基于群组用户画像的图书馆信息智能推送服务
2019-09-06兰冰
兰 冰
(德宏职业学院图书馆,云南 德宏 678400)
用户画像是通过收集用户相关信息,采用定量与定性相结合的分析方式,建构符合用户特点的标签化模型,以完整细致地勾勒出用户信息全貌,进而更好地预测用户需求的工具。而群组用户画像是对个体用户画像进行聚类分析,采用不同的模型、算法与技术,从多个维度发现规模较大的用户群体,或将特征类似的用户归为一类,从而在提供服务时可以优先满足核心群体的需求。群组用户画像的生成,方便对用户进行精准分类,结合不同群体的特点选择最为适宜的服务模式。群组用户画像在产品研发、数据挖掘、精准营销等领域得到广泛应用,也成为图书馆为用户提供智能化服务的必要手段。如今信息环境错综复杂,用户对高质量信息的需求,与信息来源繁杂、数据处理繁琐之间的矛盾日益突出,也对图书馆信息推送服务提出更高的要求[1]。图书馆基于真实积累的用户信息数据,选择适宜的模型与算法建立用户标签体系,能够反映用户群体在获取图书馆服务中的行为轨迹,进而深入挖掘用户的潜在需求,全面提高信息推送的智能化水平。
1 用户画像技术应用于图书馆的作用分析
作为大数据环境下全方位描述用户信息的工具,用户画像技术被引入图书馆服务是可行的,也是充分利用大数据资源,实现图书馆信息服务智能化的有效方式。
1.1 对大数据资源的合理利用
大数据时代各类数据资源纷至沓来,用户在利用图书馆过程中,也会产生大量的各种类型的数据资源,若对这些数据进行深入挖掘与合理利用,将获得巨大的价值。然而面对来源广泛、格式多样化的信息,很多图书馆往往感到无所适从,不知道如何对数据进行开发,甚至一度受到信息过载、知识迷航等问题的困扰。一些学者虽然提出可视化分析、网格分析等新技术,试图解决图书馆存在的问题,然而这些方法仅能够获取与用户相关的部分信息,难以保障对用户需求的准确把握。用户画像技术的引入,则可以依托大量用户真实信息建立用户群体模型,并从中提炼出有价值的内容,进而实现以用户为中心的智能化服务。
1.2 实现精准智能化服务的需要
图书馆用户群体来自各行各业,对信息服务的需求也是多样化的。要想满足不同行业、不同层次用户的需求,就需要图书馆做好用户分组分类工作,深入分析不同群体的兴趣爱好,找到这些用户的需求点,与信息资源进行精准化匹配,为他们提供具有针对性的服务。借助群体用户画像技术,正好可以满足对图书馆用户聚类的要求,方便图书馆依托大规模用户数据,发现不同群体的特征与潜在需求,主动为他们提供个性化、精准化的信息,改变被动服务的局面。构建群组用户画像模型,也是图书馆建设智能信息推送系统的必要环节,能够依托全方位的用户信息描述,为系统调取、检索与处理信息资源提供可靠依据[2]。
1.3 抓住核心用户群体的需要
用户数量与用户忠诚度,是衡量信息内容提供方服务质量的重要指标。图书馆作为信息服务机构,要想吸引并留住核心用户群体,就有必要深入、全面地挖掘用户需求。群组用户画像作为分析用户需求的可靠工具,能够辅助图书馆掌握不同服务场景下用户的大概率行为,通过建立用户属性的标签化体系,形成对用户行为特点的分层分类分析,进而提高对不同情境下用户需求的分析判断能力。作为具有向量特征的结构化数据集,群组用户画像也可以反映用户的情绪、爱好等心理特征,依托深度学习技术勾勒出可以自主演化的新用户模型,从而发现用户需求的新趋势,实现对用户行为的科学引导。
2 图书馆群组用户画像模型的构建方法
群组用户画像的构建,需要采集用户真实数据,借助机器学习、神经网络、数据挖掘等技术,依托贝叶斯函数、决策树、聚类算法建立动态模型。大数据环境下图书馆获取用户数据的渠道增多,方便全面掌握用户信息,如从行为数据、借阅记录等多个维度描述用户的属性、偏好特征,提炼用户的兴趣标签,从而形成生动具体的群组用户画像模型。
2.1 用户数据资源收集
大数据时代用户数据来源广泛,大数据技术的应用使得图书馆信息资源的互通互联达到前所未有的高度。尤其是移动终端的应用,在为用户获取图书馆资源带来便利的同时,也为图书馆提供了多样化、立体化的数据来源渠道[3]。要想绘制完整的群组用户画像,图书馆可以将用户数据资源分为5大类,包括基础信息、网络行为数据、兴趣偏好数据、情境数据、会话数据。其中要获取用户的基础信息,可以直接调取图书馆服务系统的用户注册信息;通过图书馆门户网站和移动APP,可以获得用户的内容收藏、主题分享等信息;通过检索系统可以获取文献传递、在线咨询等信息;通过智能传感设备,可以获取用户周围的天气状况、温度等情境信息。
2.2 建立用户画像标签体系
图书馆结合多方采集的用户数据,以机器学习的方式建立用户行为模型,从中抽象出用户属性、特征等标签信息[4]。然后结合用户需求动态变化,采用关联规则、回归分析等方式,不断修正用户行为、心理等核心数据,发现不同层级用户标签展现的显著特征,以获得全新的用户标签,让获取的数据与用户特点更为贴近,从而获得更加清晰的用户画像。鉴于用户大数据的不断衍生与动态变化,用户标签体系的构建趋于复杂,采用传统的单标签建模方式,很难保障对用户信息的深入挖掘[5]。因此,图书馆在广泛采集用户数据后,还需要从多个维度对这些数据进行分类处理,结合不同行业、不同领域的用户需求,在总结概括的基础上对用户信息进行标注,为不同的用户打上不同的标签,以方便计算机识别、理解与应用。
2.3 形成群组用户画像模型
图书馆在对用户数据进行清洗处理后,结合用户标签体系进行深入分析,发现不同用户群体的特点,然后从不同的评估维度评估用户信息子画像,以聚类分析的方式建立群组用户画像,具体流程如图1 所示。图书馆可以将群组用户画像分为数据采集、标签映射、数据挖掘3 个层次。首先对用户有效数据进行组织排序,存储于用户数据库中。然后对数据进行集成、过滤、分类等处理,采用逻辑回归、决策树等算法,掌握用户的个性化特征与群体特征,不断完善用户标签体系。最后,借助关联分析等技术对用户群体进行合理分类,掌握不同类型用户之间的复杂关系,将具有相同特征的用户集中起来,以获得群组用户画像模型。
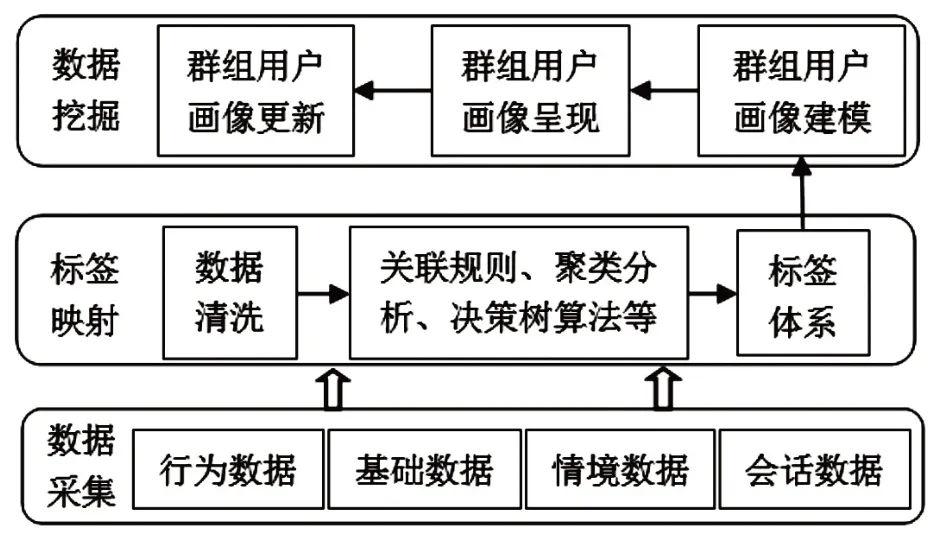
图1 图书馆群组用户画像建模
3 基于群组用户画像的图书馆智能信息推送流程
满足用户的个性化、智能化服务需求,是图书馆开展信息推送业务的出发点。图书馆在收集用户大数据建立用户画像模型后,还需要通过可视化分析等方式,确定用户群体特征与信息需求,进而保障信息智能推送服务质量。
3.1 用户画像可视化分析
在建立群组用户画像模型后,图书馆需要以整体可视化描述的方式,深入分析用户群体的行为习惯与知识结构,从中挖掘有价值的信息,这是图书馆服务系统掌握用户个性化需求,进而实现智能化推送的必要环节。图书馆用户群体的知识背景各异,信息需求多元化,图书馆可以从专业背景、性别、年龄等维度进行聚类分析,形成特定用户群的共有规律[6]。然后依据群组用户画像,具体分析不同群体用户的属性特点,从用户行为偏好、在线活跃度、借阅频率等多个维度建立可视化图表,得出不同用户群对信息服务的需求趋势。
3.2 群组用户信息推荐
图书馆实现智能信息推送服务,是基于前述建立的群组用户动态画像与可视化分析,得到对用户需求的全方位预测,进而主动为他们提供可靠服务,基本流程如图2所示。与移动新闻端等信息服务平台类似,图书馆对各类服务资源进行统一描述,建立符合用户需求的信息资源库,对大量用户数据进行标签化处理,采用关联分析与相似度分析法,了解用户对类似服务产品的喜好,形成群体用户的需求数据库,并借助信息智能推荐系统,以推荐列表的形式实现与用户需求的精准匹配。最后根据用户对推送服务的反馈情况,分析他们对智能推送信息是否满意,若不满意需要再次进行用户画像分析,为用户匹配新的信息推送列表。
3.3 用户画像评价调整
图书馆用户需求是动态变化的,随着时间、情境的变化,用户的行为数据也会随之更新,群组用户画像模型也需要不断进行调整[7]。群组用户画像模型是基于各类用户标签建立的,包含对用户偏好数据的采集、过滤与分析,在依据用户画像标签进行用户聚类分析,结合行为偏好建立用户群组后,还需要评价不同群体之间的差异。然后根据用户动态反馈及时更新群体偏好模型,实现对前期工作的检验和修正。在分析预测用户需求动态时,图书馆需要关注“舆论领袖”在群体中发挥的作用。这些用户扮演着信息中介的角色,能够极大地影响其他用户的价值判断,对于优质信息资源具有极强的分析、传播与分享能力。因此,图书馆可以从网络传播影响力角度进行群组用户画像评价,找到其中的“舆论领袖”,借助他们了解相关用户的反馈建议,进而不断优化智能信息推送模式。

图2 基于群组用户画像的图书馆信息智能推送流程
4 基于群组用户画像的图书馆信息智能推送的技术实现
群组用户画像所需的数据复杂多样,图书馆需要解决的一大难题就是在数据处理过程中,降低数据整合利用成本。为此,图书馆可以利用协同过滤、知识发现等技术,实现对用户特征信息的高效抽取,让馆员与用户之间的沟通关联化,以便为用户提供更便捷的服务。
4.1 基于协同过滤的个性化资源整合
图书馆借助群组用户画像模型,掌握不同类型用户的个性化需求,从而为用户推送个性化信息。由于馆藏资源类型丰富、格式多样,采用传统的信息检索技术,难以实现对这些信息资源迅速查询、处理、整合与传输,这就需要应用协同过滤技术,提高对用户数据的处理效率。通过对图书馆数据库资源的统一描述,结合用户画像对相关数据进行协同过滤,消除冗余数据,获得可以清晰展现用户全貌的有价值信息,以保障信息推送的准确度[8]。在这个过程中,图书馆要善于对用户画像进行分析,从中提取用户的属性特征,在关联聚类分析的基础上,把握用户群体的真实需求,并以协同过滤的方式调取符合用户需求的资源,形成个性化内容推荐数据库。
4.2 面向自然语言的知识发现技术
知识发现是融合机器学习、人工智能等众多学科的新型研究领域,具体而言,就是通过对大量异构数据资源的处理,从中提取潜在的、隐含的、易于理解的规则,从而完善知识增值的高级处理过程。在新闻推荐、个性化检索与智能客服等领域,知识发现均有广泛应用。图书馆在大数据资源处理阶段,采用面向自然语言的知识发现技术,可以实现对大规模数据的自动语义处理,提高对自然语言资源的集群、关联、分析、预测能力。自然语言处理拥有丰富的模型,可以满足图片、音频、文本等不同类型数据的处理需要,方便图书馆结合用户画像特点选择适宜的模式,构建不同信息资源的聚合体,发现其中有价值的内容与隐含知识,从而保障个性化推荐与用户需求的有效匹配。
4.3 推送结果的可视化呈现
图书馆用户数量庞大,需求多样,在为他们提供推送信息过程中产生的数据是惊人的,这些数据占用了系统存储空间,若不及时处理将降低系统运行速度。再加上根据群组用户画像分析用户需求过程中,涉及专业背景、行为偏好等众多复杂的关系图谱,增加了发现用户需求的难度。为此,基于群组用户画像的信息智能推送,需要图书馆在用户需求分析过程中,促进不同主题资源与用户偏好信息的匹配,以分布式文件系统减少冗余数据。同时采用可视化技术,以标签云图、知识地图等形式,向用户展现立体多维的知识,减少数据存储空间,提高服务系统响应速度。此外,还可以为用户提供可视化服务界面,按照用户要求将推荐结果转化为其希望的呈现形式,确保图书馆信息推送的准确性与个性化。
5 结语
大数据时代各种高新技术的应用,为全方位勾勒用户画像提供了条件,未来用户画像的应用领域也将不断延伸。在倡导以用户需求为中心的时代背景下,图书馆作为信息服务机构,充分借助用户画像发掘潜在需求,提高了信息推送的精准度。尽管当前用户画像技术的应用还不完善,但融合多项技术的用户画像分析,将成为图书馆制定信息服务决策的依据,也将成为图书馆的重要研究方向。
