基于协作小小区与流行度预测的在线热点视频缓存更新策略
2019-09-04张超李可范平志
张超 李可 范平志


摘 要:针对无线移动设备数量的指数增长使得异构协作小小区(SBS)将承载大规模的流量负载问题,提出了一种基于协作SBS与流行度预测的在线热点视频缓存更新方案(OVCRP)。首先,分析在线热点视频的流行度在短期内变化情况;然后,构建k近邻模型进行在线热点视频流行度的预测;最后,确定在线热点视频的缓存更新位置。为了选择合适的位置存放在线热点视频,以最小化总体传输时延为目标,建立数学模型,设计整数规划优化算法。仿真实验结果显示,与随机缓存(RANDOM)、最近最少使用(LRU)、最不经常使用(LFU)方案相比,OVCRP在平均缓存命中率和平均访问时延方面具有明显的优势,因此减轻了协作SBS的网络负担。
关键词:异构网络;在线热点视频;k近邻模型;流行度预测;缓存更新
Abstract: The exponential growth in the number of wireless mobile devices leads that heterogeneous cooperative Small Base Stations (SBS) carry large-scale traffic load. Aiming at this problem, an Online-hot Video Cache Replacement Policy (OVCRP) based on cooperative SBS and popularity prediction was proposed. Firstly, the changes of popularity in short term of online-hot videos were analyzed, then a k-nearest neighbor model was constructed to predict the popularities of the online-hot videos, and finally the locations for cache replacement of online-hot videos were determined. In order to select appropriate locations to cache the online-hot videos, with minimization of overall transmission delay as the goal, a mathematical model was built and an integer programming optimization algorithm was designed. The simulation experiment results show that compared with the schemes such as RANDOM cache (RANDOM), Least Recently Used (LRU) and Least Frequently Used (LFU), the proposed OVCRP has obvious advantages in average cache hit rate and average access delay, reducing the network burden of cooperative SBS.
Key words: heterogeneous network; online-hot video; k-Nearest Neighbor (kNN) model; popularity prediction; cache replacement
公式有遺漏,需仔细核对。
0 引言
蜂窝网络中的数据流量正呈现指数级的增长。根据思科CISCO(2016—2021)白皮书,到2021年全球移动数据流量每月将达到49EB,98%的移动数据流量都来自智能移动终端,78%的移动数据都是多媒体视频数据[1]。为了应对5G通信网络的数据流量需求而提出了一种新型的异构小小区的网络架构。该网络可以通过部署更多的离用户更近的微基站来增加网络容量。边缘缓存技术应用到异构小小区网络可以进一步减轻异构小小区网络的传输压力[2]。通过在小小区存放高流行度的内容,既减轻了回程链路的压力,又减少了数据传输时延[3]。
缓存高流行度的内容可以提高缓存命中率。传统的缓存更新方案以清除长期请求量比较少的内容来为高流行度的内容提供缓存空间[4]。例如,最近最少使用(Least Recently Used, LRU)和最不经常使用(Least Frequently Used, LFU)缓存更新算法都假设过去比较流行的内容在未来还会比较流行。对于相对稳定的静态内容,这些方案有比较高的缓存命中率,但是对于在线视频,缓存命中率并不是很高,因为在线视频是动态的且流行度急剧变化[5]。
文献[6]基于内容传输网络提出了一种多层缓存更新方案。在首层的缓存设备里,缓存的内容具有最高的流行度,并且缓存内容的流行度逐层递减。每当一个新的内容被请求时,都会触发缓存更新机制,对新内容进行缓存,并将最低层的最低流行度的内容清除出去。对于新缓存的内容,如果它的流行度过低的话,可能会占据缓存资源,增加网络负担。
基于Femtocell网络模型,文献[7]中提出了一种基于内容流行度的缓存更新方案,以高流行度的内容代替低流行度的内容。文中内容流行度的计算是基于用户访问频率的,频率越高流行度就高,类似于LFU的缓存更新策略。该方案只能“捕获”长期流行的内容,不能够准确分析短期内容的流行度。
来自西班牙的研究团队对YouTube网站6天内产生SCI(Science)类别252255个视频的累计观看次数进行了考察,给出其中100个视频累积观看次数的降序排列图,其中发现将近80%的累积观看次数集中于10%的视频内容[8]。在此,他们还对UGC(User Generated Content)视频的流行度随着时间的变化情况作了统计分析,发现一大部分新近产生的UGC视频的流行度急剧变化,展现出其生存活跃时间较为短暂。
基于上述分析,本文认为,一方面需要从大量的视频数据中快速找出高流行度的在线视频内容;另一方面需要选择合适的节点来存放高流行度的在线视频来满足大多数用户需求,因此,本文提出了一种基于协作小小区和流行度预测的缓存更新方案(Online-hot Video Cache Replacement Policy, OVCRP)。
本文首先爬取哔哩哔哩(bilibili)视频网站的在线视频观看量的数据,分析了在线视频的观看量的变化情况和在线热点视频所占比重的状况,然后,将在线视频观看量的数据集划分为长度为11的时间序列数据集,构建k近邻(k-Nearest Neighbors, kNN)模型进行流行度的预测。本文还分析了AP(Affinity Propagation)流行度预测的方案[9],并作了对比实验。实验结果显示k近邻模型整体的均方误差较小,展现出良好的预测性能。最后,本文以最小化总体传输时延为优化目标,建立数学模型,设计整数规划优化算法。该优化算法可以求解具有大规模节点的目标问题,它具有求解速度快的特性。仿真结果显示,OVCRP和随机缓存(RANDOM cache, RANDOM)、LRU、LFU相比,具有较高的平均缓存命中率和较低的平均访问时延。
1 在线视频数据收集和流行度分析
哔哩哔哩(bilibili)作为国内最大的在线视频服务网站之一,它每天服务的同时在线的用户超过300万,而且每天新上传的在线视频超过6万。在线视频的更新频率是非常快的,并且它的流行度很难预测。最近研究显示,大约20%在线视频的流行度已不再显示渐进的增长,而是展现出急剧的变化[5]。本文称具有这种特性的在线视频为在线热点视频。
现有文献对在线视频流行度的分析与预测存在一些缺陷。Chen等[10]通过对视频播放量的静态观察研究视频流行度。静态视频流行度一般指一段时间内视频观看的次数。为了提高静态视频流行度的预测精度和可靠性,Chen等[10]假设对视频观看次数的观察周期都比较长(例如以天或周为观察周期)。针对不同的视频类型和观测周期,结果发现它们服从Zipf分布、Power-Law分布、指数分布。然而,在线视频的特性具有短期性、流行度动态性。上述分布并不能准确捕获在线视频的流行度,因此本文提出以时为测量单位进行视频流行度的分析。
1.1 在线视频的数据收集
Bilibili网站提供不同类型的视频服务,包括动画、娱乐、影视、游戏、生活等。本文选取上述5种较流行的服务类型的视频作为研究对象,它们的观看量超过了每天观看总量的一半。程序设定每30min爬取每种类型的视频10000个,并且只爬取在线视频的观看量。
1.2 流行度分析
本文收集2018-03-19—2018-04-19这一个月的在线视频数据并定义在线视频的流行度为30min内在线视频的观看量。
图1展示了ID为4341186的在线视频在3月23日一天内的流行度的变化情况。图中的点代表30min内该视频的观看量。从图1中看出,该视频的观看量在某段时间内具有急剧变化的状况,因此称这样的视频为在线热点视频。
图2显示在线热点视频所占的比重在3月22日—3月23日的变化情况。比重定义为半小时内观看量高于指定阈值的在线视频的数量与总的视频数量之比。图2设置了5个不同的阈值,阈值定义为在线视频观看量的界限,观看量高于阈值的为在线热点视频。阈值为1000时,在线热点视频的比重最高大约为34%;阈值为2500时,在线热点视频的比重最高大約为23%;阈值为5000时,在线热点视频的比重最高大约为17%;阈值为7500时,在线热点视频的比重最高大约为13%;阈值为10000时,在线热点视频的比重最高大约为10%。图2显示,不同阈值的曲线大致上具有相同的变化趋势,并且在这2天内,在线热点视频的比重变化状况大致一样。
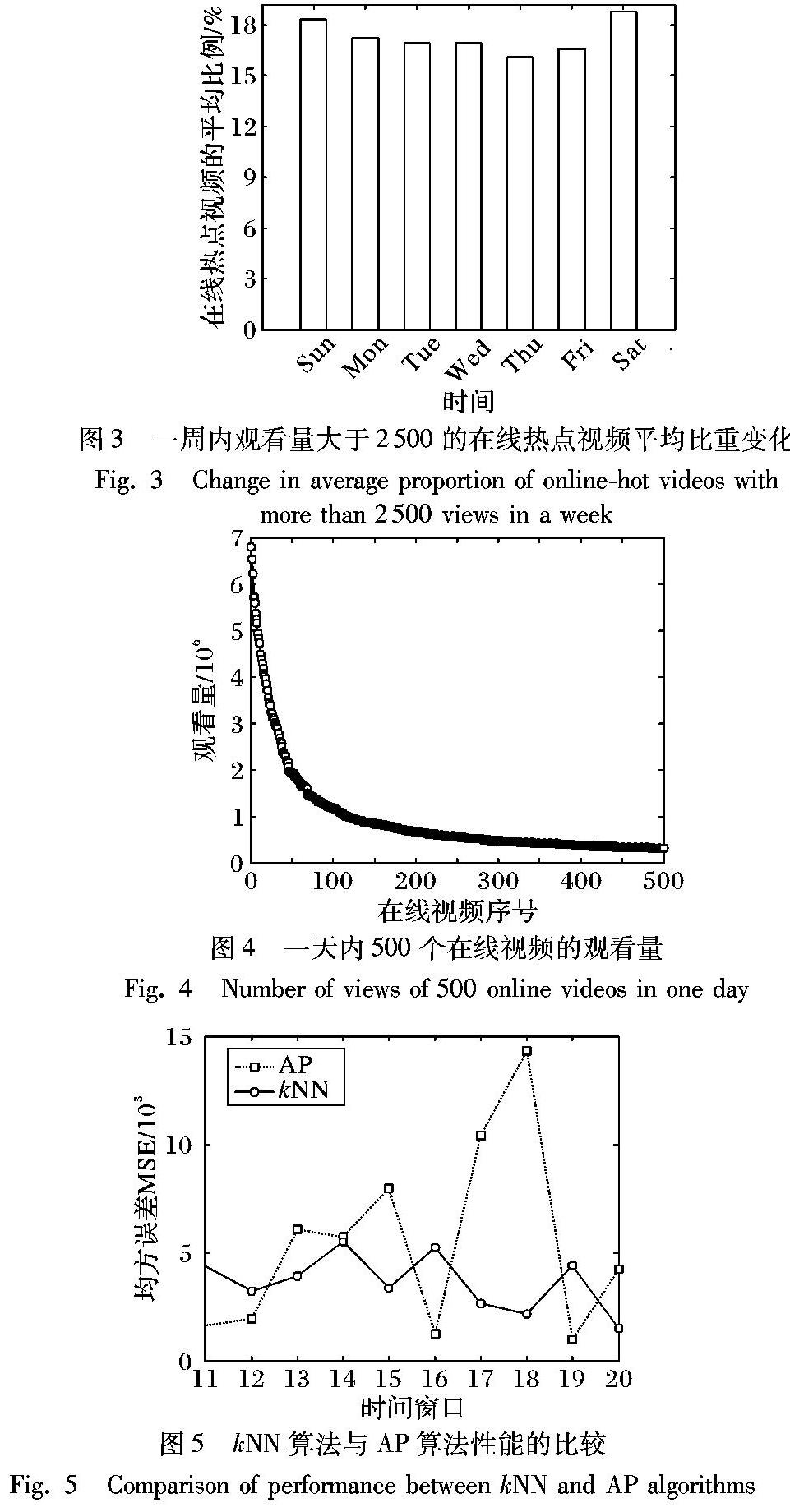
图3展示了阈值为2500时,在线热点视频的平均比重在一周内的变化情况。该图展示的比重为当天在线热点视频的比重的平均值。在线热点视频的平均比重最高大约为20%,且发生在周六和周日;比重最低大约为16%。
图4分析了500个在线视频在一天内的流行度分布情况。从图4中可以得出,大约20%的在线视频占据总观看量的80%,因此,本文设置流行度的阈值为2500,对于观看量大于阈值的在线视频视为在线热点视频。
2 运用k近邻模型进行流行度预测
Ahmed等[9]并没有考虑太多的假设来预测视频内容的流行度,而仅仅考虑了视频内容的观看次数。Ahmed等通过2个步骤进行视频内容流行度的预测:第一步,通过分析内容随时间的不同行为进行分类,以揭示流行度变化的不同模式;第二步,基于步骤一产生的分类结果,靠追踪视频内容流行度随着时间所展现的不同变化行为来预测内容未来的流行度。
在第一步中,采用AP(Affinity Propagation)聚类算法划分内容的类别。AP算法的基本思想是将全部样本看作网络的节点,然后通过网络中各条边的消息传递计算出各样本的聚类中心。聚类过程中,共有两种消息在各节点间传递,分别是吸引度(responsibility)和归属度(availability)。AP算法通过迭代过程不断更新每一个点的吸引度和归属度值,直到产生n个高质量的质心(Exemplar),同时将其余的数据点分配到相应的聚类中心。AP算法之后会得到聚类中心集合M,M={M1,M2,…,MW},其中W为时间窗口。在每一个时间窗口Mi∈W={m1,m2,…,mn},其中mi为质心,i∈{1,2,…,n}。
在第二步中,在集合M上构建概率模型进行视频内容流行度的预测。内容在每一个时间窗口都归属于一个类,随着时间的演变,会展现出一条路径(由每一个时间窗口的类别构成)。被给给定此句不太通顺长度为L的一条路径(p={m1j,m2j,…,mLj}, j∈MW),依靠最大可能性概率P(mL+1j|p)可以计算下一时刻n+1时刻内容的流行度m*,如式(1)所示:
然而,本文对视频内容不再划分类别,直接根据内容的实际历史数据进行流行度的预测。本文利用k近邻回归模型的“平均法”预测在线视频流行度[11]。k近邻模型产生的结果具有较强的一致性。首先,将收集的数据截断为序列长度为11的数据集,选取序列的前10个元素为样本实例,最后1个元素为对应的样本标签。k近邻回归算法1如下,其中i为实例序列,i为对应的实例标签,这里k=11。具体算法1流程如下。
算法1 k近邻回归预测内容流行度算法。
输入:视频样本训练集T={(1,1),(2,2),…,(N,N)},N为样本数,序列实例;
输出:序列实例对应的预测值pre。
1)根据给定的距离度量(欧氏距离),在视频训练集T中找出与实例最近的k个实例样本,并令这k个实例样本的集合为Nk();
2)在集合Nk()中,根據平均法决定所对应的预测值pre并输出,其中pre=1k∑xi∈Nk()yi,i∈[1,k]。
下面,本文进行实验来比较AP算法和k近邻算法流行度预测的准确度。作为算法性能比较,本文采用均方误差(Mean Square Error请补充MSE的英文全称, MSE)指标。将预测结果产生的均方误差进行比较,均方误差小的算法性能比较好。本文依次对11~20采样点时刻(时间窗口)的测试用例进行实验,实验结果如图5所示。
在图5中,纵坐标为均方误差MSE,横坐标为采样点时刻(时间窗口)。实验结果可以看出,kNN算法展现的结果曲线图比较稳定,而AP算法时好时坏,展现出相对不稳定的状态。从整体来看,kNN的整体均方误差较小,具有较好的预测性能。
3 缓存更新模型建立与算法设计
3.1 基于整数规划的缓存更新模型建立
协作小小区网络如图6所示。大量的微基站(Small Base Station, SBS)被一个宏基站(Macro Base Station, MBS)所服务。SBS直接连接MBS,MBS可以直接或通过SBS的重传为用户服务,而且,相邻SBS通过无线或有线连接协作地交换信令或传输数据。由于网络异构性,MBS的传输压力很大程度上卸载到了SBS。本文定义由k近邻模型预测得到的在线热点视频为content X。深色的圆柱体代表缓存content X的缓存设备。SBS之间通过协作性可以进行数据传输,并不需要大量的content X副本存在。由于限制了副本数量,不仅减少了存储空间占用量,而且当内容不再流行时删除副本所造成的开销也会降低。本文考虑MBS保留一份content X的副本用来向合适的SBS上复制内容来缓解网络压力。
缓存更新的执行周期对于网络性能影响很大。周期太长会导致缓存命中率太低,周期太短又会产生大量开销,因此,本文以数据采集的时间为缓存更新的执行周期(即30min)。由于短时间内存在大量的用户访问在线热点视频,因此本文通过最小化content X缓存到其他SBS的时延开销和用户获取content X的时延开销之和执行缓存更新方案。
本文令网络中所有content X的集合为F,F={content1,content2,…,content j},其中content j表示第j个SBS存储的content X。F包括FM(MBS存储的content X)和FS(SBS存储的content X)。V表示SBS和MBS的集合,V=VS∪VM={MBS,SBS1,SBS2,…,SBSv},其中VS表示SBS的集合,VM表示MBS的集合。定义τjv为content j缓存到SBSv的传输时延,τiv为SBSv向用户i传输内容的传输时延。定义yjv为0、1变量,如果content j被缓存到SBSv,则yjv为1,反之为0;定义xiv也为0、1变量,如果SBSv向用户i传输内容,则xiv为1,反之为0。为了便于叙述,本文定义MBS为SBS0,C为请求content X的用户集合。
式(3)表示增加副本数量,但是会设定数量的上限N,以防止副本过多导致网络性能下降;式(4)表示保证基站处有一个content X的副本;式(5)表示一个热点content j只能缓存在一个SBS;式(6)表示一个用户只和一个SBS进行通信;式(7)表示和用户建立通信的SBS中必须存放用户想要的content X。通过计算目标函数式(2)的最小值,便会得到第j个content X缓存的位置以及第i个用户接入的访问节点。
3.2 算法设计
本节主要对3.1节中建立的数学模型设计算法进行优化求解[12]。首先将协作小小区网络看成一个图G,将MBS和SBS映射为图里的点集V;将用户映射到图里的点集C;通信链路的连接状态映射为图里的边(即x和y的值);content X的集合映射为图里的设备集F;时延映射为图中两点之间的代价。通过4个步骤优化求解,这4个步骤分别为:
3.2.1 近邻用户聚合
假设SBS的通信范围较小,用户的访问时延相差不大,并且为了简化算法,本文假设将一个SBS内的所有用户聚合为一个用户,并定义聚合后的用户需求Di为聚合前SBS内的所有用户数量。目标函数式(2)改为如下:
首先松弛约束条件式(8)、(9)为1≥xiv≥0和1≥yjv≥0,这样整数规划问题就成为线性规划问题,便可以求得最优分数解为(,)。本文从最优分数解开始,逐渐优化求整数解(x,y)。首先将最优分数解(,)赋值给(x1,y1)。在图G中,本文定义基点为MBS所代表的点,并定义sumBS为关于基点所有y值之和。由于基点保留一个content X副本,因此sumBS≥1并且为整数。如果sumBS>1,令S=sumBS-1。采取以下措施,在图G中对基点进行分裂,分裂为S+1个同样的基点。对于其中每一个基点,用户连接它的状态和用户连接原来基点的状态一样。为了保证基点分配给位置v的y值不变,对于所有基点的y值,本文将此值定义为原来值的1/(S+1)倍。接下来,进行用户需求的聚合。本文定义i=∑v∈Vxivτiv,并求得i,然后对i进行升序排序。假设1≤2≤…≤|C|,用户需求聚合如算法2所示。
3.2.2 设备重新分配
首先,将解(x1,y1)赋值给(x2,y2)。对于xiv>0的位置v,并且位置v并没有用户需求,寻找离位置v最近的一个用户i′,然后重新分配位置v的设备和被位置v服务的用户到用户i′。令A为位置v处最大x值与总的设备分数之和的商。将关于位置v的每一个y值的A倍分配给用户i′的y值,剩下的1-A倍先保持不变。
对于用户需求为0的位置v,但是关于位置v的y值不为0,需要将y值更正为0,采用如下方法yjj ← yjj+yjv,yjv=0。对于用户i,若关于用户i的y值之和大于1,需要将y值之和减小到1。根据文献[12]的定理2.5,针对用户i满足xii≥1/2,∑i′∈Cxii′=1。也就是说:用户i剩下的1-xii≤1/2被离用户i最近的用户i′(记为(i))所服务。下面使xii的值最大,最大为∑j∈Fyji。方法为:从(i)处获取∑j∈Fyji-xii,并将获取的这部分分配到用户i的x值。设备重新分配伪代码如算法3所示。
3.2.3 得到半整数解
将3.2.2节得到的解(x2,y2)赋值给(x3,y3)。在图G中,本文定义位置v是半整数覆盖的含义指的是∑j∈Fyjv∈{0,1/2,1}。本步骤的目标是使得xiv∈{0,1/2,1},yjv∈{0,1/2,1}。令v′=(v),为离位置v最近的位置v′。首先构建带有权重的二分图,图的一边是位置v,图的另一边是设备j,边的权重是yjv,如图7所示。
本文考虑7个SBS和100个内容,缓存在SBS中的在线热点视频的最大数量为4,视频的流行度阈值为2500,用户从本地SBS获取内容的时延为0ms,用户从附近SBS或MBS获取内容的时延为20ms,用户从远端服务器获取内容的时延为40ms,并且内容的流行度分布满足图4的分布。实验设置在一个时间单元内产生80000次请求,共产生11组时间单元的内容请求。在前10组的请求数据中,运用RANDOM、LRU、LFU和OVCRP決定出最终缓存在SBS上的内容并在最后一组实验数据上进行性能评估。因为流行度预测的时间序列为10,需要根据前10组请求数据产生出长度为10的时间序列。本次实验使用两个性能指标进行评估,平均缓存命中率和平均访问时延。平均缓存命中率指的是命中SBS中缓存的总请求次数和所有用户总的请求次数的比[7],如式(11):
平均缓存命中率=总缓存命中的次数所有用户总请求次数(11)
平均访问时延指的是所有用户的访问时延和总用户数量的比[16],如式(12):
平均访问时延=所有用户的总访问时延总用户数量(12)
图9(a)显示了缓存容量对平均缓存命中率的影响,其中缓存容量为10~45。从图9(a)中可以看出,随着缓存容量的逐渐增大,各种方案的缓存命中率也随着增加,但是,OVCRP的缓存命中率最高,其次是LFU,最后是LRU和RANDOM。OVCRP的缓存命中率要高于LFU约17.48%、高于LRU约35.26%、高于RANDOM约35.82%。LRU和RANDOM的缓存命中率大致一样,这是由于LRU和RANDOM不能准确分析在线热点视频的流行度,然而OVCRP能精确分析出在线热点视频的流行度,并且考虑了SBS之间的协作性,因此展现出较高的缓存命中率。
图9(b)显示了缓存容量对平均访问时延的影响,OVCRP具有最低的平均访问时延,其次是LFU,最后是LRU和RANDOM策略。这是由于,OVCRP充分考虑了SBS之间的协作性,使得用户可以访问邻近的SBS,省去了用户访问远端服务器的过程,从而降低了用户的访问时延。从图9中可以看出,平均缓存命中率和平均访问时延呈现出相反的情况。平均缓存命中率越高,平均访问时延就越小;平均缓存命中率越低,平均访问时延就越大。
5 结语
通过分析在线视频的流行度,本文提出了一种基于SBS协作和流行度预测的在线热点视频缓存更新策略。因为热点内容具有短期爆发性、流行度高的特点,因此,本文将数据划分成短序列样本,通过构建k近邻模型进行在线热点视频流行度的预测。由于短期内大量的用户访问在线热点视频,因此本文通过最小化总体时延构建整数规划的数学模型;最后,通过设计图算法求解。仿真实验从平均缓存命中率和平均访问时延两个方面评估OVCRP,并将OVCRP和RANDOM、LRU和LFU传统方案进行比较。实验结果表明,从平均缓存命中率方面,OVCRP要高于LFU、LRU和RANDOM;在平均访问时延方面,OVCRP展现出最低的平均访问时延,具有良好的性能;但是本文并未考虑用户位置的变化场景,接下来将结合用户的移动性[17]进行异构协作小小区缓存更新方案的研究。
参考文献 (References)
[1] CISCO. CISCO visual networking index: global mobile data traffic forecast update 2016—2021[EB/OL]. [2018-09-20]. http://www.cisco.com/c/en/us/solutions/collateral/serviceprovider/visual-networking-index-vni/mobile-white-paper-c11-520862.html.
[2] 吴天昊.边缘缓存网络中的内容分发及基站休眠算法研究[D].北京:北京邮电大学,2018.(WU T H. Research on content distribution and base station sleep management algorithms in edge caching networks[D]. Beijing: Beijing University of Posts and Telecommunications, 2018.)
[3] WANG X, LI X, LEUNG V C M, et al. A framework of cooperative cell caching for the future mobile networks[C]// Proceedings of the 2015 48th Hawaii International Conference on System Sciences. Piscataway, NJ: IEEE, 2015: 5404-5413.
[4] 席海东.智慧协同网络中内容流行度预测与缓存替换策略研究[D]. 北京:北京交通大学,2018.(XI H D. Research on content-popularity prediction and caching replacement schemes in smart identifier network[D]. Beijing: Beijing Jiaotong University, 2018.)
[5] ROY S D, MEI T, ZENG W, et al. Towards cross-domain learning for social video popularity prediction [J]. IEEE Transactions on Multimedia, 2013, 15(6): 1255-1267.
[6] MIAO F, CHEN D, JIN L. Multi-level PLRU cache algorithm for content delivery networks [C]// Proceedings of the 2017 10th International Symposium on Computational Intelligence and Design. Piscataway,NJ:IEEE, 2017, 1: 320-323.
[7] PINGYOD A, SOMCHIT Y. Content updating method in femtocaching[C]// Proceedings of the 2014 11th International Joint Conference on Computer Science and Software Engineering (JCSSE). Piscataway, NJ: IEEE, 2014: 123-127.
[8] CHA M, KWAK H, RODRIGUEZ P, et al. I tube, you tube, everybody tubes: analyzing the worlds largest user generated content video system[C]// Proceedings of the 7th ACM SIGCOMM Conference on Internet Measurement. New York: ACM, 2007: 1-14.
[9] AHMED M, SPAGNA S, HUICI F, et al. A peek into the future: predicting the evolution of popularity in user generated content[C]// Proceedings of the Sixth ACM International Conference on Web Search and Data Mining. New York: ACM, 2013: 607-616.
[10] CHEN Y, ZHANG B, LIU Y, et al. Measurement and modeling of video watching time in a large-scale Internet video-on-demand system[J]. IEEE Transactions on Multimedia, 2013, 15(8): 2087-2098.
[11] ZHANG M L, ZHOU Z H. ML-KNN: a lazy learning approach to multi-label learning [J]. Pattern Recognition, 2007, 40(7): 2038-2048.
[12] FRIGGSTAD Z, SALAVATIPOUR M R. Minimizing movement in mobile facility location problems [J]. ACM Transactions on Algorithms, 2011, 7(3): 28.
[13] PSOUNIS K, PRABHAKAR B. A randomized Web-cache replacement scheme[C]// INFOCOM 2001: Proceedings of the 2001 Twentieth Annual Joint Conference of the IEEE Computer and Communications Societies. Piscataway, NJ: IEEE, 2001: 1407-1415.
[14] KHALEEL M S A, OSMAN S E F, SIROUR H A N. Proposed ALFUR using intelegent Agent comparing with LFU, LRU, SIZE and PCCIA cache replacement techniques[C]// Proceedings of the 2017 International Conference on Communication, Control, Computing and Electronics Engineering. Piscataway, NJ: IEEE, 2017: 1-6.
[15] ARLITT M, CHERKASOVA L, DILLEY J, et al. Evaluating content management techniques for Web proxy caches[J]. ACM SIGMETRICS Performance Evaluation Review, 2000, 27(4): 3-11.
[16] CHANG Z, GU Y, HAN Z, et al. Context-aware data caching for 5G heterogeneous small cells networks[C]// Proceedings of the 2016 IEEE International Conference on Communications. Piscataway, NJ: IEEE, 2016: 1-6.
[17] 宋天鳴.异构密集小小区中基于用户移动性的边缘缓存策略[D].北京:北京邮电大学,2018.(SONG T M. Edge caching strategy based on user mobility in dense small cell networks[D]. Beijing: Beijing University of Posts and Telecommunications, 2018.)
