基于迁移学习的零件识别方法研究
2019-08-30陈志澜
陈 绪,陈志澜,2
(1.上海海洋大学 工程学院,上海 201306;2.上海建桥学院 机电学院,上海 201306)
0 引言
随着计算机技术的发展,计算机视觉作为人工智能的一个重要分支,已经被广泛应用于各行各业,其中基于视觉的零件识别方法已成为智能制造的研究热点之一,基于以上背景,本文深入研究了基于迁移学习的零部件识别方法,拓宽了迁移学习的应用领域。
在零件识别领域中,传统方法基本采用特征提取的方法来处理图像信息,即设计者针对要识别的工程零件问题进行人工特征提取(例如边缘特征、颜色特征等、圆特征、形状特征等)[1,2],但该方法常受到目标物体的形状、大小、角度变化、外部光照等因素的影响,因而所提取特征的泛化能力不强,鲁棒性能较差。
深度学习的概念由Hinton等人于2006年首先提出[3],直到Krizhevsky等人使用深度学习的方法[4]在2012年的 ImageNet比赛中取得突破性成绩后,深度学习呈现出了爆发式发展。近几年深度学习不但被广泛的应用于语音识别、图像识别、机器翻译等领域,而且在工程、医药、物流、检索等工程项目上成功应用。深度学习在其机理上是模仿生物神经元的运作机制,在其处理图像、文本等信息时,通过一层层的网络,将原始信息一层层的进行由简单到复杂,低阶到高阶的描述。相较传统的人工提取特征的方法,深度学习的优势在于特征提取环节不需要使用者预先选定提取何种特征,而是采用一种通用的学习过程使模型从大规模数据中学习进而学得目标具备的特征[5,6]。迁移学习是以深度卷积神经网络为基础,通过修改一个已经经过完整训练的深度卷积神经网络模型的最后几层连接层,再使用针对特定问题而建立的小数据集进行训练,以使其能够适用于一个新问题。
本文针对产品装配过程中经常使用的标准件,即螺母、螺栓、螺钉和垫片四种零件的识别。在建立螺母、螺栓、螺钉和垫片数据集基础上,分别构建迁移学习深度卷积神经网络识别模型和普通深度卷积神经网络识别模型,并使用螺母、螺栓、螺钉和垫片数据集对两种模型进行训练,最后将两种识别模型的训练过程和结果进行比较与分析。
1 零件识别模型的建立
1.1 零件识别模型整体框架
本文设计的螺母、螺栓、螺钉和垫片四种零件的识别模型整体框架如图1所示,四种零件通过图片预处理的方式在输入层进行图片预处理,经过预处理的四种零件图片数据集放入到深度卷积神经网经网络识别模型中。四种零件的图片经过深度卷积神经网络模型的每一层的网络时,先是通过低层特征的组合,经由简单的描述(边缘信息、颜色信息、亮度信息等)然后再将低层特征转为更加抽象的高层特征,直至复杂抽象的描述,最终完成特征值的提取。
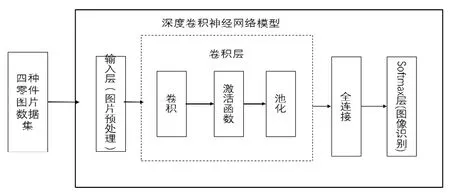
图1 零件识别模型整体框架
零件识别模型整体框架由输入层、卷积层、池化层、全连接层组成以及最后的Softmax层组成。在本文实验的两类识别模型中,进入输入层的螺母、螺栓、螺钉和垫片四种零件的图片大小经过预处理,转化为299×299×3的像素矩阵。卷积层是卷积神经网络中最为重要的部分,卷积层中每一个节点的输入只是上一层神经网络的一小块,称为卷积核。本文实验的两种识别模型,其卷积核的大小均为3×3、5×5和1×3,卷积层的目的是试图将上一层螺母、螺栓、螺钉和垫片四种零件图片的处理结果(原始图片或已经过特征提取)分为每一小块进行更加深入的分析而得到抽象程度更高的特征。本文实验的两种识别模型均采用3×3的最大池化层,其可以通俗理解为将高分辨率零件图片转化为低分辨率,且不丧失过多的特征信息。全连接层采用的是传统全连接神经网络,在整个卷积神经网络的最后一般都会有1到2个全连接层与Softmax层给出最后的分类结果,在本文实验的两种识别模型均为两层,最后以4096个神经元与Softmax层相连。Softmax层主要用于分类问题,通过Softmax层,可以得到当前测试零件图片属于不同种类的概率分布情况。假设Softmax层上一层输出为y1,y2,y3,…,yn,经过Softmax回归处理之后的输出为:
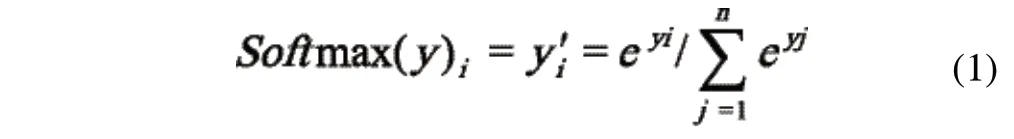
式(1)表示上层神经网络的输出被用作置信度来生成新的输出,新的输出满足概率分布的所有要求,因此成为一个概率分布,因此推导出一张零件图片为不同类别的概率分别有多大,从而完成最终的分类。
1.2 Inception V3迁移学习模型
作为迁移学习的代表Inception V3模型是GoogLeNet[7]模型的第三代改进模型,Inception V3模型的特点与传统的非GoogLeNet模型相比,它不是简单的采用卷积层的层层叠加方式,而是采用Inception模块进行层层叠加,如图2所示,Inception模块可以同时将螺母、螺栓、螺钉和垫片四种零件图片所提取的特征值进行边卷积和边池化,一个模块内可以进行多次的卷积和池化,可以说每一模块将卷积神经网络多个模块的特征结合起来,不仅使零件识别模型的精度大大提高,而且减少了大量的复杂计算工作量,从而提高运算效率[8]。
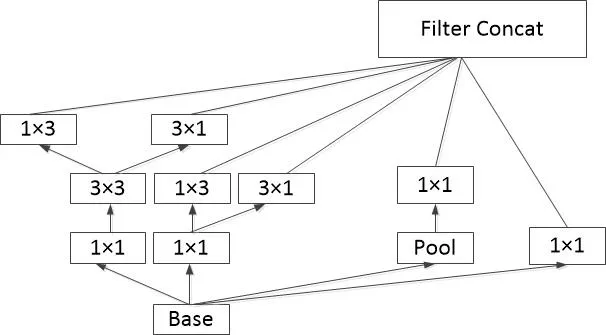
图2 Inception v3的Inception模块
与传统网络使用SGD(Stochastic Gradient Descent)反向传播算法不同的是Inception V3模型在训练过程中使用基于Adam(adaptive moment estimation)反向传播算法来基于训练数据迭代更新神经网络权重。此外,用于评判训练误差的损失函数使用的是交叉熵(cross entropy):
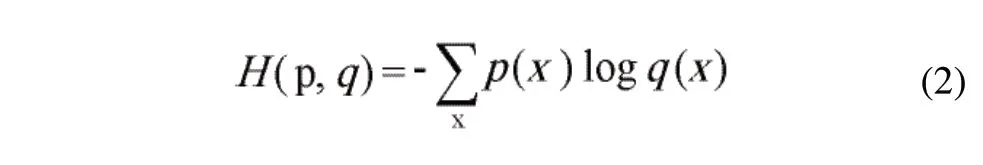
式(2)是通过概率分布q来表达概率分布p的困难程度,两个概率分布的距离,其值越小,两个概率分布越接近。当使用交叉熵作为神经网络的损失函数时,p代表的是正确答案,q代表的是预测值,这两个概率分布距离越短说明预测值越靠近正确答案。
迁移学习是将一个问题上训练好的模型通过简单的调整使其适用于一个新的问题,可以保留训练好的Inception V3模型中所有卷积层的参数,只需要建立一个或几个全连接层将最后的全连接层替换[9]。一个新的图片通过使用大数据集训练好的卷积神经网络直到瓶颈层(全连接层之前的网络层称之为瓶颈层(bottleneck))的过程可以看成是对图像进行特征提取的过程。由于在训练好的Inception V3模型上,瓶颈层的输出在通过全连接层神经网络可以很好的区分原先数据集上1000种类别的图像,所以有理由认为瓶颈层输出的节点向量可以被视为任何图像的一个更加精简且表达能力更强的特征向量[10]。所以在本文自建的数据集上可以直接利用这个训练好的神经网络模型对图像进行特征提取,然后再将提取到的特征向量作为输入来训练一个新的单层全连接神经网络处理四种零件的分类问题。一般来说迁移学习不如完全重新训练,但所需的时间和训练样本远小于训练完整的模型。所以考虑对本文的问题和现有条件,使用迁移学习解决四种零件分类问题将是一个很好的选择。
2 实验概述
2.1 实验模型内部处理次数
本文提出了一种基于深度卷积神经网络模型对零件进行分类的方法,采用的是一种由多层卷积层和全连接层以及一些用于优化网络的层或方法组成的卷积神经网络结构,使用迁移学习的方法训练模型,其主要次数 包括:
1)预训练好模型并用自建零件数据集进一步微调:使用的是在ImageNet数据集上预训练完成的网络模型,这里使用的是在以上数据集上得到训练的Inception V3模型,再使用自建的零件数据集进行微调。
2)建立零件图像的特征库:一般在卷积神经网络内部进行的,可以理解为每一步卷积乘之后所得到的权重与偏差都是特征提取的一部分,整个网络输出可以理解为正在建立零件图像的特征库。
3)输入所需查询的零件图像进行图像识别:每次输入图像进行识别时都是在使用此网络调用训练过程所保留的权重和偏差进行一次前向传播计算,以得到识别结果。
在相同迭代次数条件下,使用同样的螺母、螺栓、螺钉和垫片四种零件数据集进行训练,本文所使用的迁移学习深度卷积神经网络模型与普通深度卷积神经网络模型,对训练过程和训练结果进行对比。
2.2 实验条件及数据集建立
本文实验电脑配置为Intel Core i5 CPU,装载Windows10系统,通过Python调用由谷歌开发的一种完全开源的深度学习库Tensorflow进行训练,分别训练本文所构建的迁移学习深度卷积神经网络模型和普通深度卷积神经网络模型。最后使用Python编写螺母、螺栓、螺钉和垫片专用测试程序,对上述两类模型的训练结果进行实验测试。
本文以螺母、螺栓、螺钉和垫片四种零件作为识别对象和训练对象,实验数据集的自建原始图片通过手工拍摄或网上图片库搜集完成。四类零件的各种图片共计1474张,其中螺栓207张、螺母261张、螺钉507张、垫片499张,四类零件的部分自建数据集图片如图3所示。
3 实验结果及分析
3.1 两类模型训练过程对比与分析
训练过程中的数据集按所规定的比例,分别建成训练集(train set)和验证集(validation set)。两类模型在完成上述训练过程后,为定量确定两类模型的最终识别精度,本文还建立了螺母、螺栓、螺钉和垫片的测试集(test set)。

图3 自建数据集图片
训练集:以学习样本数据集作为训练模型。
验证集:每个迭代步数完成后用来测试当前模型的准确率。
测试集:测试训练好的模型分辨能力和精确度。
以四类零件总图片1474张的80%图片作为训练集的数据采集,验证集为四类零件总图片1474张的20%图片作为验证数据采集,测试集为四类零件总图片1474张以外的120张图片作为测试数据采集。图4、图5和图6分别为两类模型训练过程的训练精度对比、验证精度对比和损失函数值对比图,其中横坐标X轴为迭代步数,图4(a)、图4(b)、图5(a)、图5(b)的纵坐标Y轴为精度值(%),图6(a)、图6(b)的纵坐标Y轴为损失函数值。
图4(a)表示普通模型的训练精度,在迭代500次数时,其训练精度达到74%。迭代1800步时,训练精度已达到82%。当迭代次数继续增加时,训练精度与迭代次数的变化已呈现收敛趋势,其训练精度基本维持在90%左右,在迭代4000终止次数时,其训练精度仍保持在94%。图4(b)为迁移学习模型的训练精度,在迭代200次数时,其训练精度达到95%。迭代500步时,训练精度已达到96%。当迭代次数继续增加时,训练精度与迭代次数的变化同样出现收敛趋势,其训练精度基本维持在99%左右,在迭代4000终止次数时,其训练精度仍保持在99%。由图4(a)和图4(b)对比可知,其一,在达到同样训练精度时,迁移学习模型的迭代次数要比普通模型的迭代次数少得多,这表明迁移学习模型的训练效率较高。其二,普通模型在迭代1800次数时进入收敛趋势,训练精度为90%,迁移学习模型在迭代500次数时就进入收敛趋势,训练精度为96%。训练精度在同样收敛迭代次数时,迁移学习模型的训练精度值远比普通模型的训练精度高10%。
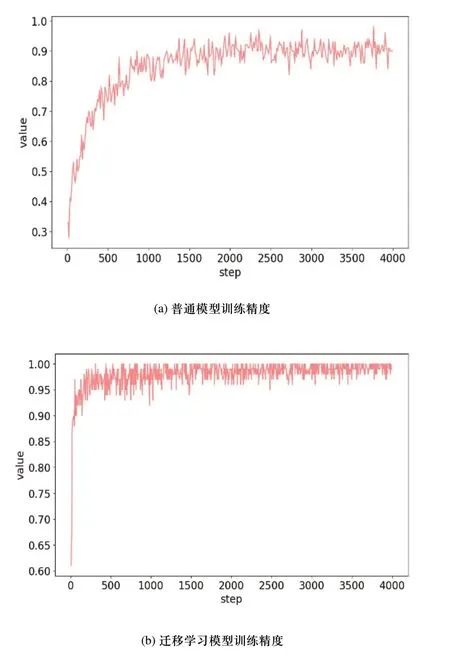
图4 两类模型的训练精度对比
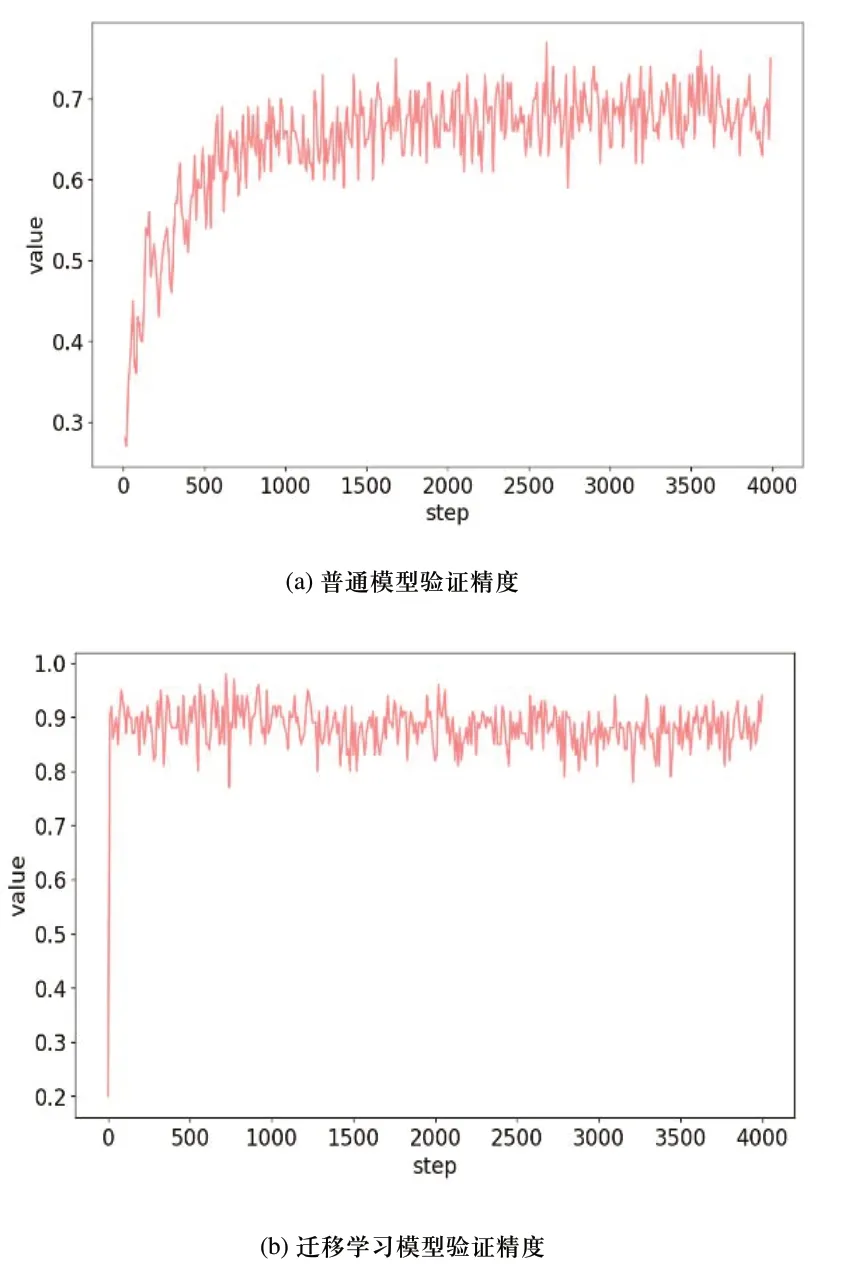
图5 两类模型的验证精度对比
图5(a)表示普通模型的验证精度,在迭代500次数时,其训练验证精度只有60%。迭代1800步时,训练验证精度已达到71%。当迭代次数继续增加时,训练验证精度与迭代次数的变化已呈现收敛趋势,其训练验证精度基本维持在70%左右,在迭代4000终止次数时,其验证精度仍保持在75%。图5(b)为迁移学习模型的训练精度,在迭代50次数时,其训练验证精度已达到90%。迭代500步时,训练验证精度达到92%。当迭代次数继续增加时,训练验证精度与迭代次数的变化同样出现收敛趋势,其训练验证精度基本维持在92%左右,在迭代4000终止次数时,其训练验证精度仍保持在94%。由图5(a)和图5(b)对比可知,其一在达到同样训练验证精度时,迁移学习模型的迭代次数要比普通模型的迭代次数少得多,这表明迁移学习模型的训练效率高于普通模型的训练。其二普通模型在迭代1800次数时进入收敛趋势,训练验证精度为71%,迁移学习模型在迭代500次数时就进入收敛趋势,训练验证精度为92%。表明迁移学习模型比普通模型更快进入收敛趋势。其三普通模型在迭代4000步验证精度为75%,迁移学习模型在第4000步验证精度为94%,这表明训练验证精度在同样收敛迭代次数后,迁移学习模型的训练验证精度值远比普通模型的训练验证精度高19%。
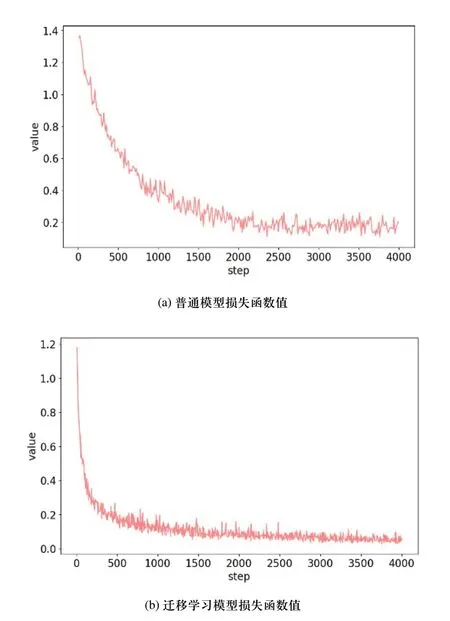
图6 两类模型的损失函数值对比
损失函数采用的是交叉熵函数方法所获得的,具体见式(2)所述。图6(a)表示普通模型的损失函数值,在迭代1000次时,其训练的损失函数值为0.33。迭代次数为2000步时,损失函数值为0.23。当迭代次数继续增加时,损失函数值与迭代次数的变化已呈现收敛趋势,其损失函数值基本维持在0.18左右,在迭代4000终止次数时,其损失函数值仍保持在0.2047。图5(b)为迁移学习模型的损失函数值,在迭代250次时,其损失函数值下降到0.27。迭代1000步时,损失函数值保持在0.14左右。当迭代次数继续增加时,损失函数值与迭代次数的变化同样出现收敛趋势,其损失函数值基本维持在0.05左右,在迭代4000终止次数时,其损失函数值仍保持在0.0475。由图5(a)和图5(b)对比可知,其一在达到同样损失函数值时,迁移学习模型的迭代次数要比普通模型的迭代次数少得多,这表明使用迁移学习模型具有较少迭代次数即可达到迅速收敛的效果,普通模型却需要花费较长时间的迭代次数才能达到收敛趋势。其二普通模型在迭代2000次数时进入收敛趋势,损失函数值为0.23。迁移学习模型在迭代1000次数时就进入收敛趋势,损失函数值保持在0.14左右。这表明损失函数值在同样收敛迭代次数时,迁移学习模型的损失函数值远比普通模型的损失函数值要低得多,即预测值也更加接近真实值。
3.2 识别精度与训练迭代次数关系
表1为迁移学习模型的训练精度和验证精度所构成的识别精度与迭代次数的关系,由表1所获取的数据来看,随着迭代次数增加,训练样本与测试样本的识别精度均呈现增加的趋势。但当训练的迭代次数达到500次左右,模型的识别精度已加入收敛阶段,此时训练精度已达到96%、验证精度也达到92%,其识别精度基本与迭代次数的增幅没有太大关系。由此可知,当迭代次数达到收敛阶段后,继续通过增加训练次数来提高识别精度是不现实的。另外,迁移学习模型在迭代500次收敛之后,其训练精度和验证精度依然分别在96%和92%有少许波动和微量幅度变化,由此推论该迁移学习模型在训练过程中并未出现过拟合现象。
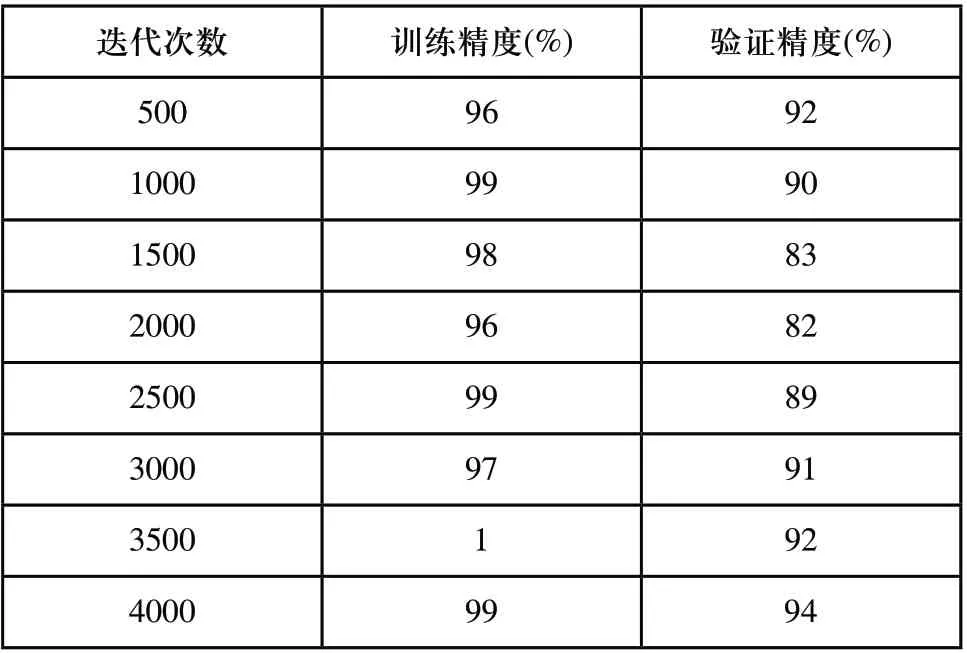
表1 识别精度与迭代次数关系
3.3 两种模型测试结果对比
本文建立了包含螺母、螺栓、螺钉和垫片图片每类30张共计120张所组成的测试集,分别对迁移学习模型和普通模型进行测试。
图7和图8分别是迁移学习模型测试结果和普通模型测试结果,图7和图8中的每张图片标号解释如下:图中第一行NO.为图片在测试集中第几张的编号,图中的第二行至第五行分别为螺母、螺栓、螺钉和垫片的拼音标注,score表示判断为螺母、螺栓、螺钉和垫片的具体概率值,第六行分别为螺母、螺栓、螺钉、垫片的最终判定结果。

图7 迁移学习模型测试结果

图8 普通模型测试结果
由图7和图8为两类模型的NO.3垫片测试结果,迁移学习模型判定垫片的概率非常大,其概率达到99.639%,普通模型判定垫片的概率仅为33.333%。NO.5为螺钉测试结果,迁移学习模型判定螺钉的概率为93.663%,普通模型判定螺钉的概率为99.062%。NO.9为螺母测试结果,迁移学习模型判定螺母的概率为99.992%,普通模型判定螺母的概率为0%。NO.12为螺栓测试结果,迁移学习模型判定螺栓的概率为68.205%,普通模型判定螺栓的概率为0.01%。两种模型对于螺钉的判定概率基本相同,其概率统计值接近100%。但对于螺栓和螺母,迁移学习模型的实际判定结果远远高于普通模型判定结果,迁移学习模型判定分别为68.205%和99.992%,普通模型几乎无法判定准确。
此外,为更深入研究模型识别错误的原因,本文还建立了迁移学习模型测试结果的混淆矩阵,如图9所示,垫片、螺钉、螺母和螺栓的recall值(召回率:TP/(TP+FN))分别为93.3%、96.7%、86.7%和83.3%。对于垫片和螺母而言,垫片仅有的两次错判被错判别为螺母,螺母有四次错判中有三次错判为垫片;对于螺钉和螺栓而言,螺钉仅有的一次错判被错判为螺栓,而螺栓的五次错判都是错判为螺钉;分析原因如下:从这四种零件形态上看,垫片与螺母具有很高的相似性,螺钉与螺栓也具有极高的相似性,因此模型判别错误原因有一定的程度的可解释性。
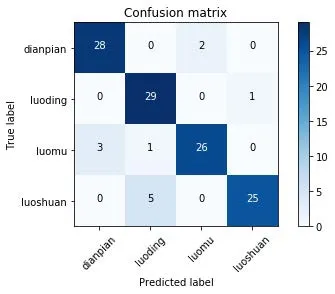
图9 迁移学习模型混淆矩阵

表2 迁移学习模型与普通模型对比表
3.4 两种模型的综合性能参数对比
表2构建了两类模型的迭代次数、训练精度、验证精度和训练时长等比较值,同时建立了包含螺母、螺栓、螺钉和垫片图片各类30张共计120张所构建的测试集,分别对迁移学习模型和普通模型进行测试,测试精度如表2最后一栏所示。
由表2可知,训练精度上大数据模型的迁移学习精度较高于小数据模型的完整训练;训练过程验证精度和测试过程测试精度上迁移学习远远高于普通模型;且由这两种模型的训练时间可知,迁移学习模型远远快于一个完整训练的普通模型。由此可见,使用迁移学习将会以较小的代价达到较高的目标。
4 结语
针对机械产品装配过程中,大量使用典型标准件螺母、螺栓、螺钉和垫片的识别问题,研究了迁移学习深度卷积神经网络模型和普通深度卷积神经网络模型的零部件识别方法。
1)通过实验对两类模型在训练精度、验证精度和损失函数值三个方面与迭代次数的比较,验证了采用较小样本量,使用迁移学习模型在训练时间上所花费的时间仅为普通模型的八分之一。
2)与普通模型相比,迁移学习模型在训练精度、验证精度和损失函数值均使用较少的迭代次数即可进入收敛阶段,但当迭代次数达到收敛阶段时,再提高模型的识别精度较为困难。
3)迁移学习模型在整体方面的识别精度值远远高于普通模型的识别精度值,并能有效防止过拟合现象。
