合权重;γ表示各状态参量的融合置信度;δ表示各状态参量的识别标识符,δ的取值仅为0或1(当状态参量超过阈值时,δ=1;当状态参量未超过阈值时,δ=0).
4 特征层融合方法验证
4.1 基于量子粒子群优化的核极限学习机
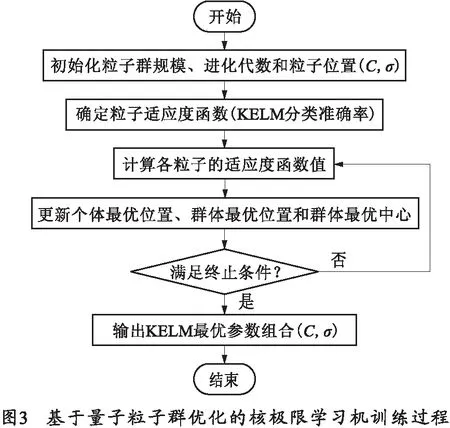
对于核极限学习机分类网络,为选择最优的网络参数组合(C,σ),选用量子粒子群算法对其进行寻优。基于量子粒子群优化的核极限学习机的网络训练过程如图3所示。
4.2 数据库分类试验
分类试验选用UCI数据库中的Diabetes、Image Segmentation、Satimage、Wine、Glass Identification和Page Blocks数据集。比较说明本方案的优越性,将粒子群优化的核极限学习机分类网络(PSO-KELM)作为对比试验。两种分类器网络对UCI数据集进行训练得到的训练分类准确率收敛过程曲线如图4所示。
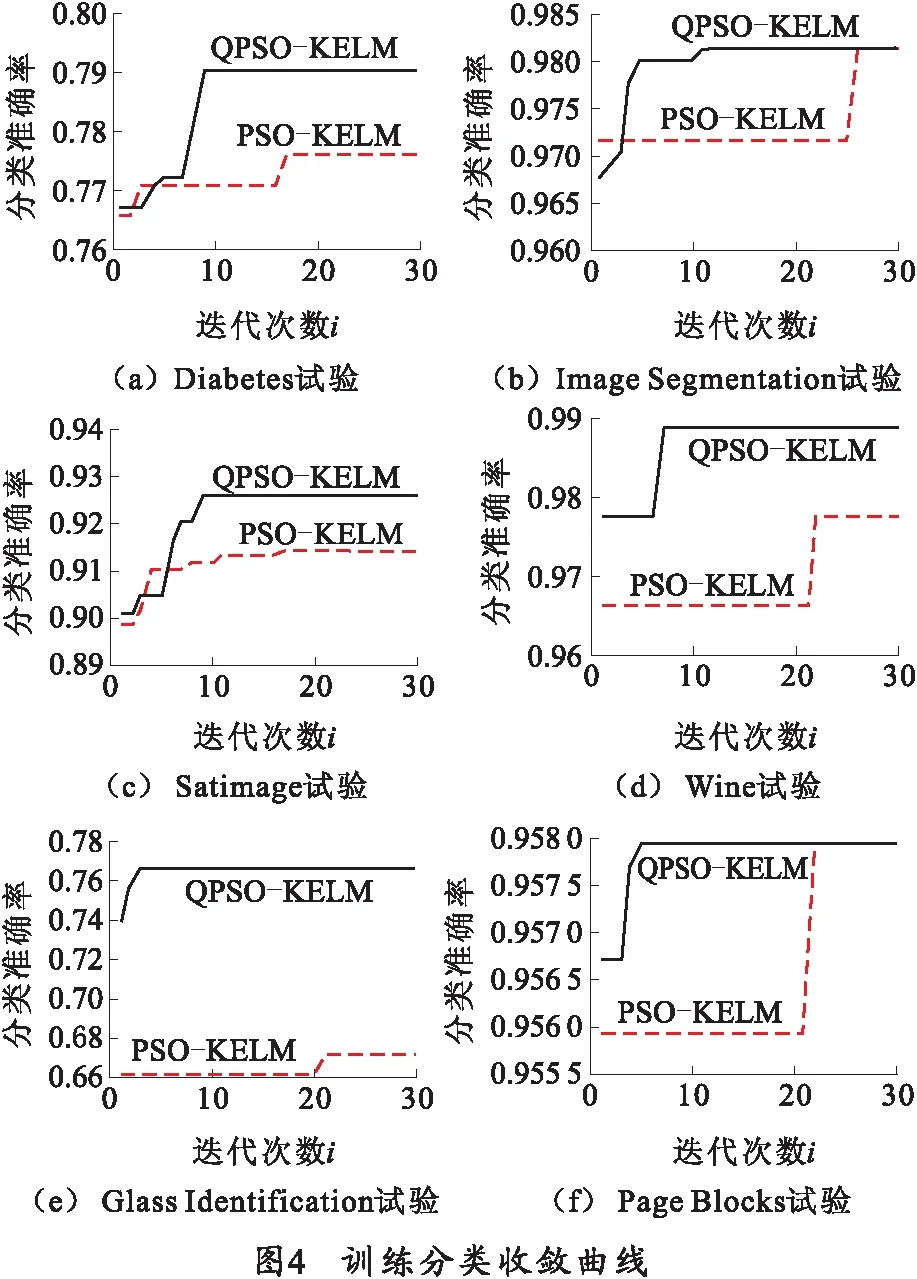
由图4中的数据可以看出:本研究确定的基于量子粒子群优化的核极限学习机分类网络(QPSO-KELM)具有更高的分类准确率和更快的网络训练速度。
4.3 发动机性能状态分类试验
4.3.1 部分试验数据采集
试验在SG150型发动机试验台架上进行,分别设置发动机正常工作、左6缸断油、右1缸断油、左6缸和右1缸同时断油、进气口堵30%和进气口堵50%共6种工况。试验中通过遮盖进气口的方法模拟进气口堵塞故障,通过断开高压油管的方法模拟气缸断油故障。试验中通过CAN总线采集转速、齿杆位移、进气压力、喷油压力、水泵后压力、机油滤前后压力信号,通过油液分析获得铁、铜、铝、铬4种元素的浓度梯度。某故障模拟方法如图5所示。

极限学习机的网络输入特征参数分别为进气压力偏差阈值、喷油压力与其阈值偏差、水泵后压力与其阈值偏差、机油滤前后压力差与其阈值偏差和铁、铜、铝与铬4种元素的浓度梯度参数与其阈值偏差作为极限学习机网络的输入特征参数。特征参数计算公式如下:
1)对于进气压力偏差、水泵后压力、机油滤前后压力差及铁、铜、铝、铬4种元素的浓度梯度,与相应阈值的偏差计算公式为
(3)
式中:α为各参量与其阈值的偏差,简称参量阈值偏差;x为各参量实测值;y为各参量阈值。
2)对于喷油压力,由于其具有上下限两个不同阈值,喷油压力与其阈值的偏差α为
(4)
式中,x表示喷油压力实测值。
4.3.2 分类网络建立
为分析不同参数组合以及不同参数数量的分类网络对于发动机运行状态的不同识别精度,分别构建如图2所示的5个具有不同输入参数组合形式的核极限学习机分类网络,进行发动机状态识别。5个网络的输出层单元数均为2,分别以10和01表示发动机状态正常和异常两种状态。输出层第1个神经元的输出大于0.5,且是输出层各神经元的输出最大者,识别为正常;输出层第2个神经元的输出大于0.5,且是输出层各神经元的输出最大者,识别为异常。
4.3.3 特征参数归一化
在利用核极限学习机分类器进行状态识别之前需要对原始特征参数进行归一化处理,将各特征参数值转换到(-1,1)内,从而消除因特征参数数量级之间的差别而对分类结果造成的影响。本章利用最大最小值归一化方法对原始特征集合进行归一化处理,构造状态识别样本集。归一化后的特征参数值为
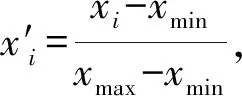
(5)
式中:xi为第i个特征参数;xmin和xmax分别表示特征向量中特征参数的最小值和最大值。
4.3.4 状态识别结果
每种状态选取40个样本作为学习样本,20个样本作为测试样本。将归一化的特征参数分别输入各分类网络进行状态识别,得到各网络的状态识别结果如表3所示。以识别率衡量网络识别精度,识别率的计算公式为

.

(6)
5 决策层融合方法验证
以上述5个分类网络作为初级弱分类器进行状态评估得到评估决策结果,然后利用D-S证据理论方案再进行决策层评估,获得最终的评估决策结果。
极限学习机各子网络和经过D-S证据理论融合分析后的发动机状态识别结果对比如表4所示。

表4 状态识别结果对比
由表4中数据可以看出,经过D-S证据理论决策层融合分析之后得到的状态评估结果的准确率进一步提升达到100%.
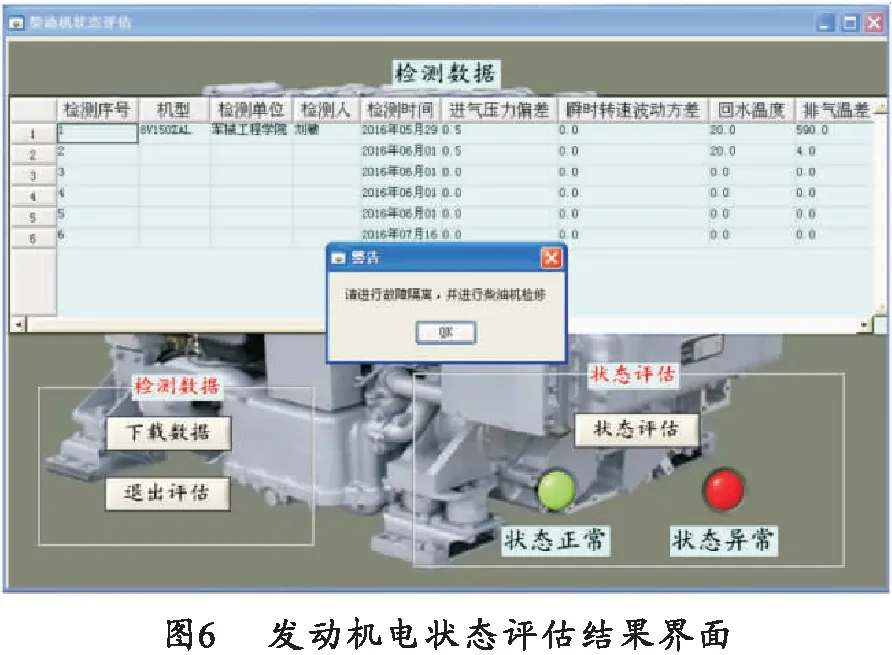
为验证诊断方法的有效性,通过实装故障模拟,对该系统进行试验测试。系统通过下载所有测试数据,并选择相应的测试数据进行当时测试状态下的柴油机整机性能状态的识别。图6为发动机状态评估结果界面,以序号为1的测试记录为例,当点击“状态评估”按钮时,系统自动完成对柴油机状态的评估。当评估结果为正常时,“正常”指示灯变为红色;当评估结果为异常时,“异常”指示灯变为红色,并提示进行子系统及部件的故障隔离,此时应该退出状态评估模块,并进入故障隔离模块进行故障的深入分析。
对柴油机起动系统、冷却系统、润滑系统、供油系统和进排气系统的故障进行识别隔离,并给出故障隔离结论和维修建议,其故障隔离到柴油机子系统及其部件。首先对柴油机进行状态评估,当评估结果为异常时,进入故障隔离模块,利用状态评估数据对此状态下的柴油机进行故障诊断。当某系统存在故障时,此系统对应的指示灯变为红色,同时此系统中某部件相应故障模式前的复选框标记为“√”.以某状态评估数据为例,对柴油机进行故障隔离。点击“故障隔离”按钮,其运行结果界面如图7所示,系统自动对柴油机子系统及其部件进行故障诊断。

6 结束语
综上所述,基于信息融合的思想,对不同状态信息进行融合分析,可以显著提高发动机状态识别精度。基于QPSO-KELM和D-S证据理论的融合诊断方案,综合利用发动机各类信号特征,进行特征层和决策层融合分析之后,发动机故障状态评估准确率逐步提升,最终的状态评估准确率可达100%.
