智能驾驶中的车道检测及应用综述
2019-09-05王振阳
金 勇 王振阳
(1.环球车享汽车租赁有限公司; 2.上海交通大学汽车电子控制技术国家工程实验室; 2.上海交通大学学生创新中心, 上海 200240)
0 引言
智能驾驶技术包含环境感知、定位导航、路径规划与决策、车辆控制等方面。车道检测是环境感知的重要组成部分,并可为路径规划与决策提供有益的信息。
大部分车道检测算法都依赖视觉传感器。其中,基于单纯机器视觉的车道检测算法历史悠久,应用广泛;21世纪初,基于视觉传感器和其他传感器融合的车道检测算法开始兴起;近年来,随着硬件的发展和理论的成熟,出现了基于深度学习的车道检测,并取得了良好的效果。车道检测的结果可用于多种自动驾驶功能或高级驾驶辅助系统(ADAS),如车道偏离预警系统、车道保持辅助系统等。
实际道路可分为结构化道路和非结构化道路。前者具有清晰的道路标志和车道划分,环境背景单一,几何特征明确,典型代表为高速公路和城市干道;后者一般没有明确的道路标志,环境背景复杂,缺乏重复性特征,典型代表为乡村道路。本文主要探讨具有“车道”的道路,即结构化道路。
1 基于机器视觉的车道检测
基于机器视觉的车道检测一般选用单目相机或多目相机。检测的一般流程如图1所示。首先,对道路图像进行反投影变换,获得道路图像的俯视图;对俯视图进行滤波和阈值化,获得二值图像;提取二值图像的特征,并根据先验知识做一些后处理。以上即为基于特征的车道检测的过称。对于结构化道路,由于车道线等道路标志存在一定的规律和约束,可以建立道路模型,对图像后处理的结果进行拟合,从而实现基于模型的车道检测。
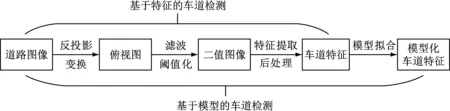
图1 基于特征/模型的车道检测的一般流程
图像后处理可分为单帧图像的后处理和多帧图像的后处理。Hough变换[1]是常用的单帧图像后处理方法之一,它将像素空间的点映射到参数空间,参数空间中曲线的交点对应像素空间中由相应参数决定的特征(如直线、圆等)。多帧图像的后处理可分为两类,一类是在提取多帧图像特征的基础上进行特征匹配,另一类是在提取一帧图像的特征后进行特征追踪或动态估计。多帧图像的后处理可基于单帧图像的后处理,也可直接基于提取的特征。
1980年代中期,E. D. Dickmanns等[2][3]提出了一种基于视觉的车道级汽车自主导航系统。系统采用长焦相机和广角相机的组合来采集图像,并利用组合卡尔曼滤波进行图像后处理。系统假设车道由直线和圆弧组成,通过计算曲率拟合车道。系统还具有车道保持功能,在典型的高速公路环境和的车速下,车辆的横向偏移不超过3%。
在随后的几年中,部分车企如通用汽车、本田、三菱等都开发了自己的车道检测系统。其中,本田的系统假设车道线为直线,利用Hough变换检测车道。通用汽车和三菱的系统则对对车道两侧的车道线施加了平行约束。
1994年,Karl Kluge[4]提出了ARCADE算法。这是一种无需先验知识的算法,它提取车道边缘点的位置和取向作为输入,利用直线和圆弧模型来估计车道的曲率和方向。算法采用最小中值平方抗差估计获得车道参数,具有较高的鲁棒性和可靠性,在输入边缘点的50%被噪声污染的情况下仍可得到准确结果。在此基础上,Karl Kluge和Sridhar Lakshmanan[5]于1995年提出了LOIS车道检测算法。该算法基于可变模板法,利用相似函数而非梯度阈值检测车道线边沿,在图像有大量杂波(如斑驳阴影、车道线破损等)的情况下仍可较好地识别。
1998年,Massimo Bertozzi和Alberto Broggi[6]提出了GOLD系统。系统采用串联的形态学滤波器提取车道线特征,检测车道;设计了专用的并行SMID计算机架构以实现低功耗下的高速实时运算,可在结构化道路上达到10 Hz的检测频率。
1999年,Chris Kreucher和Sridhar Lakshmanan[7]提出了LANA系统。与其他车道检测系统不同,该系统基于频域而非空间域。系统首先将图像划分为8×8像素的区域并在每个区域内进行离散余弦变换,然后利用贝叶斯算法对变换结果进行特征匹配。该系统在实验结果、计算速度和理论性能方面均优于LOIS。
2003年,Dong-Joong Kang和Mun-Ho Jung[8]提出了一种基于动态规划的车道分割算法。该算法将图像在垂直方向上划分为多个子区域。对于每个子区域,首先用图像聚类的方法得到车道线的初始位置,然后通过动态规划获得车道线的精确位置。与其他直接提取图像特征的算法相比,该算法可减小计算量。
2006年,Joel C. McCall和Mohan M. Trivedi[9]在总结前人经验的基础上,提出了用于车道检测和追踪的VioLET系统。该系统利用可变方向滤波器进行特征提取。可变方向滤波器可在方向和方向上独立卷积,从而加速运算;以有限个旋转方向的滤波器作为基底,即可得到任意方向上的响应。系统选用了回旋曲线车道模型,通过可变模板法进行曲率估计。车道追踪则选用了卡尔曼滤波法。
同年,王宏和陈强提出了一种适用于不同环境和夜间行驶的实时车道检测算法。与其他算法不同,该算法没有分别检测每条车道线,而是将同一车道两侧的车道线作为曲线对同时检测。算法采用随机抽样一致(RANSAC)算法进行车道拟合,车道模型选用双曲线对。
在此基础上,Mohamed Aly于2008年提出了一种城市道路车道标志实时检测方法。该方法同样采用随机抽样一致(RANSAC)算法进行车道拟合,车道模型选用三次贝塞尔曲线,兼顾了计算效率和准确度。
以上车道检测算法或系统多基于单目灰度相机。事实上,也有许多车道检测的研究是基于多目相机和彩色相机的。
1992年,E. D. Dickmanns和B. D. Mysliwetz提出了一种基于双目视觉的车道检测系统。系统可以25Hz的频率检测车道在水平和垂直方向的曲率。系统采用了时-空结合的四维模型,附加的时间连续性约束可大幅降低对图像处理的要求。2004年,Sergiu Nedevschi等提出了一种基于立体视觉的三维车道检测方法,该方法将车道视为三维表面而非平面。
1995年,Karl Kluge和Chuck Thorpe提出了基于彩色相机的YARF系统。该系统首先将彩色图像由RGB空间转换到HSI空间。在I(亮度)空间,对图像的处理与灰度图像相似,依然是利用直线-圆弧模型和卡尔曼滤波进行车道检测和追踪;在H(色调)空间,则可对不同颜色的车道线进行区分,从而在车道检测过程中提供更多信息。
2 基于多传感器融合的车道检测
结构化道路特征明确,边界清晰,十分适合视觉检测。但视觉传感器也存在一些不足(如在极端天气和弱光照条件下表现不佳)。如果将多种感知融合,往往可以取得较好的效果。
根据待融合的数据,多传感器融合可分为三种级别:数据级融合、特征级融合和决策级融合(图2)。数据级融合直接对传感器获得的原始数据进行融合,一般要求待融合的数据来自同类传感器,上文中基于多目相机的车道检测即可视为此类;特征级融合先进行特征提取,再对提取的特征进行融合;决策级融合则在特征提取的基础上,进一步作出初步决策,并融合决策得出最终结果。本章主要讨论特征级融合和决策级融合。
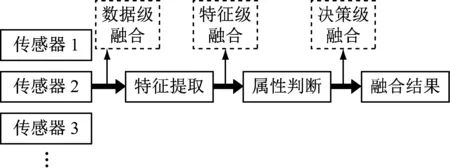
图2 多传感器融合的不同级别
2000年,J. Goldbeck等提出了一种基于视觉和高精定位系统的车道检测系统。在视觉部分,系统通过计算灰度图像的梯度检测车道线;在高精定位部分,系统利用差分全球定位系统(DGPS)和惯性导航系统(INS)确定车辆的精确位置和姿态,并与高精度地图进行对比,得出结果。视觉部分和高精定位部分只是互为备份,提高了系统的可靠性。
同年,Bing Ma等提出了一种基于相机-毫米波雷达融合的车道和道路边界检测系统。在此之前,基于相机的车道检测和基于毫米波雷达的道路边界检测往往是独立进行的,这类算法在任何一种传感器噪声较大时都会产生问题。针对上述情况,Bing Ma等基于贝叶斯理论,利用经验最大后验(MAP)估计对相机和毫米波雷达的检测结果进行了决策级的融合。
2001年,B. Southall和C. J. Taylor提出了一套基于彩色相机的道路形状估计系统。该系统利用粒子滤波器估计道路曲率及其变化率。在估计过程中,系统利用外部传感器采集车速和偏航率,用于估计相机的垂向偏置。同年,Sukhan Lee和Woong Kwon也提出了一种利用车速和转向角信息辅助的视觉车道检测系统。其中,车速信息来自主动阻尼悬架的脉冲输出,转向角则来自转向编码器的脉冲输出。
2003年,Nicholas Apostoloff和Alexander Zelinsky提出了一种基于视觉的多线索融合车道追踪系统。该系统使用了两套视觉设备,一套为安装在仪表盘上的被动相机,另一套为近场/远场双相机组成的主动视觉系统。车道检测以主动视觉系统中的近场相机为主。系统采用粒子滤波器算法,融合了车道标志、道路边缘、道路颜色、非道路颜色、道路宽度、弹性道路等线索。
近年来,用于车道检测的传感器趋于多样化。2015年,吴毅华等提出了一种基于激光雷达的车道检测方法。与之前流行的基于激光雷达扫描点密度的检测方法不同,该方法基于激光雷达的回波脉冲宽度,抗干扰能力强,检测精度高。
3 基于学习的车道检测
近年来,在基于传统图像处理的车道检测之外,还出现了基于机器学习和深度学习的车道检测算法。这类算法一般将车道检测视为语义分割或实例分割问题。
2018年,Davy Neven等[25]提出了LaneNet,其结构如图3所示。LaneNet采用编码器-解码器网络;先利用公共的编码器提取特征,再利用不同的解码器进行二值分割(车道线检测)和像素编码(车道分割),对结果进行逐像素相乘和聚类。为保证车道线的光滑性,还训练了一个小型卷积神经网络H-Net,对结果进行鸟瞰变换,并根据变换的结果拟合车道线。LaneNet的优点是可同时检测多条车道线,且无需预设车道数量。
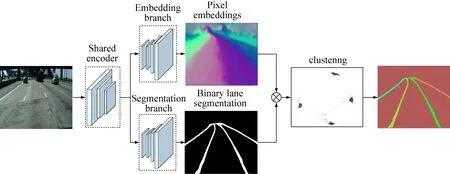
图3 LaneNet网络结构
同年,徐奕等将传统上独立的车道分割和车道线检测任务联合起来,将两个流程的输出分别编码后作为另一个流程的输入,利用几何约束关系提高检测的准确性。潘新钢等则提出了空间卷积神经网络(SCNN)。SCNN将行与列也看成层,并进行卷积和非线性激活,从而在行与行、列与列之间传递信息,特别适用于检测车道线等细长的连续形状。
基于学习的算法需要利用大量数据进行训练。常用的车道线数据集有KITTI,CULane,CityScapes,BDD100K等。大部分数据集都采用逐像素分割的方式标注车道线,但也有一些数据集(如BDD100K)采用参数化形式的车道线标签。
4 车道检测在智能驾驶中的应用
在早期的研究中,车道检测往往并不是一个独立的课题,而是与车道保持或追踪结合起来。更确切地说,车道检测是车道保持或追踪研究中的重要环节。这一时期的研究成果可以控制实车,但距离商用还有一定的差距。由于一般只涉及车道的检测(或包含障碍物的检测),而缺乏全局性的路径规划,受控车辆仍需较多的人为干预。此外,由于假设较多,受控车辆对道路要求较高,使用情境十分有限。
值得注意的是,并不是所有车道保持或追踪系统都需要前置的车道检测环节,ALVINN就是典型的一例。ALVINN是一种基于神经网络的自动驾驶系统。神经网络以采集的道路图像作为输入,以驾驶员的实际转向操作作为监督数据,经过训练,可以预测转向角,并以此为依据控制车辆转向。
21世纪初,基于车道检测的ADAS开始陆续投入市场,主要包含车道偏离预警系统(LDWS)和车道保持辅助系统(LKAS)。虽然LKAS比LDWS要复杂一些,但两者几乎是同时投入商用的。这两种系统都是通过检测车道,确定车辆相对车道的位置和运动趋势,从而在必要时做出车道偏离预警或车道保持控制。
LDWS和LKAS在实际使用中应避免与驾驶员的主动转向操作发生冲突。现有系统的解决方案一般为在转向灯开启时临时屏蔽系统。此方案在一般情况下是没有问题的,但在部分特殊情况下可能带来不便,甚至成为安全隐患。部分系统已尝试通过转向输入判断驾驶员的真实意图,从而合理地发挥作用。
车道检测也可用于更高级别的自动驾驶中。F. Heimes和H.H. Nagel于2002年提出了一种基于机器视觉和定位系统的主动驾驶辅助系统。该系统可控制车辆按照预定路线行驶。系统首先结合DGPS和高精地图进行路径规划和导航,然后根据基于视觉的车道检测结果决定车辆的具体行驶轨迹并控制车辆。
在自动驾驶车辆中,利用视觉传感器(或基于视觉传感器的多传感器融合)进行车道检测是较为常见的做法,如Tesla旗下的各款车型。但也有一些较为激进的做法,如在百度Apollo的高成本方案中,并没有进行车道线检测,而是通过高精定位系统和高精地图确定车辆相对车道线的位置。
2017年,Audi推出了全球首款量产L3级自动驾驶车辆——Audi A8。这款车型采用了多种车道检测方法以保证可靠性:首先,是基于图像识别的车道线检测;第二,是基于毫米波雷达的前车位置检测,从而估算车道位置;第三,是利用激光雷达探测车辆到道路边缘的距离,推算车道位置。
5 结束语
车道检测在智能驾驶中占有重要地位。这一领域的研究是从基于机器视觉的车道检测开始的。视觉传感器可以使用单目灰度相机,也可以使用多目相机或彩色相机。更复杂的相机可以提供更多的信息,从而减少算法的假设,提高算法的精确度和适用性。但另一方面,更复杂的相机也意味着更高的硬件成本和计算力要求。
视觉传感器是最适合车道检测的传感器之一,但也存在一些弱点。采用多传感器融合可以克服这些弱点。随着越来越多的传感器应用于自动驾驶和高级驾驶辅助系统,多传感器融合也是合理的选择。
随着硬件计算能力和效能比的提高,一些复杂的机器学习和深度学习算法开始应用于车道检测,提高了检测的精度。
从起步时期开始,车道检测的研究就着眼于车道保持或追踪。随着算法的复杂化和高质量数据集的建立,开始出现独立的车道检测研究。但车道检测始终是面向实际应用的课题。随着智能驾驶的发展,车道检测有着越来越广泛的应用。
在关于车道检测的研究中,以下方向值得关注:
(1) 从车道中获得更多信息。如今的车道检测研究多着眼于车道线位置的检测。但从车道线的颜色、数量、虚实等中,可以获得更多的有效交通信息。这一方向已有一定的积累,但还存在较大的进步空间。
(2) 视觉传感器感知的综合。这一领域较为常见的是将车道检测与障碍物检测综合起来。如果可以将更多的视觉信息(如交通标志等)综合考虑,无疑可以更加有效的利用采集的图像。
(3) 特征级的感知融合。当今车道检测中的感知融合多为决策级融合,融合方法往往为多选一,融合过程中信息损失较多。采用特征级融合可以更有效地利用传感器采集的信息,避免高精度信息覆盖低精度信息。
(4) 基于视觉的全场景分割。由对象的实例分割和背景的语义分割组合而成的全场景分割,可以将障碍物检测、车道检测、交通信息检测、可行驶区域判别等融为一体,实现端到端的复杂交通场景理解,是基于学习的检测算法的发展方向。
