基于逆向习得推理的网络异常行为检测模型
2019-09-04杨宏宇李博超
杨宏宇 李博超


摘 要:针对网络异常行为检测中因数据不平衡而导致召回率低的问题,提出一种基于逆向习得推理(ALI)的网络异常行为检测模型。首先,去除数据集中用离散数据表示的特征项,并对处理后的数据集进行归一化以提高模型的收敛速度与精度;然后,提出改进的ALI模型,通过ALI训练算法用仅由正样本所构成的数据对其进行训练,并利用已训练完成的改进ALI模型处理检测数据以生成处理后的检测数据集;最后,依据异常检测函数计算检测数据与处理后的检测数据之间的距离来判断数据是否异常。与单类支持向量机(OC-SVM)、深层结构能量模型(DSEBM)、深度自编码高斯混合模型(DAGMM)和生成对抗网络异常检测模型(AnoGAN)的对比实验结果表明,所提模型的准确率提升了5.8~17.4个百分点,召回率提升了1.4~31.4个百分点,F1值提升了14.18~19.7个百分点。可知所提出的基于逆向习得推理的网络异常行为检测模型在数据不平衡时仍具有较高的召回率和检测精度。
关键词:逆向习得推理;异常行为检测;数据不平衡;数据归一化
Abstract: In order to solve the problem of low recall rate caused by data imbalance in network abnormal behavior detection, a network abnormal behavior detection model based on Adversarially Learned Inference (ALI) was proposed. Firstly, the feature items represented by discrete data in a dataset were removed, and the processed dataset was normalized to improve the convergence speed and accuracy of the model. Then, an improved ALI model was proposed and trained by ALI training algorithm with a dataset only consisting of positive samples, and the improved ALI model which had been trained was used to process the detection data to generate the processed detection dataset. Finally, the distance between detection data and the processed detection data was calculated based on abnormality detection function to determine whether the data was abnormal. The experimental results show that compared with One-Class Support Vector Machine (OC-SVM), Deep Structured Energy Based Model (DSEBM), Deep Autoencoding Gaussian Mixture Model (DAGMM) and Anomaly detection model with Generative Adversarial Network (AnoGAN), the accuracy of the proposed model is improved by 5.8-17.4 percentage points, the recall rate is increased by 1.4-31.4 percentage points, and the F1 value is increased by 14.18-19.7 percentage points. It can be seen that the network abnormal behavior detection model based on ALI has high recall rate and detection accuracy when the data is unbalanced.
Key words: Adversarially Learned Inference (ALI); abnormal behavior detection; data imbalance; min-max scaling
0 引言
網络异常行为是指由网络用户实施的对网络正常运行造成影响的行为。这些行为具有隐蔽性强、窃取机密文件和造成网络服务质量急剧下降等特点。随着网络技术的快速发展和应用,网络异常行为的新变种更是层出不穷,其威胁也日益严重。对网络异常行为进行高效检测已成为目前的研究热点。
随着机器学习算法的广泛应用,许多学者使用机器学习方法进行网络异常行为检测研究。文献[1]采用单类支持向量机(One-Class Support Vector Machine, OC-SVM)算法通过将One-Class SVM和Online训练算法应用于入侵检测中,能够在有噪声的数据集中进行训练,同时解决了基于支持向量机(Support Vector Machine, SVM)的入侵检测实时训练的问题。上述方法的主要不足是复杂度较高,且对于大型数据集的计算代价很大,由于选择了全局阈值,无法有效处理不同密度区域的数据集。文献[2]通过使用主成分分析法(Principal Component Analysis, PCA)对原始数据集进行数据降维并消除冗余数据,找到具有最优分类效果的主成分属性集, 解决了对于大型数据集计算代价大的问题,但检测准确度较低。
使用机器学习算法检测网络异常行为检测准确率低的主要原因是可收集到的异常行为样本种类少且数量有限,造成收集到的数据集不平衡。文献[3-4]中提出通过使用变分自编码器(Variational Auto-Encoder, VAE)模型训练正常行为,虽解决了网络异常检测中数据集不平衡问题,但该方法在对数据集的处理过程中易出现关键特征提取效率不高,造成生成数据集“失真”的情况,导致检测结果准确率波动较大。
为解决以上问题,文献[5]中提出基于优化数据处理的深度置信网络入侵检测方法;文献[6]中提出基于深度置信网络的入侵检测模型;文献[7]中提出多种群克隆选择算法,通过改变该算法的匹配规则以提高识别异常数据的效率。上述方法虽然提高了入侵检测的准确率,但对于模型的参数调优较为困难,且特征提取效率较低,导致模型计算任务量大。针对上述不足,文献[8]建立了一种卷积神经网络模型,通过提高该网络提取特征的效率,进而提高了分类的准确性;文献[9]中提出了一种基于卷积神经网路算法的网络入侵检测系统,该系统通过自动提取入侵样本的有效特征,从而提升分类的准确性。上述两种方法的主要不足在于模型训练过程中收敛速度不理想,泛化能力差,导致误报率较高。
综上所述,在对网络异常行为的检测过程中,使用机器学习算法检测主要存在如下问题:
1)由于难以收集异常行为样本,导致数据集中异常数据与正常数据的量级存在严重偏差,使得训练后的结果偏向于正常行为,产生误判,因而这种方法对于网络异常行为的检测正确率较低。
2)机器学习算法对较小数据量的样本具有较好的分类效果,而且对样本的数据特征敏感,尤其是处于分类边界上的样本,若分类边界上存在被错误分配的样本,则会严重影响分类的准确性[1]。
基于逆向习得推理(Adversarially Learned Inference,ALI)模型[9]是一种成功应用于模拟复杂和高维分布的数据生成模型,其主要优势为:
1)无需利用马尔可夫链反复采样,无需在学习过程中进行推断,回避了棘手的概率计算难题;
2)如果判别器训练良好,生成网络则可以有效地学习到训练样本的分布。
因此,本文考虑通过设计一个模型首先来学习正常数据的分布,然后将检测数据输入训练完的模型并计算出其正常分布,最后将处理后的检测数据与检测数据通过异常检测函数进行对比判断此数据的异常情况。
1 ALI基本内涵
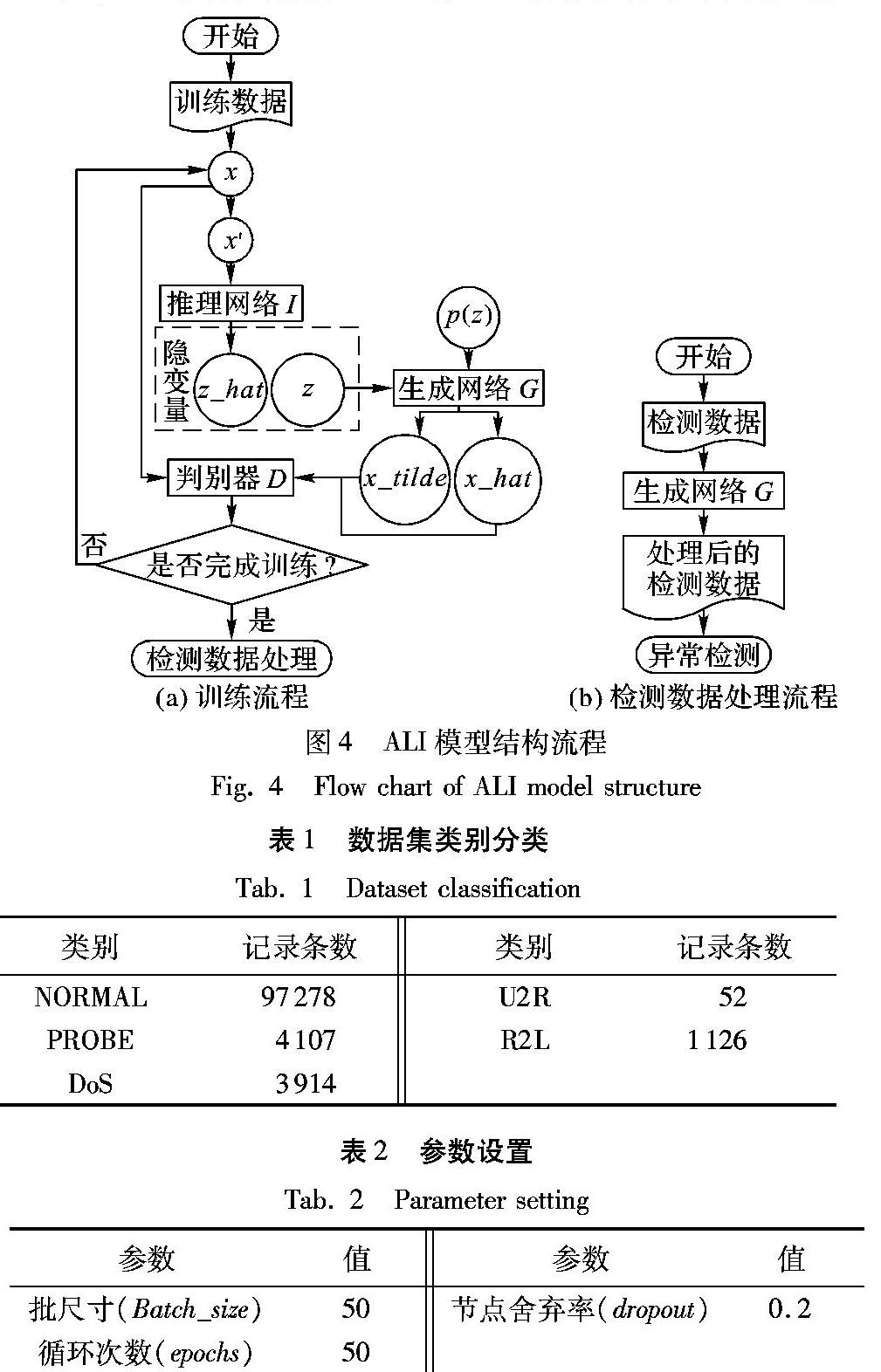
ALI模型是一种无监督数据生成模型,由编码器、解码器和判别器组成。其学习过程就是编码器、解码器和判别器之间的一种竞争过程。文献[10]将这一思想表示为:
当将ALI模型训练用于生成数据时,解码器将真实训练样本x映射到潜在变量空间,得到z_hat;编码器将潜在变量z转化为生成样本x_tilde。假设解码器的输入输出(x,z_hat)分类为1,编码器的输入输出(x_tilde,z)分类为0。判别器的目标是将尽可能多的(x,z_hat)判别为1,同时将尽可能多的(x_tilde,z)判别为0,即D(x,Gz(x))≈1且D(Gx(z),z)≈0。当编码器、解码器和判别器在训练中经过多轮竞争最终达到平衡时,此时编码器生成数据x_tilde与真实训练样本x将非常相似。ALI理论上经过训练可以完全逼近真实数据的分布,这是ALI模型的最大优势和特点。
1)数据预处理模块。
操作处理过程为:
①因ALI模型只能处理连续性数据,故去掉使用离散数据表示的特征项。
②遍历数据集对数据进行归一化处理,将数据变为[0,1]区间的小数,以提高模型收敛速度和异常检测函数计算精度。生成预处理后数据集。
2)异常检测模块。
在异常检测模块包括训练和检测过程,处理过程为:
①将预处理后的数据集按照标签分为正常数据与异常数据两类,随机从正常数据中抽取80%的数据组成训练数据集,剩余的20%和异常数据组成检测数据集。
②構建ALI模型,确定其生成网络和推理网络的构成,然后用训练数据集训练ALI模型,重复训练并调整网络内部神经元的权重。
③将检测数据集输入到训练后的ALI模型中,由该模型对所输入的数据进行处理,输出处理后的检测数据。
④将处理后的检测数据和检测数据作为数据源,使用异常检测函数计算两者之间的距离,判断异常状态并输出检测结果。
3 数据预处理
在数据预处理模块,首先去除数据集中使用离散数据表示的特征项,然后对处理后的数据集进行数据归一化(Min-Max scaling),以提高模型的收敛速度与精度。具体处理过程设计如下:
步骤1 首先,统计数据集中以离散数据表示的特征项的名称;然后,遍历数据集并将所有用离散数据表示的特征项数据去掉。
步骤2 在数据集中,连续型特征数据之间取值范围差异明显。例如特征项duration和protocol_type在数据集中的取值范围分别为[0,58329]和[1,3],可见两者之间的取值范围差距很大。为了便于异常检测函数运算和消除量纲,运用函数归一化方法,将数据集中所有数据变为[0,1]区间的小数。归一化公式如下:
步骤1 将数据集D中按照标签分为正常数据与异常数据分类,组成正常数据集D_normal与异常数据集D_anomal。随机从D_normal中抽取80%的数据组成训练数据D_train,剩余的20%数据和D_anomal组成检测数据D_test。
步骤2 使用ALI算法训练D_train,经过k次迭代训练,确定生成网络、推理网络内部神经元的权重。设生成网络为G、推理网络为I、判别网络为D,处理流程如算法2所述。
其中假设数据集有m个属性,xaj和xbj分别表示D_test_fin中的记录xa与D_test中的记录xb对应的第j个属性值。本文认为拥有较大检测结果值的样本异常可能性大。
4.2 改进ALI模型
在ALI模型中,推理网络的训练只是简单地将输入复制到輸出,虽保留了原始数据的特征,并不能确保隐变量获得有用的特征表示。为了增强提高推理网络与生成网络的训练效率,本文考虑首先通过引入一个损坏过程C(x′|x),得到受损数据作为ALI模型的输入,然后在ALI模型的隐含层填加一些约束,让这些约束使模型对输入数据中有用的特征优先学习,使模型可以学习到能更好表达样本的特征。
改进ALI的基本结构由推理网络I、生成网络G和判断器D三部分构成,都是由输入层、隐含层和输出层构成的神经网络。
改进ALI模型首先对训练数据进行训练,确定推理网络I、生成网络G和判别器D的内部神经元的权重。之后使用训练好的生成网络G对检测数据进行处理,得到处理后的检测数据。ALI模型结构流程如图4所示。
改进ALI模型的处理流程如下。
输入:训练数据D_train,检测数据D_test。
输出:处理后的检测数据D_test_fin。
步骤1 网络采用分批次训练,每次训练都从训练数据D_train中随机选取固定大小的块(batch)作为输入数据x,根据文献[11]提供的方法,通过引入一个损坏过程C(x′|x),得到受损数据x′作为推理网络的输入。
其中:z_hat为推理网络输出结果;x_tilde为生成网络输出结果;θ={W1,b1,W2,b2}表示参数的集合;f和g代表激活函数为sigmod,即当神经元的输出接近于1时为激活状态,而输出为0时为抑制状态。推理网络和生成网络的目标是最小化输入数据x与生成网络重构数据x_tilde之间的平均重构误差。为了防止模型过拟合,对损失函数加入惩罚项,损失函数如式(8)所示:
其中,ρ是稀疏性参数。式(10)表示让推理网络和生成网络隐含层中神经元j的平均活跃度接近于ρ。为达到这一稀疏限制的目标,在优化目标函数中加入一个额外的惩罚因子,即通过最小化这一惩罚因子来实现ρj′趋近于ρ的效果,所以惩罚因子可由式(9)此处的描述不通顺,另外,式(9)是否应该为式(10)?请明确。表示:
步骤3 生成网络从服从高斯分布的p(z)中随机采样作为输入,经生成网络处理生成x_hat。
步骤4 将x、x_hat和x_tilde输入判别器。判别器的目标是将生成网络的输出x_hat和x_tilde从真实样本x中尽可能分辨出来,而生成网络则要尽可能地欺骗判别器。两个网络相互对抗,不断调整参数。判别器的损失函数为:
5 实验分析
5.1 数据集与环境配置
KDD99数据集建立的目的是为入侵检测系统提供统一的性能评价基准。本实验使用KDD99 10%数据集作为本次实验的数据集,数据集以CSV格式存储,共计494021条记录,每条记录由41个特征项和1个标记位组成,标记位分为正常(normal)或异常(attack)两大类,异常类型被细分为4大类,分别为拒绝服务攻击(Denial of Service, DoS)、未授权远程主机访问(unauthorized access from a Remote machine to a Local machine, R2L)、本地未授权超级用户特权访问(Unauthorized access to local superuseR privileges by a local unprivileged user, U2R)和端口监视或扫描(surveillance and probing, PROBE)。数据集类别分布如表1所示。
实验中主机配置为Intel Core i5-6300HQ CPU,NVIDIA GeForce GTX960 GPU,内存4GB,使用Python 3.5.3编程实现,深度学习框架使用Tensorflow 1.1.0。
5.2 参数设置
ALI中训练阶段采用小批量梯度下降方法(Mini-batch Gradient Decent)对内部神经元权重进行调整,以达到降低梯度下降的计算量,即每次迭代使用固定的样本个数对参数进行更新,实现了并行计算,使模型收敛速度相比批量梯度下降和随机梯度下降方法有所提高。本文将训练集中每50个样本分为一组,每次按顺序选取一组进行训练,所有组均训练一次记为一个循环,共循环进行50次训练。
为了防止过拟合,本文在小批量梯度下降方法中每次训练过程中都暂时随机丢弃所有神经元节点的20%。具体参数设置如表2所示。
5.3 评估指标
在检测实验中,为客观评估检测模型的有效性,本文将准确率和召回率的加权调和平均值F1值作为模型的最终评估指标,为此定义如下3个基本指标量。
TP(True Positive)表示网络异常行为被正确识别的数量;FP(False Positive)表示网络正常行为被错误识别为异常行为的数量;FN(False Negative)表示网络异常行为被错误识别为正常行为的数量。利用上述3个基本指标,定义如下3个度量指标。
由表3可知数据集一共有9项特征使用离散型数据描述,首先遍历数据集将以上特征项的数据删除。之后由算法1得到归一化后的数据集,至此,数据预处理完成。
5.5 检测实验
为验证本文模型对网络异常行为检测的有效性,实验步骤如下:
1)首先对连续化的数据集D按照每条记录的第42项标记位分为正常数据集D_normal与异常数据集D_anomal;
然后使用Pandas工具库中sample函数,设置frac参数为0.8,随机从D_normal中抽取80%的数据组成训练集D_train;
最后,将D_train中剩余的20%数据和D_anomal组成检测数据D_test,删除D_train和D_test数据中的第42项标记位,生成CSV格式文件。数据集D拆分结果如表4所示。
3)将检测数据集D_test输入已训练好的ALI模型中处理,输出D_test_fin。将D_test_fin和D_test输入异常检测函数公式(3),计算D_test每条记录的结果并与网络异常行为检测中常用的算法模型进行对比实验。实验样本均来自同一数据集(D_train),选择的模型分别为:OC-SVM[1]、深层结构能量模型(Deep Structured Energy Based Model, DSEBM)[12]、深度自编码高斯混合模型(Deep Autoencoding Gaussian Mixture Model, DAGMM)[13]和生成对抗网络异常检测模型(Anomaly detection model with Generative Adversarial Network, AnoGAN)[14]。以上模型均为笔者Python编程实现,重复进行10次实验并计算10次检测结果中准确率、召回率和F1值的平均值,结果如表5所示。
由表5可见,本文模型在召回率和F1两项指标方面均优于其他的检测模型。分析对比模型如下:
1)OC-SVM模型与本文模型相比,模型在分类过程中无法有效判定异常行为的数据边界,故导致准确率、召回率和F1值相对于其他模型偏低。
2)DSEBM采用逐层次进行训练,每一层训练完成之后才进行下一层叠加并计算上一层的参数。无法有效对本文高维度复杂数据集进行特征学习,模型误判率很高,故其评估指标FN值偏大,导致相比本文模型检测准确度偏低。
3)AnoGAN生成网络的梯度更新来源于判别网络,导致生成网络更倾向生成重复但不会被判别网络认为异常的样本,而对于与生成网络生成的相似的检测数据,该模型有很高的检测准确度。AnoGAN因缺少诸如本文模型的推理网络,导致模型经训练未得到正常行为的全部数据分布,导致模式崩溃(mode collapse)[15]。
4)考虑到DAGMM虽对数据集使用高斯概率密度函数(正态分布曲线)进行精确量化,并分解为若干基于高斯概率密度函数形成的模型,提高了检测准确率;但受本文训练样本数量少的限制,DAGMM内每个混合模型没有足够多的样本,协方差计算结果不准确,故F1值相对于本文模型较低。
为了进一步验证本文模型在较少训练样本情况下的有效性,针对DAGMM和本文模型,缩小实验样本量,在D_train中随机抽取2000条数据,重复进行10次实验,并计算检测结果中准确率、召回率和F1值,结果如表6所示。
由表6可见,在训练样本较少时,本文模型相对于DAGMM,在准确率、召回率和F1三项指标方面均有明显提高。
本文模型的优势在于运用逆向习得推理机制,结合无监督的模型训练和有监督的分类与回归任务,无需显性表达生成分布,也没有繁杂的变分下限,有效避免了在传统生成模型中复杂的马尔可夫链的采样和推断,在大幅度降低了训练复杂度的同时提高了检测准确度。
上述实验结果表明,本文提出的基于逆向习得推理的网络异常行为检测模型具有较高的召回率和检测精度。
6 结语
本文针对网络异常行为数据收集不均衡以及现有检测算法检出率低等问题,提出基于逆向习得推理的网络异常行为检测模型。对数据集通过去掉离散数据项,使用线性函数归一化提高了模型的收敛速度和模型的精度,该模型首先通过ALI算法训练正常行为数据的分布;之后使用已经训练好的ALI算法处理检测数据的正常分布;最后使用异常检测函数对比判断检测数据是否异常,解决了因数据不平衡问题导致的检测正确率低的问题。实验结果表明,本文模型在样本数据不平衡时相比OC-SVM、DSEBM、DAGMM和AnoGAN四种模型具有较高的召回率和检测精度。
下一步对本文模型的改进重点集中在以下两个方面:1)对异常检测结果分类,得出异常行为的准确攻击类别;2)尝试使用其他数据集训练和测试验证本文模型,根据实验结果对本文模型继续优化,进一步提高检测准确度。
参考文献 (References)
[1] 黄谦,王震,韦韬,等.基于One-Class SVM的实时入侵检测系统[J].计算机工程,2006,32(16):133-135.(HUANG Q, WANG Z, WEI T, et al. A Real-time intrusion detection system based on One-Class SVM[J]. Computer Engineering, 2006, 32(16): 133-135.)
[2] 戚名鈺,刘铭,傅彦铭.基于PCA的SVM网络入侵检测研究[J].信息网络安全,2015(2):15-18.(QI M Y, LIU M, FU Y M. Research on network intrusion detection using support vector machines based on principal component analysis[J]. Netinfo Security, 2015(2): 15-18.)
[3] ZHOU C, PAFFENROTH R C. Anomaly detection with robust deep autoencoders[C]// Proceedings of the 2017 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2017: 665-674.
[4] 袁靜,章毓晋.融合梯度差信息的稀疏去噪自编码网络在异常行为检测中的应用[J].自动化学报,2017,43(4):604-610.(YUAN J, ZHANG Y J. Application of sparse denoising auto encoder network with gradient difference information for abnormal action detection[J]. Acta Automatica Sinica, 2017, 43(4):604-610.)
[5] 陈虹,万广雪,肖振久.基于优化数据处理的深度信念网络模型的入侵检测方法[J].计算机应用,2017,37(6):1636-1643.(CHEN H, WAN G X, XIAO Z J. Intrusion detection method of deep belief network model based on optimization of data processing [J]. Journal of Computer Applications, 2017, 37 (6): 1636-1643.)
[6] QU F, ZHANG J, SHAO Z, et al. An intrusion detection model based on deep belief network[C]// Proceedings of the 2017 VI International Conference on Network, Communication and Computing. Kunming: [s.n.], 2017: 97-101.
[7] 魏明军,王月月,金建国.一种改进免疫算法的入侵检测设计[J].西安电子科技大学学报,2016,43(2):126-131.(WEI M J, WANG Y Y, JIN J G. Intrusion detection design of the impoved immune algorithm[J]. Journal of Xidian University, 2016, 43(2): 126-131.)
[8] 贾凡,孔令智.基于卷积神经网络的入侵检测算法[J].北京理工大学学报,2017,37(12):1271-1275.(JIA F, KONG L Z. Intrusion detection algorithm based on convolutional neural network[J]. Transactions of Beijing Institute of Technology, 2017, 37(12): 1271-1275.)
[9] 王明,李剑.基于卷积神经网络的网络入侵检测系统[J].信息安全研究,2017,3(11):990-994.(WANG M, LI J. Network intrusion detection model based on convolutional neural network[J]. Journal of Information Security Research, 2017, 3(11): 990-994.)
[10] DUMOULIN V, BELGHAZI I, POOLE B, et al. Adversarially learned inference[J]. ArXiv Preprint, 2016, 2016: 1606.00704.(https://arxiv.org/pdf/1606.00704.pdf)
[11] VINCENT P, LAROCHELLE H, BENGIO Y, et al. Extracting and composing robust features with denoising autoencoders [C]// Proceedings of the 25th International Conference on Machine Learning. New York: ACM, 2008: 1096-1103.
[12] ZHAI S, CHENG Y, LU W, et al. Deep structured energy based models for anomaly detection[J]. ArXiv Preprint, 2016, 2016: 1605.00717.
[13] ZONG B, SONG Q, MIN M R, et al. Deep autoencoding Gaussian mixture model for unsupervised anomaly detection [C]// Proceedings of the 2018 International Conference on Learning Representations. Vancouver: ICLR, 2018: 1203-1224.
[14] SCHLEGL T, SEEBCK P, WALDSTEIN S M, et al. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery [C]// Proceedings of the 2017 International Conference on Information Processing in Medical Imaging. Berlin: Springer, 2017: 146-157.
[15] METZ L, POOLE B, PFAU D, et al. Unrolled generative adversarial networks[J]. ArXiv Preprint, 2016, 2016: 1611.02163.
