公路选线中的嵌套山体自动提取技术
2019-09-19王长海肖亮亮
王长海,肖亮亮
广西交通设计集团有限公司,广西南宁 530029
数字高程模型(digital elevation model, DEM)中包涵海量和多样的地形特征与构造信息,是对地形地貌特征和水文地质等信息的空间变化进行定量描述的基础数据[1],也是自动划分地形地貌类型的数据源. 以DEM数据为基础,以数字地形分析 (digital terrain analysis, DTA)等相关的数字技术为手段,通过提取分析各类地形地貌特征属性,自动划分特征地貌的各种类型,对地貌的自动分类研究有重要价值.
过去人们常常利用目视解译和人工判读辅助野外实地勘察实现地形地貌单元的分类, 基于手工目测勾绘出地貌的实体界线. 该方法精度较高,但耗时长且工作量大,无法快速提取大范围的地貌信息. 此外,还受制图人员主观因素影响,人工制作的地貌界线难以保持一致[2]. 在数字地形技术快速发展的前提下,人们已可通过计算机等工具实现地貌单元的自动或半自动划分. 对象和尺度是地形分类中最重要的两个因素[3],然而基于DEM以对象为单位实现对山体对象的提取仍处于研究之中[4].
传统地貌类型分类方法过分强调地貌单元的完整性,且无有效的地形地貌实体单元自动提取方法. 本研究针对这个难题,提出了一种基于DEM的山地、平原和嵌套山体界线的自动提取方法,利用坡度等地形因子以及水文分析等相关方法,能够实现嵌套山体界线和山地、平原的自动化提取.
考虑地形地貌环境是公路选线设计的重要原则之一[5]. 将山体提取结果应用到公路选线中,通过将各种地形影响因子转化为成本数据集,可以快速、自动地选出最优路径[6]. 相比于仅考虑微观地貌因子,同时顾及地貌实体单元完整性的选线结果更加符合实际,这对于减少公路初步选线工作量、优化公路选线方法具有重要意义.
1 地形形态划分
如何划分地貌形态的类型直接关系到地貌生产利用及地貌形态的认知科普等问题[7]. 人们通常基于局部地形的常识来进行地形地貌分类,通过大量从定性到定量的研究形成了多个地形分类体系和标准,主要包括基于地貌学、水文学、自然地理学和土壤学等分类体系.
1.1 地形形态划分体系
地形地貌的分类始于人们对局部地形的主观认识,主要包括基于水文学、自然地理学、土壤学及地貌学等分类体系.
基于水文学的分类体系主要根据地形所受的水文冲刷侵蚀的不同程度,基于纵坡面的坡长、坡宽及坡度,将地形坡面分为山肩、山顶、背坡、趾坡、麓坡和冲击地等.
根据自然地理学,地表形态差异必然引起各种自然地理现象及过程的变化[8]. 宏观上,地形可划分为平原、丘陵、高山、低山和高原等类型; 微观上,斜坡可划分为缓坡、中坡和陡坡等. 这种划分体系完全是以坡度为划分指标,常见的有以15°、25°和45°为临界值对坡体进行连续划分. 因为坡度是地形表面的单点属性之一,所以这种分类体系对于利用栅格DEM实现地貌单元的划分十分有利,本研究对平原、山地的划分也利用到了这一划分体系.
基于地貌形态学,将地形形态特征作为研究对象,依据描述要素的空间组合与分析比对来进行特征地貌的获取[9]. 基于这种方案,任何复杂的地形地貌均可以划分成3种类型的要素,分别为平地、洼地和坡地.
1.2 地形形态分类指标
利用DTA技术基于DEM来实现地形地貌的自动分类必须要给计算机确定的解析规则和规范,也就是必须有确定的分类指标,即用于描述地貌的地形因子. 地形因子是地形信息的载体和最重要的表现形式,也是地形地貌在某一方面的特征的数字描述. 因此,各种地形因子的准确提取对地貌学研究具有重要价值. 地形因子通常可以分为宏观地形因子和微观地形因子,如图1所示.

图1 地形因子分类框架Fig.1 Classification structure of terrain factor
1.3 地形形态分类方法
地貌类型划分时,将人为经验与地貌分类的量化指标进行结合,从而判断出地貌的实体单元类型,这是人工判读分类中的常用方法. 此方法在分类时人为的主观因素仍然占有很大部分,无法进行严密而又精确的地形分类. 黄杏元[10]提出了地形分类决策表方法,首先基于区域地形地貌的特点形成地形分类决策表,获得分类时所需的地形要素,然后基于DEM进行地形要素提取,再进行地形类型的自动提取,即可获得区域的地貌类型,如图2所示. 该方法为基于DEM自动提取地貌类型提供了最基础的方法,并且分类过程简单、快速. 高玄彧[11]提出一种以相对高度为主,绝对高度为辅的地形分类方法. 这种分类方法避免了其他一些分类方法中与人们的观念相悖的低山不低、高山不高的现象,符合人们对于高山、中山和低山等的观念.

图2 自动提取地形信息[10]Fig.2 Automatic extraction of terrain infomation[10]
本研究认为,基于栅格DEM利用DTA技术对地貌形态进行划分的核心问题,在于如何准确并且高效地从DEM中提取地形因子,如何利用地形因子准确表达各种地形地貌. 不同的地形形态分类方法有各自的侧重点,可以根据具体的应用目的选择不同的分类方法. 但是不管选用什么分类方法,最为重要的还是准确计算地表形态要素和拟定有效的地形分类决策方案.
2 地形因子的计算
2.1 坡度和坡向的计算
坡度(slope)和坡向是描述地形复杂度的重要指标,并且相互联系. 坡度是地表高度变化率的度量,直接反映斜坡的倾斜程度. 坡向则是斜坡方向的度量,用于反映斜坡所面对的方向[12]. 坡度是地表在某个点的倾斜程度,是经过该点的地表微分单元的法矢量n与z轴的夹角,即
(1)
在进行坡度的实际计算时,一般采用简化的差分公式,即
(2)
其中,fx是x方向的高程变化率;fy是y方向的高程变化率.
地表上的任意一点均有坡度,其单位一般为“度”或“坡度百分数”. 由坡度计算示意图(图3)可知,坡度百分数为(h/d)×100%, 度为arctan(h/d). 斜坡所面对的方向是坡向,通过某一点法线正方向的平面投影和正北方向之间的夹角则为该点的坡向[13]. 坡向α的数学表示为
(3)

图3 坡度计算示意图Fig.3 Slope calculation schematic
差分坡度和坡向的计算原理见图4,设中心格网点(i,j)的坐标为(xi,yj), 局部地形曲面设为z=f(x,y), 格网间距为g.

图4 差分坡度和坡向计算原理Fig.4 The calculation principle of differential slope and aspect
则有二阶差分公式为
(4)
2.2 水文因子的计算
水文因子指在流域分析或者水文分析中所涉及到的一些与地形有关的因子,如水流长度、水流方向、河流网络和汇流累积量等.
洼地是DEM局部地形单元, 被较高的高程所包围. 在DEM中的洼地是由数据采集和内插时的误差造成的,称为“伪洼地”. 在进行数字地形的分析时,地形特征线提取的正确性将受伪洼地的影响. 因此,在进行水文因子分析之前需要对DEM进行无洼地化处理,尽可能地减少“伪洼地”的影响,确保所提取的地形特征线能够保持良好的连续性,且无离散的点及局部的短线. 一般通过将洼地边缘的最小高程值赋以洼地区域中的每一个格网点,从而达到填平洼地的目的.
基于格网DEM的水流分析,其水流方向就是水流离开格网时的流向. 在流域分析中,八方向法是当前被广泛使用的确定流向的方法,该方法将像元的流向指向其周围8个像元中距离权重坡度最大的像元(图5). 该法的局限性在于不允许水流分散到多个像元[14].

图5 水流方向计算Fig.5 The calculation of flow direction
通过计算中心像元与其8个邻域像元的距离权重坡度,可以确定图5(a)的中心像元流向. 对于任意4个紧邻的像元,把其中心像元与邻接点的高程差除以1,可计算得到其坡度. 对于任意4个角落的邻接像元,其坡度计算则是用高程除以1.414,如图5(b). 结果显示,最陡的坡度是从中心像元到其右侧像元,因此为流向. 八方向法在回流区和边界明确的峡谷地区能够获得较好的结果[15].

图6 汇流累积量计算Fig.6 The calculation of confluence accumulation
区域地表的每点流水累积量用汇流累积量数矩阵来表示. 在进行地表径流的模拟时, 通过水流方向可以计算得到汇流累积量. 汇流累积量的计算过程如图6. 图6(a)为已填洼的DEM,图6(b)为水流方向栅格,图6(c)为汇流累积量栅格. 图6(c)中2个阴影栅格的流量累积值同为2. 其中,上面的栅格像元接受来自它左边和左下方像元的水流,下面的像元接受来自其左下方像元的水流,且其本身已有流量累计值1. 利用水流方向栅格,汇流累积量栅格列出流经它的像元数,每个格网记录了有多少个上游的像元将水排给它(不包括被计算的栅格像元本身).
通过汇流累积量栅格可以用两种方式来解释:① 汇流累积量高的像元,一般对应河道,而山脊线的像元累积量通常为0;② 若乘以每个像元的大小,则其像元值就是排水面积.
3 实验研究
3.1 实验数据介绍
本研究利用ArcGIS实现对平原、山地高效准确的提取. 由于四川盆地的地形特征整体地形四周高、中间低,呈盆地地形,西部为高原山地,东部为盆地. 盆地内的地形主要是丘陵和平原,平原和山地的地形特征较为显著. 因此,本实验采用的数据源是四川某地区的90 m和30 m分辨率的栅格DEM.
3.2 平原/山地自动划分
为了实验需要,裁减了部分比较典型的山地和平原的地形数据,原始数据是img格式的栅格DEM,具体实验数据如图7所示.

图7 实验样区数据Fig.7 (Color online) Experimental data
根据《中国1∶100万地貌制图规范》[16], 丘陵和山地指的是图斑最高点与图斑边缘最高点的高差大于30 m坡度大于7°(一般大于10°)的形态. 根据平原的构成形态,平原可抽象为多个坡度在一定阈值内、相互连接且达到一定面积的坡面所共同组成. 本研究同时对坡度、面积两个指标进行综合考虑,通过设置恰当的阈值来进行山地和平原的区分. 为此,本研究还设计了相应的计算流程来进行平原/山地的自动划分.
通过多次试验与反复对比后,本研究最后确定的坡度阈值为8°,即将原始坡度栅格重分类为0°~8°和8°~90°两类,此时可以较好地判别山体与平原的界线. 然后通过统计各个区域的面积,并确定面积阈值. 根据制图要求,在1∶100万比例尺下成图最小的图斑所对应的实际面积约为4 km2,但考虑本研究地区地形地貌的结构特点,并经反复实验及对比目视结果,最后确定本研究区域的面积阈值为8 km2. 由于自动提取的结果与实际地形有一定差异,在自动提取地貌单元之后,还要结合专家知识来进行制图综合,最终划分结果如图8所示.

图8 山体、平原划分结果Fig.8 (Color online) The classification results of mountain and plain
3.3 嵌套山体界线提取
一般情况下,平原和山地的划分并不能提取山体之间的嵌套关系,因此,需要对嵌套山体界线做进一步的划分. 根据制图规范,若两个相连的山体单元两侧图斑与垭口的最大海拔高差大于500 m,原则上应将该山体单位划分为两个实体. 根据些规则对山体进行划分仍需要相应的先验知识,但它为我们提供了划分嵌套山体界线的思路.
分界点位置的计算是山体界线提取的关键,得到分界点的位置后,各分界点之间的连线即为山体的分界线. 如图9(a)所示为相邻的山体剖面图. B和D是垭口点,A、C和E是各山峰顶点. A到B的垂直距离为a, B到C的垂直距离为b, C到D的垂直距离为c, D到E的垂直距离为d. 假设a>500 m、b>500 m、c<500 m和d<500 m. 根据前面的定义,如果垭口两侧的最高海拔高差大于500 m,那么此处应该为山体的分界点. 但是B点和D点的情况则不同,两侧的山峰顶点到最低点垭口的距离一侧大于500 m,一侧小于500 m,根据上述规则此处不是山体分界点. 所以,根据a、b、c和d的长度及其相互关系,可以判定某一垭口点是否为山体的分界点,进而可以将山体分界点的垭口点的求取,转化为求取a、b、c和d的长度[17].

图9 山体分界点判别方法示意图[17]Fig.9 Schematic of the cut-off point discrimination method[17]
然而,实际的山地情况比上述情况要复杂的多,在三维空间范围内,山体在各个方向都有相邻的连接的山地,因而求解山地分界点的过程变得十分复杂. 若把山体倒转,则需要将进行判别的垭口点转化成倒转后的山顶点,但其判别的规则不变. 如图9(b)所示,该地形为图9(a)中倒转的地形. 从这个角度看,可以将问题转换为对直观水流现象的分析. 如图9(b)所示,山体倒转后将会成为盆地. 由于在a、b、c、d中d最小,如果不断有水从上方流入该区域,随着水量增多,当水量超过盆地的容量后,即淹没深度超过d以后,E点出盆地中的水就会流向C点;同理,由于a、b均大于500 m,故当淹没深度达到500 m时,A、C两处盆地中的水流相互独立且互不连通,则B为山体的一个分界点.
因此,根据以上描述,通过将地形倒转,借助水文淹没分析,可以将判别规则从二维情况推广到三维情况,再结合汇流累计量等水文因子,即可实现嵌套山体界线的提取. 具体实验区域的数据展示如图10所示.

图10 实验区域数据Fig.10 Experimental data
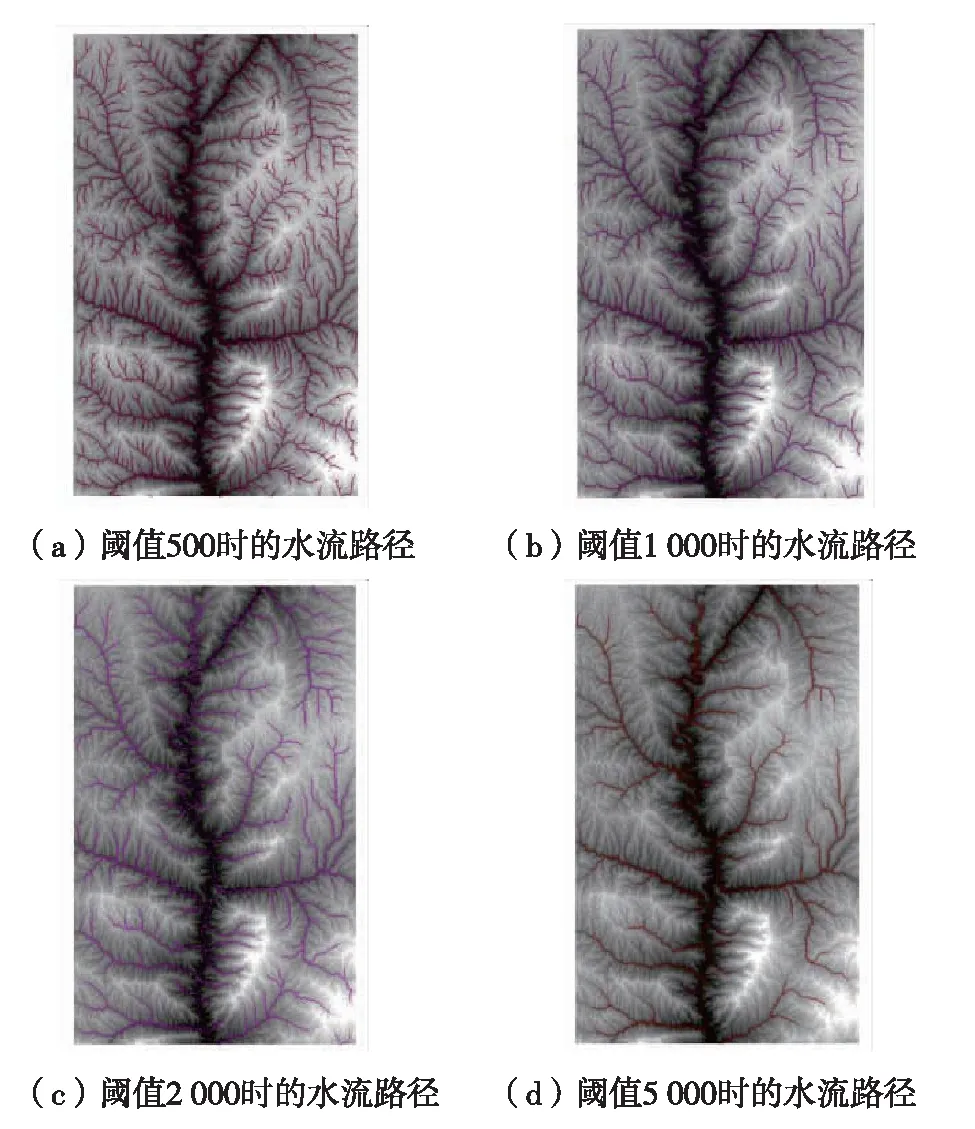
图11 不同阈值所对应的水流路径Fig.11 (Color online) Flow path corresponding to different thresholds
基于倒转地形的水文淹没分析,将最大海拔高差低于500 m的盆地都填平,依据山体判别规则,可以消除掉不满足的垭口点. 再由汇流累积量得到水流路径,然后通过设置不同的汇流累积量阈值得到不同级别的水流路径. 不同级别的水流路径对应不同的阈值,不同级别的水流路径作为不同等级的嵌套山体的划分界线. 不同阈值提取的水流路径如图11所示. 实验结果表明,通过设置合理的汇流累计量阈值,可以得到较好的嵌套山体界线的划分结果,分界线较好地反映了山体的结构特征.
由图12可见,采用本研究方法提取的山体界线与依据专家知识手工勾绘的山体界线吻合较好. 当阈值设置为5 000时,根据水流路径和图廓边界可以得到最高级别的山体界线,可以将实验区域的山体划分为5个部分. 当阈值设置为2 000时,又可以将该区域的山体再次划分为4个子区域山体,依此类推,根据其他阈值得到的水流路径可以得到其他较低级别的山体界线,由此便实现了嵌套山体界线的提取,如图12所示.
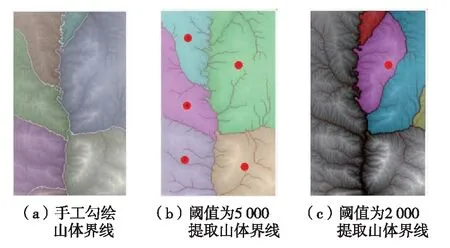
图12 嵌套山体界线Fig.12 (Color online) Nested mountain boundaries
在提取嵌套山体界线时,依据上述方法,较好地实现了第1等级和第2等级的山体界线的提取,但对于更低等级的嵌套山体界线,由于基于水流路径的提取存在某些界线无法闭合的问题,因此仍需综合利用专家知识、地貌特点和参考特征线等信息,进一步调整和修改自动提取的界线.
3.4 公路选线
利用ArcGIS的空间分析功能,基于DEM数据,综合考虑地形、坡度和河网分布等各类地形因子信息,再分别按照对地形的不同影响,将其重新分为10个等级. 同时,将实验区域整体的山体与平原的分布情况考虑在内,利用平原与山体划分实验结果,连同将上述微观地形因子数据集作为公路选线的综合成本数据集. 根据文献[6],坡度、起伏度及河网分布对公路选线影响的重要性依次为“坡度>起伏度>河网分布”. 由于宏观的山体、平原分布情况,是从宏观角度考虑地形起伏对公路选线的影响,相比微观因子,其在实际公路选线中作为预先初步判断条件,因此将其实验重要性排在河网分布之后. 在此基础上,选定起点和终点,利用ArcGIS计算得到距离成本数据集与方向数据集,如图13所示. 最后,再执行最短路径功能得到公路选线的最优路径. 实验结果如图14所示.

图13 距离成本数据集Fig.13 (Color online) Distance costs dataset
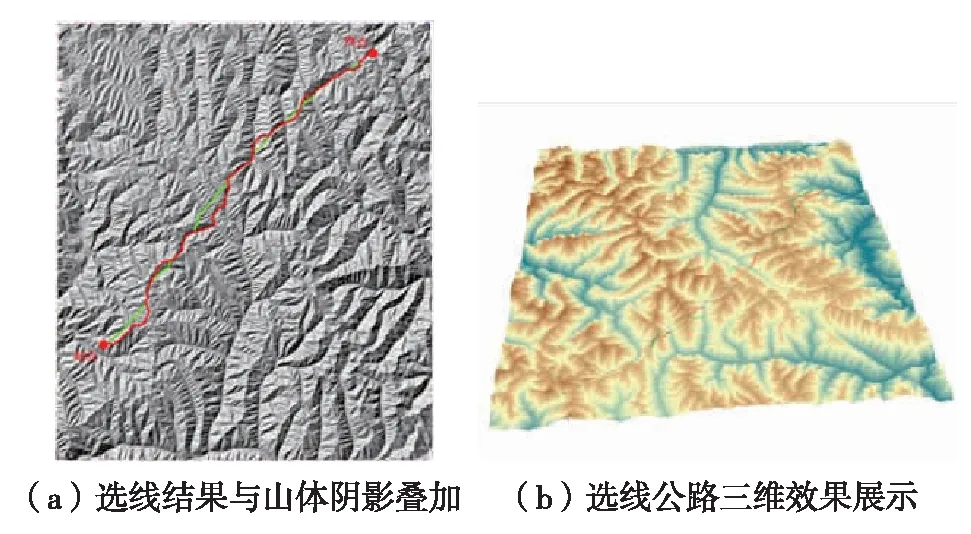
图14 公路选线结果Fig.14 (Color online) Highway route selection results
根据实验结果,利用地形分析的手段进行公路选线,在计算成本数据集时,顾及宏观山体分布因子与否得到的公路选线结果出现了一定的偏差. 如图14所示,从选线结果路线长度来看,估计宏观山体因子得到的选线结果,路线长度比为顾及宏观山体因子得到的路线更短,并且路线更为笔直,弯曲更少. 从路线经过的地形看,顾及宏观山体因子得到的结果所经过的地形相对更趋一致,路线连续的起伏相对较少. 总体来看,相比未考虑宏观山体因子的结果,估计宏观山体因子的公路选线结果更为合理.
结 论
本研究基于DEM数据,通过数字地形分析方法,利用面积和坡度两个指标,计算出大于一定阈值的坡度,且相互连通的栅格的面积,实现了山地和平原的自动划分. 研究利用水文淹没分析法消除了不符合山体判别规则的山体垭口,且利用水文分析的相关方法,通过设置合适的汇流累计量阈值,较好地实现了山体界线的自动划分,实验结果与依据专家知识手工勾绘的结果相比,取得了良好的效果. 基于该方法提取的山体界线,结合专家知识加以修正及制图综合,能够加快地貌制图的速度,提高地貌基本形态类型的分类精度,为大面积地貌信息的高效提取与综合利用奠定基础. 最后,本研究基于山地和平原的划分结果,分别在顾及宏观山体因子与否的情况下进行了公路选线实验. 从实验结果来看,与传统只考虑微观地形因子的公路选线结果相比,顾及宏观山体因子的公路选线结果更为合理,可以为初步的公路选线提供更加可靠合理的结果,大大提高公路选线的工作效率.
本研究所采用的方法在嵌套山体提取时,坡度和汇流累积量阈值的确定以及山体界线的闭合需要一定的人工干预,存在自动化程度不足的问题. 在以后的研究中拟增加曲率、鞍部点和山脊线等指标,拟通过建立地形对象的层次关系,真正实现以对象为单位的地貌实体界线的自动化提取. 在公路选线中,拟增加地质条件、土地利用等因素,同时研究不同因素对公路选线成本的权重,得到更加合理的公路选线结果.
