基于强化学习的实体关系联合抽取模型
2019-09-04陈佳沣滕冲
陈佳沣 滕冲

摘 要:针对现有的基于远程监督的实体和关系抽取方法存在着标签噪声问题,提出了一种基于强化学习的实体关系联合抽取方法。该模型有两个模块:句子选择器模块和实体关系联合抽取模块。首先,句子选择器模块选择没有标签噪声的高质量句子,将所选句子输入到实体关系联合抽取模型;然后,实体关系联合抽取模块采用序列标注方法对输入的句子进行预测,并向句子选择器模块提供反馈,指导句子选择器模块挑选高质量的句子;最后,句子选择器模块和实体关系联合抽取模块同时训练,将句子选择与序列标注一起优化。实验结果表明,该模型在实体关系联合抽取中的F1值为47.3%,与CoType为代表的联合抽取模型相比,所提模型的F1值提升了1%;与LINE为代表的串行模型相比,所提模型的F1值提升了14%。结果表明强化学习结合实体关系联合抽取模型能够有效地提高序列标注模型的F1值,其中句子选择器能有效地处理数据的噪声。
Abstract: Existing entity and relation extraction methods that rely on distant supervision suffer from noisy labeling problem. A model for joint entity and relation extraction from noisy data based on reinforcement learning was proposed to reduce the impact of noise data. There were two modules in the model: an sentence selector module and a sequence labeling module. Firstly, high-quality sentences without labeling noise were selected by instance selector module and the selected sentences were input into sequence labeling module. Secondly, predictions were made by sequence labeling module and the rewards were provided to sentence selector module to help the module select high-quality sentences. Finally, two modules were trained jointly to optimize instance selection and sequence labeling processes. The experimental results show that the F1 value of the proposed model is 47.3% in the joint entity and relation extraction, which is 1% higher than those of joint extraction models represented by CoType and 14% higher than those of serial models represented by LINE(Large-scale Information Network Embedding). The results show that the joint entity and relation extraction model in combination with reinforcement learning can effectively improve F1 value of sequential labeling model, in which the sentence selector can effectively deal with the noise of data.
Key words: reinforcement learning; joint extraction; sequence tagging; named entity recognition; relation classification
0 引言
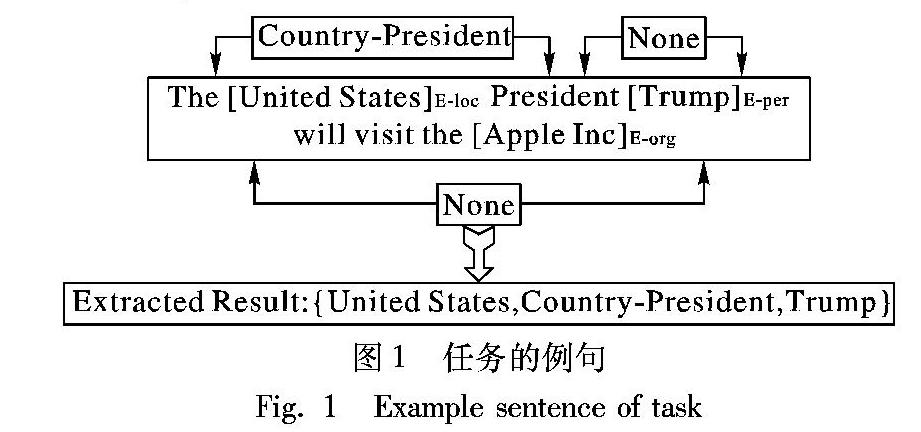
實体和关系的联合抽取是从非结构化文本中同时检测实体引用和识别它们的语义关系,如图1所示。不同于Banko等[1]从给定句子中抽取关系词的开放信息抽取,在本任务中,关系词是从预定义的关系集中抽取的,该关系集可能不会出现在给定句子中。它是知识抽取和知识库自动构建中的一个重要途径。
传统方法以串行的方式处理此任务,即Nadeau等[2]先抽取实体,然后Rink等[3]识别它们的关系。这个串行的框架使任务易于处理,并且每个组件可以更灵活;但是它忽略了这两个子任务之间的相关性,并且每个子任务都是一个独立的模型。Li等[4]提出实体识别的结果可能会影响关系分类的效果,并导致错误的传递。
与传统方法不同,联合学习框架是使用单个模型将实体识别和关系抽取结合在一起。它能有效地整合实体信息和关系信息,在这项任务中取得了较好的效果。大多数现有的联合方法是基于特征的结构化系统[4]。它们需要复杂的特性工程,并且严重依赖于其他自然语言处理(Natural Language Processing, NLP)工具包,这也可能导致错误传播。为了减少特征抽取中的手工工作,Miwa等[5]提出了一种基于神经网络的端到端实体和关系联合抽取方法。虽然联合模型可以在单个模型中让实体识别模块与关系分类模块共享参数,但它们也是分别抽取实体和关系,并生成冗余信息。例如,图1中的句子包含三个实体:“United States”“Trump”和“Apple Inc”,但只有“United States”和“Trump”才有固定的关系“Country-President”。在这句话中,实体“Apple Inc”与其他实体没有明显的关系,因此,从这句话中抽取的结果是{United States,Country-President,Trump},它在这里称为三元组。Zheng等[6]提出了一个标签方案,将联合抽取任务转换为标签问题。通过建立含有关系信息的标签,使用序列标注模型直接抽取实体及其关系,而不单独识别实体和关系。
大多数现有的工作都需要高质量的标注数据。为了获得大规模的训练数据,Mintz等[7]提出了远程监督的方法,假设两个实体在给定的知识库中有关系,则包含这两个实体的所有句子都会提到这种关系。远程监督虽然能有效地实现数据的自动标注,但存在着标签噪声的问题。以三元组{Barack Obama,BornIn,United States}为例,由远程监督标注的数据“Barack Obamba is the 44th president of the United State”就是一个噪声数据,远程监督认为这个句子中Barack Obama与United States的关系是“BornIn”,即使这句话根本没有描述“BornIn”关系。
因此,以往的基于远程监督的数据集上的实体关系联合抽取的研究存在着标签噪声的问题。噪声语句产生错误的标签,会对联合抽取模型产生不良影响。Feng等[8]提出了一种基于噪声数据的句子级关系分类模型,其模型包括两个模块:句子选择器和关系分类器。句子选择器通过强化学习选择高质量的句子,将所选句子输入到关系分类器;关系分类器进行句子预测,并为句子选择器提供反馈。他们的模型能够有效地处理数据的噪声,在句子层次上获得更好的关系分类效果。
本文提出了一种由句子选择器和序列标注模型两个模块组成的序列标注模型。通过使用句子选择器,可以从一个句子包中选择高质量的句子,然后通过序列标注模型预测句子的标签。目前主要的挑战是当句子选择器不清楚哪些句子的标签错误时,如何有效地联合训练这两个模块。
本文将句子选择任务当作强化学习问题来解决[9]。直观地说,虽然模型没有对句子选择器进行显式监督,但是可以把所选语句作为一个整体进行评估,因此,句子选择过程具有以下两个性质:一是试错搜索,即句子选择器试图从每个实体的句子集合中选择一些句子,并获得对所选句子质量的反馈;二是只有当句子选择器完成了句子选择过程,才能获得从序列标注模块的反馈,这个反馈通常是延迟的。这两个特性让本文使用强化学习技术。
本文工作中的贡献包括:
1)提出了一种新的序列标注模型,该模型由句子选择器和序列标注模型组成。这个模型能够在相对没有噪声的数据中进行实体和关系的联合抽取。
2)将句子选择定义为一个强化学习问题,使得模型能够在没有明确的句子级标注情况下执行句子选择,通过序列标注模型较弱的监督信号提供反馈。
3)根据实体将数据分成不同的集合,句子选择器选择实体集合中的高质量句子,然后所有的集合中选择的数据作为干净的数据训练序列标注模型。
1 相关工作
实体识别和关系分类是构建知识库的重要步骤,对许多NLP任务都有帮助。两种主要框架被广泛应用于解决实体识别及其关系抽取的问题:一种是流水线方法,另一种是联合学习方法。
流水线方法将此任务视为两个独立的任务,即命名实体识别(Named Entity Recognition, NER)和关系分类(Relation Classification, RC)。经典的NER模型是线性统计模型,如隐马尔可夫模型(Hidden Markov Model, HMM)和条件随机场(Conditional Random Field, CRF)[10],其中CRF模型结合了最大熵模型和隐马尔可夫模型的优点[11]。向晓雯等[12]、佘俊等[13]、张金龙等[14]采用规则与統计相结合的方法研究命名实体识别任务,取得了较好的结果。近几年,Chiu等[15]、Huang等[16]、Lample等[17]几种神经网络结构已成功应用于NER,将命名实体识别任务处理成序列标注任务。现有的关系分类方法也可分为手工抽取特征的方法[3]和基于神经网络的方法。
联合模型使用单个模型抽取实体和关系,而大多数联合方法是基于特征的结构化系统,例如Ren等[18]、Singh等[19]、Miwa等[5]、Li等[4]提出的方法。最近,Miwa等[5]使用基于长短期记忆(Long Short-Term Memory, LSTM)网络的模型抽取实体和关系,这可以减少手工工作。Zheng等[6]提出了一个标签方案,可以将联合抽取任务转换为序列标注问题。基于这种标签方案,研究不同的端到端模型,可以直接抽取实体及其关系,而不单独识别实体和关系。本文所提出的方法是基于一种特殊的标签方式,因此可以很容易地使用端到端模型来抽取结果,而不需要运用NER和RC分别进行。
一般来说,训练神经网络模型需要大量的标签数据,人工标注数据是非常耗时的。为了解决这个问题,Mintz等[7]提出了远程监督方法,该方法假设所有关于三元组中的两个实体的句子都描述了三元组中的关系。尽管远程监督取得了成功,但这种方法存在着标签噪声问题。为了解决这一问题,Lin等[20]、Ji等[21]提出了多个句子级别的注意力机制,可以降低噪声句子的权重。然而,这种多句子学习模型并不能直接过滤掉噪声数据的影响。Feng等[8]提出了一个基于噪声数据的句子级关系分类模型,首先在强化学习框架下选择正确的句子[22],然后预测过滤后数据中每个句子的关系。本文提出的方法首先在强化学习的框架下选择正确的句子,然后从干净的数据中预测每个句子的标签序列。
2 方法介绍
本文提出一个句子选择器和序列标注的联合抽取模型,双向长短期记忆条件随机场(Bidirectional Long Short-Term Memory Conditional Random Field, Bi-LSTM-CRF)模型来联合抽取实体及其关系,句子选择器来选择高质量的句子。在本章中,首先介绍如何将抽取问题改为标签问题,然后介绍用于选择高质量句子的强化学习模型。
2.1 标签模型
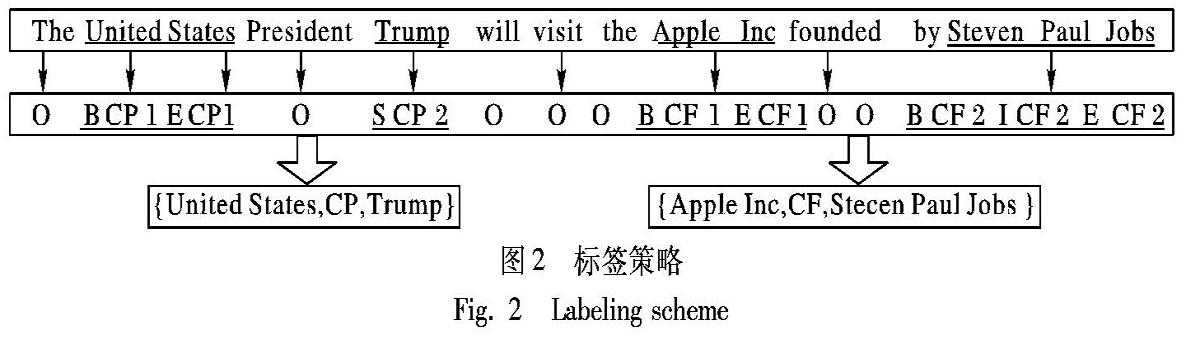
图2是对训练集标注的示例。句子中的每个词都被打上一个有助于提取结果的标签。标签“O”表示“其他”标签,这意味着相应的单词独立于提取的结果。除“O”外,其他标签还包括三个部分:实体中的单词位置、关系类型和关系角色。本文使用实体开始(Begin,B)、实体内部(Inner,I)、实体结尾(End,E)、单个实体(Single,S)等符号来表示实体中单词的位置信息。关系类型信息从一组预定义的关系中获取,关系角色信息由数字“1”和“2”表示。提取的结果由三元组表示:(Entity1;RelationType;Entity2)。“1”是指单词属于三元组中的第一个实体,“2”是指关系类型后面的第二个实体,因此,标签总数为N=2*4*r+1,其中r是预定义关系集的大小。
输入语句标签以及结果如图2所示。输入语句包含两个三元组:{United States,Country-President,Trump}和{Apple Inc,Company-Founder,Steven Paul Jobs},其中“Country-President”和“Company-Founder”是预定义的关系类型。单词“United”“States”“Trump”“Apple”“Inc”“Steven”“Paul”和“Jobs”都与最终提取的结果相关,因此,它们是根据本文的特殊标签进行标注的。例如,“United”这个词是实体“United States”的第一个词,与“Country-President”的关系有关,所以它的标签是“B-CP-1”。另一个与“United States”相对应的实体“Trump”被标签为“S-CP-2”。另外,其他与最终结果无关的词被标签为“O”。
2.2 从标签获取结果
从图2的标签序列中,可以知道“Trump”和“United States”共享相同的关系类型“Country-President”;“Apple Inc”和“Steven Paul Jobs”共享相同的关系类型“Company-Founder”。最后将具有相同关系类型的实体组合成一个三元组以得到最终结果,因此,“Trump”和“United States”可以合并成三元组,关系类型为“Country-President”。因为“Trump”的关系角色是“2”,“United States”是“1”,最终结果是{United States,Country-President,Trump}。同样可以得到三元组{Apple Inc,Company-Founder,Steven Paul Jobs}。
此外,如果一个句子包含两个或两个以上具有相同关系类型的三元组,模型会根据就近的原则将每两个实体组合成一个三元组。例如,如果图2中的关系类型“Country-President”是“Company-Founder”,那么在给定的句子中会有四个具有相同关系类型的实体。“United States”最接近实体“Trump”,“Apple Inc”最接近“Steven Paul Jobs”,因此结果将是{United States,Company-Founder,Trump}、{Apple Inc,Company-Founder,Steven Paul Jobs}。
2.3 词向量
词向量是神经网络的输入。对于词嵌入的方法,本文选择CBOW(Continuous Bag-Of-Words model)而不是Skip-Gram。本文的选择是基于这样一个考虑:CBOW是根据上下文预测一个词,或者通过查看上下文最大化目标词的概率进行预测,而Skip-Gram的输入是当前词的词向量,而输出是周围词的词向量。也就是说,通过当前词来预测周围词,即用于预测上下文。Skip-Gram需要更多的数据来训练,这样它就可以学会理解很多单词,甚至是罕见的单词。对于NER任务,是根据上下文预测词的标签,而不是预测上下文,因此,本文训练CBOW嵌入模型以获得双向长短期记忆(Bidirectional Long Short-Term Memory, Bi-LSTM)编码器的输入表示。
2.4 Bi-LSTM-CRF模型
2.4.1 CRF
条件随机场结合了最大熵模型和隐马尔可夫模型的特点,是一种无向图模型,近年来在分词、词性标注和命名实体识别等序列标注任务中取得了很好的效果。条件随机场是一个典型的判别式模型,其联合概率可以写成若干势函数联乘的形式,其中最常用的是线性链条件随机场。若让x=(x1,x2,…,xn)表示被观察的输入数据序列,y=(y1,y2,…,yn)表示一个状态序列,在给定一个输入序列的情况下,序列标注通常公式化为:
其中:tj(yi-1,yi,x,i)是一个转移函数,代表在标注序列中,第i-1个和第i个的标注与整个观测序列之间的特征关系;sk(yi,x,i)是一个状态函数,代表标注序列中第i个标注与此时相对应的观测序列中的值的特征;λj和μk的值均是从训练数据中进行估计,较大的负值代表其对应的特征模板可信度低,而较大的非负值代表其对应的特征事件可信度高,其中Z(x)代表归一化因子,其公式如下:
最终的最优化输出序列计算公式如下:
以往的研究表明,特征选择在传统的概念抽取中起着重要的作用。NER的性能在很大程度上取决于不同意见的领域知识的构建和研究。
2.4.2 LSTM与Bi-LSTM
循环神经网络(Recurrent Neural Network, RNN)模型是一种在序列标注任务上表现优异的神经网络模型,因为序列标注任务中,无论是序列内部还是序列的边界对上下文信息都是敏感的,而循环神经网络RNN与传统的神经网络相比,恰好有着时间序列这一特性,它更能充分地利用前面序列的信息,因此它更加适用于序列标注的任务。长短期记忆(Long Short Term Memory, LSTM)网络模型采用LSTM单元来替代原先循环神经网络RNN模型中的隐藏层,该模型能够有效处理较长距离的依赖关系以及解决梯度消失问题。
LSTM區别于RNN的地方,主要就在于它在算法中加入了一个判断信息有用与否的“处理器”,这个处理器作用的结构被称为细胞(cell)。一个cell当中被放置了三扇门,分别叫作输入门(i)、遗忘门(f)和输出门(o)。一个信息进入LSTM的网络当中,可以根据规则来判断是否有用。只有符合算法认证的信息才会留下,不符的信息则通过遗忘门被遗忘。一个细胞的结构如图3所示。
i、 f、o分别表示输入门、遗忘门和输出门。W和b表示权重矩阵和偏移向量。遗忘门是决定需要从细胞状态中丢弃什么信息,它会读取ht-1和xt,输出一个在0到1之间的数值。1表示“完全保留”,0表示“完全舍弃”。遗忘门的计算公式如下:
f=σ(Wf[ht-1,xt]+bf)(4)此处是否遗漏了公式,后面的参数说明中没有看到Ct、sig等函数。回复:没有遗漏公式,其中包括了对图三的说明,Ct,Sig符号可以在图三中看到
其中:ht-1表示的是上一个LSTM单元的输出,xt表示的是当前细胞的输入,Ct-1是前一个单元的记忆,ht是当前网络的输出,Ct是当前单元的记忆。Sig表示sigmoid函数,Mul表示向量乘法,Con表示向量加法,tanh为激活函数。
输入门决定让多少新的信息加入到cell状态中来。实现这个需要包括两个步骤:首先,一个叫作“输入门”的sigmoid层决定哪些信息需要更新;一个tanh层生成一个向量,也就是备选的用来更新的内容,Ct。在下一步,把这两部分联合起来,对cell的状态进行一个更新。
接下来是更新旧细胞状态,Ct-1更新为Ct。需要把旧状态与ft相乘,丢弃确定需要丢弃的信息。得到新的候选值后,根据决定更新每个状态的程度进行变化。公式如下:
输出门需要确定输出什么值。这个输出将会基于当前的细胞状态,也是一个过滤后的版本。首先,模型运行一个sigmoid层来确定细胞状态的哪个部分将输出;接着,模型把细胞状态通过tanh进行处理(得到一个在-1到1之间的值)并将它和sigmoid层的输出相乘,最终仅仅会输出确定输出的那部分。公式如下:
双向长短期记忆(Bi-LSTM)网络模型是由前向的LSTM与后向的LSTM结合而成,Bi-LSTM的计算流程与单向长短期记忆网络LSTM模型在本质上是一样的,也是利用LSTM的公式计算每个LSTM单元的细胞状态与隐藏层输出,不同的是,Bi-LSTM首先针对逆时序的隐藏层增加了和正时序的隐藏层处理相对应的权重参数矩阵与偏置向量,正时序和逆时序将通过各自的权重参数矩阵与偏置向量得到隐藏层的输出向量ht,再对这两个输出向量进行合并操作,对于不同的应用,它们的合并方式会略有差异,本文将采用连接的方式将两个输出向量进行合并。
2.4.3 Bi-LSTM-CRF
上面介绍了在序列标注问题上效果比较优异的传统统计模型的代表条件随机场(CRF)模型和被广泛应用于序列标注任务中的Bi-LSTM网络模型。其中,CRF模型的优点在于能够通过特征模板去扫描整个输入文本,从而对整个文本局部特征的线性加权组合有着更多的考量,最关键的是,序列标注中的X和Y代表的都是整个输入文本和标注序列,并非独立的词语或标注,所以CRF模型优化的目标是出现概率最高的一个序列,而不是找出序列的每个位置出现最高概率的标注;而它的缺点在于,首先特征模板的选取需要对训练语料有一定的先验知识,需要从语料中相关信息的统计数据中分析出对标注有着重要影响的特征,特征的数量多了会使模型出现过拟合的现象,特征数量少了则会使模型出现欠拟合的现象,特征之间如何组合是一项比较困难的工作;其次,条件随机场模型在训练过程中,由于受限于特征模板制定的窗口大小,所以难以考察长远的上下文信息。Bi-LSTM网络模型的优缺点在某种程度上与CRF模型恰恰相反,它在序列标注任务的表现上异常强大,可以有效地将长远的上下文信息利用进来,同时它还具备了神经网络本身的对于非线性数据的拟合能力,然而从图3.5中可以看出,然而从图3.5中可以将看到,这一句话需要去掉Bi-LSTM模型的输出层输出的标注yt由当前时刻的输入文本向量xt和将正时序LSTM单元与逆时序LSTM单元的记忆输出合并而成的隐藏层的输出ht决定,而与其他时刻k的输出层输出的标注yk没有关系,因此,Bi-LSTM模型的优化目标是对于每个时刻都寻找到在这个时刻出现概率最大的标注,再由这些标注构成序列,这往往会导致模型对标注序列的输出发生不连贯的现象。
这两种模型的优缺点恰好互补,于是将两者结合起来的模型Bi-LSTM-CRF出现了,即在传统的Bi-LSTM模型的隐藏层上在加入一层线性CRF层,如图4所示。
2.5 句子选择器
本文将句子选择作为一个强化学习问题来处理。句子选择器称为代理“Agent”,它与由数据和序列标注模型组成的环境“Environment”进行交互。“Agent”遵循一个策略来决定在每个状态“State”(包括當前句子、所选句子集)时执行什么操作“Action”(选择当前句子或不选择当前句子),然后在作出所有选择时从Bi-LSTM-CRF模型获得反馈“Reward”。
如前所述,只有在完成对所有训练语料的选择后,句子选择器模型才能从序列标注模型中获得延迟反馈,因此,对于整个训练数据的每次遍历,如果只更新一次策略函数,这显然是低效的。为了获得更多的反馈并提高训练过程的效率,本文将训练语料X={x1,x2,…,xn}分到N个集合B={B1,B2,…,BN}中,并且当完成一个集合的筛选后就计算一次反馈。集合根据实体进行划分,每个集合对应一个不同的实体,每个包bk是一个包含同一个实体的句子序列{xk1,xk2,…,xk|Bk|},但是实体的标签是有噪声的。本文将动作定义为根据策略函数选择句子或不选择句子。一旦在一个包上完成选择,就会计算反馈。当句子选择器的训练过程完成后,将每个包中的所有选定语句合并,得到一个干净的数据集X,然后,将干净的数据用于训练序列标注模型。
本文将介绍句子选择器(即状态、行动、反馈、优化)如下。
1)状态。
状态si表示当前句子和已选定的句子。本文将状态表示为连续实值向量F(si),它编码以下信息:a)从序列标注模型中获得的当前句子的向量表示;b)已选句子集的表示,它是所有已选句子的向量的平均值。
2)动作。
本文定义了一个动作ai∈{0,1}来表示句子选择器是否会选择包B的第i个句子,通过策略函数πΘ(si,ai)来决定ai的取值,将一个逻辑函数作为策略函数表示如下:
其中:F(si)表示状态向量,σ(·)表示sigmoid函数,参数Θ={W,b}。
3)反馈。
反馈函数代表所选句子质量的标志。对于一个集合B={x1,x2,…,x|B|},本文为每个句子选择一个动作,以确定是否应该选择当前句子。假设模型在完成所有选择后有一个最终反馈,因此,句子选择器模型只在最终状态S|B|+1收到延迟反馈。其他状态的反馈为零,因此,反馈的定義如下:
其中:B^为选择的句子集合,是集合B的子集;r是集合代表的实体;p(r|xj)是由序列标注模型计算出来的,对于特殊情况B^=,将反馈设置为训练集所有句子的平均值,这样可以过滤掉全是噪声的集合。
在选择过程中,不仅最终的行为有助于反馈,所有先前的行为都有助于反馈,因此,这种反馈是延迟的,并且可以通过强化学习技术很好地处理。
4)优化。
对于一个集合B,本模型希望得到最大的反馈,目标函数定义如下:
2.6 句子选择器+序列标注模型
如图5所示,左边为句子选择器,右边为序列标注模型,句子选择器由策略函数、反馈函数等组成,用来在训练集中挑选高质量的句子,作为序列标注模型的输入,序列标注模型接收句子选择器的输入,然后给句子选择器提供反馈,指导句子选择器选出高质量的句子。
3 实验介绍
3.1 数据集
为了评估本文方法的性能,本文使用由远程监督方法生成的公共数据集纽约时报(New York Times, NYT)[18],采用远程监督方式,无需人工标注,即可获得大量的训练数据。测试集是人工标注的以确保其质量。总的来说,训练数据包含353000个三元组,测试集包含3880个三元组。此外,关系集的大小为24。
3.2 评估策略
本文采用准确率(Precision, P)、召回率(Recall, R)和F1值对结果进行评估。与传统方法不同的是,本文方法可以在不知道实体类型信息的情况下抽取三元组。换句话说,本文没有使用实体类型的标签来训练模型,因此在评估中不需要考虑实体类型。当三元组的关系类型和两个对应实体的位置偏移都正确时,则认为它是正确的。本文从测试集随机抽取10%的数据来创建验证集,并根据Ren等[18]的建议将剩余数据用作评估。本文将每个实验运行10次,然后记录平均结果。
3.3 参数设置
本文的模型由一个Bi-LSTM-CRF序列标注模型和一个句子选择器模型组成。词向量是通过在NYT训练语料上运行Word2vec[23]生成的。词向量的维度为300。本文在嵌入层上使用droupout来防止过拟合,大小为0.5。LSTM隐藏层维度为300。对于句子选择器的参数,本文分别在预训练阶段和联合训练阶段将学习率设置为0.02和0.01。延迟系数τ为0.001。
3.4 基准线
将本文的方法与几种经典的三元组提取方法进行了比较,这些方法可分为以下几类:基于本文的标记方案的流水线方法、联合提取方法和Bi-LSTM-CRF方法。
对于流水线方法,本文遵循Ren等[18]的设置:通过CoType方法获得NER结果,然后使用几种经典的关系分类方法检测关系。这些方法包括:
1)2009年Mintz等[7]提出的DS-Logistic模型,这是一种远程监督和基于特征的方法;
2)2015年Tang等[24]提出的LINE(Large-scale Information Network Embedding)模型,这是一种网络嵌入方法,适用于任意类型的信息网络;
3)2015年Gormley等[25]提出的FCM(Fuzzy C-Mean)模型,这是一种复合方法,将词汇化语言语境和嵌入词结合起来进行关系提取的模式。
本文采用的联合提取方法如下:
4)2014年Li等[4]提出的DS-Joint模型,这是一种有监督的方法,它利用人工标注数据集上的结构化感知器联合提取实体和关系;
5)2011年Hoffmann等[26]提出的MULTIR(MULTi-Instance learning which handles overlapping Relations请补充MULTIR的英文全称)模型,这是一种典型的基于多句子学习算法的远程监控方法,用于对抗噪声训练数据;
6)2017年Ren等[18]提出的CoType模型,这是一个独立于领域的框架,将实体信息、关系信息、文本特征和类型标签共同嵌入到有意义的表示中。
此外,本文方法还与经典的端到端标注模型进行了比较:2016年Lample等[17]提出的LSTM-CRF模型,利用双向LSTM对输入句子进行编码,利用条件随机场预测实体标签序列,实现实体识别的LSTM-CRF算法。
3.5 实验结果
本文的实验分为三个部分进行,包括序列标注模型的训练、句子选择器模型的训练以及联合训练。其中前面两个模型的训练为预训练,目的是为了联合模型能够尽快地收敛。本文通过实验得到了不同方法的对比结果,其中LSTM-CRF模型与RL-LSTM-CRF(Reinforcement Learning for LSTM-CRF)本文方法的缩写是Bi-LSTM-CRF,不是RL-LSTM-CRF吧?这个名称也没有英文缩写,全文是否需要统一,请明确。回复:LSTM-CRF模型上文介绍了是利用双向LSTM编码的模型,也就是Bi-LSTM-CRF模型的缩写。RL-LSTM-CRF中RL指的是加入强化学习的模型,RL是Reinforcement Learning的缩写,LSTM-CRF同上。如果不明确的话,需要给RL-LSTM-CRF加上说明RL-LSTM-CRF(Reinforcement Learning for LSTM-CRF)。
模型不仅记录下了准确率、召回率、F1值,还将实验的标准差记录下来,标准差是将每个模型运行10次的结果,如表1所示。
可以看出,本文的方法RL-LSTM-CRF在F1分数上优于所有其他方法,与联合抽取CoType模型相比本文模型的F1值提升了1%,与串行抽取LINE模型相比本文模型的F1值提升了14%。实验结果证明了本文方法的有效性。此外,从表1中还可以看出,联合提取方法优于流水线方法,標注方法优于大多数联合提取方法。它还验证了本文的标签方案对于联合提取实体和关系的任务的有效性。与传统方法相比,端到端模型的精度有了显著提高,基于神经网络的方法能很好地拟合数据,因此,它们可以很好地学习训练集的共同特征。
4 结语
本文提出了一个新的模型,该模型由句子选择器和序列标注模型组成,通过强化学习框架在噪声数据集中联合抽取实体和关系。句子选择器为序列标注模型选择高质量的数据。Bi-LSTM-CRF模型预测句子级别的序列标签,并作为弱监督信号向选择器提供反馈,以监督句子选择过程。大量的实验表明,本文模型能够过滤掉有噪声的句子,并比现有的模型更好地执行联合实体和关系提取。
此外,本文的解决方案可以推广到使用噪声数据或远程监督的其他任务中,这将是未来的工作。后期打算用更优的端到端的模型来替换本文现有的序列标注模型,例如用LSTM解码层替换CRF解码层等。本文只考虑一个实体属于一个三元组的情况,并将重叠关系的识别留给以后的工作。
参考文献 (References)
[1] BANKO M, CAFARELLAM J, SODERLAND S, et al. Open information extraction from the Web[C]// Proceedings of the 20th International Joint Conference on Artificial Intelligence. New York: ACM, 2007: 2670-2676.
[2] NADEAU D, SEKINE S. A survey of named entity recognition and classification[J]. Lingvisticae Investigationes, 2005, 30(1): 3-26.
[3] RINK B, HARABAGIU A. UTD: classifying semantic relations by combining lexical and semantic resources[C]// Proceedings of the 5th International Workshop on Semantic Evaluation. New York: ACM, 2010: 256-259.
[4] LI Q, JI H. Incremental joint extraction of entity mentions and relations[C]// Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2014: 402-412.
[5] MIWA M, BANSAL M. End-to-end relation extraction using LSTMs on sequences and tree structures[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2016: 1105-1116.
[6] ZHENG S C, WANG F. Joint extraction of entities and relations based on a novel tagging scheme[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2017: 1227-1236.
[7] MINTZ M, BILLS S, SNOW R, et al. Distant supervision for relation extraction without labeled data[C]// Proceedings of the 2009/47th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2009: 1003-1011
[8] FENG J, HUANG M, ZHAO L, et al. Reinforcement learning for relation classification from noisy data[C]// Proceedings of the 2018/32nd Association for the Advancement of Artificial Intelligence Conference on Artificial Intelligence. Menlo Park, CA: AAAI, 2018:5779-5786
[9] SUTTON R S, BARTO A G. Reinforcement learning: an introduction[J]. IEEE Transactions on Neural Networks, 1998, 9(5): 1054-1054.
[10] LUO G, HUANG X J, LIN C Y, et al. Joint entity recognition and disambiguation[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 879-888.
[11] 馮元勇,孙乐,张大鲲,等.基于小规模尾字特征的中文命名实体识別研究[J].电子学报,2008,36(9):1833-1838.(FENG Y Y, SUN L, ZHANG D K, et al. Study on the Chinese named entity recognition using small scale tail hints[J]. Acta Electronica Sinaca, 2008, 36(9): 1833-1838.)
[12] 向晓雯,史晓东,曾华琳.一个统计与规则相结合的中文命名实体识别系统[J].计算机应用,2005,25(10):2404-2406.(XIANG X W, SHI X D, ZENG H L. Chinese named entity recognition system using statistics-based and rules-based method [J]. Journal of Computer Applications, 2005, 25(10): 2404-2406.)
[13] 佘俊,张学清.音乐命名实体识别方法[J].计算机应用,2010,20(11):2928-2931.(SHE J, ZHANG X Q. Musical named entity recognition method [J]. Journal of Computer Applications, 2010, 30(11): 2928-2931.)
[14] 张金龙,王石,钱存发.基于CRF和规则的中文医疗机构名称识[J].计算机应用与软件,2014,31(3):159-162.(ZHANG J L, WANG S, QIAN C F. CRF and rules-based recognition of medical institutions name in Chinese [J]. Computer Applications and Software, 2014, 31(3): 159-162.)
[15] CHIU J P C, NICHOLS E. Named entity recognition with bidirectional LSTM-CNNs[C]// Proceedings of the 2016 Transactions of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2016: 357-370
[16] HUANG Z, XU W, YU K. Bidirectional LSTM-CRF models for sequence tagging[EB/OL]. [2018-12-02]. https://arxiv.org/pdf/1508.01991.pdf.
[17] LAMPLE G, BALLESTEROS M, SUBRAMANIAN S, et al. Neural architectures for named entity recognition[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2016: 260-270.
[18] REN X, WU Z, HE W, et al. CoType: joint extraction of typed entities and relations with knowledge bases[C]// Proceedings of the 26th International Conference on World Wide Web. New York: ACM, 2017: 1015-1024.
[19] SINGH S, RIEDEL S, MARTIN B, et al. Joint inference of entities, relations, and coreference[C]// Proceedings of the 2013 Workshop on Automated Knowledge Base Construction. New York: ACM, 2013: 1-6.
[20] LIN Y, SHEN S, LIU Z, et al. Neural relation extraction with selective attention over instances[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2016: 2124-2133.
[21] JI G, LIU K, HE S, et al. Distant supervision for relation extraction with sentence-level attention and entity descriptions[C]// Proceedings of the Thirty-First Association for the Advancement of Artificial Intelligence Conference on Artificial Intelligence. Menlo Park, CA: AAAI, 2017: 3060-3066.
[22] NARASIMHAN K, YALA A, BARZILAY R. Improving information extraction by acquiring external evidence with reinforcement learning[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2016: 2355-2365.
[23] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[J]. Advances in Neural Information Processing Systems, 2013, 26: 3111-3119.
[24] TANG J, QU M, WANG M, et al. LINE: large-scale information network embedding[C]// Proceedings of the 24th International Conference on World Wide Web. New York: ACM, 2015: 1067-1077.
[25] GORMLEY M R, YU M, DREDZE M. Improved relation extraction with feature-rich compositional embedding models[C]// Proceedings of the 2015 Conference on Empirical Method in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 1774-1784.
[26] HOFFMANN R, ZHANG C, LING X, et al. Knowledge-based weak supervision for information extraction of overlapping relations[C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2011: 541-550.
