一种手语识别装置设计
2019-09-07方全彪许梦文宋晓娜王新勇
邢 倩,方全彪,许梦文,宋晓娜,王新勇
( 河南科技大学,河南 洛阳 471000)
随着社会的进步,聋哑人正逐步融入大众生活,但是对于正常人来说能使用手语的人却很少,这也造成了聋哑人在日常生活中与普通人的交流障碍。聋哑人与正常人之间的交流主要有两种方式:手语翻译和书面表达[1]。但是手语翻译需要专业人员和高昂的费用,书面表达主要通过画图或文字交流,效率不高且不方便。在这个背景下,本文提出一种基于弯曲传感器的手语识别装置,不仅能够降低手语翻译成本,而且能够实现便捷高效的手语识别。
1 总体设计

图1 总体结构图
本手语识别装置总体结构主要由STM32微控制器、RFP弯曲传感器、MPU6050加速度传感器、蓝牙模块、显示模块、语音模块组成。本装置由STM32作主控,通过弯曲传感器和加速度传感器分别采集手指、手腕的运动信息并转化为电压信号传给主控,再与已建立好的手语模块库数据相比较,从而判定所示手语含义,由显示屏显示同时由语音模块播报。总体结构图如图1所示。
2 功能实现
2.1 基于弯曲传感器的手指弯曲识别
RFP弯曲传感器是柔性可穿戴的薄膜式弯曲传感器(如图2所示),可对任何接触面的压力进行静态和动态测量[2],将传感器感应区所受压力转换成电阻信号,然后通过分压电路将电阻信号转化为电压信号。当传感器处于伸直状态,传感器阻值为30 kΩ,当弯曲约90°时, 传感器阻值约是50 kΩ。 结合传感器本身特性,搭建分压测量电路,传感器两端电压大小即代表弯曲程度的大小,利用 STM32微控制器自身所带的 AD采集功能[3],对所测量的电压进行模数转换并存储,等待进一步处理。

图2 薄膜式弯曲传感器
2.2 手指语模板库的建立
由实验测量可知,当手指伸直时,采集弯曲传感器两端电压约为1.6 V,当手指完全弯曲大约为2 V左右。STM32的AD采集分辨率是12位,即将0~3.3V均分为0~4096,所以对应单片机所采集到的值应该是1986~2482左右,两者相差500个值。以50个数为界将手指分为十个不同的弯曲程度,来表示手指当前的状态,建立手指语的模板库。定义一个数组,每个元素代表一个手指,元素的值代表手指的弯曲程度,在未接受训练计划前,对系统采用均分制,将1980~2480均分为十份以0~9代表不同的程度。例如手势A只有一个大拇指伸直,则对应的数组可以表示为 {2,9,9,9,9 ,9,9,9,9,9}。
另外模板库可以通过使用者的训练来进行完善,让系统根据使用者的自身习惯建立适合的数据库。
2.3 手指语的实现
系统运行中会不断地进行弯曲电阻的电压值采集,将电压值划分为0~9不同的等级,10个手指的弯曲程度记录在一维数组中,一次采集完成即对模板库进行对比,寻找是否相对应的词条,如果找到匹配词条输出数据。手指电压采集可能是{2080,2472,2462,2466,2468,2467,2477,2453,2480,2446}对应的弯曲等级是{2,9,9,9,9,9,9,9,9,9}。这样在模板库里就能找出对应的词条A。
2.4 手势语的识别
手语不仅包括手指语,通常还有手掌的空间运动,二者结合共同构成手语。所以如果要更全面的进行手语识别,需要在手指语的基础上添加手掌的姿态解算。
2.4.1 手掌姿态的检测
本系统采用MPU605六轴陀螺仪传感器,可以测量三轴加速度、三轴角速度,并且内部自带了硬件滤波,可以减少程序的繁琐。本设计所采用的MPU6050传感器自带数字运动处理器DMP,且InvenSense公司提供了一个MPU6050传感器的嵌入式运动驱动库,可以将原始数据结合DMP输出的6轴姿态解算数据,直接转换成四元数输出,可以很方便地计算出欧拉角,从而得到俯仰角(P),横滚角(R),航向角(Y)[4]。核心计算:四元数就是包含四个元的一种数,可表示为Q=q0-qv=q0+q1i+q2j+q3k其中,q0,q1,q2和q3都是实数,q0称为实部、qv=q1i+q2j+q3k称为虚部。
q0=quat[0]/q30;
q1=quat[1]/q30;
q2=quat[2]/q30;
q3=quat[3]/q30;
P=asin(-2*q1*q3+2*q0*q2)*57.3+P-error
R=atan2(2*q2*q3+2*q0*q1,-2*q1*q1-2*q2*q2+1)*57.3+R-error
Y=atan2(2*(q1*q2+q0*q3),0*q0+q1*q1-q2*q2-q3*q3)*57.3+Y-error
其中P-error,R-error,Y-error为误差纠正数
上述公式就是将一次的姿态变换分别用四元数矩阵和欧拉角矩阵表示出来[5]。
同时我们也可以从MPU6050中获得手掌运动状态中的三轴加速度,通过加速度积分可以得到速度,速度积分可以得到位移[6]。对于计算机控制系统,采样时间极短,可以认为这段时间内的加速度是恒定的,根据公式X=V0*T+1/2AT^2,V=V0+a*T ,可以计算出该时间段内的位移大小,并且将末速度作为下次计算的初速度。这样就能得出手掌在空间的位移情况。
2.5 手语模板库的建立
每个手语过程在基于香农采样定理的前提下,将运动过程进行时间细分。如一个手语动作在1 s内完成,将其过程记录为10组数据,每组数据中包括100MS内的位移情况和姿态(俯仰角、横滚角、航向角)。这样一个动作的手掌运动就可以用10*6的多维数组。再加上手指语的手指弯曲情况也按照时间细分即为10*10的多维数组,基于这160个数据来表示一个完整的手语词条。手语模板库同手指模板库的建立过程相同,但是手语复杂多样,所以需要在使用者训练数据基础上建立。
2.6 隐马尔可夫模型(HMM)的数据分析
隐马尔可夫模型(Markov Model)是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域[7]。手语识别传感器数据与语音数据类似,都是时序序列,因此本系统选用在语音识别领域应用广泛的隐马尔科夫模型作为手势识别模型。将隐马尔可夫模型应用于手语识别系统,它可以根据用户的历史数据,来提高手语的识别能力。主要流程图如图3所示。

图3 隐马尔科夫模型主要流程图
一个隐马尔科夫模型分为两部分,一个是马尔科夫链,用π,A描述输出状态序列;另一个是随机过程由B描述,产生观察值序列,所以HMM模型可以写成一个三元组(π, A, B)。如果一个系统可以作为HMM模型被描述,就可以用来解决三个基本问题:使用前向算法(forward algorithm),针对一个观察序列匹配最可能的系统;使用Viterbi算法,对于一个已生成的观察序列,确定最可能的隐藏状态序列;使用前向-后向算法(forward-backward algorithm),针对已生成的观察序列,决定最可能的模型参数。算法主要分为两步:
第1步:使用前向后向算法对经过特征提取的手指弯曲、手掌运动序列,即观察值序列,进行训练学习得到该手势对应的HMM模型参数。
第2步,使用前向算法将手语特征序列作为输入,计算产生此序列的概率,找出它最大时的模型,该模型对应的手势即为识别结果。
为验证作品的识别效果,每种动作采集50组数据,其中10组用于训练HMM模型,40组用于识别。识别效果如表1所示。手势从左到右依次对应1-4的编号。
3 总结
手语的研究不仅有助于改善聋哑人的生活、学习和工作条件,同时也可以应用于动画的制作、医疗研究、游戏娱乐等诸多方面。本设计利用计算机控制系统的方法对手语的提取、识别设计了新颖的算法思路,但是由于隐马尔科夫模型算法实现对主控芯片要求极大,若不计成本换用高级芯片,则必然与设计初衷相悖。而且在实际的操作中仍有着很多的难题。总之计算机控制系统推动着我们的发展,但是它仍有不足的地方需要我们一起完善。
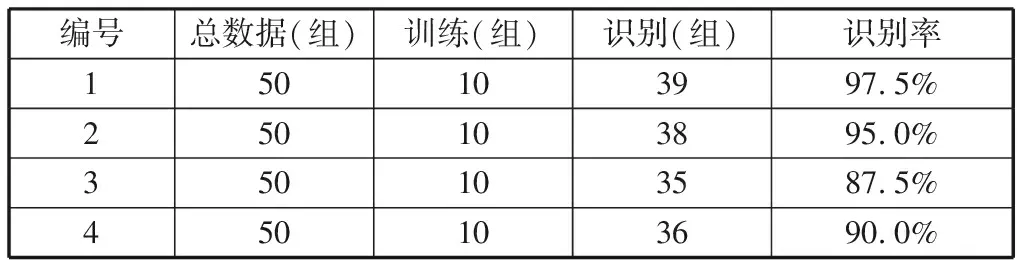
表1 训练HMM模型的实验数据
