基于混合Copula模型的水稻保险费率厘定
2019-09-20赵玉,严武,李佳
赵 玉,严 武,李 佳
(1.东华理工大学 经济与管理学院,江西 南昌 330013;2.江西财经大学 金融学院,江西 南昌 330013)
一、引言
粮食是关系国家安全和社会稳定的战略物资。气候变化导致的粮食歉收和市场波动导致的丰产不丰收降低了农户种粮的积极性。2015年之后中国粮食产量结束了连增的趋势,粮食生产出现了种植面积和产量双降的局面。为了保障粮农的利益,国家实施了粮食价格支持政策。但因受到“黄箱政策”的约束,国内粮食财政补贴的空间越来越小。如何采用市场化工具保障农户种粮收益已经成为重大、迫切的社会问题。农业保险作为应对自然灾害、维持收入稳定的重要风险管理工具,理论上有助于提高农户种粮的积极性、促进粮食生产[1]。从世界贸易组织的规则来看,实施农业保险补贴属于国际贸易允许的“绿箱政策”[2]。从国际经验来看,美国农业保险制度经过近百年的改革与完善,已发展成为世界上最成熟的农业保险体系,为其农业构建了牢固的安全网[3]。从国内农业风险管理的实践来看,相比于期货、期权等复杂的金融衍生品工具,农业保险更适合现阶段的农户抵御农业经营风险。农业保险既是现代农业发展的支柱,也是农村经济健康发展的重要条件。经过近四十年的发展,国内农业保险已开发了自然灾害险、价格险、收入险、气象指数险等险种,覆盖了农林牧渔全农业领域。与产品创新形成鲜明对比的是,多数农业保险处于小范围试点阶段,农业保险市场有效需求不足。当前,中国农业保险存在农户农业保险需求不高、保险公司从事农业保险业务积极性不高、政府引导作用有待增强等问题[4]。中国农业保险正面临“供需双冷”的困境,合理的保险定价是破题的关键[5]。保险定价不合理极易诱发逆向选择和道德风险,从而阻碍了农业保险市场的发展。
随着保险品种的创新,国内先后试点了农产品价格保险和收入保险。价格保险和产量保险仅考虑了单一风险因子,而收入保险在实务中同时考虑了价格和产量双风险因子。目前,黑龙江、江苏、河南等地分别针对玉米、水稻和小麦等粮食作物试点了收入保险。收入保险综合了产量险与价格险的保障功能,更加符合农户风险保障的现实需要。与单独的农作物产量或者价格保险相比,农产品收入保险可以提高农户购买农业保险的积极性[6]。从社会福利角度分析,收入保险在增加生产者福利及整个社会福利方面比产量保险更好[7]。在保险实务中,合理的收入保险费率厘定需要保险人对农产品产量、价格和收入的分布作出准确估计。过去几十年产量分布被用来厘定农业保险费率。常用的费率厘定方法主要是参数模型。该类方法要求先验地假设农作物产量服从某种分布[8]。先验假设限制了参数方法的应用。为了克服这一缺陷,有些学者在测算保险费率时采用了半参数或非参数分布模型[9-10]。在收入保险定价方面,国内有学者测算了粮食作物的收入保险费率。谢凤杰等通过对辽宁省5个市县大豆收入保险费率进行测算,指出收入保险费率、保额存在明显的地区差异[11]。王保玲等采用单产和价格测算了中国谷物的收入保险费率[12]。对比已有研究发现,收入保险费率的测算结果依赖于所使用的统计方法并对价格数据较为敏感。目前学术界并未就价格数据选择标准形成共识。不同的数据选择标准和来源导致研究结果出现了较大差异,制约了农业收入保险的理论研究和实务发展。
农业收入保险可以为自然风险和市场风险提供双重保障,是未来中国农业保险发展的方向。从已有文献来看,大多数研究在时间序列分析的基础上采用参数分布模型来拟合农产品产量和价格的边缘密度,并运用单一Copula 函数拟合联合分布,在缺少对比和模型选择标准时可能会造成一定的偏差。过高或过低的保险费率均不利于农业保险市场的发展。另外,各地区水稻种植业风险无论在产量还是价格方面都具有异质性,这意味着不同地域的保险费率存在差异。在厘定农业保险费率时,分析变量的时空特征可能比仅分析变量的时间序列趋势更加合理。有必要采用较科学的统计方法测算水稻收入保险费率并与产量保险、价格保险做对比,为进一步优化中国粮食保险机制提出对策建议。
二、研究方法与数据
(一)研究方法
Copula函数可以将多个随机变量的边缘分布表述为联合分布的形式。将水稻产量和价格记作q和p,它们的边缘分布分别记作F1和F2,联合分布记作F,Copula函数记作C。F和C的表达式如下:
F(q,p)=C(F1(q),F2(p))
(1)
(2)
其中,u1和u2为边缘分布的概率。将联合密度函数记作f,Copula密度函数记作c,随机变量的边缘密度函数记作f1和f2。联合密度函数的表达式如下:
f(q,p)=c(F1(q),F2(p))f1(q)f2(p)
(3)
由此可得到收益的数学期望值表达式为:

F2(p))f1(q)f2(p)dqdp
(4)
将风险保障水平记作λ,保险合同的预期损失公式如下:
EL=E[(λμ-qp)I(qp≤λμ)]
(5)
I为示性函数,当实际收入小于保险金额λμ时,示性函数值等于1,触发理赔,否则等于0。收入保险的纯费率表达式如下:
r=EL÷(λμ)
(6)
同理可以推导出价格保险和产量保险的纯费率表达式。保险精算的难点在于选择合适的概率密度函数来逼近总体的真实分布。现有研究主要采用拟合多个密度函数,然后根据K-S检验等统计方法进行优选。但这种方法依赖于事先对总体分布的假设,而做出这种假设往往会存在信息遗漏。非参数方法则不需要对总体分布做出先验假设。
从密度函数的定义可知,某一点x处的密度函数估计值的大小与该点附近所包含的样本点个数有关。若x附近样本点比较稠密,则密度值较大,反之,则较小。核密度估计法不依赖于样本区间的人为划分,该方法根据x邻域(窗口)内的点距离x的远近来确定它们对密度值的贡献大小。核密度法得到的密度函数估计值表达式如下:
(7)
核密度法容易受到窗口h大小的影响,h取值会影响到密函数估计值的光滑程度。为了克服h取值的影响,将密度函数估计值和真实值的均方误差记作MSE(式(8)),求MSE的最小值,可以得到最佳窗口的估计值。
(8)
在采用非参数方法得到了边缘密度函数f(x)之后,采用极大似然法估计Copula函数的参数。价格和产量的联合分布函数为F(q,p,θ1,θ2,β),其中,θ1为q的边缘分布函数的待估计参数,θ2为p的边缘分布函数的待估计参数,β为Copula函数的待估计参数。价格和产量的联合密度函数如下:
=c[F1(q,θ1),F2(p,θ2),β]f1(q,θ1)f2(p,θ2)
(9)
由于采用了非参数方法估计了边缘密度函数,因此待估计的对数似然函数可以简化为:
(10)
常用的Copula函数主要包括正态Copula、Gumbel-Copula、Clayton-Copula和Frank-Copula函数。其中,Gumbel-Copula、Clayton-Copula和Frank-Copula函数分别用于描述上尾部相关、下尾部相关和双尾部相关三种典型的相关模式。由于事物之间的关系是复杂多变的,产量和价格之间的关系并非一成不变。根据以上Copula函数的特征构建混合Copula函数来衡量复杂的相关模式。Hu给出了混合Copula函数的构造方法并证明双变量混合函数仍具有一般Copula函数的优良性质[13]。基于此,将混合Copula记作MC4,公式如下:
MC4=w1CGauss+w2CGumbel+w3CClayton+w4CFrank
(11)
权重w1+w2+w3+w4=1,且权重w1、w2、w3和w4均不小于0。混合Copula函数涵盖了四种函数的特性,不仅可以描述粮食产量和价格之间,上尾部、下尾部和尾部对称相关三种相关模式,还可通过权重来判断产量和价格之间是否存在尾部非对称相关模式。分别计算不同类型Copula函数的极大似然对数值及参数,并将这些参数作为初始值代入公式(11)的惩罚极大似然函数(12)中,采用EM算法估计权重和相依结构参数。
L=∑[lnf1(q,θ1)+lnf2(p,θ2)]+
∑ln[∑wkck(F1(q,θ1),F2(p,θ2),βk)]-
T∑gγ(wk)
(12)
惩罚函数采用具有无偏性、稀疏性和连续性的SCAD函数形式,公式为:
(13)
其中,w为非负值的权重参数,a为大于2的常数,γ为大于0的门限值。为了验证联合分布模型的合理性,根据理论联合分布与经验联合分布的平方欧氏距离来选择合适的Copula函数。
二元联合分布的经验Copula函数记为Cf,理论Copula函数记为Cn,由平方欧氏距离的定义得到距离函数:
d2=∑|Cf(u1i,u2i)-Cn(u1i,u2i)|2
(14)

估计出混合模型的参数后,采用Monte Carlo模拟获得单产、价格和收入的大样本数据,并计算出种植水稻的预期收入和不同保障水平下的纯风险费率。参考Cole等的研究,模拟的步骤如下[14],首先,根据合适的联合分布函数生成10 000组边缘分布函数F1和F2的值;其次,根据样条函数插值计算出对应的单产和价格数据;然后,将F1和F2的值代入联合分布函数中得到联合分布的概率,利用数值积分得到产量、价格和产量×价格的期望值;最后,利用式(5)、式(6)厘定价格、产量和收入的纯保险费率。
(二)数据预处理
生产者价格准确反映了粮食的生产成本和粮农的预期,采用该价格指标测算收入保险价格能够更好地保障农户的利益。生产者价格数据和亩产数据均来自2002年至2017年的《中国农产品成本收益资料汇编》。根据生产季节划分,国内产稻地区主要种植了早、中、晚三类水稻,其中早稻、中稻和晚稻的主产省份数量分别为9、10和9个。采用农产品生产价格指数(定基指数,2000年为100)对水稻价格序列做了平减,计算出2001年至2016年的实际价格。收入保险的关键是厘清产量和价格之间的联合分布。在此基础上,可以计算出不同保障水平下的保险费率。
早稻和晚稻主产区主要分布在长江以南地区,中稻主产区主要分布在秦岭淮河以南地区。地域上的集中种植使得水稻产量和价格的趋势变化具有一定的趋同性,但各地自然和市场环境的差异也导致了水稻产量和价格的异质性。由于保险合约需要满足可保性要求,即保险只保障不可预期的风险,因此在计算产量和价格风险的联合分布之前,先采用个体固定效应的面板自回归模型将产量和价格数据分解为序列趋势、个体效应和随机波动三部分,其中,随机波动项对应不可预期的风险。经过模型的调试,确定单产趋势方程和价格趋势方程中自变量的最优滞后阶数。从表1估计结果可知,方程较好地拟合了序列的趋势。由趋势方程分解得到的个体效应反映了各地区之间的单产差异和价格差异,这种差异不随时间的变化而改变(图1和图2)。

表1 变量趋势方程估计结果
图1表明各主产区晚稻产量地区间差异较大,而中稻和早稻产量地区间差异较小。图2则表明早稻和晚稻生产者价格地区间差异较大,而中稻生产者价格地区间差异较小。虽然种植水稻的收入风险主要来自价格波动,但在多数年份产量的变化对冲了一部分价格波动的负面影响。由于收入等于产量与价格的乘积,因此,利用产量风险和价格风险之间“此消彼长”的联系来设计收入保险,既可以节约保险合约的交易费用又可以保障农户的收入水平。

图1 单产序列的个体效应图

图2 价格序列的个体效应图
三、研究结果
(一)边缘概率密度函数估计
核密度函数有多种不同的表达式,不同的核函数对核密度估计影响不大。采用应用最广泛的正态核函数来估计产量波动和价格波动序列的边缘密度函数。由式(8)计算得到最优窗口宽度,其中早稻单产和价格波动序列的最佳窗口宽度分别为6.13和1.01,中稻单产和价格波动序列的最佳窗口宽度分别为8.71和1.14,晚稻单产和价格波动序列的最佳窗口宽度分别为7.90和1.03。将最优窗宽代入式(7)得到相应的三组边缘密度函数值。
图3报告了由非参数方法得到的密度函数形态。其中,早稻亩产波动最大值为45.16kg,最小值为-49.03kg,标准差为17.27kg,峰度系数(3.20)接近正态分布的峰度,偏度系数(-0.39)表明分布向左倾斜,早稻出现减产的概率高于增产概率。每50kg早稻的生产价格波动最大值为5.44元,最小值为-6.06元,标准差为2.53元,峰度系数(2.69)低于正态分布的峰度,偏度系数(0.02)表明分布略向右倾斜,未来早稻粮价上涨的概率略高于价格下跌的概率。中稻亩产波动最大值为65.82kg,最小值为-126.29kg,标准差为31.51kg,峰度系数(5.46)明显高于正态分布的峰度,偏度系数(-1.17)表明分布向左倾斜,中稻出现减产的概率高于增产概率。每50kg中稻的生产价格波动最大值为6.40元,最小值为-8.14元,标准差为2.71元,峰度系数(3.17)接近正态分布的峰度,偏度系数(-0.22)表明分布向左倾斜,中稻降价的概率高于涨价的概率。晚稻亩产波动最大值为53.98kg,最小值为-67.72kg,标准差为22.47kg,峰度系数(3.18)接近正态分布的峰度,偏度系数(-0.49)表明分布向左倾斜,晚稻出现减产的概率高于增产的概率。每50kg晚稻的生产价格波动最大值为6.67元,最小值为-5.46元,标准差为2.59元,峰度系数(2.61)低于正态分布的峰度,偏度系数(0.30)表明分布略向右倾斜,未来晚稻粮价上涨的概率略高于价格下跌的概率。
从三种水稻产量和价格波动的边缘分布形态来看,种植中稻面临的产量和价格风险高于种植其他两种水稻。早稻的产量风险最低,晚稻的产量风险介于早稻和中稻之间。晚稻的价格风险最低,早稻价格风险介于中稻和晚稻之间。
根据边缘分布律计算出三种水稻产量和价格波动的Pearson相关系数分别为0.151、-0.222和-0.042,Kendall相关系数分别为0.097、-0.115和-0.034,Spearman相关系数分别为0.145、-0.161和-0.044。产量和价格波动的相关特征表明尽管种植中稻面临的产量和价格风险高于种植其他两种水稻,但通过风险的对冲,产量风险可以抵消部分价格风险。对于早稻而言,产量风险和价格风险之间不存在“此消彼长”的关系,两种风险的正相关可能会导致风险的叠加。
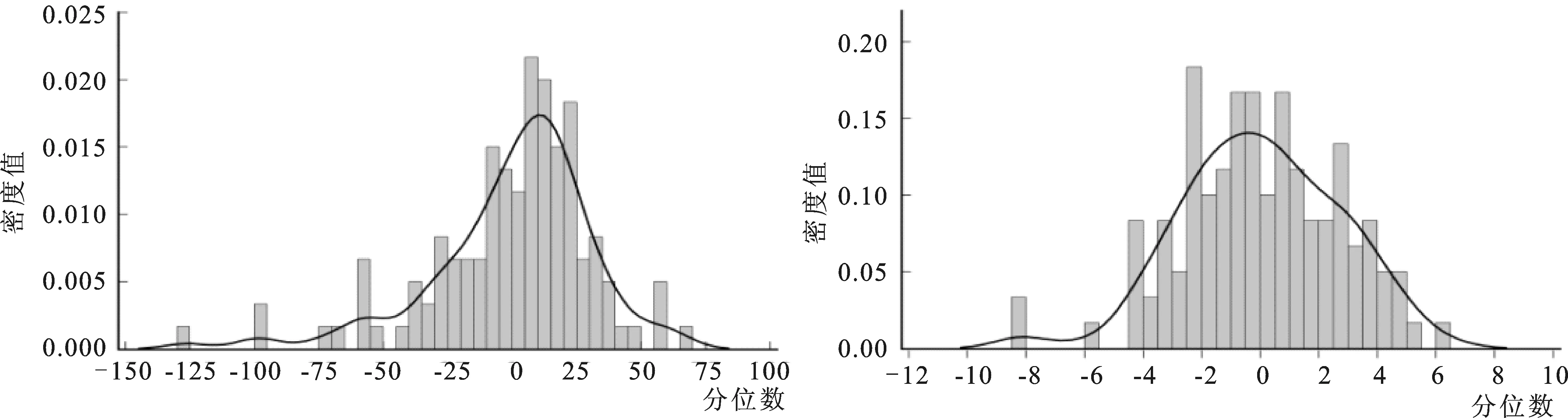
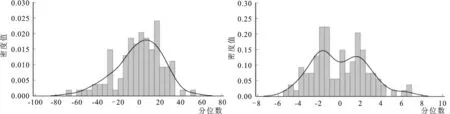
a.早稻产量波动的边缘密度函数 b.早稻价格波动的边缘密度函数c.中稻产量波动的边缘密度函数 d.中稻价格波动的边缘密度函数e.晚稻产量波动的边缘密度函数 f.晚稻价格波动的边缘密度函数图3 水稻单产和价格波动的边缘密度分布图
(二)混合Copula函数估计结果
在估计边缘密度函数的基础上,由式(10)计算了Gaussian、Clayton、Gumbel和Frank四种类型Copula函数的参数及对应的极大似然函数值,并由式(12)和式(13)计算了混合Copula函数的参数及对应的惩罚极大似然函数值。在计算混合Copula函数的参数时,根据验算将惩罚极大似然函数中的参数a设置为3.7时,函数拟合效果最好。
表2报告了联合分布的估计结果。早稻、中稻、晚稻产量和价格联合分布混合模型的似然函数值分别等于3.268、2.007和44.558,平方欧氏距离分别为0.018、0.020和0.032。根据平方欧氏距离可知,与单一Copula模型相比,混合Copula模型对数据的拟合效果更好。因此,水稻的产量和价格波动序列服从混合Copula联合分布模式。混合Copula函数反映了产量和价格序列之间的相关特征。混合Copula的参数估计值表明水稻的产量与价格序列并不具有明显的尾部相关性。基于混合Copula函数生成10 000组数据并计算了三种相关系数,其中,三种稻谷产量和价格波动的Pearson相关系数分别为0.153、-0.191和-0.011,Kendall相关系数分别为0.102、 -0.129和-0.007,Spearman相关系数分别为0.154、-0.192和-0.011。早稻和中稻三种相关系数均在5%的水平上显著,而晚稻三种相关系数在5%的水平上不显著。这表明早稻的产量与价格序列存在正相关性,中稻的产量与价格序列存在负相关性,晚稻的产量与价格负相关性较弱。
为了避免因模型对数据的过度依赖而导致参数不稳定,采用非参数Bootstrap抽样方法,计算了模型参数的95%置信区间(见表2)。95%置信区间覆盖范围小,参数不会因为抽样而产生较大误差,反映了混合模型参数估计结果的信度较高。

表2 水稻产量和价格联合分布估计结果
(三)保险费率厘定结果
在混合Copula函数的基础上分别厘定水稻产量保险、价格保险和收入保险三种类型保险的费率。首先根据表2中三种水稻对应的混合Copula函数作为随机数发生器模拟生成10 000组单产与价格波动概率值,并根据样条函数插值计算出概率对应的单产和价格波动数据。然后利用趋势方程、地区个体效应、波动值得到水稻单产、价格和收入的模拟值。最后通过与实际数据对比,运用式(5)、式(6)计算出水稻产区在不同保障水平下的纯保险费率。
表3报告了2016年部分水稻产区分别由产量、价格以及收入风险引起的预期损失,并报告了90%、95%和100%保障水平下的保险纯费率。从风险因子对应的预期损失对比来看,大部分地区的水稻收入风险带来的损失大于产量或价格风险引起的损失。从水稻品种间的预期损失对比来看,早稻价格风险引起的损失高于产量风险引起的损失,而中稻和晚稻产量风险引起的损失高于价格风险引起的损失。从地区间预期损失的对比来看,发生风险的地区异质性非常明显。福建、广西和河南属于产量风险偏低的地区,江西和河南属于价格风险偏低的地区,福建、河南和广西属于收入风险偏低的地区,江苏、安徽、浙江和贵州属于产量风险偏高的地区,江苏和贵州属于价格风险偏高的地区,江苏、安徽、湖北等地属于收入风险偏高的地区。
江苏、安徽、河南、江西、广西、贵州等地的中稻和晚稻价格风险对冲了部分产量风险。因此,这些地区中稻和晚稻的收入保险费率较低。其他地区的水稻收入保险费率则明显高于产量保险费率。在100%的保障水平下,主产区早稻产量险纯费率为3.05%~6.68%,中稻产量险纯费率为4.73%~13.16%,晚稻产量险纯费率为3.34%~6.89%;早稻价格险纯费率为6.71%~8.63%,中稻价格险纯费率为3.65%~6.01%,晚稻价格险纯费率为3.43%~4.46%;早稻收入险纯费率为8.60%~12.84%,中稻收入险纯费率为5.89%~12.07%,晚稻收入险纯费率为4.59%~7.94%。比较三种水稻的保险费率可知,产量险和收入险的保险费率地区差异性较大,而价格险的保险费率地区差异性较小。
根据已有研究,保险毛费率=纯费率×(1+安全系数)×(1+营业费用系数)×(1+预定结余率),其中安全系数、营业费用系数和预定结余率分别设置为 15%、20%和5%[15]。据此计算出在100%的保障水平下,主产区早稻产量险毛费率为4.42%~9.68%,中稻产量险毛费率为6.85%~19.07%,晚稻产量险毛费率为4.84%~9.98%;早稻价格险毛费率为9.72%~12.50%,中稻价格险毛费率为5.29%~8.71%,晚稻价格险毛费率为4.97%~6.46%;早稻收入险毛费率为12.46%~18.61%,中稻收入险毛费率为8.53%~17.49%,晚稻收入险毛费率为6.65%~11.51%。

表3 部分省份水稻保险纯费率厘定结果
注:预期损失单位为元/亩。
四、结论与讨论
(一)主要结论
收入保险承担了产量保险和价格保险的双重功能。根据价格波动和产量波动“此消彼长”的负相关关系,可以优化保险合约,设计出费率更低的收入保险。借助个体固定效应的面板自回归模型将面板数据分解为趋势项、个体效应和波动项,采用混合Copula模型模拟了价格波动和单产波动的联合分布并计算了不同险种的保险费率。研究得到以下几点结论:(1)与单一的Copula函数相比,混合Copula函数能够更精确地刻画产量和价格波动的联合分布,提升收入险费率厘定的准确性。混合Copula 函数综合了多种Copula函数的优点,便于精确地拟合具有复杂结构的数据。(2)收入保险从产量风险和价格风险两方面保障了粮农的收益。水稻收入保险能够帮助粮农规避产量和价格波动带来的经济风险。与传统的产量保险相比,农业收入保险对农户收入的保障力度更大,也更符合中国新型农业经营主体的需求,是未来农业支持政策的发展方向。(3)在现阶段水稻价格形成机制下,量价之间负相关性较弱甚至表现为正相关性,这使得推行早稻收入保险的成本明显高于产量保险或价格保险的成本。根据测算出的各地区粮农预期损失和保险成本结果可知,江苏、安徽、江西、河南、贵州和广西具备了在中稻、晚稻主产县(市)试点实施水稻收入保险的必要条件。
(二)讨论
在农业保险理论研究方面,陈平、陶建平等测算出湖北省82个县的中稻产量险纯费率在100%的保障水平下平均为5.21%,其中风险最高的团风县为17.33%,风险最低的谷城县为1.38%[16]。在100%的保障水平下,王保玲等测算出中国稻谷收入险纯费率为9.302%,产量险纯费率为11.821%[12];袁祥州测算出中国稻谷收入保险纯费率为7.01%,产量险纯费率为6.16%[17]。本文测算的早稻产量保险费率低于收入保险费率,主要是因为早稻产量风险和价格风险在大多数情况下不存在对冲关系。目前与水稻相关的保险还包括天气指数保险。尽管天气指数险具有数据客观透明且费率较低等优点,但该类保险的保险责任主体仍为气象灾害等自然因素,其对农户收入的保障效果弱于收入保险。
保险理赔的触发值会影响是否赔付和赔付多少,该参数是保险合约的一个关键指标。对于水稻产量险而言,当发生自然灾害导致产量低于保障水平与目标产量乘积时触发保险理赔。对于水稻价格险而言,当水稻价格低于保障水平与目标价格乘积时触发保险理赔。对于水稻收入险而言,当水稻产量或价格下降导致每亩收入低于保障水平与目标收入乘积时触发保险理赔。在农业保险实务中,为了避免出现道德风险和逆向选择行为,一般将试点地区保险标的近三年平均产量作为目标产量,将近三年平均收购价作为目标价格,将目标产量和目标价格的乘积作为目标收入。这一做法的优点在于计算简单且便于农户理解,但由于使用的数据期限较短,会导致厘定的费率偏差较大。以浙江省为例,本研究基于随机模拟得到早籼稻2016年目标收入为1 168.47元/亩,基于三年平均值计算得到的目标收入为1 113.05元/亩。2016年浙江省早籼稻每亩实际收入为1 188.96元/亩。对比可知,基于历史数据的分布特征,通过蒙特卡洛模拟得到单产、价格、收入及其期望值并代入费率公式,厘定的保险费率更加准确。
五、对策建议
农业收入保险具有双重保障、符合国际贸易规则等优点,是农业保险未来的发展方向。市场风险既损害了粮农的收益,又影响了市民的“米袋子”。在分析水稻保险定价的基础上,为发挥农业保险保障收入和稳定生产的作用,提出以下三点建议。
第一,完善农产品生产价格信息的采集和发布机制。政策性农业保险具有准公共品的性质,在费率厘定方面,政府部门应加以指导并提供服务。农业部门应建立权威的数据信息采集系统,及时面向社会公布农业生产、交易数据,为农业收入风险区划、收入保险定价和理赔提供可信的依据。生产价格能真实反映水稻生产成本,更好地保障粮农的利益,收入保险的价格触发应以生产价格为依据。目前国家统计局对各省份农产品生产价格的统计由国家农调队完成并按年度发布。较少的数据量不能很好地为保险精算提供支撑。一方面,相关部门应加大对产粮大县采样频率,覆盖到更多的种植户,并尽可能以县域为单位发布数据。另一方面,发挥批发市场、远期市场、期货市场的定价机制,向保险交易双方提供有效的价格信号。
第二,优化水稻价格形成机制和保险机制。推进水稻价格的市场化改革进程,逐渐恢复产量和价格之间“此消彼长”的市场特征。同时借助市场化工具保障粮农的收入水平。根据水稻种植风险的地区差异,实施灵活的保险定价策略和风险防控策略。应根据水稻产区产量风险和价格风险的特点推行不同的农业保险。结合水稻种植情况和地区财政收入水平向农户提供合适的政策性保险产品,同时在保险合约设计上以农户的风险管理需求为导向。对于种植早稻的地区,应尽快推出规避价格风险的市场化工具。对于财政状况较好的粮食主产区,试点水稻收入保险,并对农户给予保费补贴[18]。在收入保险费率接近或低于产量保险费率的水稻主产区应尽快试点并逐步推广水稻收入保险。
第三,做好地区间的风险补偿和系统性风险防控。推动保险企业在风险较高的水稻产区开展保险业务。一方面,按照市场规律科学厘定水稻保险费率,使保险费率与地区风险水平相适应,保障企业的盈利水平;另一方面,统筹粮食风险补偿基金,基于地区间粮食种植业风险的异质性,运用风险补偿基金加大对预期种粮收入损失较高产区的保费补贴。另外,加强农业风险在时间、空间、品种间和国内外市场间的关联性监测,在全国范围内建立农业大灾风险分散制度,做好系统性风险防控。一是建立中央和省两级农业大灾风险准备基金,并做好基金的运营和保值;二是除了目前开展的再保险业务外,还应通过农业巨灾债券、巨灾保险期权、巨灾保险互换和特别融资支持等金融创新产品疏通农业巨灾风险的融资渠道。
