一种高效人体行为特征提取方法
2019-09-06谭论正丁锐
谭论正,丁锐
(1.中山职业技术学院信息工程学院,中山528402;2.中山火炬职业技术学院信息工程系,中山528436)
0 引言
近年来机器学习的发展使智能视频监控技术得到了很大的进步[1-2]。人体行为识别是计算机视觉的重要研究领域。目前提出的人体行为识别方法大致分为两类:基于外观特征的方法[3-4]和基于运动的方法[5-7]。基于外观的方法捕获视觉信息以构建特征模型。Turek等人[8]提出了一种场景分析方法,其中场景元素的类别,如道路、停车区、人行道和入口,可以根据移动物体在其中和周围的行为进行分割和分类。但是,特征的尺寸变大,算法变得更加复杂,计算速度也很慢。此外,这些方法的质量高度依赖于鲁棒跟踪,由于噪声、遮挡、光照条件和阴影的变化,这本身就很困难。此外基于特征模型的方法还忽略了动作的固有时间信息。因此,目前的研究大多采用基于运动的算法,运动特征可以分为局部和全局特征。局部特征,如轮廓、密集的轨迹[9]、时空描述符[10-11]仅使用观察区域的信息。还需要计算显着性,这需要大量的计算时间,同时易受背景杂乱或光照变化等噪声的影响。全局特征,如运动能量图像[12]和动态历史图像[13]使用整个序列但忽略行动方向,难以捕获不同持续时间的动作。基于运动特征的方法计算量同样很高。
针对以上问题,本文提出一种新的基于运动的特征方法,解决了上述计算负荷高的问题。所提出的特征在尺度,方向和持续时间方面具有不变性。它基于光流,并且应用了几种降低噪声的技术。为了获得方向不变的动作表示和识别,通过考虑直方图中每个方向(左侧或右侧)的总量值来调整构造光流直方图的方向。此外,通过频域分析与频域变换框架显示所提出特征的移位不变性。
1 光流直方图
使用光流提取动作特征。由于背景噪音使其原始形式的光流难以使用,因此需要对噪声进行处理。我们使用直方图方法来降低噪声,以获得动作的代表性特征。
首先通过组合帧数作为块来减少背景噪声,对于每个块中的每个帧,计算光流。然后,在每个像素中,挑选每个轴中的所包括的帧之间的光流的中值,采用中位数流量矢量获得每个块的每个像素的光流中值。图1 显示了原始光流和中值流之间的交替。

图1 原始光流(左)和中值流(右)之间的比较
1.1 图像块的权重计算
HOG(梯度直方图)描述符已广泛应用于计算机视觉领域,因为它具有局部图像的几何和光照不变性。然而,HOG 描述符在实际应用中具有局限性,因为它没有旋转不变性并且对噪声更敏感。SIFT 方法基于局部图像属性为每个关键点分配方向,关键点描述符可以相对于该方向表示并实现图像旋转的不变性。因此,提出了旋转不变HOG 描述符(R-HOG),将角度-π到π 分为多个方向区域Nbin。为了对称,Nbin必须是4的倍数。图像块中的每个像素具有中值光流向量vˉ,图像块的初始直方图由以下方程构成。对于每个范围,对应的中值流向量的大小累加得到每个方向区域的权重:
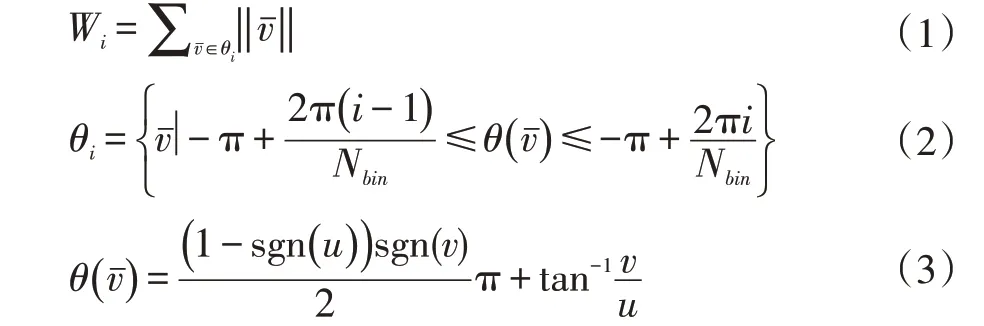
其中,Wi是每个方向区域的重量,1≤i≤Nbin和θ是矢量的方向角vˉ,vˉ从-π 到π,使用这些权重,构建图像块的初始加权直方图,如图2所示。
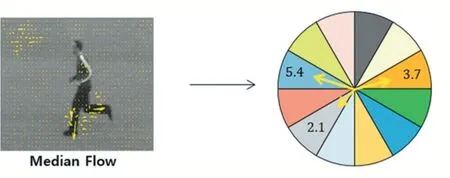
图2 来自中值光流的每个图像块的重量计算
1.2 行为的方向不变性
由上文的步骤中得到了初始直方图的数量NB。然而,对于具有不同方向的相同动作这些直方图具有不同的分布。例如,将左臂拉伸到左侧,右臂拉伸到右侧,具有不同(但对称)的直方图。为了减少识别方法的计算量,本文采用对齐方向的方法将不同方向的相同动作采用相同的直方图:通过比较直方图中每个半边的总量来解决预测动作的方向,即在构造光流直方图时在分配行为的方向,从而达到行为的方向不变性。将直方图的右半部分分配为从到,左半部分是其余部分,如果右半侧的量值大于左侧,则每个方向区域的重量用对称方向区域替换,进行方向对齐。然后我们得到块的对齐直方图,方向对齐过程如图3 所示。

图3 不同方向的相同动作直方图对齐过程
2 直方图正则化和连接
直方图的正则化对于尺度不变特征生成是必要的,因为即使动作是相同的,直方图的权重也会随着人物在场景中的大小而变化。然而,将每个直方图归一化为总权重为1 将扩大无动作块中的噪声效果,因此,通过在直方图的总权重中引入阈值τ来解决这个问题。
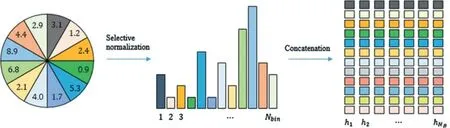
图4 直方图归一化和连接
3 频率域低通滤波
因为每个演员在不同的时间开始动作,因此,虽然直方图H 作为一个动作的表示,仍然很难作为一个特征直接代表动作,因此需要加入时间特征。我们利用傅立叶变换将时间域转化成频率域,保证时间变换时特征的不变性。我们通过傅里叶变换后使用幅度来获得移位不变属性。
此外,虽然中位数减少了部分噪音,仍然有大量噪音存在。由于噪声通常具有高频率,因此通过频域中的低通滤波来消除噪声。频域处理分为两个主要部分。如下式所示:

4 实验
为了验证所提方法的有效性,我们在KTH 动作数据库和我们自建数据集(Smart 类)上进行了训练与测试。实验采用OpenCV 和Python 用于在Ubuntu 16.04操作系统上使用HP-EliteDesk-800-G4 内配2 块1080NIVEA 独立显卡的图形工作站上进行仿真。我们在每个数据集中使用相同的实验设置:Nf=5,Nbin=32,τ=0.1,wbin=2 π,wB=0.5 π。分类由多类SVM[21]进行,使用Liu[22]提出的算法提取光流。
4.1 KTH数据库
KTH 动作数据库在同一场景中捕获,由同一场景中的多个类似动作执行。KTH 数据集由600 个低分辨率视频序列(180×144 像素)组成,其中包含六种不同的人体动作:handclap、handwave、walk、jog、run 和box。它们由4 个人在4 种不同的场景(室外,户外用放大的相机,户外用不同的衣服和室内)重复演出。这是一个更具挑战性的数据库,需要考虑与人体动作相关的上下文信息。

图5 KTH数据集
我们使用原始数据库拆分进行训练和测试,16 个类别用于训练,9 个数据类别进行测试,本文算法在KTH 数据库中识别结果混淆矩阵如图6 所示。图中“鼓掌”和“挥手”的混淆度相对较高,原因是鼓掌和挥手的动作相似导致特征相似度高,相似度很高的“跑”、“慢跑”行为之间的混淆度为5%,说明本文方法具有很高的区分度。本文在KTH 数据库上与其他现有方法进行了对比实验,所提出的特征检测方法的准确性如表1 所示。我们可以观察到:我们的方法的平均识别精度为96.3%,表明我们的方法过程简单且计算负荷相对较低,但与最先进的算法具有相当的性能。
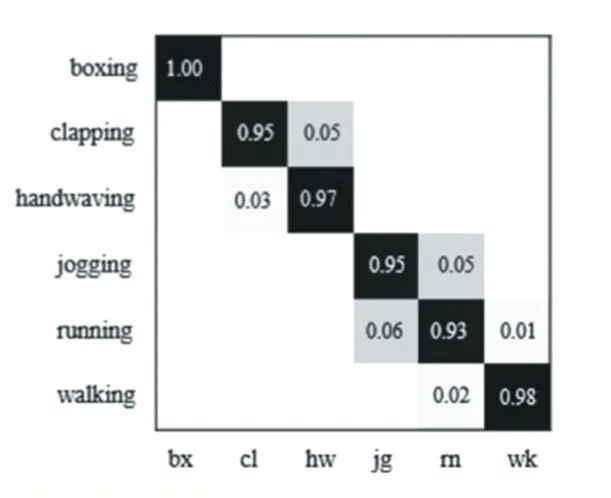
图6 KTH数据集中的混淆矩阵

表1 不同方法的异常检测结果
4.2 自建数据集(单视图)
我们的自建数据库包括单视图和多视图两种方式,数据集有6 个动作(站立、坐着、面朝下、伸展腰部、举手、挥手),包括12 组,每组30 人,共有2160 个活动视频和4 个摄像头的额外多相机组场景。单视图采用了单次测试的方法来测量准确度。单视图中的自建数据集及其混淆矩阵如图7 所示。本文算法的平均识别精度为93.17%,主要混淆部分在拉伸腰部和举手。由于在拉伸腰部和举手方面具有相似的运动模式,本文提取的特征在归一化和几何信息丢弃策略下在这两种行为特征提取的混淆度较高。

图7 单视图自建数据库和混淆矩阵
4.3 自建数据集(多视角)
多视图视频在同一个地方有10 个人,并且每个人都有跟踪框。图8 显示不同视图中的多视图组场景。每个小组场景有4 个视图,我们使用通过SVM 的分数多数投票机制识别行动。训练是在单视图视频中进行的,我们使用多视图场景作为测试。首先,我们在每个视图中判断每个人的行为,定义了4 个决策,通过SVM得分类为一个动作。当SVM 得分低于阈值的时采用多数投票得到最终的行动决定。最后本文方法的多视点场景的平均精度为87.04%,尽管对象或其他人严重遮挡时,本文算法但仍显示出较好的辨别性能。

图8 不同视图中的多视图组场景
5 结语
本文提出了一种新颖的基于光流的特征描述方法,本文特征提取方法的计算负担相比于已有方法更低,同时具有尺度不变性,对不同的视频帧长以及行为方向的鲁棒性较好。由于背景的光流包含一定的噪声,本文提出了几种方法来减弱噪声影响。首先,计算图像块光流的中值,然后,对基于整体量级的直方图进行正则化,最后在频率域进行低通滤波减少噪声影响。所提出的特征具有方向不变的属性对于具有不同方向或持续时间的相同动作具有相同的输出。在KTH实验数据集与自建数据集中与其他现有方法进行对比实验。实验结果表明了本文算法具有更好的有效性和对现实生活环境的适用性。
