一种改进Deep Forest算法在保险购买预测场景中的应用研究
2019-09-10林鹏程唐辉
林鹏程 唐辉








摘 要:为了实现保险场景的精准营销,同时充分利用千万级客户和保单历史成交记录的数据特点,本文经热门算法研究和统计理论分析,提出一种基于XGBoost改造的Deep Forest级联算法。该算法采用XGBoost浅层机器学习算法作为Deep Forest级联构建块,同时用AUC-PR标准作为级联构建深度学习不平衡样本评价的自适应过程,并将此算法分别与原有XGBoost算法和原始Deep Forest算法进行性能比较。经实践,上述算法应用投产于保险购买预测场景中,分别比原有XGBoost算法和原Deep Forest算法提高5.5%和2.8%,效果显著;同时提出的浅层学习向基于Deep Forest深度优化操作流程,也为其他类似应用场景提供了实践参考方向。
关键词:Deep Forest;XGBoost;深度学习;保险精准营销
中图分类号:TP301.6 文献标识码:A 文章编号:2096-4706(2019)22-0116-07
Abstract:In order to realize the precise marketing of the insurance scenario,and make full use of the data characteristics of tens of millions of customers and the historical transaction records of insurance policies,this paper proposes a Deep Forest cascade algorithm based on XGBoost transformation through popular algorithm research and statistical theory analysis. This algorithm adopts XGBoost shallow machine learning algorithm as the building block of Deep Forest cascade,and uses AUC-PR standard as the adaptive process of cascading deep learning unbalanced sample evaluation,and compares the performance of this algorithm with the original XGBoost algorithm and the original Deep Forest algorithm respectively. Practice has proved that the above algorithm applied in the prediction scenario of insurance purchase is improved by 5.5% and 2.8%,respectively,compared with the original XGBoost algorithm and the original Deep Forest algorithm. At the same time,the proposed shallow learning direction based on Deep Forest depth optimization operation process also provides practical reference for other similar application scenarios.
Keywords:Deep Forest;XGBoost;deep learning;insurance precision marketing
0 引 言
近年來,保险的作用越来越受到人们的认可;购买保险已成为大家的日常消费行为。而人们更希望根据自身的经济情况、家庭财力情况和风险承受能力购买合适的保险产品。尽管大多数保险公司在保单销售、客户服务中留下了大量的客户、保单及客户服务的历史数据,但是向客户推销保险产品时,常常还是依靠经验或随机选择客户进行推销,成功率较低,耗费大量人力和物力成本。因此,如何利用既有数据合理地分析和预测客户未来购买保险产品的行为成为金融保险领域重要的研究课题。
目前,在研究预测客户购买行为方面大部分集中在互联网、银行、基金证券等领域。文献[1]运用既定的需求成熟度模型计算客户多元属性中的相关系数,并运用统计学进行假设检定,确保系数的合理性和稳定性,运用线性回归算法来完成对银行客户购买行为的预测;文献[2]立足于RFM分析模式,采用k-means算法对客户进行聚类分析,然后借助马尔可夫链理论,建立相关转移矩阵,同时利用Dirichlet-multinomial模型来估计转移概率,从而解决客户信息单一性的不足和转移矩阵内的多项式分配问题,从而完成客户购买倾向预测;文献[3]分别运用常规机器学习算法,例如Logistic回归、SVM(支持向量机)算法和Logistic回归-支持向量机平均融合算法对上网客户进行购买预测行为;文献[4]中李栋等人主要是利用果蝇优化算法(ELM)计算极限学习机(ELM)参数,从而构建极限学习机浅层神经网络,进行客户购买基金行为的预测。
在保险领域中,研究客户购买预测行为的相关文献较少,目前已有的基本上是通过统计和常规分类算法进行实验研究。比如文献[5,6]基本通过经验法则或者问卷调查的形式,利用二元Logistic回归统计分析方法来计算客户购买保险的意愿;文献[7]主要通过改进支持向量机等多种机器学习方式进行实践,尝试得出客户购买预测行为。
虽然上述方式在一定程度上实现了客户购买行为预测能力,但是在大型保险公司中面向的往往是对上亿规模用户的保险购买行为预测,每个用户的大量特征还存在稀疏性强的特点,这种场景下往往更适合采用树状算法进行分类预测[8];为了进一步提升树形算法准确性,往往采取bagging或者boosting集成的方式进行模型构建,比如随机森林(RF)或者梯度决策树(GBDT)方式,但这些集成方式由于浅层学习和评估标准不可微,优化效果主要靠人工调整参数,和深度学习自动化迭代更新权重参数相比,存在最优的局限性;特别是当大量的训练数据可用时,浅层学习能力往往不如深度学习能力[9]。
为进一步实现保险精准营销,须将原有的基于树形集成方式(例如XGBoost)的客户购买保险行为预测模型进一步做深度优化,本文采用深度森林(Deep Forest)[10]作为一种新型的深度学习能力,并针对其级联结构中在实际保险购买行为预测业务中的不足,提出了一种改进实践算法——基于XGBoost改造的Deep Forest级联算法。
实践表明,基于XGBoost改造的Deep Forest级联算法应用于保险产品购买预测模型中,预测效果和实际应用效果在深度优化方面均比原有单个XGBoost效果更优,同时也比原有Deep Forest优化效果更稳定。
1 Deep Forest算法简介
当前主流的人工智能技术主要实现深度学习,而其中典型的技术是采用神经网络技术,而Deep Forest则另辟蹊径地进行深度学习,本节主要介绍Deep Forest算法原理,同时根据保险购买预测场景业务情况,对该算法进行相关局限性分析。
1.1 原理介绍
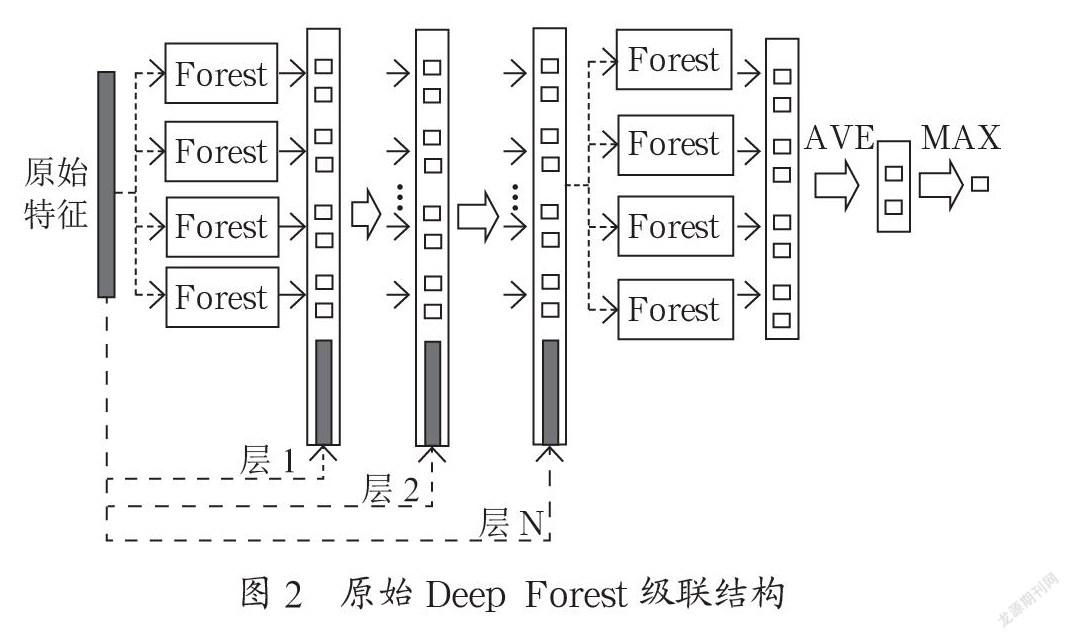
传统的基于神经网络深度学习算法,要求各层节点都是可微模块,才能使用反向传播机制(Back-propagation)來更新各层参数。若遇到各层节点是采用擅长处理表格型数据(或者离散数据)等其他不可微模型时,神经网络结构难于进行深度学习。对此,南京大学的周志华团队于2017年提出了一套新型的深度结构学习算法——Deep Forest,算法过程如图1所示。探索在不可微情景下的表示学习能力,同时,能够构建具有自适应模型复杂度的多层结构。
Deep Forest有别于以往基于神经网络的深度学习算法,特别是在处理深度学习过程中的特征关系处理能力(FeatureRelationships)和表征学习能力(Representation Learning)。有自身独特之处。
首先,特征关系处理能力方面,Deep Forest是通过构建多粒度扫描方法(Multi-GrainedScanning),对原始特征输入进行变换,增强特征表达能力,适合于对原始序列数据(sequencedata,例如声音、图像等)的特征工程处理。
其次,在表征学习能力方面,Deep Forest构建一套级联结构(Cascadeforeststructure),级联中的每一层接收由上一层处理后的特征信息,并将该层处理结果传递给下一层。级联的每层包含两个随机森林(RandomForest)和两个完全随机树森林(Completely-randomtreeforest)。级联过程中,每次扩展一个新的层之前,会将整个级联性能在交叉验证数据集上进行评估,如果没有显著的效果增强,则训练过程被终止,因此级联过程的层数是自动确定的。这种级联结构的表征学习能力,非常适用于离散型或者表格型等场景数据。
而相比于深度神经网络,Deep Forest级联结构也有明显的优势。首先,Deep Forest的参数主要依靠原生随机森林或者完全随机数森林等基分类器参数,相比于深度神经网络的上百个调优参数要少很多;其次,它可以根据数据规模和特定应用场景,自适应完成级联层数,无需人工额外干预;最后,Deep Forest提供级联框架为其他非微模型的深度优化提供了重要参考依据[11]。
Deep Forest的出现,为深度学习在深度神经网络之外的方法,打开了一扇门。
1.2 应用局限性分析
尽管Deep Forest在学术领域得到了实践认可,但是将其用于构建保险购买预测场景的模型构建,特别是效果优化方面,仍存在如下局限性:
首先,Deep Forest级联过程中采用随机森林和完全随机树森林两种基分类器,虽然能最大化克服过拟合的问题,但是由于这两种基分类器在样本抽取和样本特征抽样的随机性,训练效果稳定性往往同这两个基分类器设定的随机参数有很强的相关性,而随机参数选取自身与训练样本数量和分布特性非常敏感,这种敏感的关系多数情况通过人工方式不断调优确定。构建保险购买预测模型,由于样本数据特征随着时间推移,易造成概念偏移,需要模型定期进行迭代。每次迭代训练数据,无论量级和分布都会因业务需要发生变化,因此在完全无人工干预的情况下,容易因之前单个随机森林参数设定不再适用于新场景,造成冗余的级联训练(有时候层级大于20),最后导致模型过于复杂,而收敛效果往往无显著提升。
其次,保险购买预测应用场景是一个典型的不平衡样本的二元分类问题,正负样本比例高达1:180;而Deep Forest级联每层评价标准采用精确度(Accuracy)作为模型自适应完成训练指标,往往容易造成评价失真,无法客观评价最终级联模型是否在业务上满足精准预测和查全率的指标要求。
最后,虽然Deep Forest算法在众多领域实验中具备优越的表现性能,但是在保险购买预测模型实践中如何用好Deep Forest算法,需要研究一个有科学依据的、合理的进阶式应用方案,以实现传统树形集成算法深入优化能力。
对此,本文希望结合Deep Forest的优势特点,克服上述的现有不足,使得原有保险购买行为预测浅层模型具备深度学习的能力,对现有的Deep Forest进行优化改进,提出了基于XGBoost改造的Deep Forest算法。
2 基于XGBoost改造的Deep Forest算法
为了更好地实现保险精准营销的购买预测,本节主要对Deep Forest算法进行相关原理分析,并对其中的不足提出相关改造措施。
2.1 引入XGBoost的原因
分析如图2中Deep Forest级联结构[10],假设r表示级联块中每个基分类器的权重,N代表级联的第N层,Nm代表第N层上有m个基分类器,FNi表示第N层的第i个基分类器,ZN-1表示第N层的上一层输入,μ为基分类器的期望结果,代表平均预测能力,σ2为平均方差,代表训练和预测的差异效果,Y代表预测值结果。
可以看出假设m给定的情况下,则要求各个分类器方差要最小。为了使每一层的输入数据稳定,由(2)(3)(4)可以看出,在每层给定相同m的情况下,級联效果的方差也是和各自基分类器有关。
因此对于Deep Forest,在给定基分类器个数的前提下,要发挥最佳自动化迭代效果,对于基分类器要求较高,即要同时满足偏差和方差小的特性。
原始Deep Forest级联中,采用的是随机森林和完全随机树森林作为基分类器,这种分类器属于Bagging集成方式,而Bagging方式比较擅长处理方差大的问题,比如通过增加集成中树的颗数或随机采样。偏差学习方面需要根据特定的训练数据进行大量的算法调参(比如树的深度)[12],因此不太适用于多轮模型迭代的自动化应用场景。
保险购买行为预测场景训练数据每天具有千万级别的客户和投保数据更新,而且部分字段会随着时间推移发生非平稳性变化,因此容易造成训练样本和测试数据在一定时间内须重新迭代训练,因此对基分类器要求具备较强的偏差自适应处理能力。
目前基于树的集成中,擅长处理偏差的方法是Boosting结构。它是一种多个弱分类器的集成技术,通过每个弱分类器预测结果相加,根据给定的损失函数计算集成模型中下一个弱分类器的预测内容和自身弱分类器的权重,通过反复迭代,最终形成一套强大的分类器。
XGBoost[13]是GradientBoosting的实现,通过对损失函数引入二阶泰勒展开进一步的拟合和构建每个弱分类器,由算法自动计算所需的每个弱分类器个数和相关系数,全程无须人工特殊参与。
在每次计算损失时,引入上述正则计算,则会在整体上减小方差,进而达到基分类器既实现偏差小,又实现方差小的目的[14]。
另外,XGBoost有别于其他实现GradientBoosting技术的算法,主要体现在:
首先,在弱分类器选择上不仅支持CART分类器,同时支持线性分类器;其次,在分类器训练分割点选择计算上,最大化采取CPU多线程并行计算方式,对于训练数据的稀疏情况(比如缺失值)提供相关默认处理方式,以及对于特征列的存储做了内存压缩和优化,因此在时间和空间上提高了算法效率。
综合上述考虑,保险购买行为预测场景中可将XGBoost作为Deep Forest的基分类器使用。
2.2 样本不均衡评估标准选择
Deep Forest级联结构默认情况下是采用准确度(Accuracy)来度量每层性能。
在保险购买预测的二分类问题中,相关的混淆矩阵如表1所示。
实际场景中,真实不发生购买的人群数量远大于真实发生购买的人群数量,属于正负样本比例非常不均衡的应用场景。因此若用式(10),无法客观地评价识别TP的能力。
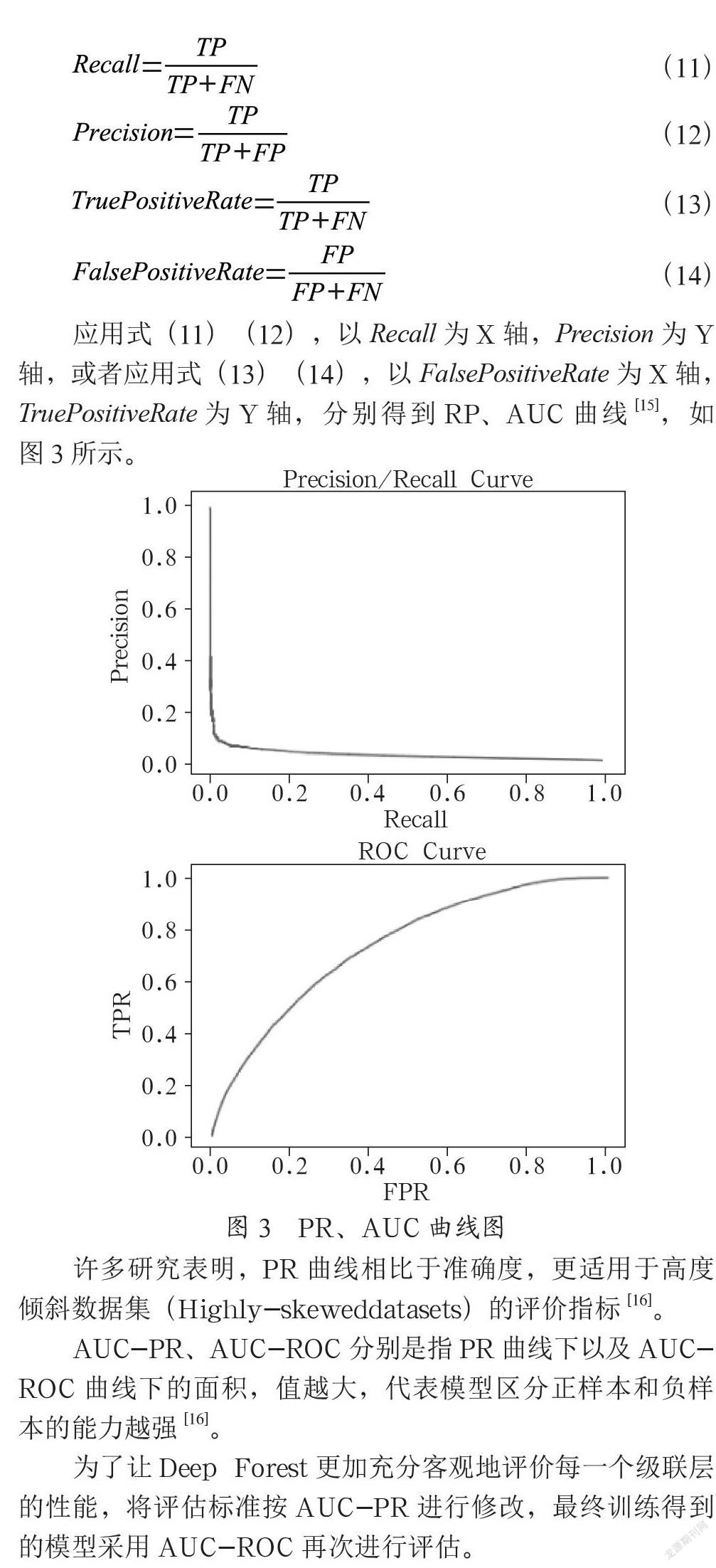
针对衡量TP的识别能力,有如下公式[15]:
应用式(11)(12),以Recall为X轴,Precision为Y轴,或者应用式(13)(14),以FalsePositiveRate为X轴,TruePositiveRate为Y轴,分别得到RP、AUC曲线[15],如图3所示。
许多研究表明,PR曲线相比于准确度,更适用于高度倾斜数据集(Highly-skeweddatasets)的评价指标[16]。
AUC-PR、AUC-ROC分别是指PR曲线下以及AUC- ROC曲线下的面积,值越大,代表模型区分正样本和负样本的能力越强[16]。
为了让Deep Forest更加充分客观地评价每一个级联层的性能,将评估标准按AUC-PR进行修改,最终训练得到的模型采用AUC-ROC再次进行评估。
2.3 改进算法说明
综合以上分析,在保险购买预测应用中,提出了基于XGBoost改造的Deep Forest级联算法的使用。具体算法示意过程如图4所示。
在应用过程中,采用XGBoost对原始特征和样本浅层学习并且完成特征选择,而在级联过程中,采用XGBoost浅层机器学习算法作为Deep Forest级联构建块,级联过程中每层是由上一层每个构建块的交叉验证输出值和初始选择的特征值进行拼接,作为该层输入供各构建块进行训练,各层用AUC-PR标准作为级联构建深度学习的自适应过程。
假设每层构建块的个数M,每个构建块的参数Mi,连续i次(early_stopping_rounds)作为整体算法的超参数设置。
具体训练步骤的算法描述如下:
输入:训练集D={(X1,Y1),(X2,Y2),…,(Xn,Yn)}
特征集F={F1,F2…,Fn}
过程:Base_gcforest_mXgboost(D,F):
F’,M=XGBoost(D,F)#利用XGBoost进行特征选择。#F’为选择后的特征,M为选择特征所使用的参数
While(1):#进入级联计算
For(i=0;i<M;i++):#M为每层构建块的个数
Dit,Dif=XGBoost-i(D,F’,Mi)
#Dit,Dif分别为第i个构建块XGBoost经K
#折交叉验证的各个训练集计算的正负概率值
#Mi为第i个构建块的M参数随机微调取值
Sum_Dt=Sum_Dt+Dit#累加所有构建块正概率值
Sum_Df=Sum_Df+Dif#累加所有构建块负概率值
R(L)=AUC-PR(D,Max(Sum_Dt/M,Sum_Df/M))
#根据D中的真实值与该层各个构建块预测均值最大值作为预测值,进行当前L层的AUC-PR计算。
If(R(L-I)>max(R(L),R(L-1),R(L-2),..,R(L-I+1)):
break#如果当前L层AUC-PR值连续I次未大于L-I层AUC-PR值,则结束级联,最好的层数记为L-I层
Dtf=(D1t,D1f,D2t,D2f,D3tD3f,,….Dmt,Dmf)
//将构建块每项结果进行叠加拼接
D<-(D,Dtf)#将该层计算出来的每个样本正负概率值,拼接训练集D,形成新的D,作为下一层输入
对于预测部分,取AUC-PR值最大的层(即上述训练步骤中的L-I层),计算运算到该层中各个XGBoost构建块的预测结果,进行求和取均值,并且将最大值作为最终的预测结果。
另外,在保险购买预测场景中,通过将每层分类器进行5折交叉验证,用于控制样本过拟合风险。
在这种改进之后,能够使得XGBoost得到进一步的深度优化,整个框架下的级联收敛效果稳定性得到加强,另外非常便于处理样本不平衡的场景使用。
3 实际应用
3.1 场景数据
在保险购买预测模型中,通过业务场景确认、特征选取以及数据追溯加工,经数据提取、探查和清洗,最终得到相关客户保单等数据,作为原始特征及训练样本数据。数据统计情况如表2所示。
在所有的特征数中,类型特征占比在60%左右,类型特征中二值特征占比在80%左右。
业务场景的目标是预测客户是否会再次购买保险产品的行为,过程中将购买行为作为正样本,不购买行为作为负样本进行标识。从标注情况来看,该学习样本具有正负样本比例不均衡特点;同时,根据业务应用场景,最终模型效果不仅要满足精准预测要求,而且还需满足不同使用场景下对预测群体的查全率要求。
因此,该场景具有典型的数据量大、特征稀疏,同时正负样本比例不均衡的特点。
3.2 应用方案说明
为了客观评价改进算法和原有算法的性能,在实验过程中,采取如下应用对比流程,如图5所示。
由单个XGBoost分类器进行完成数据训练后,按特征重要性排序提取相关特征,然后分别送入Deep Forest原始算法和基于XGBoost改造的Deep Forest級联算法进行训练生成模型,最后用AUC-PR和AUC-ROC进行性能评价。
两种级联算法的超参数设置如表3所示,可以看出,两个深度优化算法主要在级联构建块和自适应评价标准上有所区别。
3.3 结果分析
3.3.1 特征计算结果
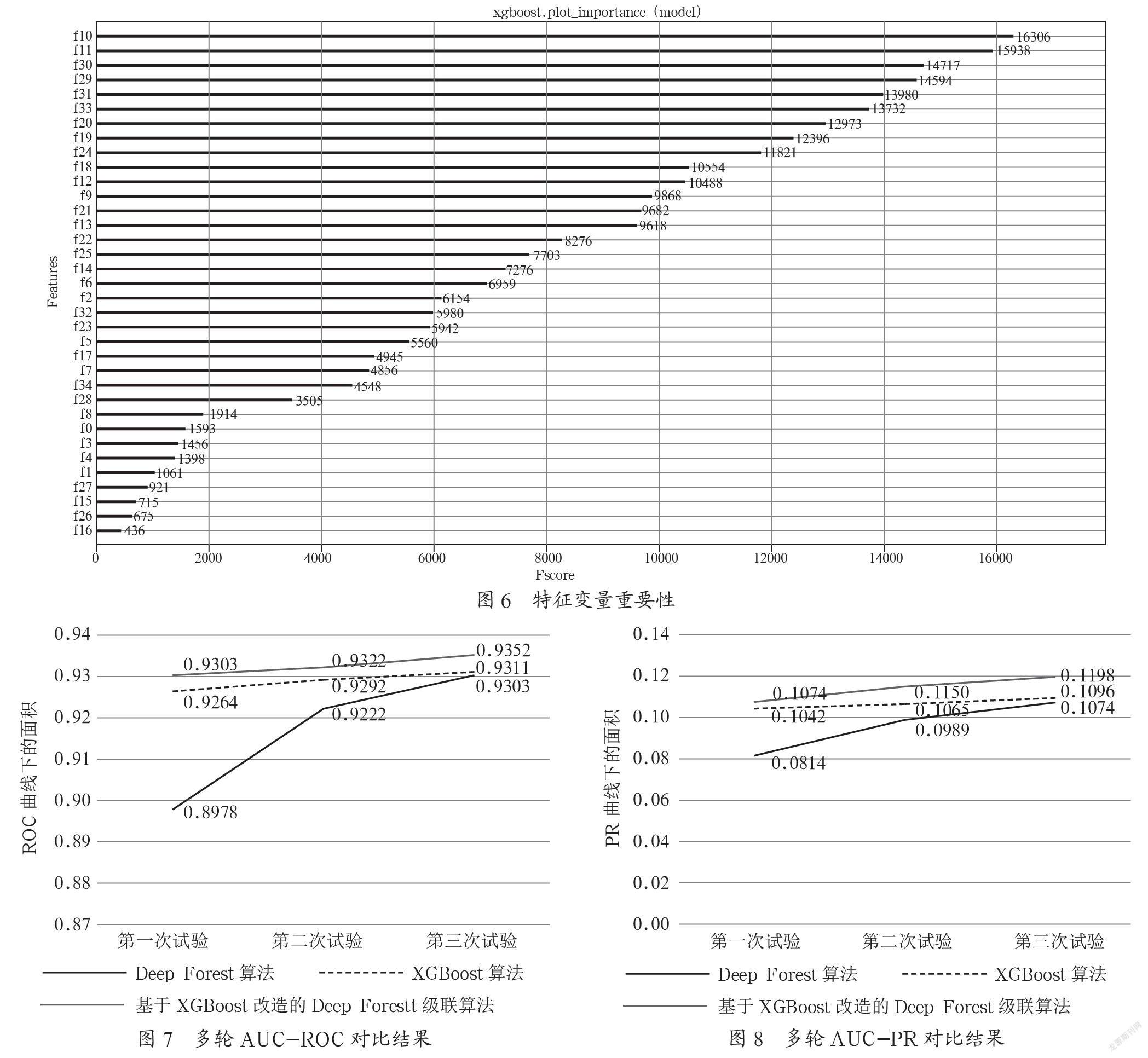
原始样本经特征加工后的特征变量,使用XGBoost进行特征变量挑选,最终选取了35个特征变量,从而可以判断这些特征变量对客户购买预测行为影响更为明显。分析结果如图6所示。3个算法将利用相同的35个特征开展模型构建。
3.3.2 算法效果分析
结合35个特征和原始样本,分别在Deep Forest、基于XGBoost改造的Deep Forest级联算法进行效果实验比较,采用相同的测试数据集进行验证结果,相关的AUC-ROC曲线和AUC-PR曲线对比如图7和图8所示。
结果表明,在三轮参数调优过程中,基于Deep Forest改造的多层XGBoost的训练效果,无论在AUC-ROC或AUC-PR方面,都比原有的Deep Forest级联效果更好,而且效果更加稳定。
同时本文还加入单个XGBoost与基于XGBoost改造的Deep Forest级联算法的比较;可以看出,改进算法与单个XGBoost在性能方面相比,也得到了深度优化的效果。
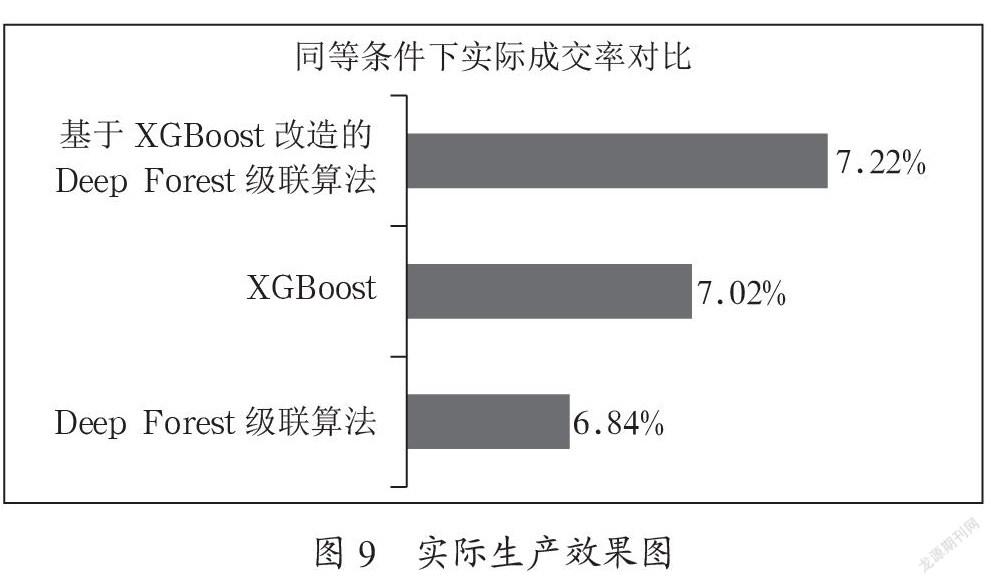
3.3.3 实际投产效果对比
根据上述三个算法完成的三个模型,分别在相同的预测集进行投产预测。
跟踪三个月在同一查准率的情况,三个模型实际产生的效果表现如图9所示。
图9中,相同条件是指同一个地区,同一群客户,同样的时间段内进行比较。成交率是“模型预测客户购买保险行为,且客户实际会购买保险人数”与“预测客户购买保险行为”人数的比值。由于该预测是对客户未来一段时间内发生购买保险行为的预测,而该统计结果只是距离模型投产之后两个月的情况,因此实际成交结果还会增长。
从数据实验测试和现有投产效果对比来看,基于XGBoost改造的Deep Forest级联算法的实际生产效果,分别比原有XGBoost算法和原Deep Forest算法提高2.8%和5.6%。因此可以认为基于XGBoost改造的Deep Forest级联算法在深度学习方面,起到一定的优化效果。
4 结 论
针对保险购买预测数据中样本量大、特征稀疏以及正负样本比例不均衡的场景应用,本文在原始Deep Forest算法基础上,提出了基于XGBoost改造的Deep Forest级联算法。该算法将XGBoost作为基分类器,引入Deep Forest级联构建块,同时将AUC-PR值作为Deep Forest级联自适应评价标准。
通过保险购买预测场景中的对比应用,实践表明,基于XGBoost改造的Deep Forest级联算法,在预测效果上均比原始Deep Forest更优,可为其他相似场景下的应用提供新的思路。同时,本文提出和使用的算法对比方案,也可为浅层机器学习算法向深度优化方向发展过程中的对比分析提供重要实践参考和借鉴。
参考文献:
[1] 田敏,李纯青,李雪萍.需求成熟度模型的商业银行零售客户交叉购买行为预测研究 [J].西安工业大学学报,2013,33(5):392-397.
[2] 黄聪,王东.基于RFM分析模式与马尔可夫链的客户行为预测模型研究 [J].情报杂志,2009,28(S2):143-146+69.
[3] 祝歆,刘潇蔓,陈树广,等.基于机器学习融合算法的网络购买行为预测研究 [J].统计与信息论坛,2017,32(12):94-100.
[4] 李栋,张文宇.基于FOA-ELM的客户基金购买行为预测仿真 [J].计算机仿真,2014,31(6):233-237.
[5] 吴玉锋.社会阶层、社会资本与我国城乡居民商业保险购买行为——基于CGSS2015的调查数据 [J].中国软科学,2018(6):56-66.
[6] 王垒.互联网人身保险购买意愿研究 [D].杭州:浙江财经大学,2016.
[7] 赖春燕.数据挖掘在我国家庭保险购买行为分析上的应用 [D].哈尔滨:哈尔滨工业大学,2017.
[8] MURTHYSK.AutomaticConstructionofDecisionTreesfromData:AMulti-DisciplinarySurvey [J].DataMiningandKnowledgeDiscovery,1998,2(4):345-389.
[9] 孙志军,薛磊,许阳明,等.深度学习研究综述 [J].计算机应用研究,2012,29(8):2806-2810.
[10] ZHOU Z H,FENG J. Deep Forest:Towards an Alternative to Deep Neural Networks [C]//IJCAI-17,2017:3553-3559(2018-05-14).https://arxiv.org/abs/1702.08835v2.
[11] FENG J,YU Y,ZHOU Z H,.Multi-Layered Gradient Boosting Decision Trees [C]//arXiv:1806.00007.(2018-05-31).https://arxiv.org/abs/1806.00007.
[12] 曹正凤.随机森林算法优化研究 [D].北京:首都经济贸易大学,2014.
[13] CHEN T Q,HE T,BENESTY M,etal.XGBoost:Extreme Gradient Boosting [EB/OL].(2019-08-01). http://ftp.igh.cnrs.fr/pub/CRAN/web/packages/xgboost/index.html.
[14] DIDRIKN.TreeBoosting WithXgboost-Why Does XGBoostwin“Every”Machine Learning Competition [EB/OL].(2017-10-22).https://brage.bibsys.no/xmlui/bitstream/handle/11250/24 33761/16128_FULLTEXT.pdf.
[15] 周志华.机器学习:第1版 [M].北京:清华大学出版社,2016.
[16] DAVIS J,GOADRICHM.xgboost:The Relationship Between Precision-Recall and ROC Curves [EB/OL].International Conference on Machine Learning.(2006-01-15).https://minds.wisconsin.edu/bitstream/handle/1793/60482/TR1551.pdf?sequence=1&is Allowed=y.
作者簡介:林鹏程(1980-),男,汉族,福建龙岩人,算法工程师,硕士,研究方向:人工智能在企业中的应用;唐辉(1981-),男,汉族,湖北天门人,高级工程师,硕士,研究方向:人工智能在企业中的应用。
