区块链实用拜占庭容错共识算法的改进
2019-09-04甘俊李强陈子豪张超
甘俊 李强 陈子豪 张超

摘 要:针对应用于联盟链的实用拜占庭容错(PBFT)共识算法网络结构静态、主节点选取随意和通信开销较大的问题,提出了一种改进的实用拜占庭容错(EPBFT)共识算法。首先,给共识节点设置一系列活动状态使得节点通过状态转换在系统中拥有完整生命周期,由此节点可以动态地加入和退出,系统拥有动态的网络结构。其次,对PBFT的主节点选取方式加以改进,增加以最长链为选举原则的主节点选举过程。在主节点选举完成之后,通过数据同步和主节点验证过程进一步保证主节点的可信性。最后,优化PBFT算法的共识流程以提高共识效率,使得EPBFT算法的通信开销在视图变更较少发生的情况下降低为PBFT算法的1/2。实验结果表明,EPBFT算法具有较好的有效性和实用性。
关键词:实用拜占庭容错;联盟链;主节点;选举
Abstract: Since Practical Byzantine Fault Tolerance (PBFT) consensus algorithm applied to the alliance chain has the problems of static network structure, random selection of master node and large communication overhead, an Evolution of Practical Byzantine Fault Tolerance (EPBFT) consensus algorithm was proposed. Firstly, a series of activity states were set for consensus nodes, making the nodes have complete life cycle in the system through state transition, so that the nodes were able to dynamically join and exit while the system has a dynamic network structure. Secondly, the selection method of master node of PBFT was improved with adding the election process of master node with the longest chain as the election principle. After the election of master node, the reliability of master node was further ensured through data synchronization and master node verification process. Finally, the consensus process of PBFT algorithm was optimized to improve the consensus efficiency, thus the communication overhead of EPBFT algorithm was reduced to 1/2 of that of PBFT algorithm with little view changes. The experimental results show that EPBFT algorithm has good effectiveness and practicability.
Key words: Practical Byzantine Fault Tolerance (PBFT); alliance chain; master node; election
0 引言
区块链是一种新型的去中心化协议,它通过将数字加密[1]、共识算法、分布式存储、时间戳[2]等技术结合构建去中心化的分布式系统,其中共识算法的作用是为了解决拜占庭将军[3]問题。拜占庭将军问题抽象于现实世界,在点对点(Peer to Peer, P2P)网络[4]中,可能出现硬件故障、网络拥堵甚至恶意攻击等不可预知的问题。另外系统在任意时刻可能存在多个提案,因为提案的成本很低。共识算法除了要处理这些失效之外,还要完成提案的最终一致性,在区块链中有着非常重要的作用。
关于共识算法的研究很早便已经开始,最早由Pease等[5]和Lamport等[6]在20世纪80年代通过拜占庭将军问题进行描述和分析,提出了著名的拜占庭容错(Byzantine Fault Tolerance, BFT)算法。不同于比特币系统“挖矿”的工作量证明(Proof of Work, PoW)[7]系列共识算法(达成共识的概率上的最终一致),BFT类协议依靠节点之间相互传递消息对提案达成确定性共识结果;然而也是由于这些特性造成节点间需要两两之间递归传递指数级复杂度的消息,不太具有可实际操作性,而且节点的加入和退出过程需要进行特别处理。这些研究起初常被人们忽视。直到区块链技术和比特币的出现,BFT算法重新引起关注,因为这一算法虽然存在很多缺点,但它为解决拜占庭问题提供了一种不同于PoW那样的需要耗费巨大算力新思路,为以后的实用拜占庭容错(Practical Byzantine Fault Tolerance, PBFT)算法的出现作出了准备。
在1999年,Castro等[8]提出了实用拜占庭容错(Practical Byzantine Fault Tolerance, PBFT)共识算法,改进于BFT算法,继承了它的优点,同时将算法复杂度由指数级降为多项式级。由此实用拜占庭容错算法在实际系统应用中变得可行。PBFT算法是基于状态机副本复制的算法,每个状态机副本保存服务状态,实现客户合法请求,除了交易之外,还可以完成其他类型的操作,应用范围广泛。在系统中存在(n-1)/3的数量的错误节点的情况下,仍可保证系统安全性和活性,正确地达成分布式共识。
然而现有的PBFT算法还存在一些不足。首先,其网络结构是静态类型,如果动态增加节点,必须重启应用,造成不必要的损失,影响系统可用性,尤其在某些行业,经常性的重启系统是不能忍受的。PBFT算法中主节点的选举方式是按编号依次轮流作主节点,这种主节点的选举方式较为随意,在选举成功主节点后也没有对主节点的真伪性进行验证,使得选举出来的主节点很有可能是恶意节点,具有一定的安全隐患,尽管在后续的共识过程中主节点的恶意性有可能被从属节点识破并通过视图变更将其推翻,但是仍然会造成一定的损失,频繁的视图变更也会增加系统开销,降低系统效率。三阶段广播过程,需要比较大的网络传输和通信开销,要进一步优化。在主节点选举成功后也没有完善的数据同步过程,在每一个视图变更后,集群中的节点可能出现保存的副本数据有多有少的情况,因为由于网络等原因会导致各个节点的进度不一致,从而导致状态不一致[9],所谓状态一致,即是指交易编号、区块高度、视图号等信息都保持一致,所以在新的主节点选举出来以后,需要进行集群中节点的数据同步。
本文针对现有的PBFT算法网络结构类型静态、主节点选举方式随意、不能保证主节点可信性、网络开销比较大、缺少完善的数据同步过程等问题,提出一种改进实用拜占庭容错(Evolution of Practical Byzantine Fault Tolerance, EPBFT)共识算法模型。参考原子消息广播算法ZAB(ZooKeeper Atomic Broadcast)[10],针对PBFT算法特点,将集群中的节点分为领导者与跟随者两种角色,依情况使节点处于不同的状态,同时依据节点状态的不同决定节点是否能够进行共识过程,从而使得集群中可以动态加入和退出节点;设计一种新的选举方式,在原有的PBFT算法基础上改变主节点的选举方式,不再按照编号选择主节点,而是选举出拥有处理过最大视图号以及最大编号的请求的节点作为主节点,在数据同步阶段,可以方便进行数据同步;在主节点选举完成之后增加一个数据同步及验证阶段,在进行数据同步的同时对所同步的数据进行验证,若验证的数据通过,则可以确定新的主节点为可信节点,正式承认选举出的新的主节点,开始新一轮的共识过程。确认阶段是对准备阶段的再确认,防止视图变更发生于准备阶段后产生的不一致。在联盟链的环境中,节点有监督,网络较稳定,视图变更情况并不会频繁发生,且在视图变更后增加了数据同步及验证过程,保证了状态一致性,所以可以省略三阶段中的最后的确认阶段。本文贡献如下:
1)改进PBFT算法中主节点选举方式,改原来的依据节点编号选举为拥有处理过最大视图号以及最大编号的请求的节点选举,也就是最长链选举。使得主节点的选举方式更加合理,选举出的主节点更加可信。
2)增加数据同步及验证阶段,在主节点选举完成之后增加数据同步及验证阶段,进一步验证新主节点的可信性,在完成数据同步的同时完成对新选举出的主节点的真伪性进行验证,若新的主节点可信,则开始新一轮的共识;反之,重新进行选举过程。
3)在前两点基础上省去原来的PBFT算法中的确认阶段,由此可以减少网络和时间开销,使算法更加高效。
4)改进原PBFT静态结构为动态结构,设计一套节点加入和退出集群以及工作的完整周期,通過给节点赋予领导者与跟随者两种角色,以及不同状态,使得集群中节点可以动态地加入和退出,无需重启整个集群,提升整个集群的稳定性和可用性。
5)实现本文所写的改进的算法模型,并通过实验验证,新的改进的PBFT算法模型在保证数据可信性和安全性的前提下,有效地降低了共识需要花费的时延,提高了交易吞吐量。
1 相关工作
拜占庭容错算法的研究很早就已开始,但近年随着区块链技术的落地才在计算机领域流行起来。特别是由于PBFT的提出使得拜占庭容错算法拥有较高的效率和安全性,得以应用于实际系统中实现,针对PBFT算法的改进研究明显增多。对已有的BFT类共识进行研究,按照改进思路的不同分类,主要可以归纳为3大类方向[11-12]:1)针对非拜占庭错误场景优化;2)针对拜占庭错误场景优化;3)为公链应用优化。
首先是针对假设系统无拜占庭节点的场景进行优化,即假设系统中基本不存在恶意节点,允许节点存在宕机行为,在这种情况下对BFT算法进行简化或优化。最出名便是以Paxos[13]、Raft[14]为代表的传统分布式一致性算法。Raft算法由Paxos算法简化而来,经过改进简化Raft算法易于实现。HQ(Hybrid Quorum)协议[15]参考并优化了PBFT协议,针对无竞争的情况简化通信。如果有竞争,性能也退化为和PBFT类似。应用于ZooKeeper中的ZAB算法改进自Paxos,共识过程简单有效,已被广泛用于分布式协调一致性过程,拥有较高的吞吐量和较低的时延;但由于此类算法面向的是分布式系统数据库和日志等存储领域,不能解决拜占庭容错问题,所以不适合于区块链环境。
然后是针对拜占庭错误场景进行优化,这类优化基本在PBFT的基础上进行改进,由于要处理拜占庭错误节点,必然要增加相互之间确认的通信,出现明显的性能下降。Tangaroa算法[16]具有Raft简单易理解的优点,同时兼具拜占庭容错性。由Tangaroa演变出另一种称为可扩展拜占庭容错协议——ScalableBFT[17],能够实现比Tangaroa更好的性能。对PBFT改进的系列算法多用于联盟链中。
在为公链应用优化方面,Tendermint[18]出现于加密货币之后,内置了简单的数字货币,以此为基础实现了股权证明(Proof of Stake, PoS)与PBFT的结合,节点需要缴纳保证金,如果作恶保证金就会被没收。相似地在2016年,小蚁提出的代理拜占庭容错(delegated Byzantine Fault Tolerant, dBFT)算法,该算法同样在PBFT的基础上借鉴了PoS算法,共识节点按照节点的权益来选出,该算法一定程度改进了PoS缺乏最终一致性的问题,使其能够更适合金融场景;但这一方式也受到共识节点数量有限、中心化程度高的质疑。2016年,Micali等[19]提出了一种快速拜占庭容错共识算法——AlgoRand,在该算法中,共识的验证者和领导者通过密码抽签技术选出,同时还构想出一个新协议完成区块的共识。
此外,以比特币为应用的PoW算法不能适应一般应用的高吞吐量和及时处理的需要。为应对PoW要求的高算力带来的巨大的资源浪费问题,提出权益证明为代表的共识算法PoS[20],集群由可信度较高的节点组成,共识节点的选取标准依情况而定,但都是为了最大限度保证节点的可信度,但可能导致权益集中的问题,对交易吞吐量、延迟、区块大小等方面也较少关注。
可以看出,出现了较多PoW系列算法与PBFT结合的方式提高共识节点可信度,但是通过授权投票产生“超级节点”的方式会加大系统中心化程度,这显然和区块链初衷是相违背的。另外以Paxos、Raft为代表的传统分布式一致性算法无法应对拜占庭容错问题,但由于其共识效率高的特点,越来越多地被拿来与PBFT相结合,这给共识算法改进带来新的启发。本文提出的改进算法同样是基于联盟链的前提下,具体的共识节点的选取可以依照不同的应用场景而定。共识节点的准入设置一定程度保证了可信度,同时增加的对主节点的选举和验证过程在不提高系统中心化程度的基础上保证主节点的可信度,同时也保证了共识速度不受影响。赋予节点生命周期使节点能动态加入和退出,改进三阶段广播流程,缩短交易确认时延,提高了区块吞吐量。
2 PBFT算法分析
2.1 BFT算法及流程
正PBFT是一种状态机副本复制算法,也就是将服务作为状态机来建模,在分布式系统中,状态机在不同的节点复制副本,所以,最初PBFT算法是用在分布式系统领域,并不是用在区块链领域的。在PBFT算法中,一个主节点领导的共识过程处于一个视图v之中,视图是连续编号的整数,在各个视图之中,都存在三种角色,分别是客户端、主节点、从节点。主节点和从节点都是备份节点,因为它们都进行数据备份,它们各自的功能如下。
1)客户端。客户端c是请求的发送方,发送的请求格式为〈REQUEST,o,t,c〉,其中o是请求执行的操作,t是时间戳,用来保证请求的唯一性,只会被执行一次,同时还使得客户端发送的请求是全排序的,后发送的请求的时间戳一定比之前发送的请求的时间戳更高。
2)主节点。主节点主要负责接收客户端发来的请求,同时对这些请求进行排序,分配编号,再向集群中的从节点广播请求。
3)从节点。从节点主要负责接送收此处是否应为接收主节点和其他从节点发来的消息,进行相应的验证,只会之后是否应为之后再执行对应的操作,最后将共识结果发回客户端。
所有节点组成的集合用大写字母R表示,那么集合中的每一个副本可以用0到|R|-1的整数表示,集合的理想节点数为:
其中: f是失效节点的最大个数;|R|是节点数,虽然可以部署多于此数的节点,但是这样只会降低系统性能,并不能对共识过程有帮助。
主节点的选取由如下公式确定:
其中:p是副本编号,v是视图号,当主节点失效或者被从节点推翻时,启动视图变更,依照此公式选取新的主节点。
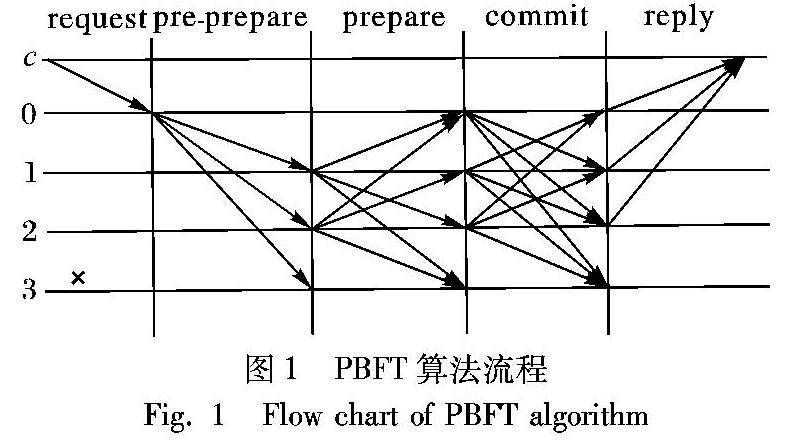
接下来介绍PBFT算法的流程,总共包括五个阶段,分別是请求、预准备、准备、确认、回复。其中主要的阶段是中间三个,即预准备、准备、确认。下面介绍这五个阶段:
1)请求阶段。当客户端c向主节点p发送请求消息m。
2)预准备阶段。主节点P接收到客户端c发来的请求m时,主节点为消息m分配一个编号n,然后向所有的从节点广播预准备消息,预准备消息的格式为〈〈PRE-PREPARE,v,n,d〉,m〉,其中,v是视图编号,d是请求消息m的摘要。
3)准备阶段。节点在接收到预准备消息时会对其进行检验,如果同意预准备消息,则进入准备阶段;如果不同意,则什么也不做。节点在进入准备阶段后向除自己以外的其他节点广播准备消息,同时将预准备和准备消息写入消息日志。准备消息格式为〈PREPARE,v,n,d,i〉,其中i是节点自身编号。准备阶段完成的标志为收到2f+1个从不同副本节点收到的与预准备消息一致的准备消息。对副本节点验证预准备和准备消息主要检查有:视图编号v、消息序号n和摘要d,以及水线,水线作用是防止一个失效节点使用一个很大的序号消耗序号空间。
4)确认阶段。当节点完成准备阶段后,进入确认阶段,此时节点向除自己以外的所有节点发送确认消息,确认消息格式为〈COMMIT,v,n,D(m),i〉,每个节点接收确认消息进行的检查有:签名正确,消息的视图号与当前视图号相同,消息的序号满足水线的条件。定义确认阶段完成的条件为节点i已经接收了包括自身在内2f+1个确认消息且与预准备消息一致。
5)回复阶段。当节点完成确认阶段后,向客户端发送回复消息〈REPLY,v,t,c,i,r〉,其中r是请求最后的执行结果。客户端只有收到f+1个不同节点发来的同样响应时才认为请求正确执行成功。
PBFT完整流程如图1所示。
2.2 PBFT算法不足点分析
从对PBFT流程的详细分析可以看出,现有的PBFT算法具有以下几点不足。
1)客户端只能向主节点发送请求,若请求消息过多,可能造成主节点过载,可用性降低,不适合区块链的P2P网络环境。
2)主节点选取方式较为随意,不保证主节点正确性,若出现连续选举出的主节点为恶意节点,则将极大浪费系统资源,降低系统可靠性和安全性;没有较为完善的备份数据的同步过程,随着时间的推移,不同节点之间的数据差异越来越大。
3)没有灵活的共识节点加入和退出机制,使得节点在加入或退出集群时很不灵活,特别是在集群中节点较多或者节点变更比较频繁的情况下,系统将更加难以应对,大幅度降低了系统可用性。
4)三阶段广播,包括一次单节点广播,加两次全节点全网广播,特别是后两次全节点广播,非常消耗网络带宽,在区块链这样的P2P环境下,若请求过频,容易造成网络拥堵。假设全网节点数为N,则完成一次三阶段共识过程,总共需要进行消息传递的次数Z为:
显然,当集群中节点较多时,消息传递次数将急剧增加。
3 EPBFT算法设计与实现
3.1 整体思想
经典的PBFT算法基于状态机复制原理,最初用于分布式文件系统协调一致,除了关注解决拜占庭容错问题之外,还着重解决所有副本节点在全局都执行相同顺序的请求操作序列,所以在将PBFT算法应用于区块链系统中时有诸多地方需要改进以适应区块链系统。在联盟链系统中节点的进入经历了相应的身份认证机制,如基于第三方的身份认证、纯分布式的身份认证等结合密码学技术可以有效防止女巫攻击问题。根据第2章对PBFT算法的分析,结合区块链系统实际应用情况,提出以下几点主要改进方案:
1)改变客户端单点提交请求到主节点方案,而是向全网广播附上签名的交易数据。这样的方式更适合P2P环境。
2)增加主节点选举过程,在主节点宕机或者被从节点“推翻之后”,进行主节点选举,选举标准按照最长链原则,选取拥有处理过最大视图号与最大编号请求的节点为新的主节点。
3)增加数据同步及验证过程,在主节点选举完成后进行数据同步,同步时从节点对同步数据进行验证,若验证通过,才正式承认新的主节点,开始下一轮共识过程。
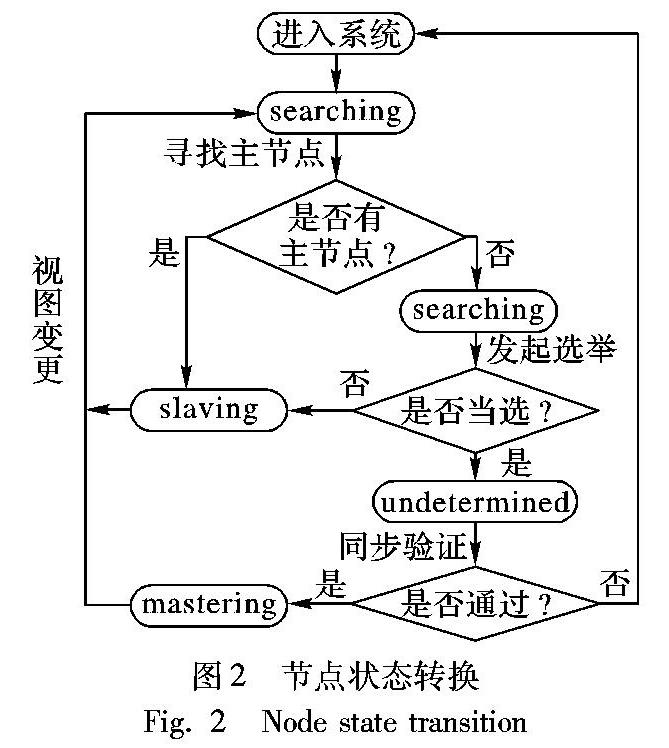
4)通过给节点设置一系列状态,在不同的状态节点拥有不同的行为,共识节点通过在不同状态之间的转换从而在集群中拥有完整生命周期,从节点与主节点通过心跳保持联系,从而使集群中的节点可以动态地加入和退出,使得在节点变动时不必重启系统,增加系统可用性。节点的状态转换过程如图2所示。
5)去掉三阶段中的确认阶段,PBFT的确认阶段作用是确保其他节点都已经收到足够多的信息来达成共识。这一阶段发送的COMMIT消息没有同意或者不同意的信息,只是起一个统计票数的作用,在PBFT三阶段共识过程中那些处于预准备和准备阶段的消息在视图变更发生后将被丢弃。一个消息完成了确认阶段说明已经有足够多的节点都完成了准备阶段,因此确认阶段保证了PBFT在更换主节点后减少数据同步操作直接可以进入下一个视图状态执行新的共识过程(这并不能完全消除不一致,因为COMMIT消息同样可能延迟甚至丢失)。PBFT算法是解决传统分布式系统容错,确认阶段其实是对准备阶段的一种“确认”。当消息完成准备阶段之后即说明该消息已经被合法数量的节点验证通过,即为系统所共识,但是由于存在网络延迟等不确定因素,可能存在某些节点不能同时完成准备阶段,如果在准备阶段之后发生视图变更,将会导致不一致性。在联盟链区块链环境,需要保证的是节点具有相同的初始状态,也就是具有相同区块高度和视图号,这两者可以通过区块同步和视图变更保证。另外在联盟式区块链在有监督且较稳定的环境中,视图变更不会也不应是常态,为确认阶段所花费的数据传输开销应该设法避免。
在省略确认阶段的情况下,消息在完成准备阶段后提交,需要保证在准备阶段之后发生视图变更后系统的一致性。本文设计利用视图变更过程来保证一致性,在视图变更时加入了选举过程与同步验证过程。选举过程的作用是选出系统共识节点中区块链结构最长的节点作为待定主节点,待定主节点选举出来后进行同步验证过程,以此消除由于网络原因造成的状态不一致性。另外待定主节点在同步过程中可能同步非法区块,而利用区块链的特性可以容易地检验区块合法性,所以设计出同步验证过程,监督待定主节点在同步过程中行为的合法性。如果待定主节点在同步过程中出现恶意行为,那么将再次选举新的待定主节点。基于以上分析,EPBFT所设计的改进的共识流程可以在不影响系统容错性的情况下降低共识过程的数据传输量与通信开销,提升了共识效率。具体情况下的通信开销在实验部分论述。一般情况下假设全网节点数为N,此时完成一次共识过程需要进行的消息传递次数Z为:
当节点数较多时,可以节省对网络带宽的消耗,缩短共识过程。
3.2 算法设计
3.2.1 算法符号表示
1)集群中节点分为两种,一种是主节点(master),一种是从节点(slave),所有节点集合用集合R表示,两种节点都称为备份节点,用编号{0,1,…,i,…,|R|-1i的前后两边都有点号,书写正确吗?请明确。回复:点号表示省略了编号从1到i和i到R-1的其他节点编号}表示。
2)令集合R中最大能容忍的恶意节点数为f,则集合R大小必须满足公式:
R≥3f+1(5)
一般情况下,集合数取3f+1,因为更多的共识节点不会对共识过程有帮助,反而会降低整体性能。
3)集合中节点具有四种状态,分别命名为:寻找(searching)、待领导(undetermined)、领导(mastering)、服从(slaving)。
4)视图编号用整数v表示,请求编号用整数n表示,视图变更或遇到新请求时,v和n加1。在一个视图中,n必须在水线之间:
H≥n≥h(6)
5)两阶段分别命名为快提案阶段(fast-proposal)和快确认阶段(fast-confirm)。
3.2.2 算法流程
初始化系统时,先经过主节点选举过程选举出主节点,接下来进行数据备份与验证阶段,因為在去中心化的区块链共识系统中,如果要达到共识的目的,各共识节点需要开始于相同的状态。所谓达到相同的状态就是各个备份节点存储的数据一致,视图号和请求编号即区块高度、上一块区块哈希值等信息一致。完成数据备份与验证阶段后,系统开始预准备和准备两阶段共识过程。在消息传递过程中,使用密码学技术保证消息的完整性和真实性,定义Si为消息签名,Di为消息摘要。
具体的算法流程如下:
若系统有主节点,直接从第三步开始进行。直接进入快提案阶段。此处指代不明确,指哪一步?请调整语句当系统没有主节点时,进行主节点选举过程,所有节点处于searching状态,先经过主节点选举过程选举出主节点,此时当选的节点变为undetermined状态。
接着进行数据备份与验证阶段,各个从节点需要从拥有最长链的待定主节点处备份数据,从节点在得到备份数据后需要对数据进行验证,验证通过后保存。只有超过2f+1的从节点验证通过,才算是正式承认主节点,主节点从undetermined状态转变为mastering状态,其余节点从searching状态转变为slaving状态,成为从节点,视图号v加1。若主节点备份数据验证失败,说明待定主节点不可信,将该节点排除出系统,重新选举主节点。
交易发起者c向集群中节点发送一个已签名交易,若接收节点向全网广播交易,各共识节点(包括主节点)收到交易后验证交易的合法性,若合法,则缓存起来。主节点待收到足够的交易或者到一段时间间隔以后,生成一个区块。
快提案阶段 主节点为产生的区块生成快提案消息,分配一个编号n,然后向所有的从节点广播快提案消息,快提案消息的格式为〈〈FAST-PROPOSAL,v,n,Si,Di〉,block〉,其中:v是视图编号,block是需要共识的区块。从节点i∈{0,1,…,|R|-1}在接收到快提案消息是会对其进行检验,如果同意快提案消息,则进入快确认阶段,如果不同意,则对主节点表示怀疑,广播视图变更消息。副本节点验证快提案消息主要检查有:视图编号v、消息序号n、签名和摘要、水线、区块交易验证。
快确认阶段 节点在进入快确认阶段后向除自己以外的其他节点广播快确认消息,同时将快提案和快确认消息写入消息日志。快确认消息格式为〈FAST-CONFIRM,v,n,Si,Di,i〉,其中i是节点自身编号。快确认阶段完成的标志为收到2f+1个从其他不同副本节点收到的与快提案消息一致的快确认消息,若到时间超时为止未收到足够快确认消息,将区块丢弃。副本节点验证快确认消息主要检查有:视图编号v、消息序号n、签名和摘要以及水线。
当共识节点完成快确认阶段后,提交请求,保存区块,表明该区块加入区块链尾部。
算法主要流程如图3所示。
3.2.3 主节点选举
主节点选举依据最长链原则,选出集群服务器中最后一个共识完成的拥有最大视图号的编号最大的服务器作为主节点。视图号与编号合起来用一个long型数据存储,分别占据高32位和低32位,用vnid(view-number id)表示选举过程主要分为以下几种情况(图34~5此处指代图4、5吧?请明确括号中三个数依次为:节点编号,目标节点编号,目标vnid)。
1)集群初始化主节点选举。
各服务器初始化后,各共识节点都处于searching状态,都投票给自己,并将自己的一票存入自己的票箱,服务器收到所有外部投票后,进行选票PK,相应更新自己的选票并广播出去,并将合适的选票存入自己的票箱。选票PK有三种情况,分别是:
a)若收到的选票中最大vnid小于自己当前主张的vnid,忽略。
b)若收到的选票中最大vnid等于自己当前主张的vnid,若此时节点编号也相同,将选票存入自己的票箱。否则比较节点编号,若当前主张节点编号较高,忽略消息;否则清空票箱,相应更新自己的选票存入票箱并广播出去。
c)若收到的选票中最大vnid大于自己当前主张的vnid,清空票箱,更新当前主张的vnid,相应更新自己的选票存入票箱并广播出去。
当票箱中有来自不同节点的2f+1个目标一致的选票时,选举完成,清空票箱,向其目标主节点发送确认消息。被其他节点认同且收到至少2f+1个来自不同节点的确认消息的节点成为待定主节点的节点进入undetermined状态。选举过程如图4~5所示。
2)slave进入集群投票给自己。
slave进入集群,或者发生网络分区后找不到master,会进入searching状态并发起新的一轮投票。集群中其他节点将告知其当前主节点信息,收到超过来自不同节点的2f+1个节点一致信息后,该节点与当前主节点建立心跳联系,进入slaving状态,成为从节点。如图65所示。
master宕机后,或者在被slave发起的视图变更推翻后,将当前master排除出集群,进入searching状态并发起新的一轮投票,并且都将票投给自己,投票过程与第一种情况相同,此处不再赘述。
为节点定义一个完整的生命周期为选举阶段提供基础的同时,实现了集群中节点的动态变更,极大地提高了系统灵活性和可用性。
3.2.4 数据备份与验证
当选出待定主节点之后进行的数据备份与验证阶段,是为了使各节点状态达到一致,这在前面已有解释,同时还可以进一步验证待定主节点是否为恶意节点。过程如下。
数据同步阶段 选举过程完成后,从节点向待定主节点发送同步请求消息,消息格式为〈SYN-REQUEST,v,vnid,Si,此处有两个逗号,且均为下标,是否应该为一个逗号,且逗号不应该为下标,请明确。后面仍有此类书写,请一并核对。i〉,如前所述,v为视图号,vnid为各自提交的最大事务号,待定主节点接收到该消息后首先检查视图号是否合法,若是则查看对比自己的末尾区块编号与消息中的vnid是否一致,若一致直接发送同步成功消息〈SYN-SUCCESS,v,Si,i〉给该从节点;否则根据其他节点所拥有的数据区块的不同,向集群中其他节点分别发送同步消息和相应的备份数据区块,消息格式为〈〈SYN-DATA,v,Si,i〉,blocks〉,blocks為相应的备份数据区块。
数据验证阶段 其他的节点收到待定主节点的备份数据区块后,验证其合法性。如果合法,则保存起来,广播验证通过消息,消息格式为〈SYN-ACK,v,Si,i,d〉,d为收到的备份数据区块中最后一个区块的摘要;否则将其丢弃。同时保存收到的来自其他节点的验证结果消息。因为这一过程验证目标明确,所以只需要一次消息广播过程即可确定待定主节点的合法性。当从节点收到来自其他不同节点的2f+1个通过消息且消息中d一致后,验证成功,这样可以保证待定主节点发送给每个从节点的备份数据区块都是一致的。此时从节点向主节点发送〈SYN-ACHIEVE,v,Si,i〉消息。节点进入slaving状态,成为从节点;反之,认为待定主节点是恶意节点,排除该节点,重新进行选举。
验证确认阶段 当待定主节点收到2f+1的同步完成消息后,表示有足够的从节点正式同意自己,且系统中有足够的共识节点。这时待定主节点进入mastering状态,正式成为主节点。
该过程如图76所示。
3.2.5 切换视图
在原算法的基础上更进一步,不止在主节点失效时触发视图变更,当从节点怀疑主节点时同样广播视图变更消息,从而可能触发视图变更,推翻主节点。具体流程如下:
1)当从节点发现主节点失效或者怀疑主节点是恶意节点时,向集群中其他节点广播视图变更消息,前文已阐明怀疑过程,此处不再赘述。视图变更消息格式为(VIEWCHANGE,vnew,vold,Si,i),vnew为新的视图号,vold为旧的视图号,i为节点编号,vnew=vold+1。
2)其他从节点在收到视图变更消息后,验证消息中的vold是否与当前一致,且vnew=vold+1,同时检查主节点是否失效:若主节点未失效且不认为主节点发来的提案有问题,则忽略该消息;若验证通过后,广播视图变更确认消息,消息格式为(VIEWCHANGE-CONFIRM,vnew,vold,Si,i)。
3)当从节点收到2f+1个来自不同节点的视图变更确认消息后,切换为searching状态,進入主节点选举阶段,开始重新选举主节点。
4 实验分析
本章从通信开销、时延、吞吐量和安全性方面对EPBFT进行测试,同时与原来的PBFT算法进行比较对照,以此验证改进算法的有效性和可用性。实验网络环境采用实验室局域网通信,使用6台配置相同的Windows系统台式机作为共识节点。
4.1 系统设计
为了测试改进的算法的有效性和可用性,实现了以改进算法为核心的区块链系统。系统底层为一般区块链技术架构,采用链式数据结构,使用P2P网络架构,加密方法采用椭圆曲线非对称加密,整个系统是去中心化的。整个系统分为数据上传、选举与同步、共识、数据存储四三此处书写有误,“选举与同步”模块是“共识”模块的子模块,在共识模块中已有说明。原文“整个系统分为:数据上传,选举与同步,共识,数据存储四个模块。”修改为“整个系统分为:数据上传,共识,数据存储三个模块。”个模块。
数据上传模块 此模块负责产生模拟交易数据,并持续向共识模块传递交易数据,这些交易将被存入区块并被共识模块共识,以此测出时延和吞吐量等数据。
共识模块 此模块将数据上传模块传递来的交易后,产生区块进行共识,是整个系统的关键模块,共识流程采用本文提出的EPBFT算法。其中共识模块又分为主节点选举、数据同步及验证和区块共识三个子模块。主节点选举模块负责主节点的选举以及所有节点加入和退出以及状态的转换逻辑;数据同步及验证负责在选举出新的主节点后向其他节点同步数据以及对同步的数据进行验证;区块共识则是进行改进后的区块共识过程。
数据存储模块 此模块负责将完成共识的区块进行存储,数据同步验证过程将保证每个节点在视图变更后存储当前完整区块链数据。存储的数据可以被查询显示,不可被修改。
整个系统架构如图87所示。
4.2 性能测试
理论上在减去了原PBFT共识过程中的确认阶段的改进算法在共识速度上将获得提升。现通过基于改进算法构建的实验系统对通信开销、吞吐量、时延和安全性四方面进行测试,并与原PBFT算法进行比较,从而验证改进算法的有效性和可用性。在测试过程中保证实验机器中可能的故障节点和恶意节点都是相同的节点f个,在这里的实验中采用f=1。因为集群节点数至少为3f+1,所以选择3组对比实验,分别使用4个节点,5个节点与6个节点作为共识节点。
4.2.1 通信开销分析
设现在平台共识节点数为n(n>3),可以利用共识算法流程计算出一次完整的PBFT共识需要的通信次数,计算范围只包括预准备阶段、准备阶段和确认阶段三个主要阶段。同时设视图变更概率p,p=1/q(平均每q次共识发生1次视图变更)。
1)PBFT通信开销。
首先由前文对PBFT共识过程分析知三阶段总通信次数为2n(n-1)。
对于视图变更过程,视图变更阶段每个从节点广播视图变更消息,本阶段共识网络中的通信次数为(n-1)2。视图变更确认阶段新视图的主节点收到来自其他从节点的视图变更后发送视图变更确认消息给所有从节点,本阶段共识网络中发生的通信次数为(n-1),那么系统在p概率下发生视图变更时通信总次数为:
2)EPBFT通信开销。
由前文对EPBFT共识过程分析知二阶段总通信次数为n(n-1)。
在主节点选举过程中,投票第一轮各个从节点发送自己的投票给除了自己之外的从节点。本阶段共识网络中的通信次数为(n-1)2。投票第二轮各个从节点通过选票PK更改投票对象,更改后将投票发送至除了自己之外的从节点,该过程通信次数为(n-1)2。完成选举的从节点发送确认消息给待定主节点,该过程通信次数为(n-1)。
在数据同步验证阶段中,数据同步过程中待定主节点给每一个从节点发送其对应的同步消息,该过程次数为(n-1)。同步验证过程中所有从节点发送验证通过消息给除了待定主节点和自己之外的所有从节点,该过程通信次数为(n-1)(n-2)。验证确认过程中所有从节点在同步完成后发送同步完成消息给待定主节点,该过程通信次数为(n-1)。
所以选举过程与同步过程总通信次数为3n2-4n+1。根据假设,若系统在概率p下发生视图变更,则总共的通信次数为:
3)通信开销对比。
令两种算法通信开销比值为I,则在没有出现视图变更情况的共识过程中,两种算法通信次数比值I1为:
由式(9)可知I1恒等于2,所以如果系统没有发生视图变更,那么EPBFT算法是PBFT通信次数的一半,有效降低了共识过程中的网络通信次数。
而在视图变更发生的情况下,两种算法通信次数比值I2为:
经过系统实验验证,将发生视图变更概率P作为自变量,两种共识算法在节点数固定的情况下参与共识下的通信次数比I。当P=0.5时I趋近于1,此时两种算法的网络通信次数基本相等。当P<0.5,也就是每当大于两次共识过程后才可能发生一次视图变更时PBFT的网络通信次数大于EPBFT,当P越小,I越趋近于2,也就是说视图变更情况出现概率越小,EPBFT的通信次数越接近PBFT的一半,因为系统需要为选举和同步验证过程所花费通信开销的情况越少。在联盟链系统环境和节点比较稳定的情况下,系统发生视图变更的概率是很小的,通信开销接近为PBFT的一半。如果区块链平台每两次共识就会发生一次视图变更,这样的情况对系统来说是不可接受的,因此,EPBFT算法可以有效减少系统在共识过程中的通信开销。
4.2.2 吞吐量测试
吞吐量一般指单位时间内系统处理的事务数,吞吐量的高低显示了系统承受负载,处理事务或者请求交易的能力。在区块链领域中,一般用每秒交易数(Transaction Per Second, TPS)来表示,即:
其中:TransactionsΔt為出块时间内系统处理交易数,Δt为出块时间。吞吐量随着每个区块的容量增大相应地也会变大,但随着区块容量的增大,共识时间和网络负载也会增大,所以当大到一定程度时吞吐量会有所下降。为了便于对照,控制变量,将一个块中包含的交易数固定为10个。测试了在4、5、6个共识节点下的三组对照实验。多次测试取平均值,得出统计结果。
两种算法在相同条件下吞吐量对比如图98所示。
可以看出两种情况下随着节点数增加,吞吐量都略微减少,但是改进的EPBFT算法吞吐量更高,几乎比原PBFT算法高出一倍,并且随着交易量的加大,吞吐量提升得更加明显。
4.2.3 时延测试
共识时延(DelayTime)是衡量共识算法运行速度的重要指标,较低的共识时延使得交易可以快速得到确认,区块链安全性更高,同时也能变得更为实用。在本文中测试的共识时延为区块完成一次共识过程的时间,即:
其中:Tconfirm为区块完成确认时间,Ttransmit为快提案阶段开始时间。多次测试取平均值,得出统计结果。
两种算法在相同条件下共识时延对比如图109所示。
4.2.4 算法安全性
为验证EPBFT的安全性,从两个方面考虑:一方面是对集群中恶意节点数量的控制,二是测试在主节点为恶意节点或者失效时系统的反应。
首先在共识节点中设置一个恶意节点的情况下,可以完成共识,当在总节点数不变,恶意节点增加以后超出系统所能承受的最大恶意节点数量,无法完成共识。
然后再让主节点传播恶意请求(如将请求序号设置的很大),系统无法完成共识,发生视图变更将存在恶意行为的主节点“推翻”,重新选举新主节点。再验证新共识算法在主节点宕机行为下的安全性与容错性,设置主节点在一次共识过程中宕机。PBFT算法中从节点检测主节点宕机后执行视图变更过程的两个阶段,随后更新视图号,保证上一轮中完成快确认阶段的消息全部处理结束,其他未完成快确认阶段的请求全部丢弃,之后开始新的共识;EPBFT在检测到主节点失效后开始前文所述主节点选举过程。选出新主节点后,主节点与所有从节点进行同步与验证阶段,保证了在新视图开始时全局数据的一致性。同步结束后开始下一轮共识。
实验表明EPBFT共识算法在提高了共识速度并减少共识时延的基础上与原PBFT共识算法一样能够保证分布式系统一致性和安全性,提供f=(n-1)/3的容错性,证明了改进的算法是有效和可靠的。
5 结语
本文提出了一种基于PBFT改进的算法模型EPBFT,给集群中节点定义一个完整的生命周期,使得节点可以动态加入和退出;对原PBFT的主节点选举方式加以改进,选举出的主节点更为可信;在主节点选举完成之后,共识过程执行之前增加一个对主节点是否所拜占庭节点的主节点验证及数据过程,增加一个主节点验证及数据同步过程,判断主节点是否为拜占庭节点,此处语句不通顺,需调整。回复:增加一个对主节点是否所拜占庭节点的主节点验证及数据过程”调整为“增加一个主节点验证及数据同步过程,判断主节点是否为拜占庭节点,进一步保证主节点的可信性使全节点在共识开始时状态一致。依据区块链环境优化共识过程,加快共识过程。未来工作将继续优化算法细节,进一步降低网络通信量。可以在以后引入节点评分机制,综合选取最优节点。将算法应用于某一实际领域的区块链系统中,为区块链的应用及普及作出贡献。
参考文献 (References)
[1] BONNEAU J, MILLER A, CLARK J, et al. SoK: research perspectives and challenges for bitcoin and cryptocurrencies [C]// Proceedings of the 2015 IEEE Symposium on Security and Privacy. Washington, DC: IEEE Computer Society, 2015: 104-121.
[2] 蔡维德,郁莲,王荣,等.基于区块链的应用系统开发方法研究[J].软件学报,2017,28(6):1474-1487.(CAI W D, YU L, WANG R, et al. Blockchain application development techniques[J]. Journal of Software, 2017, 28(6): 1474-1487.)
[3] EYAL I, CENCER A E, SIRER E G, et al. Bitcoin-NG: a scalable blockchain protocol[C]// Proceedings of the 13th USENIX Symposium on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2016: 45-59.
[4] AMALARETHINAM D I G, BALAKRISHNAN C, CHARLES A. An improved methodology for fragment re-allocation in peer-to-peer distributed databases[C]// Proceedings of the 4th International Conference on Advances in Recent Technologies in Communication and Computing. Piscataway, NJ: IEEE, 2012: 78-81.
[5] PEASE M, SHOSTAK R, LAMPORT L. Reaching agreement in the presence of faults[J]. Journal of the ACM, 1980, 27(2): 228-234.
[6] LAMPORT L, SHOSTAK R, PEASE M. The Byzantine generals problem[J]. ACM Transactions on Programming Languages and Systems, 1982, 4(3): 382-401.
[7] LI J R, WOLF T. A one-way proof-of-work protocol to protect controllers in software-defined networks[C]// Proceedings of the 2016 Symposium on Architectures for Networking and Communications Systems. New York: ACM, 2016: 123-124.
[8] CASTRO M, LISKOV B. Practical Byzantine fault tolerance[C]// Proceedings of the 3rd Symposium on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 1999: 173-186.
[9] REITER M K. A secure group membership protocol[J]. IEEE Transactions on Software Engineering, 1996, 22(1): 31-42.
[10] JUNQUEIRA F, REED B. ZooKeeper分布式過程协同技术详解[M].谢超,周贵卿,译.北京:机械工业出版社,2016:188-193.(JUNQUEIRA F, REED B. Detailed Explanation of Zookeeper Distributed Process Collaboration Technology[M]. XIE C, ZHOU G Q, translated. Beijing: China Machine Press, 2016: 188-193.)
[11] 袁勇,王飞跃.区块链技术发展现状与展望[J].自动化学报,2016,42(4):481-494.(YUAN Y, WANG F Y. Blockchain: the state of the art and future trends[J]. Acta Automatica Sinica, 2016, 42(4): 481-494.)
[12] 韩璇,刘亚敏.区块链技术中的共识机制研究[J].信息网络安全,2017(9):147-152.(HAN X, LIU Y M. Research on the consensus mechanisms of blockchain technology[J]. Netinfo Security, 2017(9): 147-152.)
[13] LAMPORT L. The part-time parliament[J]. ACM Transactions on Computer Systems, 1998, 16(2): 133-169.
[14] ONGARO D, OUSTERHOUT J. In search of an understandable consensus algorithm[C]// Proceedings of the 2014 USENIX Annual Technical Conference. Berkeley, CA: USENIX Association, 2014: 305-319.
[15] COWLING J, MYERS D, LISKOV B, et al. HQ replication: a hybrid quorum protocol for Byzantine fault tolerance[C]// Proceedings of the 7th Symposium on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2006: 177-190.
[16] COPELAND C, ZHONG H. Tangaroa: a Byzantine fault tolerant raft [EB/OL].[2018-10-25]. http://www.scs.stanford.edu/14aucs244b/labs/projects/copeland zhong.pdf.
[17] MARTINO W. KADENA: the first scalable, high performance private blockchain [EB/OL].[2018-10-25]. http://kadena.io/docs/Kadena ConsensusWhitePaperAug2016.pdf.
[18] KWON J. Tendermint: consensus without mining[EB/OL]. [ 2018-10-25].https://tendermint.com/static/docs/tendermint.pdf.
[19] GILAD Y, HEMO R, MICALI S, et al. Scaling Byzantine agreements for cryptocurrencies [EB/OL].[2018-10-25]. http://eprint.iacr.org/2017/454.
[20] QUANTUM M. Proof of stake [EB/OL].[2018-10-25]. https://en.bitcoin.it/wiki/Proof of Stake.
