基于稀疏降噪自编码器的随机森林模型
2019-09-20景英川
武 峥,丁 冲,景英川
(太原理工大学 数学学院,山西 晋中 030600)
一、引言
伴随着新时代的来临,当今的信息技术迈进了高速发展的时期,获取与储存数据越发方便,人们在实际应用中所获得的数据种类也多种多样。在多种不同的数据面前,随机森林在某些情况下会表现出较差的性能,对部分数据无法很好地适应。为增强随机森林算法性能,本文从数据本身入手,对数据的特征提取方法进行改进,主要是运用了神经网络之中的稀疏降噪自编码器对数据中隐含的特征进行精炼提取,并将提取后的特征运用于随机森林。
本文采用了三个数据集对特征提取后的随机森林算法进行分析比较,发现该算法对于一般常见的数据集而言,相比普通的随机森林或者进行主成分数据提取后的随机森林拥有更为优异的性能。
在机器学习的众多算法之中,基本的分类器有许多种类,例如决策树以及支持向量机等算法[1-2]。这类算法被称为单分类器,可能存在过拟合等不足之处。
运用集成学习的方法,将多个相同或不同的分类器进行某种组合,可以获得相较于单分类器而言更为优秀的性能。Bagging以及Boosting是两类基础的集成学习方法[3-4],而随机森林是一类相对比较成熟的多分类器,也是Bagging中运用最为广泛的一类方法[5-8]。
随机森林作为一种多分类器,其主要思想是将决策树作为基本的单分类器,将各个独立的单分类器同时运用Bagging算法进行组合,在变量的选取方面使用了随机属性的选择。随机森林相对于传统的决策树算法,能够在不进行剪枝的同时防止过拟合的出现,同时又具备较快的训练速度且参数调整方便,而且在高维数据处理上,对其分类也有着良好的并行性。鉴于随机森林所表现出的各种出色的性能,该方法被应用于医学、生物学等多种学科的分类预测之中。
自编码神经网络作为深度学习中不可忽视的一个重要内容,是一类无监督的学习方法,对原始数据采用一系列非线性变化后重构成与原始数据相近似的数据[9-11]。假如自编码器之中的隐藏层神经元个数比原始数据的维数小,将会使得自编码器将原始数据维数进行一定的压缩处理。同时,若原始数据之间隐含有某些有联系的结构,那么自编码器也能够很快发掘此类数据间的相关性,在输出层重新构建原始数据。假如使得自编码器之中的隐藏层神经元个数接近或大于原始数据维数,此时就可以对自编码器之中的隐藏层神经元增加适当的稀疏性限制,使得数据变得相对稀疏,可视为对原始数据的一种重构。与此相同的是,在每次应用样本对神经元进行训练时随机激活部分神经元可以令自编码器更具有鲁棒性。
本文将稀疏降噪自编码神经网络与随机森林相结合,提出基于稀疏降噪自编码进行特征提取的随机森林,旨在应用稀疏降噪自编码器的特殊性质,对原始数据进行重新构成,发现原始数据潜在联系,使得数据更容易被随机森林学习。将变化后的特征作为新的特征集,运用随机森林对重构后的特征分类。本文使用两类小样本数据集及一类较大样本数据集对该方法进行测试,选取普通随机森林、主成分随机森林作为参照模型,与稀疏降噪自编码器随机森林进行分类效果的比较。
二、随机森林算法
(一)随机森林算法简介
Leo Breiman于2001年在决策树及集成学习的基础上进行改进并发表了随机森林算法。如图1所示,随机森林利用Bagging算法构建了众多与原始数据集的样本个数相同的训练集,这些训练集全部是由原始数据集有放回地抽取所产生,且各个训练集互不相同。将每个训练集构建单棵决策树的同时进行随机属性选择[12],对其节点采取随机的属性分裂。

图1 随机森林图解
随机森林的分类是结合了所有决策树的结果进行综合投票后产生的,将所获票数占总得票数比值最大的类别视为样本最终的分类,因此随机森林算法在进行数据分析时对于数据的噪声拥有优秀的容忍性,获得优良的分类效果。对于高维的数据而言,随机森林在编程中拥有优秀的并行性。不仅如此,在实际应用中随机森林除了能进行分类、回归以外,还能对缺失值、异常值进行处理。
随机森林拥有许多优良之处:对于许多数据集,其准确率均高于其余算法;在面对较高维的数据时能够进行准确的处理,而且不必对数据的特征属性进行人为选取;训练速度较为迅速,能够利用并行化方法加速运算;即使使用不平衡的数据集,它也能够尽可能地平衡误差;即便缺失较多特征,仍能够保证准确度不降低;由于引入了部分随机性,令随机森林具有更加优秀的鲁棒性。
(二)随机森林理论
设随机森林能够表达为{h(X,θk),k=1,2…,K},K作为随机森林之中拥有的决策树的数量。原始的数据集T为{(xi,yi),xi∈X,yi∈Y,i=1,2,…,N},其中N为样本数,X为含有M个特征的N×M矩阵,Y含有J个互不相同的类别。第k次抽取的训练集记为Tk。
1.泛化误差界。随机森林的泛化误差PE*为:

maxj≠YavkI(h(X,θk)=j))<0)
(1)
PE*是随机森林对于分类错误率的一个度量标准。有如下收敛定理[5]:

maxj≠YPθ(h(X,θ)=j))<0)
(2)
定义随机森林的余量函数mr(X,Y)为公式(3)。同时该函数值越大,标志着随机森林的可信度越大。
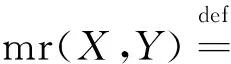
maxj≠YPθ(h(X,θ)=j)
(3)
PX,Y(mr(X,Y)<0)
(4)

s=EX,Ymr(X,Y)
(5)
(6)
结合以上几个公式,随机森林的泛化误差界可化简为式(7):
(7)
2.袋外估计。随机森林有一个独特的优势,不必对它使用交叉验证以得到误差的无偏估计。Bagging的主要思想是在包含有m个样本的数据内,有放回地任意选择m个样本重组为新的数据集。由式(8)可知在原始数据集中大约存在36.8%的样本从未在新的数据集之中被抽取到,这些未出现在采样数据集中的样本可以用来验证学习器的泛化性能,称之为袋外估计[3]。Breiman也在论文中指出,袋外估计是随机森林泛化能力的一个无偏估计。
(8)
袋外错误率(obb error)是袋外估计一种常见的表达形式,具体计算方式为:首先对于每一个样本,使用那些将它作为袋外样本的树(大约为36.8%的树)进行计算,并且统计每棵树的分类情况;其次选择投票最多的类视为该样本的类别;最终使用分类错误的样本数量占所有样本数的比值当作随机森林的袋外错误率。
为检验三种方法在训练集和测试集上的性能,本文使用两种标准对三类不同方法的性能进行度量,以测试误差为主的同时加入袋外错误率作为辅助评价标准。
三、自编码神经网络
自编码器作为神经网络之中一类极为常见的算法,在最近几年内获得普遍关注,而且成功地运用于众多领域,其在数据压缩、特征提取等方面有着十分出色的性能。自编码发展至今,在传统自编码器的基础之上[9,11],已经有了很多的变种方法,比如稀疏自编码器、降噪自编码器等[13-14]。
(一)传统自编码器
传统自编码器一般包括编码阶段和解码阶段两个结构互相对称的阶段,即在存在多个隐藏层的自编码器中编码阶段和解码阶段隐藏层的数量是相同的。图2是一种存在单隐藏层的自编码器,这个自编码器输入一个六维向量,经过编码阶段压缩为三维向量后,再经过解码阶段还原为与输入向量近似相等的六维向量。

图2 自编码网络示意图(1)图片引用自https://blog.csdn.net/on2way/article/details/50095081。
按照图2的结构,传统自编码器的编码解码过程能够表现为以下公式:
h=σe(W1x+b1)
(9)
(10)
其中,x为含有M个特征的一个样本,W1,b1为编码过程的权重项和偏置项,W2,b2为解码过程的权重项和偏置项,σ为一类非线性变化,通常使用的函数是sigmoid、tanh、relu等。解码过程的σ可以是编码过程相同的非线性变化或者仿射变化。
(11)

(12)
由于在编码以及解码的过程当中,自编码器未涉及关于数据的标签信息,因此自编码器是一类无监督的神经网络。对于传统的自编码器,隐藏层有三种互不相同的表现:压缩结构、稀疏结构和等维结构。这三种结构通常是按照隐藏层之中的神经元的个数进行划分的,当原始数据的维数大于隐藏层神经元个数时称为压缩结构;反之称为稀疏结构;若原始数据的维数等于隐藏层神经元个数时,则称之为等维结构。
压缩结构能够对原始数据进行压缩,若原始数据之间隐含某些有联系的结构,自编码神经网络就能够发掘出它们之间的相关性,并在输出层重构原始数据。而稀疏结构的作用是在隐藏层神经元之中加入一定的稀疏性限制,使得重构之后的数据具有优秀的稀疏性;同时,能够对原始数据进行干扰,人为施加噪声使得网络更加具有鲁棒性。
(二)改进自编码器
1.稀疏自编码器。当自编码器之中的隐藏层节点比输入的原始节点数目多时,应当人为地对隐藏层实施一定的约束。
Andrew Ng认为高维并且稀疏的表达是优秀的,因此本文在损失函数中加入惩罚项将隐藏层的节点进行稀疏性限制。为了实现限制效果一般使用KL散度或者L1,L2正则化迫使神经元稀疏化,并且将其作为惩罚项加入损失函数之中。
如果通过稀疏化后的神经元仍能完美重建原始数据,那么说明这些稀疏表达包含原始数据的大部分特征,能够看作是对原始数据的一种简单表达,这样使得模型的性能获得优异的改善。
本文使用加入L1,L2惩罚项的损失函数对数据进行稀疏性处理并防止数据的过拟合。在这里稀疏自编码的损失函数能够近似地改写为以下公式:
(13)
其中L1范数作为稀疏惩罚项使数据能够稀疏表达,而L2范数的加入能够避免数据产生过拟合现象。
2.降噪自编码器。降噪自编码的提出是受到了人类对被遮挡的事物仍然能够进行较准确的判别这一现象启发。假如某个模型拥有优秀的鲁棒性,那么部分缺失的数据在隐藏层上的表达应该同无缺失的数据几乎相等。

(14)
降噪自编码器通过人为地在原始数据之中施加少量噪音,避免了隐藏层神经元在学习过程中学到没有意义的恒等函数,同时得以学习到一个更具有鲁棒性的表达。
四、基于自编码特征提取的随机森林模型实验
(一)实验目的
为改善随机森林的性能,本文从对原始数据特征的重构入手,结合深度学习中应用较为广泛的自编码器对数据进行深层次改变。在改变数据的特征结构的同时进行特征提取,将特征提取后的数据进行随机森林预测。
因为稀疏自编码器具有良好的泛化性能以及稀疏性,降噪自编码拥有较为优秀的鲁棒性,因此本文采用的模型结合了稀疏自编码与降噪自编码的部分优点,利用稀疏降噪自编码器对原始数据进行重构,使得重构后的数据具有优秀的性能,采用了大于或近似于原始数据维数的隐藏层神经元个数。
当模型运用较大的隐藏层神经元时,可以令其具有更加优异的表达能力,然而于此同时会产生过拟合的状况,因此要进行一定的限制,通常采用添加约束条件的方法。经过限制的多隐藏层神经元模型和较少隐藏层神经元的模型相比仍然拥有很强的表达能力,但是又避免了过拟合的情况。并且,由于不为零的权值较少,因此神经网络只能够使用较少的神经节点以学习到神经网络的总体信息,这样会使重构数据变得稀疏并且被学习的特征仍旧拥有很强的代表性。稀疏降噪自编码的损失函数可以表示为:
(15)
为了验证稀疏降噪自编码器处理后的随机森林算法(以下简称EN-RF)的可行性和适用性,本文收集了三组经典的分类数据集。为表现本文算法的优势,同时构建随机森林算法(RF)及主成分分析处理后的随机森林算法(以下简称PCA-RF)[15],同使用稀疏降噪自编码器处理后的随机森林模型进行对比。
如果基于稀疏降噪自编码器的随机森林模型在分类预测效果上优于其他两种算法,则说明此方法在分类问题中是适合并有效的,能够用于实证研究。
(二)实验数据及主要过程
1.实验数据。本文选用的三种经典数据集均来自UCI,分别为banknote authentication Data Set(以下简称BA)、Connectionist Bench Data Set(以下简称CB)以及经典的MNIST数据集,其中MNIST数据集是一组常用的多分类样本量较大的稀疏数据集,其余两组数据集为小样本量的二分类数据集。
在实验中将三者的训练集进行随机分割,每次测试将其中20%的样本数据视为测试集,其余的视为训练集,重复进行100次实验。数据集部分重要信息见表1。
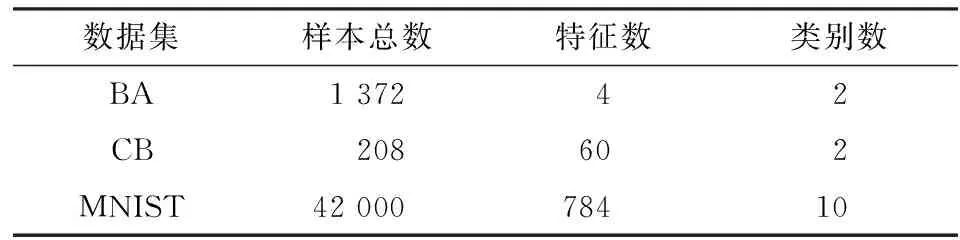
表1 实验数据信息
这三类数据集包括了二分类及多分类问题、普通数据集及稀疏数据集、样本量较少的数据集及样本量较大的数据集。三类数据集包含了常见的分类情况,本文利用稀疏降噪自编码随机森林对这三类数据集进行分类,同时加入随机森林以及主成分随机森林进行结果对比。
2.主要过程。本文利用Python语言,对三类经典数据集分别应用普通随机森林、主成分随机森林作为参照模型,对稀疏降噪自编码随机森林进行分类效果比较。
为获得合适的随机森林参数,本文采取了交叉验证的实验方法对随机森林参数进行选取。在每一个数据集上,分别对原始数据集、主成分降维后的数据以及自编码重构后的数据进行交叉验证,在所获取的最佳属性中选取较为合适的属性作为该数据集随机森林的最优属性。
对于主成分分析中的特征选择,对所有数据集统一按照累计方差贡献率提取因子。将因子按方差贡献率由大到小排列,且累计方差贡献率大于98%。对于稀疏降噪自编码的特征选择,本文选用了稀疏降噪自编码器对原始数据进行一定的重构,部分参数见表2。

表2 部分参数信息
(三)实验结果及分析
1.实验结果。本文使用所选的数据集重复100次随机实验,每次实验过程中均将原始数据集依据固定的比例随机分割成为训练集及测试集。为直观显示结果,本文将100次实验所得测试误差以及obb error进行图像拟合。将结果进行展示,见图3~5。
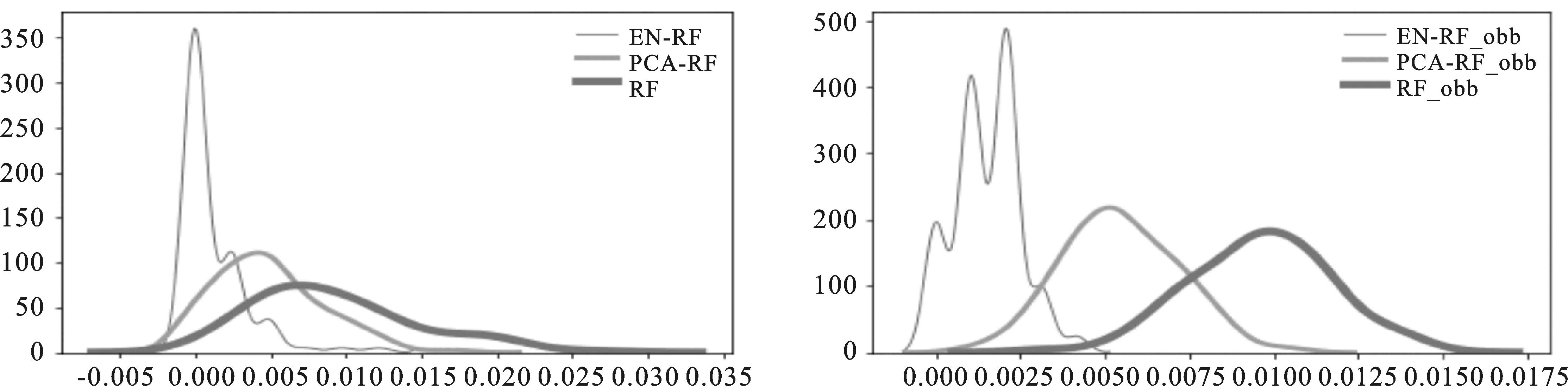
图3 钞票数据集实验结果

图4 声纳数据集实验结果
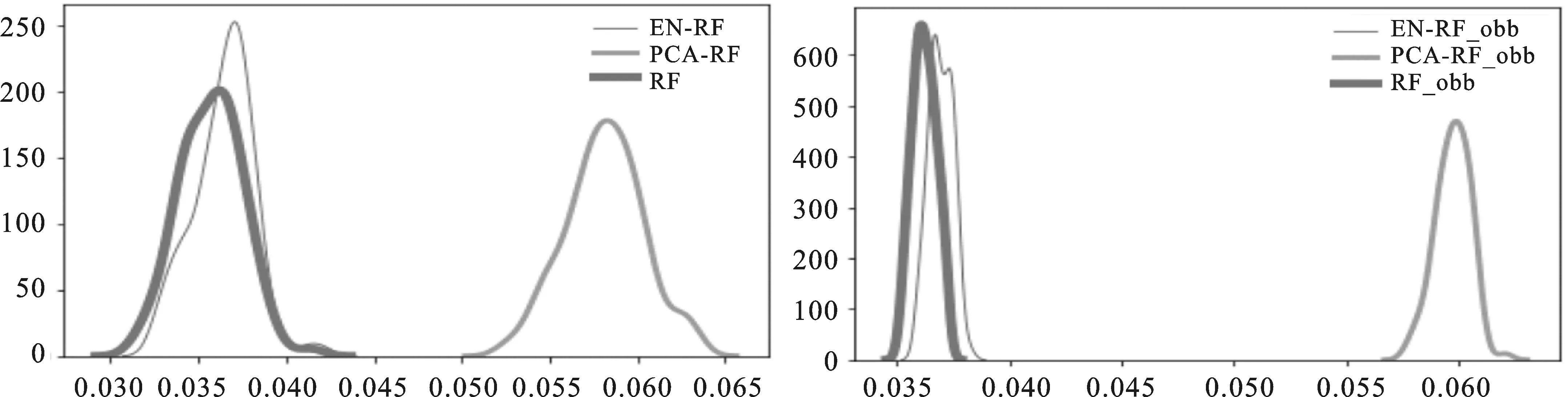
图5 MNIST数据集实验结果
本文将100次实验数据的测试误差取平均值,分析各方法的优劣。实验结果见表3。
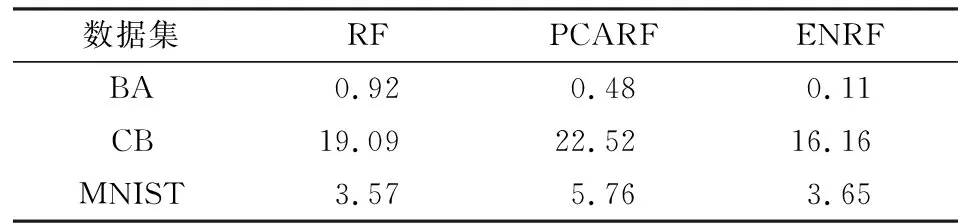
表3 测试误差 单位:%
2.结果分析。通过以上实验结果的展示,能够看出无论选取测试误差还是obb error值作为评判标准,在维数较少的数据集中,本文的算法性能优势更为明显,而在MNIST数据集上,该算法同未经数据处理后的随机森林算法表现接近。尽管普通随机森林在BA数据集上的分类效果已经足够好了,但本文采用的算法依旧具有少量的改善效果。并且,由于本文所用到的参数较多,导致部分参数未调整至最好,因此算法依然具有一定的进步空间。
比较三种方法,普通随机森林在高维或低维数据中均有不错的表现。运用主成分分析进行特征选择的随机森林在实验中表现不理想,且由于主成分方法的限制令其无法运用于更高维的数据中。相对而言,运用自编码进行特征选择的随机森林在高维或低维数据集上均能取得理想的结果且综合优于随机森林算法,因此认为自编码随机森林是可行的,同时其适用性较为广泛。
自编码器作为神经网络之中一类极为常见的深度学习算法,虽然进行稀疏性处理可以消除部分过拟合的影响,但不可避免地有时仍然存在过拟合等问题。这主要是由于在进行自编码时数据无监督,导致了自编码产生较大偏差,具体表现为在参数调整的过程中出现了过低的准确率,而这种过低的准确率是能够排除的。随着稀疏自编码调参过程,准确率过低问题出现频率有着明显降低,但如何将这种问题解决仍需要做进一步探讨。
五、结论
面对如今多样的数据集,本文将随机森林中原始数据的特征选择做为主要思路,提出了应用稀疏降噪自编码器将原始数据进行重构的随机森林模型。该模型采用了改进的稀疏降噪自编码器对原始数据进行等维或稀疏重构,由于该自编码器泛化能力较强且拥有优秀的鲁棒性,重构后的数据相较于原始数据更为稀疏且可以展示原始数据之间的内在联系,较好地减小了各个属性之间的相关性,使得数据更容易被随机森林学习。
本文通过实际的数据集,说明了稀疏降噪自编码重构的随机森林方法的有效性及优越性。其无论在小样本数据集还是大样本数据集中均存在良好的表现,证明稀疏降噪自编码重构的随机森林方法具有较强的适用性。
本文方法仍存在许多应当进一步改良的地方:第一,自编码器是深度学习中的一类重要分支,虽然在处理过程中加入惩罚项及噪音防止过拟合,但仍不可避免地存在部分过拟合的情况。虽然随着稀疏自编码调参过程的进行,准确率过低的问题出现频率有着明显降低,但如何将这种问题解决仍需要做进一步探讨。第二,虽然随机森林的调参工作是由计算机完成,但自编码调参无法由计算机完成,需手动调参。这主要是由于自编码作为一类经典的无监督学习方法,无法对参数好坏做出评价。因此,应当更加密切结合深度学习中的知识,设计一个有监督的学习,使总体的大部分调参工作能够由计算机完成,并且有监督的学习能够更好地适应数据本身的情况。
在以后的研究中,我们不妨考虑以下几个方向的发展:通过改进自编码器的模型,使其能够对某些特殊的数据具有更加优秀的特征提取能力;随机森林是一类强大的并行算法,自编码同样能够进行并行运算。为应对当今的大数据挑战,将随机森林同自编码更有效地结合起来,能够在算法上大幅度提高效率和性能,令该算法得以运用到大数据之中;自编码作为一类经典的无监督学习方法,应当结合深度学习中的内容,从而构造一个有监督的方法,令自编码学习到更多有用的数据间的内在联系,使得算法精度得到提高。
