基于Python对豆瓣电影数据爬虫的设计与实现
2019-08-23裴丽丽
文/裴丽丽
1 概述
根据《中国互联网络发展状况统计报告》,到2018年12月为止,全年新增网民5653万,网民规模达8.29亿,普及率为59.6%,与2017年底相比提升3.8%。互联网的普及使得网上的信息资源呈现爆炸式增长,大数据时代的到来,对如何在短时间内从网页中找到用户需要的信息提出了挑战,无论是搜索引擎还是个人或者组织,要获取目标数据,都要从公开网站爬取数据,在这样的需求之下,网络爬虫技术应运而生。
网络爬虫,又被称为网页蜘蛛或者网络机器人,是指按照某种规则从网络上自动爬取用户所需内容的脚本程序。通常情况下,每个网页包含其他网页的入口,网络爬虫可以通过一个网址,链接进入其他网址获取内容,最后返还给广大用户所需要的信息数据。目前最适合用来网络爬虫的编程语言是Python,Python语言整合了针对网络爬虫所需要的一系列库,能够高效率得完成爬取目标数据。
2 网络爬虫的实现
本文以豆瓣网电影模块为例,实现了Python网络爬虫的全过程,并将爬虫结果保存在本地。主要分四个步骤实现,寻找爬虫入口,使用re和requests库获得所有电影信息的
url链接、使用BeautifulSoup库解析电影数据、将爬取到的信息保存到本地。
2.1 编程环境
Window10操作系统、python3.7、Pycharm集成开发环境、谷歌浏览器
2.2 寻找爬虫入口
豆瓣电影网站与有些网站不同,无法直接在当前页面的网页源码中找到我们所需要抓取电影的具体信息,因此需要寻找爬虫入口。通过谷歌浏览器:更多工具->开发者工具->Network->XHR发现可抓取链接到每部电影的网页https://movie.douban.com/j/search_subjects?type=movie&tag=最新& sort = rec ommend & page _limit=20&page_start=0,其中,tag为查询电影的类型,共有17种类型,本文以热门电影为例进行爬虫的设计与实现;sort为排序方式;page_limit为每页显示的电影个数,page_start为查询电影起始位置。抓取信息时,只需改变tag及page_start(20的倍数),就可以获取更多的url链接。具体如图1所示。
2.3 使用re和requests库获取所有电影信息的url链接
通过import requests测试程序是否报错,确定安装好requests库后,通过requests 库提取网页源码,requests 库比urllib库提取网页源码更简洁,方便开发者使用,只需要几步就可以实现。获得网页源码后,继续通过re库提取url链接,图2中,url链接是"url":"https://movie.douban.com/subject/27060077/"这样的形式,该形式不是一个标准的url链接,需要进行相应的处理,假设当前需要提取100部电影的信息,具体代码和注释如下:
#导入所需库
import requests
import re
#page控制抓取电影的数量
page=0
while page<=80:
url="https://movie.douban.com/j/search_subjects?type=movie&tag=热 门&sort=recommend&""page_limit=20&page_start="+str(page)
#通过requests库的get()方法获取源码
r = requests.get(url)
html = r.text
#通过re库提取当前页面的url链接
ree = re.compile('"url":"(.*?)"',re.S)
items = re.findall(ree,html)
for item in items:
#对url形式进行处理
url = item.replace("\","")
print(url)
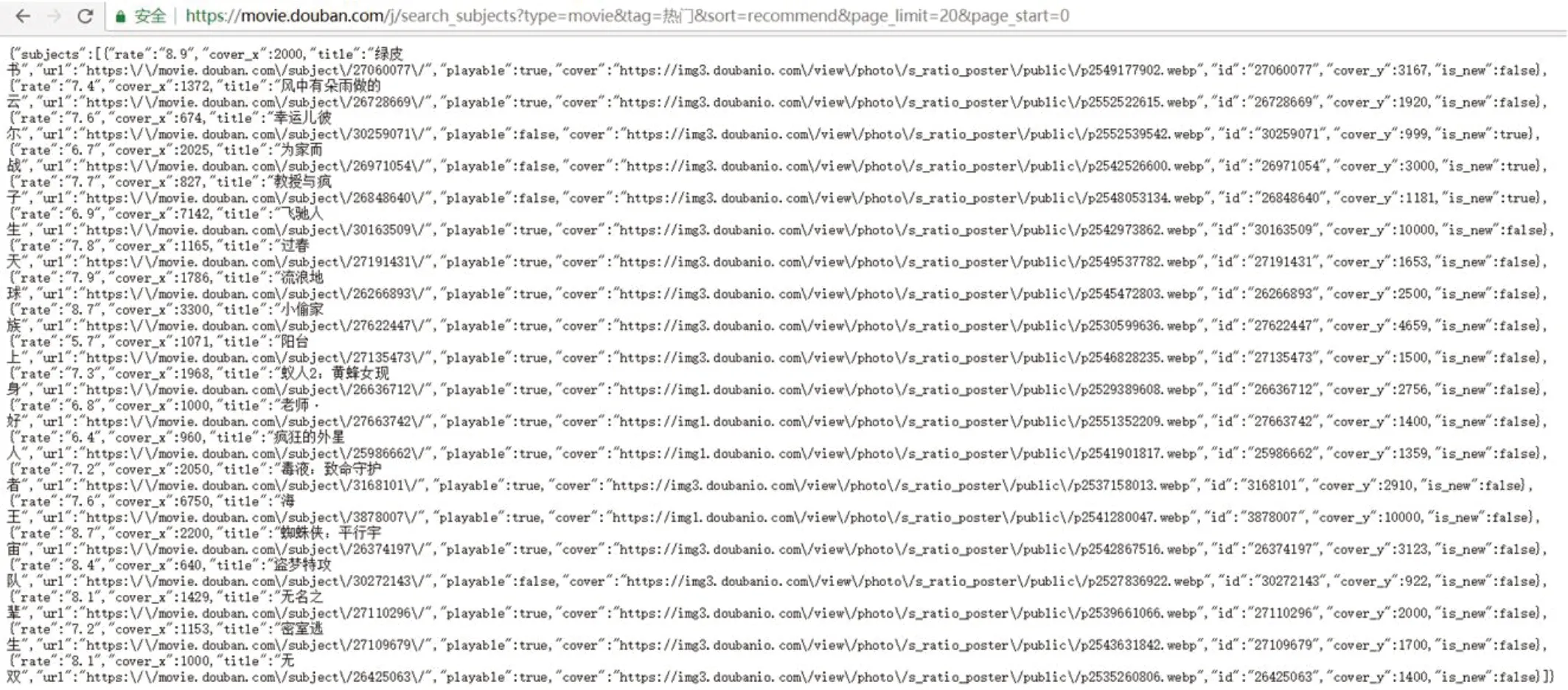
图1:url链接入口

图2:获取url链接

图3:部分网页源码
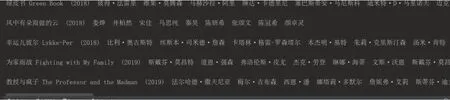
图4:提取电影信息

图5:存储的csv文件
page+=20
2.4 使用BeautifulSoup库解析电影数据
通过from bs4 import BeautifulSoup测试程序是否报错,确定安装好BeautifulSoup库后,通过该库解析电影数据,提取电影的具体信息,进入一部电影,部分网页源代码如图3所示。
如图4,提取该电影的名称,上映年份,导演,主演,豆瓣评分,短评等信息,部分提取代码如下:


2.5 保存到本地
如图5,从网页中爬取到数据后,需要保存到本地,既可以保存在文件中,也可以保存在数据库中,本文将结果保存为csv文件。部分代码如下:
with open("E:\a.csv","a")as f:
#中间代码为2.4中解析出的电影信息
f.write(movie)
f.close()
3 结语
本文基于Python提供丰富的库,实现了豆瓣电影种热门类型电影的爬取,可以根据提出的爬虫方法对豆瓣官网的图书和音乐等其他模块进行爬取,以此来研究用户的喜好。当今处于大数据时代,用户对各类数据的需求越来越大,爬虫作为数据收集的一种手段,具有广阔的应用前景。
