基于多层忆阻脉冲神经网络的强化学习及应用
2019-09-15张耀中胡小方周跃段书凯
张耀中 胡小方 周跃 段书凯
强化学习,是智能体通过与环境交互、试错的过程来学习的行为.它是一种以环境反馈作为输入的自适应的机器学习方法[1],目前已广泛应用于控制科学、运筹学等诸多领域[2−3].在强化学习过程中,智能体最初对环境一无所知,通过与环境交互的方式获取奖赏.智能体在这个过程中学习策略,使得最终能在某种评价体系下达到最优目标.Q 学习是一种典型的无需模型的强化学习算法,智能体根据动作价值即Q 值函数,通过对状态–动作序列进行足够多的访问,学习到最优策略[4].通常,在Q 学习任务中,Q 值函数由表格的方式实现,在状态为连续值的情况下,则通过离散化状态以存储动作价值,然而传统的表格法有如下缺点:1)状态的离散度难以控制.2)状态维数较多时会导致维数灾难.
将神经网络作为Q 值函数拟合器可以有效解决以上问题.神经网络可以分为三代:第一代把McCulloch-Pitts 神经元模型作为计算单元;第二代为人工神经网络(Artificial neural network,ANN),它们的计算单元中带有激活函数;脉冲神经网络(Spiking neural network,SNN)将脉冲神经元作为计算单元,被称为第三代神经网络[5].SNN 的学习方式与哺乳动物的学习方式非常类似[6].此外,SNN能量效率高,有报道证明SNN 芯片比用现场可编程门阵列(Field programmable gate array,FPGA)实现的ANN 能耗低两个数量级[7].因此,基于SNN的强化学习算法更容易进行低功耗–硬件实现.
与ANN 类似,SNN 的学习算法也分为监督学习算法和非监督学习算法.非监督学习算法仅仅基于数据的特征,这类算法对计算能力要求较低,因为不需要数据集的多次迭代,脉冲神经网络中典型的非监督学习算法是脉冲时间依赖可塑性(Spiketiming dependent plasticity,STDP)学习规则[8].而监督学习算法需要带有标签的数据集,需要多次迭代运算,主要有远程监督学习算法(ReSuMe)等[9].
目前许多训练SNN 的学习算法都只能用于不含隐含层的网络,且没有通用的方法[10].对于训练多层SNN,一种方式是先训练ANN,再将其转换为SNN[11],这种基于映射的学习方式会导致局部最优,因为训练在ANN 上进行,而不是SNN[12].也有人提出了利用突触延迟的监督学习算法,并行调整隐含层和输出层权重[13].由于本文基于多层SNN 实现强化学习算法,因此设计有效的多层SNN 的训练方法是一个必须要解决的问题.
基于传统半导体器件和集成技术实现的神经网络电路复杂度高、规模小、处理能力有限,难以真正用于嵌入式智能体.本文进一步引入新型纳米信息器件忆阻器,探求强化学习算法的硬件加速新方案.忆阻器是除电阻、电容、电感以外的第四种基本电路元件,由Chua[14]于1971 年基于电路完备性理论提出,其定义忆阻器的电阻值为流经忆阻器的磁通量和电荷的比值(M=dφ/dq).然而,由于没有物理实物,忆阻器一直没有引起太多的关注.直到2008 年,美国惠普(HP)实验室制造出了基于二氧化钛的交叉存储阵列,并声称交叉点处的存储单元即为预言的忆阻器[15],立即引起了学术界和工业界的深厚兴趣.之后,研究者对忆阻器的模型、特性进行了广泛的研究[16−17].此外由于忆阻器具有记忆力和类似突触的可变导电性,使其成为构建硬件神经网络关键部件—电子突触的理想器件.近年来,Jo等[18]证明了CMOS 神经元和忆阻突触构成的神经网络能够实现一些重要的突触行为,如STDP.在此基础上,研究者提出了多种用忆阻器实现STDP 的方法,例如Panwar 等[19]实现了对任意STDP 波形的模拟.Serrano-Gotarredona 等[20]仅用一个忆阻器实现并完成了对STDP 的仿真.
本文提出并研究了基于多层SNN 的强化学习算法,并利用忆阻器设计了其硬件实现方案,下文称之为忆阻脉冲强化学习(Memristive spiking reinforcement learning,MSRL).首先,为了实现数据和脉冲之间的转换,设计了用于数据–脉冲转换的脉冲神经元;然后,通过改进基本STDP 学习规则,将SNN 与强化学习算法有效结合,并设计相应的忆阻突触以期实现硬件加速.此外,为了进一步提高网络的学习效率,构建了可动态调整的网络结构.最后基于brian2 框架[21]完成了对MSRL 的实验仿真.结果显示,MSRL 控制的智能体可以以较低的计算资源消耗,高效地完成强化学习任务.
本文结构如下:第1 节介绍了Q 学习和SNN以及忆阻器的背景知识,第2 节给出MSRL 算法的基础,第3 节详细地介绍了MSRL 算法设计.第4节给出仿真结果,第5 节总结全文.
1 背景知识
1.1 Q 学习
强化学习的理论基础是马尔科夫决策过程(Markov decision process,MDP).MDP 可以表示为:(S,A,Pa(st,st+1),Ra(st,st+1)),其中S是状态集,A是动作集,Pa(st,st+1)表示若智能体在时间t时处于状态st,采取动作a可以在时间t+1 时转换到st+1的概率;Ra(st,st+1)表示通过动作a,状态st转换到st+1所带来的及时奖赏.
强化学习中的Q 学习是一种经典的在线学习方法.在学习过程中,智能体在每一个时间步(step)内尝试动作,获得来自环境的奖赏,从而更新Q 值和优化行动策略π(s)(如图1).这个学习过程称为时间差分(Temporal difference,TD)学习[22].
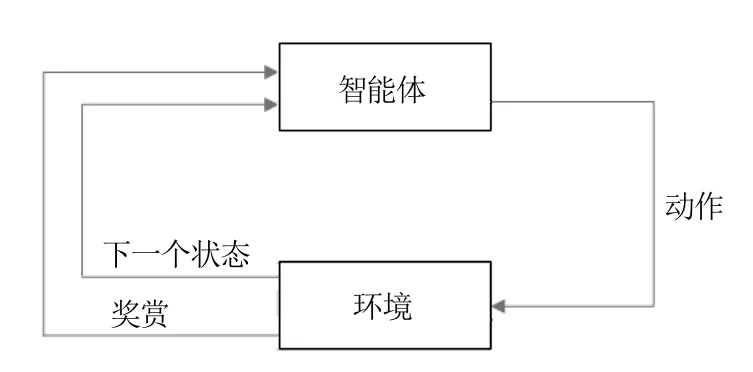
图1 Q 学习过程Fig.1 The process of Q-learning
强化学习的目标是让智能体通过与环境的交互学到最优的行动策略π∗(s),使累积奖赏即回报最大.回报定义为
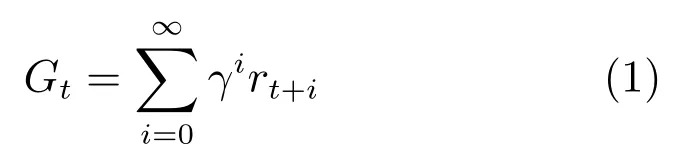
其中,折扣因子γ ∈[0,1],表示我们对未来奖赏的重视程度.γ=0 时智能体只关注当前奖赏值,γ=1时未来奖赏与当前奖赏同样重要.
Q 学习算法中的Q 值是智能体按照行动策略π(s)执行动作后所得回报的期望,定义为
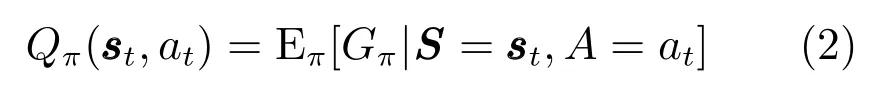
智能体通过Q 值的更新优化行动策略π(s),使其所得回报增大.Q 值更新公式为
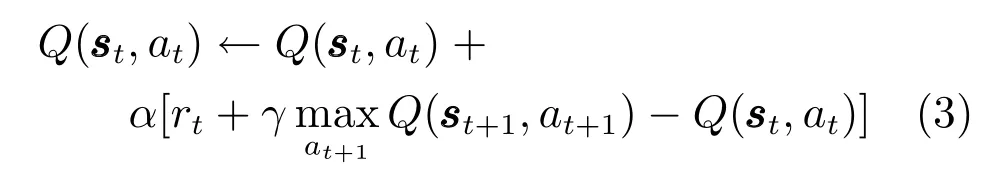
除此之外,在Q 学习中选择动作的基本策略也即本文采取的策略是策略,该策略也是Q学习同其他机器学习所不同之处,它反映了Q 学习中智能体探索(Exploration)和利用(Exploitation)之间的权衡.前者是指随机尝试动作,以期获得更高的回报,即;后者是执行根据历史经验学习到的可获得最大收益的动作,即greedy.智能体以概率随机选择动作,而以1−的概率选取最大价值所对应的动作.
基本Q 学习的算法流程可描述为
算法1.基本Q 学习算法

1.2 脉冲神经网络
脉冲神经网络(Spiking neural network,SNN)起源于神经科学,广泛用于构建类脑神经系统模型,例如用于设计模拟大脑皮层中的信息传递和时间动态可观测过程[23].与ANN 类似,SNN 也是由神经元和突触构成,本文利用经典的LIF(Leaky integrate-and-fire)神经元模型和具有STDP 学习规则的突触模型来构建SNN.
在流经离子通道的电流作用下,脉冲神经元(Spiking neuron,SN)的细胞膜将会产生动作电位u(t)[24].当动作电位达到阈值后,神经元将会发放脉冲,这个过程可以描述为
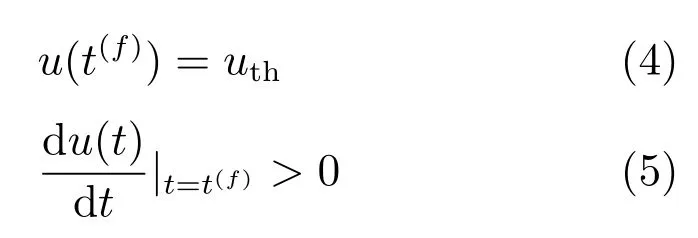
其中,t(f)是神经元发放脉冲的时间,uth是阈值电压.
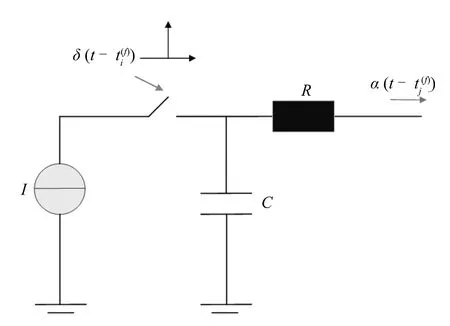
图2 LIF 模型Fig.2 LIF model
LIF 模型将神经元抽象为一个RC 电路(图2).图2 中,为来自突触前神经元i的脉冲信号,而为突触后神经元j的输出脉冲.神经元收到输入电流后,由于积分电路的作用,动作电位会升高,直到达到激活阈值,发放脉冲,这个过程称为积分点火.在脉冲发放后,由于漏电流的作用,神经元的动作电位会立即恢复至静息电位,这一过程是对真实生物神经元中的离子扩散效应的模拟[25].LIF 模型的微分方程描述如下
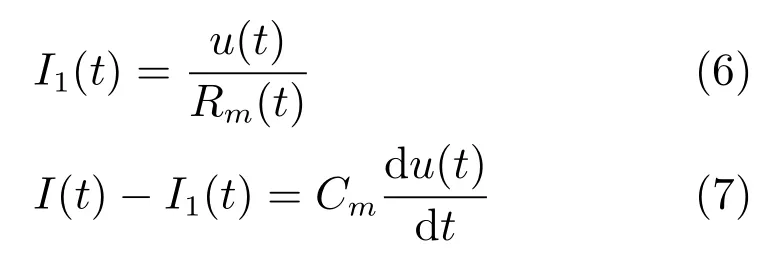
其中,Cm为神经元膜电容,I(t)为外界输入电流,I1(t)为漏电流,Rm(t)为神经元膜电阻.
在LIF 模型中,外部输入电流I(t)通常为的加权和,因此,神经元j收到第i个神经元的输入电流可以表示为
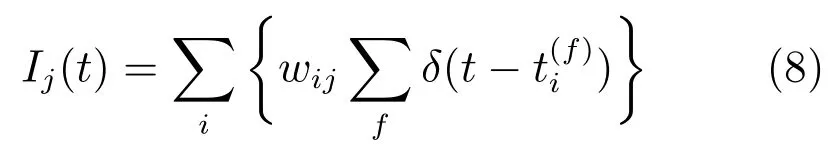
其中,wij为神经元i和j之间的突触权重;为突触前神经元i发出第f个脉冲的时间.
STDP 规则是SNN 的基本学习规则之一,具有良好的生物学基础.Hebb 等[26]于1949 年提出通过改变神经元相互之间的连接强度来完成神经系统学习过程的假设,称为Hebb 规则.Hebb 规则指出,如果两个神经元同时发放脉冲,则它们之间的突触权重会增加,反之会减少.这一假设描述了生物神经元突触可塑性的基本原理.随后在海马趾上进行的研究发现了长时增强(Long-term potentiation,LTP)效应和长时抑制(Long-term depression,LTD)效应:在一个时间窗口内,如果突触后神经元发放脉冲晚于突触前神经元发放脉冲,则会导致LTP 效应,而反之则会导致LTD 效应.前者称为“突触前先于突触后”事件(“Pre before post”event),后者称为“突触后先于突触前”事件(“Post before pre”event).LTP 和LTD 有力地支持了Hebb 的假设.
LTP 和LTD 效应是与脉冲发放时间高度相关的,基于这两种效应和相关实验,Markram[27]于1997 年定义了STDP 规则,在STDP 规则中权重的变化量是前后两个神经元激活的时间差的函数,该函数称为学习窗函数ξ(∆t),STDP 学习窗函数ξ(∆t)以及权重变化量∆wij如下所示
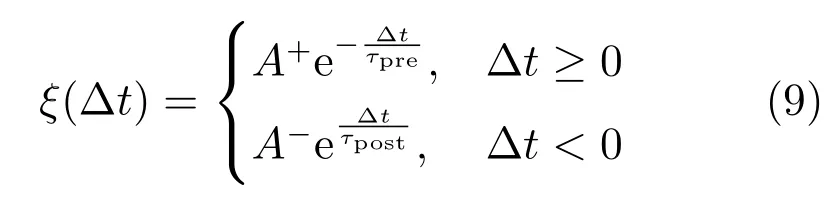
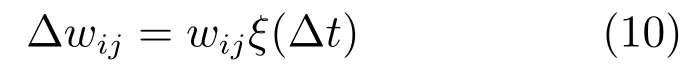
式(9)中,∆t=tpost−tpre为突触后神经元与突触前神经元发放脉冲时间差,而τpre,τpost分别为突触前后的时间常数,权重增强的增益A+>0,减弱的增益A−<0.∆t≥0 对应LTP 效应而∆t<0 对应LTD 效应.STDP 学习规则可以看作是Hebb 规则在时间上的改进版本,因为它考虑了输入脉冲和输出脉冲调整突触权重时时间上的相关性,换句话说,STDP 强调了脉冲之间的因果联系.
1.3 忆阻器模型
HP 实验室于2008 年制造出了能够工作的物理忆阻器,并提出了HP 忆阻器模型(图3).
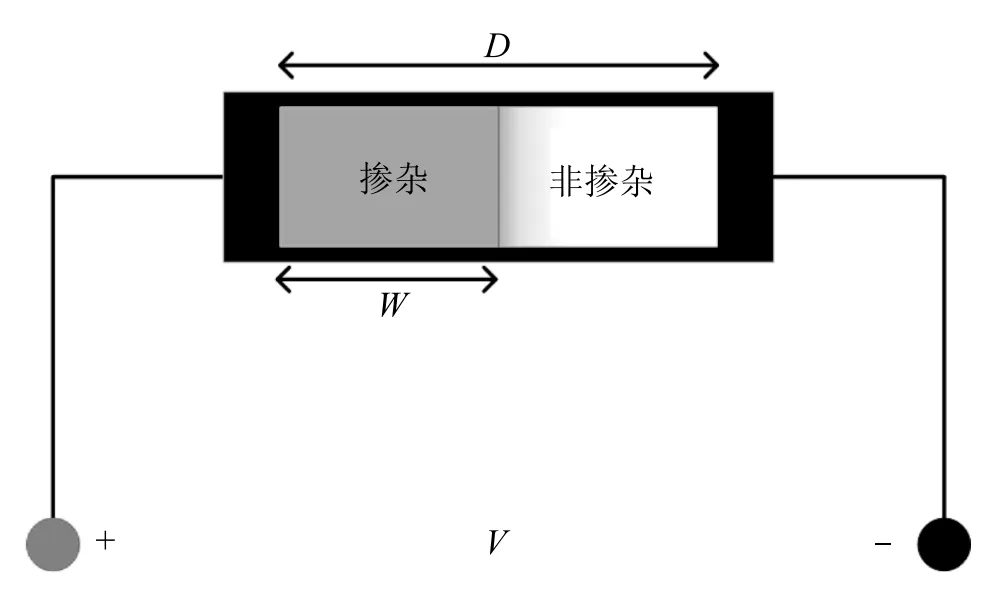
图3 HP 忆阻器模型示意图Fig.3 HP memristor
图3 中,D是二氧化钛薄膜的厚度,亦为忆阻器的全长,W是掺杂层的宽度,会在电场作用下改变,并与流过忆阻器的电荷数有关.当掺杂宽度W增大,忆阻值减小,反之忆阻值增大.忆阻器的总电阻值可表示为
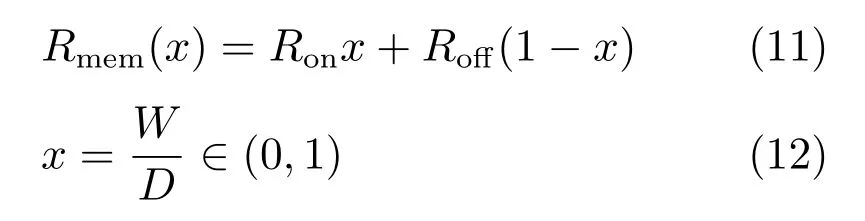
其中,Ron和Roff分别为掺杂区和非掺杂区的长度达到全长时的电阻,也称为极值电阻.由于在时间t时,掺杂区的宽度取决于通过忆阻器的电荷量,而电流为电荷的导数,因此,内部状态变量x的变化可以表示为电流的函数
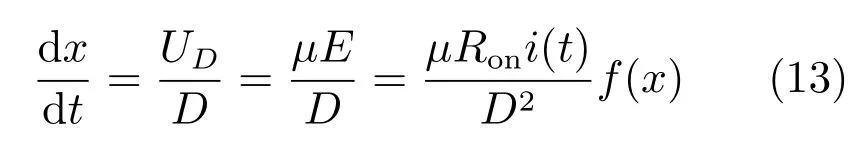
其中,UD是掺杂区和非掺杂区之间边界移动的速度,µ是平均离子漂移率,E是掺杂区的电场强度,i(t)为流经忆阻器的电流,f(x)为窗函数,已存在多种多样的函数表达形式,通常用于模拟离子漂移的非线性,限制器件边缘特性等.本文的主要目的并非提出新的忆阻器模型,而是利用合适的模型实现忆阻突触,后文详述,这里不做过多讨论.
2 基于忆阻SNN 的强化学习
忆阻脉冲神经网络强化学习(MSRL)算法的目标在于减小TD 误差的绝对值,使回报最大.训练SNN 所需样本来自对过往经验的回放,这些经验存放在记忆池中.经验回放减少了需要学习的经验数目,学习效率高于智能体直接与环境交互学习的方式[28].由此,设计MSRL 算法的首先任务是设计学习效率较高的SNN 并使之与Q 学习结合.
2.1 忆阻SNN
MSRL 算法的设计是基于一个三层的SNN,如图4 所示.图中省略号表示神经元的数量随着任务的不同而变化.网络中输入神经元将状态值转换为状态脉冲δS(t),其数量等于状态的维数.输出神经元的输出为Q 值脉冲δQ(t),其数量等于动作数.这样的结构意味着每个输入神经元对应每个状态维度,每个输出神经元对应每个动作.相邻层神经元之间用忆阻器连接,忆阻器可工作在三种状态:a)权重不可更改状态;b)权重调节状态;c)断开状态.
适当调节隐含层节点数量是有必要的,如果隐含层节点数过少,网络的学习能力和信息处理能力不足.反之,如果节点过多可能会增加网络结构的复杂性,减慢运行速度.具体的隐含层神经元数量对网络性能的影响将在第4 节讨论.
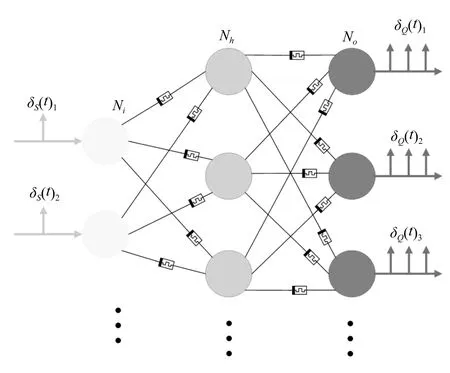
图4 脉冲神经网络结构Fig.4 The structure of SNN
2.2 数据−脉冲转换
考虑到脉冲神经元接受、处理和传递的信息是脉冲信号,因此有必要设计数据与脉冲之间的转换关系.在本文中,模拟数据转换为脉冲时间序列的过程为编码,其逆过程为解码.一个时间窗口T为10 ms.
1)输入层神经元
生物学研究表明,在生物视觉神经网络中,神经元对信息的编码与首次发放脉冲的时间有关,发放时间越提前说明输入脉冲与输出脉冲之间的相关性越强[29].由此引入一维编码方式[30]:状态值s ∈[smin,smax],编码后首次发放时间t(s)∈[0,T],则编码规则为
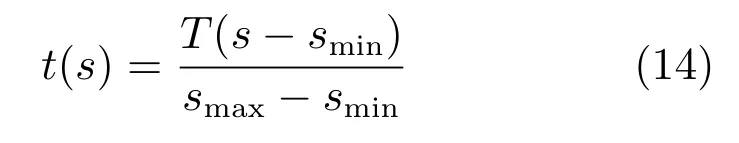
这种编码方式使输入神经元在一个T内只发放一个脉冲.基于式(14),并结合式(8)得到隐含层输入电流Ih(t)为
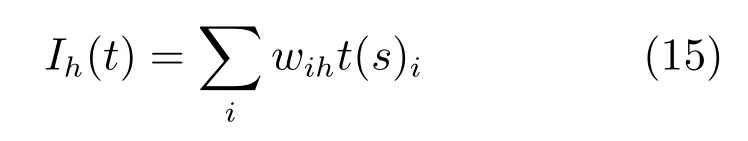
其中,wih为输入层与隐含层神经元之间的突触权重.输入神经元用于将状态值转换为单个的状态脉冲,没有解码过程.
2)隐含层神经元
研究以下情形:两个LIF 神经元i,j由一个突触连接.突触前神经元i为输入神经元而突触后神经元j为输出神经元,它们的初始电压均为0,神经元i在t0时间电压达到阈值而发放脉冲,根据式(8),脉冲将通过突触转换为输入至神经元j的电流,如果输入电流能使突触后电位达到阈值,则突触后神经元j将发放脉冲.通过神经元不应期的设置,在一个时间窗口的时间内,神经元j只会发放一个脉冲,如图5(a)所示.
对于隐含层神经元,设置激发态时其只发放一个脉冲,解码时将其脉冲发放时间th直接作为输出数据,从而可得输出层输入电流Io(t)
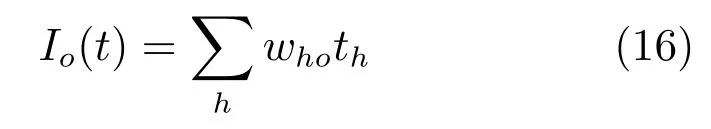
其中,who是隐含层与输出层之间的突触权重,编码时则根据发放时间还原脉冲即可.
3)输出层神经元
由于首次发放时间越提前说明输入输出相关性越强,则可以认为在一个时间窗口内,输出层中最早发放脉冲的神经元为动作价值最大的动作,这意味着首次发放时间和动作价值呈反相关关系,解码时直接将首次发放时间作为输出数据则需要修改Q 值更新公式.为了减少算法设计的复杂度,输出层神经元发放脉冲的形式设置为连续发放.如图5(b)所示,进而计算其平均发放率(Mean firing rate)[24]

其中,nsp是输出层神经元在一个时间窗口T内发放脉冲的数量.事实上,平均发放率和首次发放时间是等效的,一个神经元的平均发放率越高,由于脉冲时间间隔均等,则说明它的首次发放时间就越提前[24].因而如果设置输出层神经元总是在一个时间窗口内,连续发放时间间隔相同的脉冲,那么可以直接将nsp作为输出动作价值.进一步,近似认为输出脉冲时间将T均等分,所以输出脉冲序列的发放时间为等差数列,在已知数列项数即脉冲数量nsp的情况下可还原脉冲序列.
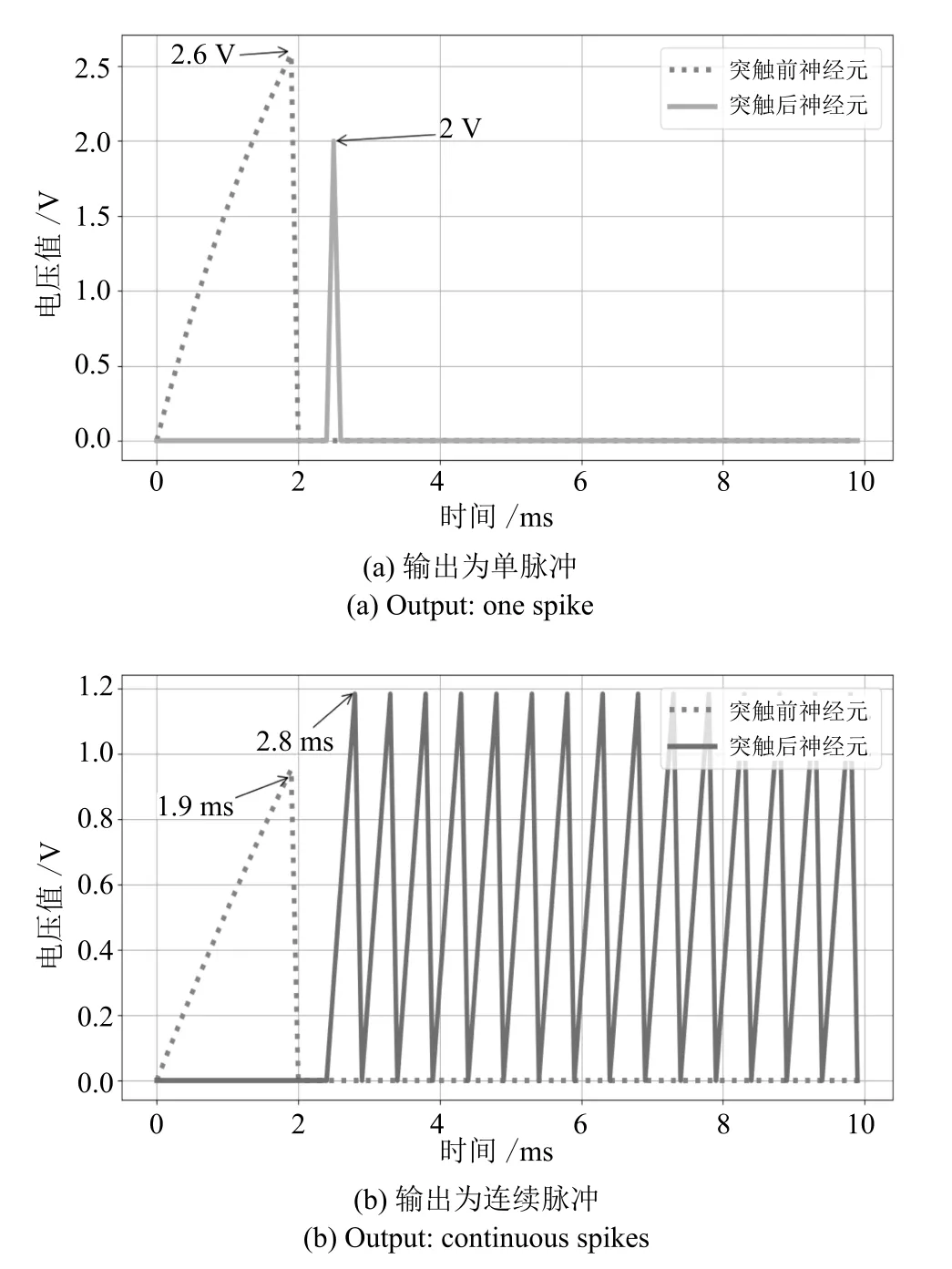
图5 脉冲神经元响应Fig.5 The response of spiking neurons
2.3 改进STDP 与忆阻突触设计
神经科学领域的主要研究问题之一是对生物学习过程的解释.例如,STDP 学习规则的提出是基于对单个生物突触的实验,但对于STDP 规则如何在脉冲神经网络中实现权重调整并没有统一且详尽的描述[31].为了实现STDP 规则对脉冲神经网络的权重调整,进而应用于强化学习中,需要对基本STDP规则加以改进.其思路在于引入第三方信号(可以是奖赏信号或TD 误差信号),作为突触权重的调节信号[31].
以奖赏信号为调节信号的STDP 规则称作Reward STDP,例如文献[32]提出如下权重调节规则
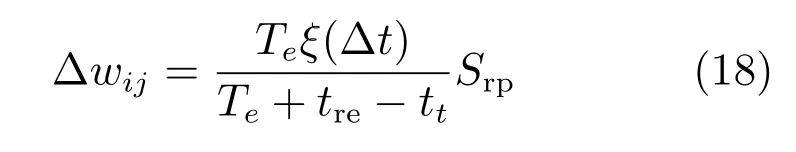
方案中奖赏为一个时间函数Srp,tre是奖赏出现的时间而tt是智能体执行动作的时间.Te是每次迭代持续的时间.Reward STDP 实现了在虚拟环境中对觅食行为这一生物问题的建模.但是,这种方案不适用于强化学习任务,因为在强化学习任务中,执行动作的事件和奖赏之间可能达到上千步的延迟,导致学习效率非常低.
以TD 误差信号作为调节信号的STDP 规则称作TD STDP 规则,为了方便讨论,将TD 误差重写
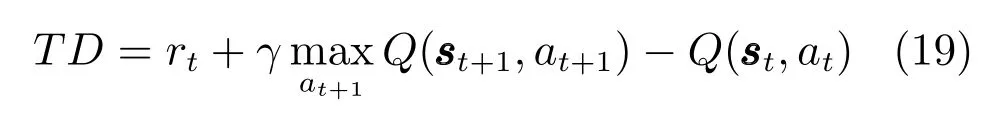
利用式(19),文献[33]提出如下的权重调节方案
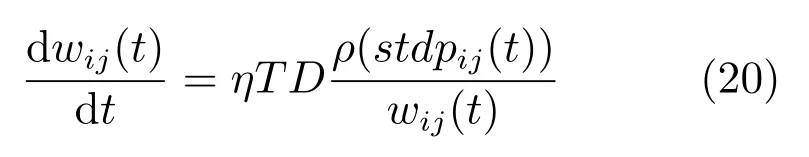
其中,ρ(stdpij(t))为突触前发放脉冲与突触后发放脉冲的概率之差,η ∈[0,1]为学习率.此改进方案的立足点在于,TD 误差反映了目标值和实际输出值的偏离程度.如果TD 误差为正,说明目标值优于实际值,当前的突触权重应该加强,反之应该减弱,但是,这种权重调节方案并不能直接应用于MSRL算法,原因在于,此方案限制每个神经元仅发放一个脉冲,而MSRL 中输出层神经元发放的是连续脉冲.另外,直接将TD 误差作为权重调节系数不能最小化误差,需要定义损失函数.
我们在式(20)基础上提出改进的STDP 规则.首先,将ξ(∆t)简化如下
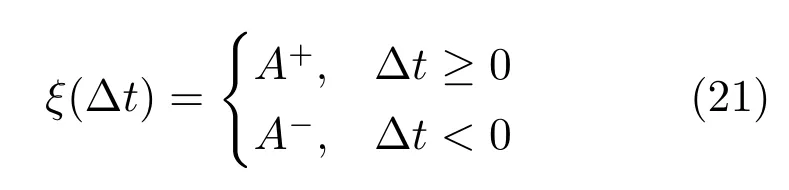
式(21)不考虑输入和输出脉冲的时间差,只考虑输入和输出脉冲之间的相关性.进一步,按照文献[34],定义损失函数如下
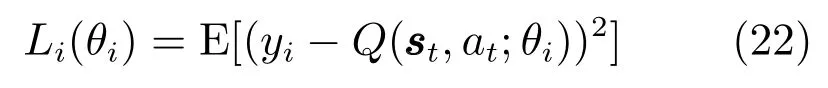
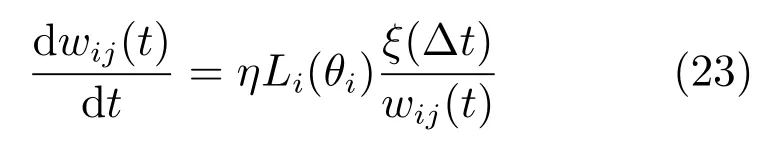
在此基础上,本文还设计了对应的基于忆阻器的人工突触,以期进一步实现所提出算法的硬件加速.定义非线性窗函数如下
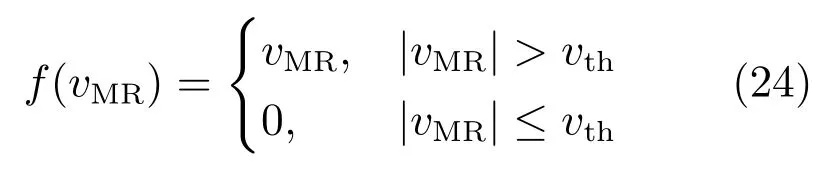
其中,vMR为忆阻器两端电压,vth为忆阻器的阈值电压,调整忆阻器两端电压大小可使忆阻器处于权重调节或不可更改两个状态.
进一步,设置权重调节状态时vMR为
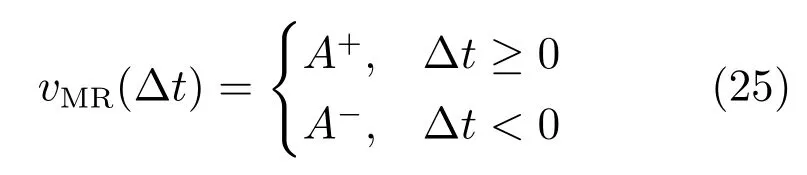
而突触权重的更新如下
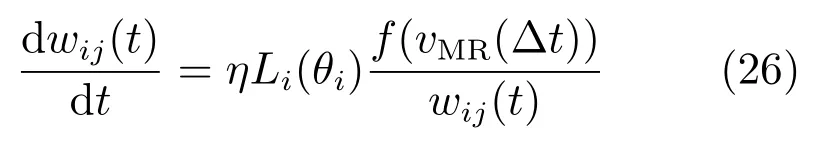
即可实现改进后的STDP 学习规则.
3 算法流程
在第2 节基础上,给出MSRL(算法2)的具体实现流程.如下所示:
1)数据收集
强化学习任务开始时,没有足够的样本用于训练SNN,需要通过智能体与环境的交互以获取样本.此时使权重服从均值和方差均为0.1 的正态分布,并通过正则化提高权重收敛速率,即

其中,n为输入神经元的数量.另外,为了消除脉冲之间的相关性,每个神经元注入了微量的噪声[33].每一个时间步(step)内,神经网络的运行时间为两个时间窗口T.我们设置输入层和隐含层只在第一个T内发放脉冲,一个T的时间过后,输出层再发放脉冲.一旦神经网络运行完成,便得到了输出脉冲数量Q,隐含层输出脉冲时间th,根据策略,智能体有1−的概率选择Q最多的神经元所对应的动作,而以的概率随机选择动作.中的值会随着迭代次数的增加而递减,以确保随着任务的进行智能体逐渐依赖于策略π(s)而不是无目的的选取动作.
2)网络训练
根据文献[35],突触权重变化会逆行而快速的传播到突触前神经元树突的突触上,但并不会向前传播到下一级突触上,这表明类似反向传播算法的机制可以在脉冲神经网络中存在并发挥作用.因此提出如图6 所示的训练方式.图中画出的忆阻器表示此时忆阻器处于权重调节状态,未画出的忆阻器则处于断开状态.一次训练包含多个样本,每一个样本使神经网络运行三个时间窗口T.训练时,首先断开所有忆阻器.之后使目标动作对应的输出神经元与隐含层之间的忆阻器导通,这类似于监督学习中利用标签进行训练.令隐含层神经元发放对应的隐含层脉冲δh(t),运行一个时间窗口后,在第二个时间窗口内令输出神经元发放目标脉冲(图6(a)).网络运行完两个时间窗口后,断开隐含层与输出层之间的忆阻器,使输入层和隐含层之间的忆阻器导通(图6(b)),令输入神经元发放状态脉冲δS(t),同时令隐含层神经元再次发放隐含层脉冲δh(t).如此循环往复,直到一次训练完成.
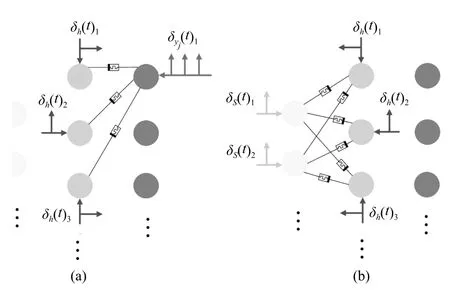
图6 忆阻脉冲神经网络的训练过程Fig.6 The training process of memristive spiking neural network
3)网络测试
测试时忆阻突触的权重将完全由训练结果决定,通过设置忆阻器电压,可以使其工作在权重不可更改状态.神经网络的运行步骤同训练前.
具体的MSRL 算法描述如下:
算法2.忆阻脉冲神经网络强化学习(MSRL)算法


4 实验与分析
4.1 实验设置
1)CartPole-v0
如图7 所示,一辆小车上用铰链装有一只平衡杆,平衡杆可以自由移动.在力F的作用下,小车在离散时间区间内向左或向右移动,从而改变小车自身的位置和杆的角度.这个模型的状态有4 个维度:a)小车在轨道上的位置x;b)平衡杆与垂直方向的夹角θ;c)小车速度v;d)平衡杆角速度ω.
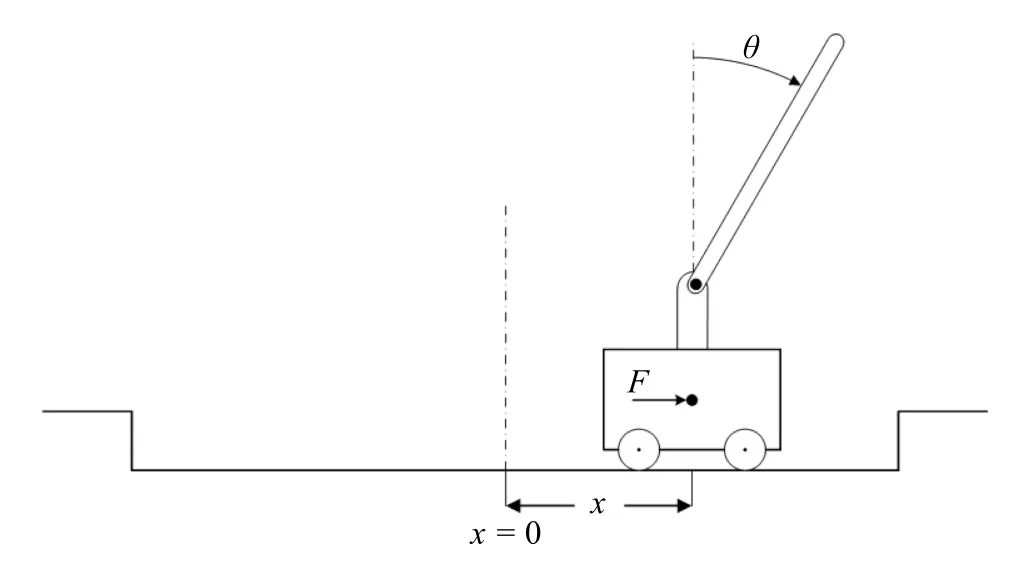
图7 CartPole-v0 示意图Fig.7 CartPole-v0
游戏中每移动一个时间步(step),智能体都会通过观察获得下一个状态的值,并且会获得值为1的奖赏.游戏终止的条件为:a)平衡杆的角度的绝对值大于12◦;b)小车的位置与x=0 的位置的距离超出±2.4 的范围;c)在一次迭代(episode)中step 数超过200.满足条件c)则认为游戏成功.由于摆杆角度和车位移的绝对值较小的情况下游戏容易成功,因而定义每一步的游戏得分为
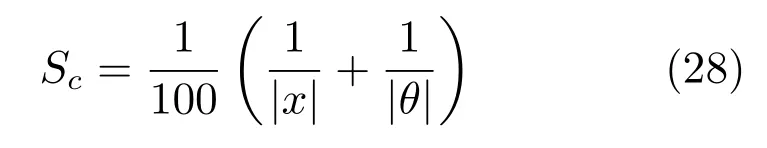
每次游戏得分通过此次游戏总分除以此次游戏迭代步数得到.MSRL 参数设置如下:对设置=0.1,学习率η设置为0.1,记忆池容量为10 000,折扣因子γ为0.9.算法运行500 次迭代.
2)MountainCar-v0
如图8 所示,一辆小车被置于两座山峰之间,小车的初始位置x0∈(−0.6,−0.4),山谷处的位置为−0.5.任务目标是开到右边小旗处.但是,车的动力不足以一次爬上山顶,因此,小车需要来回移动以获取足够的速度到达目标处.智能体的状态由两个维度组成:a)小车轨道位置x ∈(−1.2,0.6);b)小车的速度y ∈(−0.07,0.07).
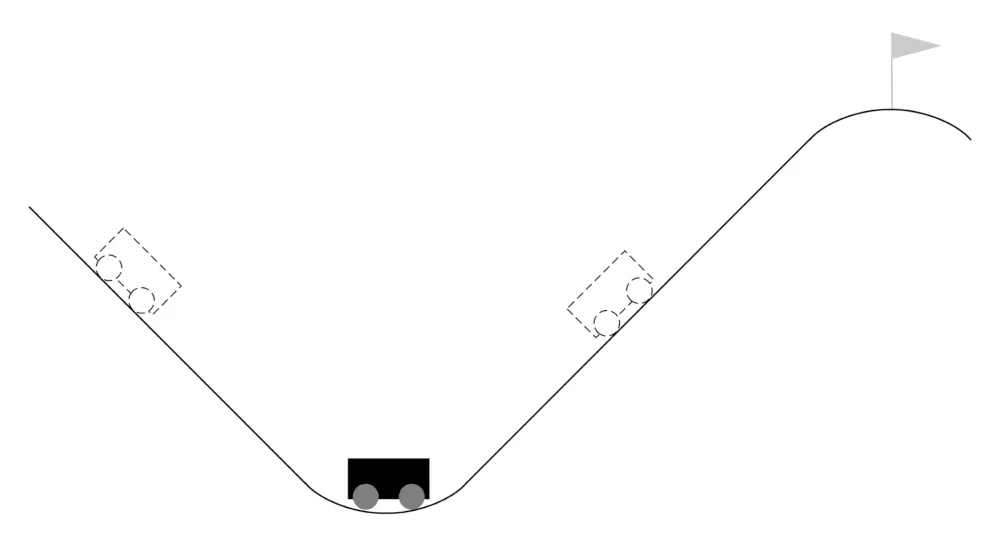
图8 MountainCar-v0 示意图Fig.8 MountainCar-v0
每一个step 中,小车有三个动作可供选择:向右、停止、向左.小车移动一步后会获得观察值和值为−1 的奖赏.根据小车与终点的距离,定义每步游戏得分Sm为
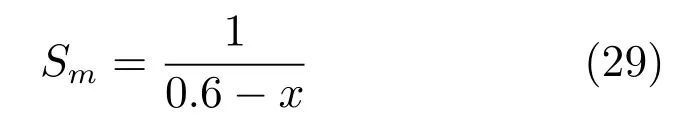
每次游戏得分计算方式与CartPole-v0 相同.另外,设定当一次迭代中步数超过300 游戏也会自动结束.MSRL 参数设置如下:对−greedy,同样设置=0.1,学习率η设置为0.1,记忆池容量为5 000,折扣因子γ为0.9.算法运行100 次迭代.
3)隐含层神经元数量
为了确定SNN 隐含层神经元的数量,我们在其他实验参数相同的情况下分别独立运行了隐含层神经元数量不同的MSRL 算法,并比较它们的TD 方差,结果见表1.表1 的列展示了隐含层神经元数量不同的情况下TD 方差的大小,在其他参数相同的条件下进行实验.TD 方差小表明学习效率更高.CartPole-v0 的输入神经元为4 个,MountainCarv0 为2 个.
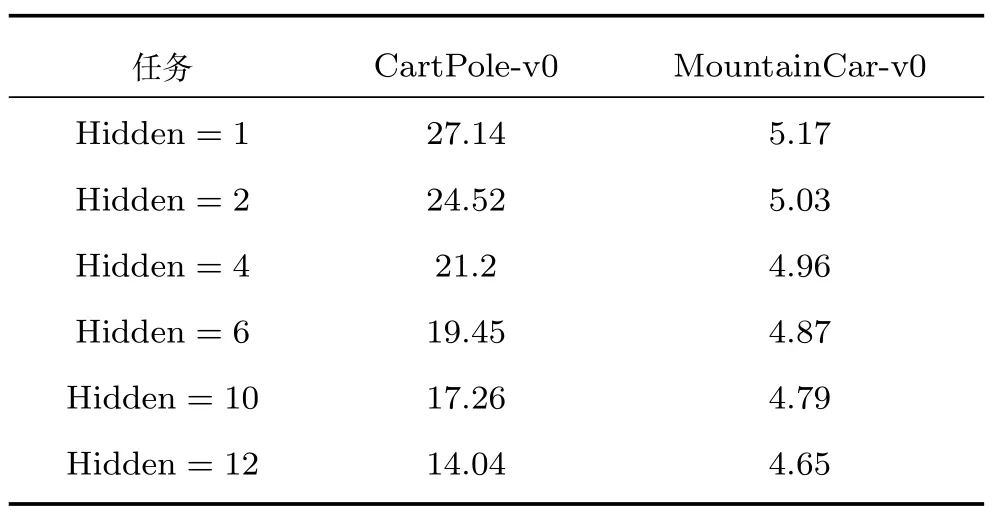
表1 不同隐含层神经元数量TD 方差对比Table 1 The comparison of TD variance for different hidden neurons
从表1 中可以发现,隐含层神经元数量较少,TD 方差较大,但数量过多并没有显著提高学习效率,反而可能会增加网络复杂度,减慢运行速率.因此我们设置CartPole-v0 隐含层神经元数量为6,MountainCar-v0 隐含层神经元数量为4,作为折中的一种优化选择.
4.2 实验结果与分析
1)MSRL 有效性验证
在实验过程中智能体的状态反映了学习效果.Cartpole-v0 游戏中,平衡杆的角度和小车的位移越小越好,这样游戏才可能成功.而MountainCar-v0游戏中,小车在速率足够大的情况下才能爬上右侧山坡,到达目标.我们分别在训练开始前和训练开始后随机抽取相同数量的样本以观察样本的数值分布,结果如图9 所示.可以看出,在CartPole-v0 中,当完成了200 次游戏后,平衡杆的角度和小车的位置集中于原点附近.而在MountainCar-v0 中,完成了50 次游戏后,坐标值的变化显示小车学会了利用左侧山坡获得反向势能,并且速率大于训练之前.
2)算法对比
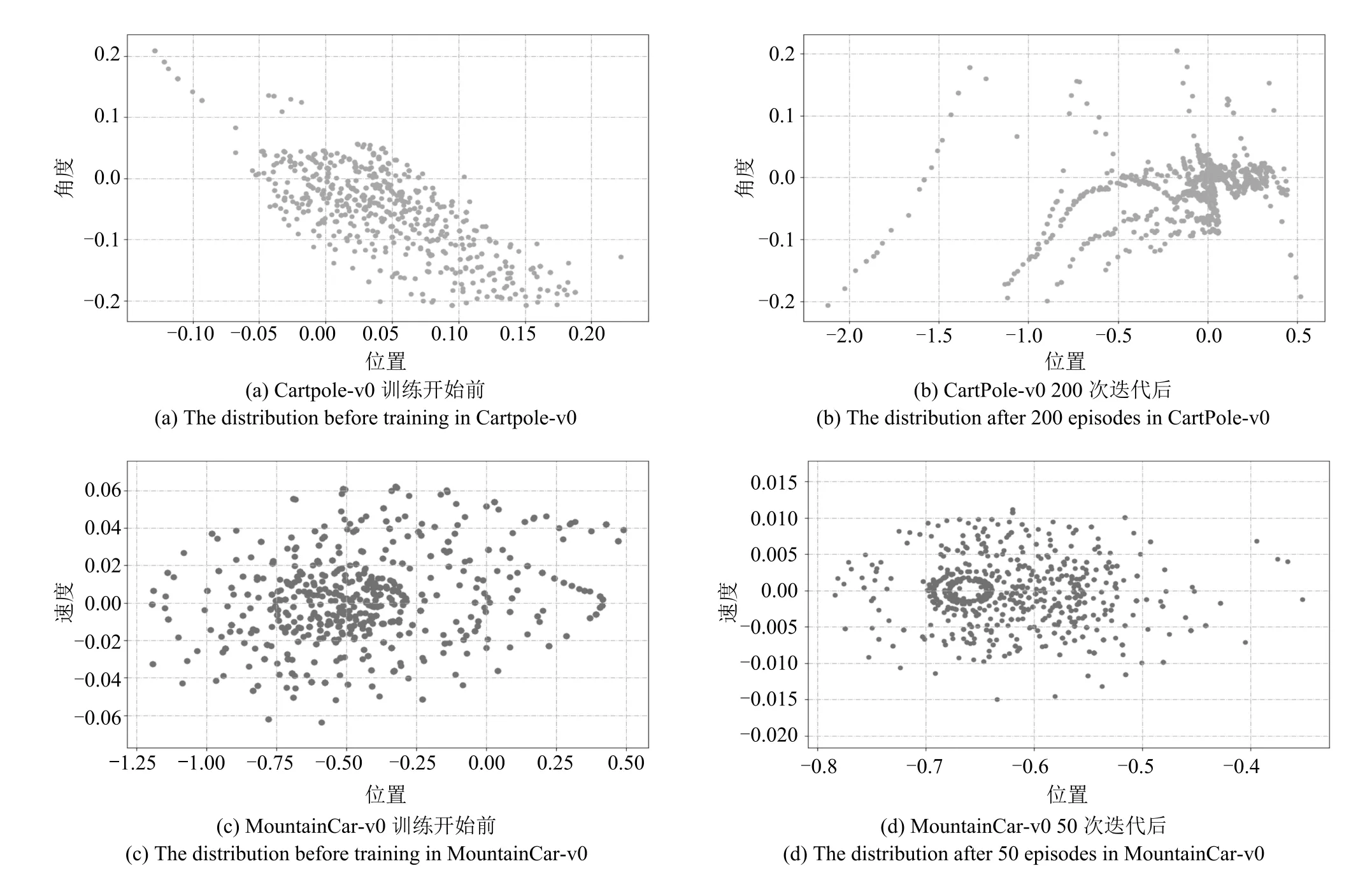
图9 MSRL 训练前后样本状态分布对比Fig.9 The comparison of sample states distribution before and after training of MSRL
为进一步说明MSRL 的特点,我们将深度Q 网络(Deep Q network,DQN)和离散状态Q-learning作为比较的对象.三者折扣因子和学习率均相同,DQN 同样采用三层全连接前向网络结构,隐含层神经元数量为10,且其记忆池容量与MSRL 相同.三个算法在同一台计算机上分别独立运行.对比结果如图10 和表2 所示.
根据游戏环境的设置,在CartPole-v0 游戏中每次游戏的迭代步数越高越好,而MountainCar-v0 则相反.图10(a)和10(b)的结果显示,在CartPolev0 游戏中,MSRL 算法所控制的倒立摆系统游戏成功率和得分高于另外两种算法.尽管DQN 先于MSRL 算法完成游戏目标,但其收敛性较差.图10(c)和10(d)的结果显示,在MountainCar-v0 游戏中,MSRL 算法所控制的小车容易以较少的步数达到目标处,且最少步数小于另外两种算法,同时游戏得分为三者中的最高值.从两个游戏的结果可以看出,离散状态之后的Q-learning 算法难以达成目标.我们将结果列在表2 里以更清楚对比结果.
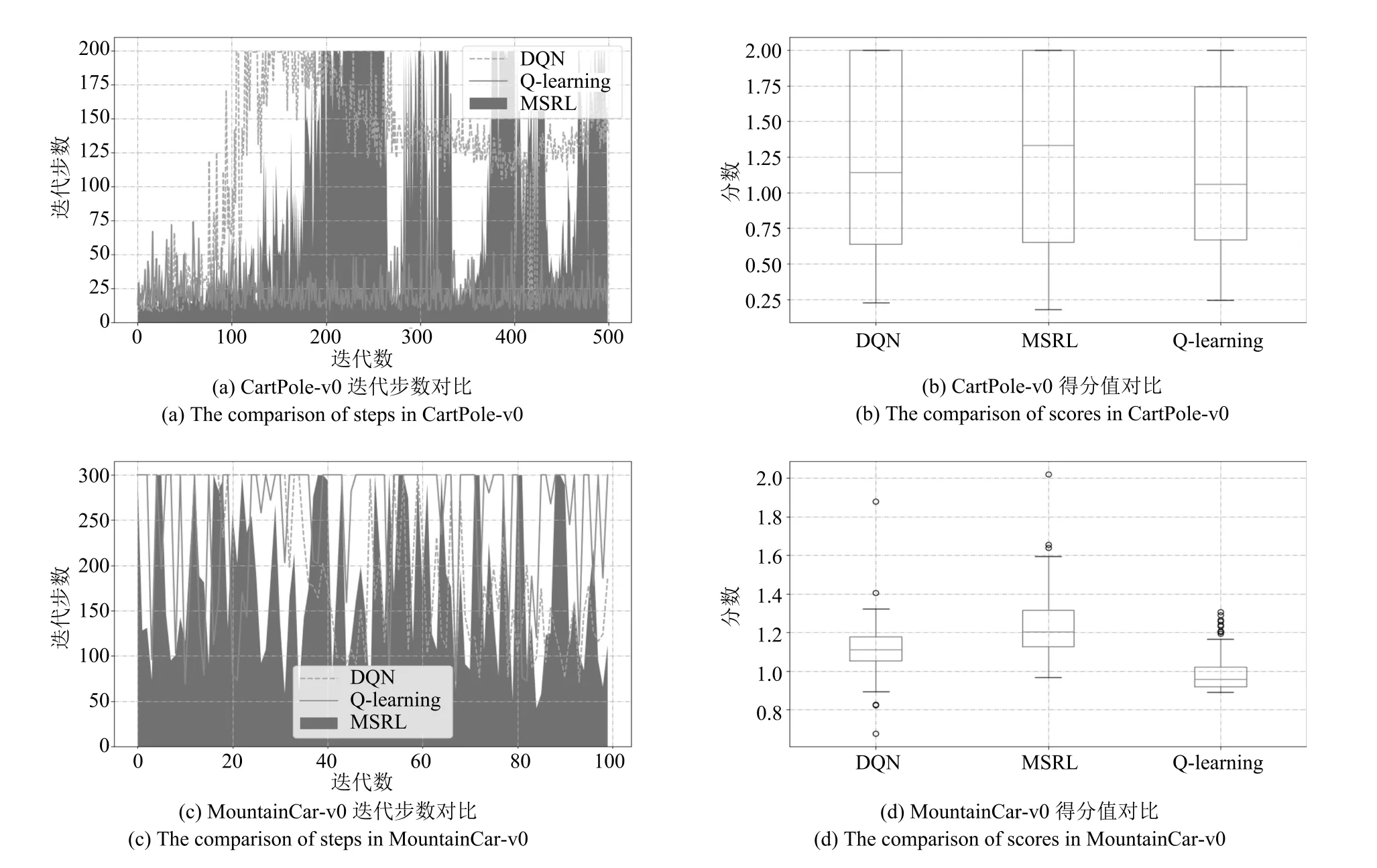
图10 比较结果(A)Fig.10 The results of comparison(A)
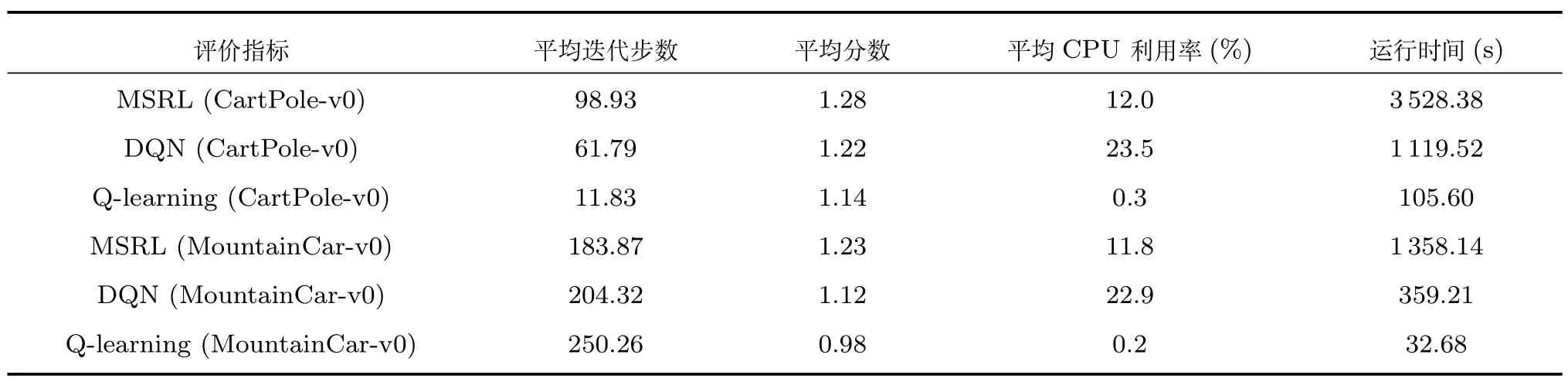
表2 比较结果(B)Table 2 The results of comparison(B)
表2 中,平均迭代步数为实验中的累积步数除以迭代数,而平均分数为累积分数除以累积步数.在CartPole-v0 游戏中,MSRL 算法总平均迭代步数相比于DQN 和离散Q-learning 明显增加,而在MountainCar-v0 游戏中,MSRL 算法总平均迭代步数相比于DQN 和离散Q-learning 明显减少.两个游戏中得分最高者均为MSRL.此外,我们还在游戏执行的每一步中记录CPU 利用率,最后用累积CPU 利用率除以累积步数以计算平均CPU 利用率.结果显示,尽管Q-learning 能以较短的运行时间和较低的CPU 利用率完成目标,但是其计算效果不如神经网络式强化学习.而MSRL 算法CPU利用率低于DQN,但运行时间长于DQN.根据文献[36],采用不同的模拟策略影响脉冲神经网络的运行时间.而本文利用新型信息器件忆阻器的高密度、非易失性等优势,融合优化的网络结构和改进的学习算法,有望以实现MSRL 的硬件加速,同时减少对计算资源的依赖.
5 结论
尽管传统的神经网络与强化学习算法的结合提高了智能体的学习能力,但这些算法对计算能力依赖性较强,同时网络复杂度高,不适合硬件实现.为了进一步达到硬件加速,促进嵌入式智能体在实际环境中独立执行任务,本文设计了基于多层忆阻脉冲神经网络的强化学习(MSRL)算法.首先解决了数据与脉冲之间的转换问题;在前人工作基础上,改进了STDP 学习规则,使SNN 能够与强化学习有机结合,同时也设计了相应的忆阻突触;进一步,设计了结构可动态调整的多层忆阻脉冲神经网络,这种网络具有较高的学习效率和适应能力.实验结果表明,MSRL 与传统的强化学习算法相比能更高效地完成学习任务,同时更节省计算资源.在未来的工作中,我们将研究深度SNN 与更复杂的强化学习算法例如Actor-Critic 算法的结合,并进一步改进学习算法以增强算法稳定性.
