基于Python语言的中文分词技术的研究*
2019-09-04祝永志
祝永志,荆 静
(曲阜师范大学 信息科学与工程学院,山东 日照 276826)
0 引 言
Python是当今最热门的编程语言之一,仅次于Java语言、C语言。国内的知名互联网企业也有很多使用python语言搭建的,比如网易、豆瓣等。由于很多公司使用Python进行开发和其他工作,导致Python招聘相关工作岗位的范围很广,涉及到从后台维护到前端开发。Python适用于数据科学方面,比如数据采集、数据分析和数据可视化等,社会发展的需求也是Python热门的原因之一。
用高级语言编程可以大大提高生产力的想法并不新鲜,当今社会各个领域都离不开数据的支持,获取和充分利用数据是一个巨大的问题,而Python就是一门可以解决这种问题的高级编程语言。Python爬虫是众多数据来源渠道中重要的一条,运用它可以提供优质和价值丰富的数据集[1]。除了获取数据,Python在后续的数据处理等过程中也展现出了巨大的优势,它的应用范围十分广泛,几乎覆盖了整个程序设计的领域[2]。在本文中首先运用Python爬虫爬取新闻网页数据,为后续实验提供文本数据,然后对文本进行切分,对切分结果进行去除停用词处理后对分词进行了加权处理筛选出关键词,在加权时采用了TF-IDF算法和TextRank算法对分词的重要性进行计算,根据加权结果提取出关键词,最后运用WordCloud库采用词云的方式对关键词进行展现。数据的获取和分析处理过程都程序化,不仅可以节省时间,使得阅读过程更加方便快捷,而且可以迅速地从中文文本中提取到高价值的信息。
1 Python简介
1.1 Python
Python作为当今最热门的编程语言之一,它的应用场景很多,比如科学计算,软件的开发与维护等等,Python已经是当前热门领域中不可或缺的编程语言,比如云计算、网络爬虫、人工智能等等。在当今热门的语言中,Python的优势主要体现在以下两点:
(1)易于学习,开源,高级语言,可移植性,可解释性,面向对象,可扩展性,丰富的库和规范的代码。
(2)具有一个强大的标准库和许多功能丰富的第三方库,这些使得开发过程更简单,这些库可以应用于学计算、数据分析等多个领域[3],对这些库的熟练使用会使开发过程变得更简便和高效。标准库包含的功能有很多,比如文本处理和操作系统功能调用等。
1.2 jieba
结巴分词(Jieba)作为一个强大的分词库,它的开发者通过大量的训练后,向其录入了有两万多条词组成了基本的库,不仅如此,jieba的实现原理也比较完善,设计的算法有基于前缀词典的有向无环图、动态规划、HMM模型等[4]。jieba分词支持三种分词模式:
(1)精确模式,此模式试图以最高精度来对句子进行划分,适用于文本分析;
(2)全模式,此模式可以扫描出句中全部可成词的词语,并且速度很快,但它并不可以解决歧义问题;
(3)搜索引擎模式,此模式基于精确模式对长词在进行切分,可以将此模式用于搜索引擎分词[5]。
Jieba分词的jieba.cut()方法有三个参数:字符串,cut_all,HMM(Hidden Markov Model,隐马尔可夫模型)参数。其中字符串是待分词的实验文本,第二个参数cut_all=True时使用全模式,当指定cut_all=False时为精确模式。图1展示了不同模式的使用方法和分词结果。
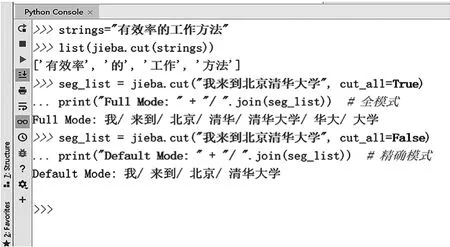
图1 jieba分词模式
2 Python爬虫
Python爬虫就是用Python编程实现的网络爬虫,Python拥有很多可用于爬虫的第三方包和框架,可以轻松地实现爬虫功能[6]。用Python来写爬虫程序不仅爬取速度快,处理各种爬虫问题也很方便。Python爬虫的用处有很多,比如各种数据聚合的网站像搜索引擎和信息对比的网站等都运用了爬虫技术。
2.1 Python爬虫库
Python有两个十分强大的第三方库常用于写爬虫程序,一个是requests,另一个是BeautifulSoup。Requests是一个简单易用的HTTP库,包含了大多数HTTP功能。BeautifulSoup是一个网页解析库,最主要的功能就是在网页上抓取数据,它能够很容易的提取出HTML或者XML标签中的内容。Python爬虫的架构主要是由URL管理器,网页下载器和网页解析器这三个部分组成。其中URL管理器负责管理将要抓取和已经抓取网页的url集合。网页下载器用于爬取相应的网页,并将抓得的数据以字符串的形式存储,然后传输给网页解析器。网页解析器用于解析出有用的数据存储下来,并且给URL管理器补充url。除此之外还有调度器主要负责调度各部分间协调工作。
2.2 Python爬虫流程
Python爬虫的流程主要分为四个步骤:发起请求,获取响应内容,解析内容和保存数据。
(1)发起请求
对目标发送一个Request,Request中主要包含有请求方式、请求URL和请求头三个部分,这个Request可以还包括headers等,然后等待响应。
(2)获取响应内容
若正常,会得到一个Response,Response中包含响应状态、响应头和响应体。其中最重要的就是响应体,它包含所请求资源的内容,这个内容可能是HTML,二进制等
(3)解析内容
对响应的内容进行解析,根据获取内容类型的不同采用不同的解析方式,解析方式有正则表达式、网页解析库、BeautifulSoup解析处理、转为Json对象等。
(4)保存数据
对解析过后的内容进行保存,保存形式有多种,可以根据需要保存为不同的格式。
3 中文文本分词
分词是指将完整的一句话根据其语义分拣成一个词语项集[7],该词语项集作为参与关联规则挖掘的基本单元[8]。中文分词是指以词作为基本单元,运用计算机自动地对中文文本进行词语的切分,即变成英文文本中用空格将句中的词分开的形式,这样方便计算机识别出各语句中的重点内容。
3.1 创建自定义词典
许多情况下,我们需要对特定的场景来进行分词,这时会有一些特定领域内的专用词汇,这些词汇往往是词库里没有的,解决这个问题的方法是创建自定义词典,自定义词典的有两个重要方法:载入词典,往词库里添加单词。
Jieba中载入词典:jieba.load_userdict(file_name),其中file_name是文件类对象或自定义词典的路径,载入词典的格式需与 dict.txt 相同,每词占一行;每行需要分成三个部分为:词语、词频、词性,词频和词性可省略不写,它们之间要使用空格来分开,并且其顺序不可改变。其中file_name 若采用路径或二进制来打开文件,则文件必须采用UTF-8编码。当词频被省略的时候,Jieba会采用自动计算的方式来确保词频被分出。
自定义词典的方式可以被用来添加jieba词库中不存在的词。虽然jieba具有对新的词汇进行辨别的能力,但单独添加这些词可以确保更高的正确率,还能够解决未登录词的问题,然而人们对分词技术和汉语结构的理解程度也会影响着自定义词典的准确度[9]。示例中在自定义词典中添加了‘探测器造访’和‘火星探测卫星’两个新词,从实验结果可以看出,两个词语在分词结果中被准确的切分出来,使得分词结果更加精确。添加新词示例:
test_sent='2020年我们将发射一个火星探测卫星'jieba.add_word('火星探测卫星')
在自定义词典中添加了“火星探测卫星”这个词,图2展示了是否添加分词后的不同运行结果。

图2 是否添词不同结果对比
从结果可以看出添加分词使得火星探测器被准确的切分出来,分词结果更加准确。
3.2 关键词提取
对中文文本关键词提取的方法是采用不同方法对文本分割后的分词进行计算权重,进行加权的方法有TF-IDF算法和TextRank算法。
3.2.1 TF-ID算法
TF-IDF(Term Frequency-inverse Document Frequency)是一种统计方法,其中TF(Term Frequency)的意思是词频,IDF(Inverse Document Frequency)的意思是逆文本频率指数,TF-IDF算法所求实际上就是这两者相乘所得的乘积。该算法的主要思想为:若某词在一类指定的文本中出现的频率很高,而这个词在其他类文本中出现的频率很低,那么认为该词具有此类文本某些代表性的特征,可用词对此类文本进行分类[10]。因此使用TF-IDF算法计算分词重要性可对某一文本提取关键词。
词频指的是一个词在指定的文件中出现的次数。在特定文件dj中词语ti的TF公式如下:

其中,ni,j表示词ti在文件dj中出现的次数,分母表示dj中包含的所有词出现的次数的总和。
逆向文件频率是用来衡量词普遍性的一个定义,对于某词t的IDF的计算公式如下:

其中,|D|是语料库中的文件总数,分母表示dj中包含有ti的文件的数目。TF-IDF的计算公式如下:

在指定的文本中出现次数多而在文件集合中其他文件中出现频率低的词计算出来的TF-IDF值更高,所以使用TF-IDF算法可以过滤掉一些常用词。
3.2.2 TextRank算法
TextRank算法是一种基于图的算法,它是一种排序算法,用于处理文本,可用于提取关键词[11]。
TextRank可由一个有向有权图G=(V,E)表示,图中任两点vi,vj之间的边的权重为Wji,对于给顶点vi,点vi的TextRank计算公式如下:
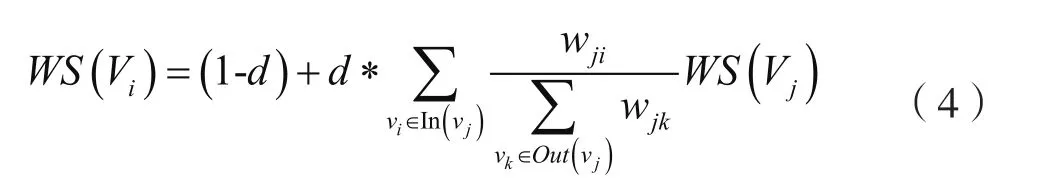
其中,In(vi)为指向该点的点集合,Out(vi)为该点所指向的集合,d为阻尼系数,取值在0到1之间,表示某点指向其他任意点的概率。
TextRank算法基于PageRank算法[12],步骤为:
(1)分割文本,过滤。
(2)采用分割单位建立图模型。
(3)根据式(4)在节点进行权重迭代,收敛时结束。
(4)根据权重的大小对节点进行排序,排序时采用的是倒序的方式,排序后根据重要性假设得到了T个候选关键词。
(5)在原始文本中对候选词检测它们之间是否相邻,相邻的时候将他们组合成多词关键词。
3.3 词云制作
词云是一种使用语言分析技术对文本进行分析统计后生成可视图像的技术[13]。词云图[14],也称为文字云,是用图像的方式对文本中频繁出现的词语进行展现,形成“关键词渲染”或者“关键词云层”的效果。词云图可以过滤掉大量的低频和低质量的文本,让浏览者只需匆匆一瞥就能够通过关键词来领会文本的核心内容。WordCloud库用于生成词云,是python的第三方库,这个库的功能十分强大,在统计分析方面有着很好地应用。
4 实验
4.1 软件环境
本文编程语言为Python,编程环境是pycharm,第三方包有wordcloud、jieba等,直接使用pip安装即可,安装命令为:pip install wordcloud,pip install jieba。
4.2 获取数据
本文采用介绍嫦娥四号相关资讯的新闻网页作为爬虫目标网页。这一事件标志着人类首次将探测器成功发射到月球背面,对月球背面进行了近距离的拍摄,并传回了世界第一张月球背面图像,这是一次伟大的创举。原网页如图3所示。

图3 新闻网页
编写程序对网页数据进行抓取,并将抓取到的数据保存到指定的文本文件中。第一步要导入的相关库:
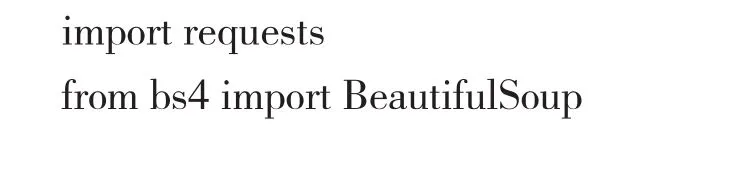
然后要获得网页的Html,这时要用到Requests库中的requests.get()方法,使用方式如下:

其中r.raise_for_status()在不成功的时候时抛出异常。然后要用BeautifulSoup库进行解析,首先分析一下网页的HTML结构,在Chrome中打开目标网页,右键查看源码可以看到如图4所示。

图4 网页源码
对网页源码进行分析,结合html相关知识,可以看出title为 因为select()方法返回的是一个列表,对于paras要采用循环的方式实现。最后将数据写入文件并且保存,这里将爬取到的文章以字典的格式来保存: 爬取的数据被保存到指定路径和文件名的文本文档中,图5是对爬取内容进行展示。 图5 爬取的数据 因为实验要用到panda里面的value_count()等方法,所以要导入panda和jieba等相关包,然后读取文本获取文本数据: 对文本进行分词,因为分词结果较长这里只打印一部分进行展示。而cut()方法返回的是可迭代的generator,若要打印指定某几行时需要写循环,这里运用列表的形式打印出前五个分词结果,简化了代码过程,关键代码为: 分词结果如图6所示。 图6 分词前五个结果 从分词结果中可以看出分词不仅分出了词语,还将标点也当做一个词切分出来,像标点这样的数据不仅无用,而且会占据存储空间,影响分词结果的准确度。所以要先对文本进行数据预处理,然后再进行后续实验。 在处理文本的前后,Jieba会自动地筛除掉有些字或词,筛除掉的字或词被称为Stop Words(停用词)。停用词大致被分类两类:一种是被普遍包含的功能词,比如“是”、“在”等等,这种词一般没有什么实际含义,基本上不会单独表达文本的重要内容,若要记录这些词会占据很大的磁盘空间;另一种包含词汇词,这种词的特征是被普遍应用,但是却不能保证准确的搜索结果,也不能够降低搜索范围,并且会影响搜索效率。从运行结果可以看到,在去除停用词后,一些无用的符号和词语被去除,使得分词结果更清晰准确。首先创建停用词词典: 打印前十个结果如图7所示。 图7 去除停用词前后对比 在去除停用词后对剩下的分词文本进行处理,首先运用统计词频的方法,观察一下运行结果,统计词频时采用的是value_count()方法,这个函数能够对Series里面的每个值进行计数并排序。函数为:word_fre = pd.Series(word).value_counts()排序后的实验结果前二十行如图8所示。 图8 统计词频结果 在统计词频后发现最后结果依然有噪声数据存在,比如“成于”这种词还没有被划分出去,因此基于词频的中文分词算法是不可靠的。 分别使用TF-IDF算法和TextRank算法对分词结果进行权重计算,其中TF-IDF算法得到的结果前二十个如图9所示。 图9 TF-IDF算法运行结果 对分词结果执行TextRank算法,计算分词的权重并进行排序,计算结果前二十个如图10所示。 图10 TextRank算法结果 对比三种算法的运行结果,TF-IDF算法和TextRank算法的运行结果中基本上没有常用词这种带有噪声的分词,这两种算法的运行结果的差异性也不大,与基于词频的算法相比较分词效果明显的增强。 最后采用TF-IDF算法对筛选的结果进行词云的绘制,根据计算的权重大小选取了前一百个结果进行绘图,实现可视化。 词云不仅用于展示标签,也多用于呈现文本的关键词语,以便帮助人们简明扼要地了解文本的大体内容。最后根据词的重要性来绘制词云,词云可以从不同维度展现数据:词汇本 身、频率(词汇大小)、以及词汇的颜色,使得分词结果简单清晰。 每个词云在wordcloud中被当作一个对象,生成一个美观的词云需要三步:配置对象参数,加载词云文本,输出词云文件。在Wordcloud中,w.generate(txt)用于向w中加载文本,w.tofile(filename)输出为图像格式保存。常用的参数列表如表1所示。 表1 wordcloud对象参数 最后采用云效果图进行展示,词云效果图的文字的不同大小以及颜色的不同展示了文本内容的关键程度。月球在词云图中占据了显眼的位置,其次就是嫦娥、梦想等,通过对词云图的简单浏览就可以大致了解文本的主要内容,词云图如图11所示。 图11 词云效果图 本文首先运用python的第三方库对新闻网页进行了爬虫操作,将爬取的数据保存为文本文档作为后续分词实验的数据,然后对文本进行分词处理,在分词的过程中先进行了数据预处理,采用自定义词典的方式对新词进行识别划分,然后又进行了去除停用词操作来提高分词结果的准确度,然后根据TF-IDF算法和TextRank算法计算分词的权重来提取关键词的结果较理想,成功筛选掉了噪声数据,最后根据TF-IDF的结果对关键词采用了词云的方式实现了数据的可视化。 本文通过实验对文本数据提取出了有价值的信息,并且用一种清晰的方式对重要内容进行了展示。但是本文爬虫只是抓取了单个网页,数据量比较小,后续可以将抓取数据量加大,实验结果可能会更加明显。


4.3 文本分词
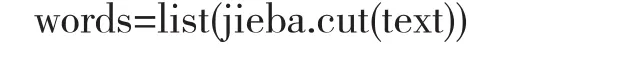
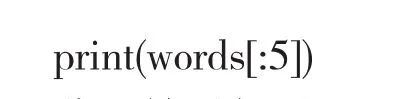




4.4 提取关键词


4.5 词云


5 结 语
