全并行转置型FIR 滤波器在加速卷积神经网络上的应用
2019-09-06刘建梁袁贤珍
刘建梁,袁贤珍
(1.天津天瞳威势电子科技有限公司,天津300384;2.中车株洲电力机车研究所,株洲412005)
0 引言
卷积神经网络(Convolutional Neutral Network,CNN)作为人工神经网络的延伸,是第一个真正成功训练多层网络结构的学习算法,被广泛用于机器视觉、人工智能等领域[1]。
在卷积神经网络推理运算中,卷积运算为计算密集型运算[2]。由于卷积计算量庞大,需要设计与计算量相匹配的加速器。图形处理器(Graphic Processing Units,GPU)、现场可编程门阵列(Field Programmable Gate Array,FPGA)、专用集成电路(Application Specific Integrated Circuit,ASIC)是常用的神经网络加速器。在这些加速器中,FPGA 凭借它的高度并行计算、低功耗、可重复编程的特点而被广泛采用[3]。
本文受全并行转置型FIR 滤波器结构的启发,将这种结构应用在加速卷积神经网络卷积运算的FPGA设计中。在此结构基础上,使用Xilinx DSP Slice 的INT8 优化技术,最终使设计在运算速度和电路面积上都得到了优化。
1 卷积神经网络卷积运算
卷积神经网络卷积层由若干卷积单元组成,完成对图像特征的提取,卷积运算也是该网络中计算量最大的部分。典型的卷积运算示意图如图1 所示。

图1 卷积运算示意图
卷积层中的每个神经元与上一层的局部感受感受野相连进行像素的加权求和,其计算公式如式(1)。

式中,Xjl表示第l 层中的第j 个特征图;Xil-1为上一层的特征图的输入;Wlij为卷积核的权值。卷积核窗口按照一定的步长在特征图上滑动,每滑动一次产生一个卷积运算结果。当卷积核窗口滑动至行尾时,会向下移动一行并从左侧行始开始新的一行卷积,直到完成整幅图像像素的卷积运算。可以发现,参与卷积运算的像素之间是独立进行计算的,并没有前后依赖关系,这就为FPGA 流水线并行结构设计带来了可能[4]。
2 Xilinx DSP Slice INT8优化
DSP48E1 Slice 是Xilinx 7 系列FPGA 中的运算单元,乘法、乘加和乘累加是其最显著的功能,DSP48E1结构示意图如图2 所示。

图2 DSP48E1结构示意图
从图2 可知,DSP48E1 内部集成1 个25 位的预加器和1 个25×18 的乘法器,A 和D 是预加器的输入,B是乘法器的输入,INT8 优化技术就是利用预加器和乘法器,同时处理两个并行的INT8 乘法。
为了能并行计算A*B 和D*B,A 和D 之间要进行特殊的编码,既要保证高位不影响低位的计算,也要做到低位计算对高位的任何影响必须可检测、可恢复[5]。具体编码方法是把D 左移16 位后与A 相加,如图3所示。参考文献[6]提出了将(D<<16+A)*B 的结果分离出A*B 和D*B 方法,这里不再赘述。

图3 预加器输入A和D的编码方式
3 全并行转置型FIR滤波器
有限长单位冲激响应滤波器(Finite Impulse Response 滤波器,FIR 滤波器)是数字信号处理系统中的基本元件,在通信、图像处理、模式识别等领域有着广泛的应用。全并行转置型FIR 滤波器本质上也是FIR滤波器,只是从FPGA 硬件实现的角度,具有全并行和转置的特点。全并行是指依据输入信号的并行数据流而设计,每个时钟会得的一个输出响应;转置是相对于全并行直接型FIR 滤波器而说的,采用流水线技术和重定时技术,在直接型结构的基础上进行了转置[7]。以抽头数为3 的全并行转置型FIR 滤波器为例,系统转移函数如式(2):

滤波器结构框图如图4 所示,从图4 可以看出该结构的两个特点:①所有滤波运算的乘法同时执行;②所有抽头系数共享输入信号。如果输入信号和抽头系数都是8bit,这个结构恰好可以使用INT8 优化技术减少DSP的使用,用1 个DSP48E1 打包两个相邻的乘法器。
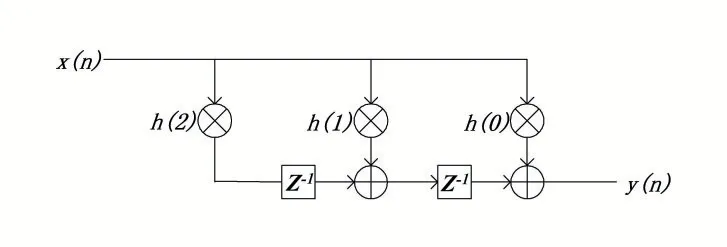
图4 抽头为3的全并行转置型FIR滤波器结构框图
4 卷积运算模块设计
对于一个卷积核尺寸为3×3 的卷积运算,可以看作是3 个抽头数为3 的FIR 滤波器分别滤波后再并行求和。这样做的好处是可以充分发挥FPGA 的并行计算特点,每个时钟周期完成一次卷积运算,同时能够减少DSP 的使用,本设计硬件实现框图如图5 所示。

图5 3×3卷积运算模块设计
输入特征图是以逐行的方式进入预缓存LineBuffer。由于LineBuffer 是由真双端口RAM 构成,在SAME 填充方式下,只需要预缓存特征图的第一行,随后生成列对齐的3 行特征图像素,以数据流的方式流入乘法器,完成卷积运算。需要注意的是,由于对特征图进行了填充,当卷积核移动到行首或者行尾时,需要额外的逻辑对乘法器的输出进行控制,保证卷积运算结果的正确。
5 结语
在Zynq7000 平台上对本设计进行了验证,实际使用6 个DSP48E1 Slice,结果符合预期。
本文基于全并行转置型FIR 结构和Xilinx DSP Slice INT8 优化技术,对量化精度为8 比特的卷积神经网络卷积运算模块进行了优化设计,兼顾了卷积运算的速度和面积。对于k*k 的卷积核,需要占用DSP Slice 数量为ceil(k/2)*ceil(k/2),对卷积神经网络加速器设计,具有很高的参考价值。
