基于动态网格密度的SNN聚类的ET-GM-PHD滤波算法*
2019-08-22王杰贵朱克凡
彭 聪,王杰贵,朱克凡
(国防科技大学电子对抗学院, 合肥 230037)
0 引言
在经典的多目标跟踪算法中,由于雷达等传感器分辨率较低,通常目标视为点目标进行跟踪,此时只考虑跟踪目标的运动信息,而未包含目标的外形信息。近年来,随着传感器技术的提升,运动目标在一个采样周期里不再只返回一个量测值,这种在同一时刻能够得到至少一个量测值的目标称为扩展目标。扩展目标可以由运动状态(位置、速度和加速度等)和扩展形态(大小、形状和朝向)共同表征,扩展目标跟踪就是基于传感器得到的信息,利用相应的信号处理方法,对扩展目标的运动状态和扩展形态进行精确估计的过程。
传统的多目标跟踪算法如联合概率数据关联算法、多假设跟踪算法等都依赖于数据关联,这类算法会带来“组合爆炸”问题[1],复杂的多维计算会增加算法的运行时间,影响跟踪性能。基于随机有限集的多目标跟踪算法规避了数据关联,有效的解决了“组合爆炸”问题。随机集理论是Matheron于上世纪七十年代提出的,主要应用于几何方面,在上述基础上, Mahler提出了有限集统计特性理论,它是随机集的一种特例,将随机变量的统计理论延伸到了随机集合(random finite set, RFS),并率先将RFS理论应用于多目标跟踪领域。RFS框架下的多目标跟踪利用Bayes法则传递目标的概率密度,但是算法中的积分为集值积分,很难求解。做为一种近似的滤波方法,概率假设密度(probability hypothesized density, PHD)滤波器被提出来,它传递的目标概率密度的一阶统计近似矩。2009年,Mahler将PHD滤波技术应用于扩展目标领域,并给出了扩展目标PHD(extended target PHD, ET-PHD)滤波器的更新方程[2]。2010年,Granstrom等学者给出了ET-PHD的高斯混合实现形式,即ET-GM-PHD滤波[3]。
扩展目标跟踪面临的首要问题就是量测集的划分,文献[4]中提出了一种基于距离的划分方法,该方法对空间上距离较远且量测比较密集的情况跟踪效果较好;文献[5]提出k-means划分方法,其划分准确度好于距离划分,但是本质上,以上两种划分方法都是基于距离划分的,在量测密度差距较大的环境下,两者划分效果不理想。针对此问题,文献[6]提出了一种基于SNN相似度的量测划分方法,该方法对量测密度不敏感,但存在计算量偏大的不足。
本文在文献[6]的基础上,提出了基于动态网格密度的SNN相似度划分算法,该算法首先通过动态网格计算量测集的密度分布情况,利用双阈值对量测集进行杂波滤除;然后根据SNN相似度对处理后的观测数据进行划分,以达到节省计算时间,提高跟踪稳定性的目的。
1 ET-GM-PHD滤波技术
1.1 ET-PHD滤波技术
ET-PHD滤波算法的预测步和标准的PHD滤波算法预测步一致,其更新方程是预测强度vk|k-1(x)和一个量测伪似然函数LZ(x)的乘积形式,下面给出ET-PHD滤波算法的具体形式[7]。
1)预测部分
设k-1时刻的后验强度为vk-1,则ET-PHD预测强度为:
βk|k-1(xk|xk-1)]vk-1(xk-1)dxk-1
(1)
式中:γk(xk)表示k时刻新生目标的RFS的强度函数;pS,k(xk-1)为目标在k时刻存活的概率;fk|k-1(xk|xk-1)为k时刻单目标的转移概率密度;βk|k-1(xk|xk-1)表示衍生目标的强度。
2)更新部分
假设k时刻的预测强度vk|k-1(x)和量测集Zk,且量测个数服从Poisson分布,ET-PHD更新方程为:
vk(x)=LZ(x)vk|k-1(x)
(2)
LZ(x)是量测的伪似然函数:
LZ(x)=1-(1-e-γ(x))pD(x)+
(3)
式中:γ(·)表示扩展目标所产生的量测值的均值;pD(·)为目标被检测概率;p∠Zk表示p为量测集合Zk的一个划分子集;ωp为划分p的权值;|W|为子集W内元素的个数;dW为观测子集W的非负系数;φz(x)为扩展目标量测的似然函数;λk为单位空间内的杂波个数;ck(zk)为杂波的分布函[8]。
1.2 ET-GM-PHD滤波技术
由于ET-GM-PHD滤波算法和标准的GM-PHD滤波算法的预测步和更新步一致,因此文中只给出标准GM-PHD滤波算法的预测和更新方程。
GM-PHD滤波器满足以下假设条件:
1)每个目标的运动模型和量测模型均为高斯线性的,即:
fk|k-1(x|xk-1)=N(x;Fk-1xk-1,Qk-1)
(4)
gk(z|x)=N(z;Hkxk,Rk)
(5)
2)目标的生存概率和检测概率与目标状态相互独立,即:
pS,k(x)=pS,k
(6)
pD,k(x)=pD,k
(7)
(3)新生目标的RFS强度为高斯混合形式,即:
(8)
基于以上假设,GM-PHD滤波器的预测步可表示为:
(9)

更新步可表示为:
(10)

1.3 扩展目标量测划分问题
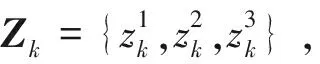
从上述例子可见,量测值的增加将使得量测集的划分数迅速增加,影响跟踪的实时性,因此寻找准确快速的量测划分方法是ET-GM-PHD滤波中的重要一步。针对这个问题,提出了基于动态网格密度的SNN相似度的量测划分算法。
2 基于动态网格密度的SNN相似度量测划分方法
在SNN算法的基础上,利用动态网格技术对量测数据进行预处理,从而达到减小算法运行时间,提高跟踪精度的效果。
2.1 基于动态网格密度的量测集预处理
定义1:网格单元:数据空间中的每一维均匀的分成若干等分,从而将数据空间划分成若干个互不相交的超矩形单元,这样的单元称为网格单元。采用动态网格划分,根据每一时刻数据点的数量来决定网格的划分数[9]:
K=(Nz,k(1-γ))1/d
(11)
式中:Nz,k表示k时刻量测集的个数z,γ表示数据压缩率,d表示数据的维数。
定义2:网格单元的中心与重心。设一个网格中有m个数据点b1,b2,…,bm,该单元的中心点Uc是一个d维的向量(uc1,uc2,…,ucd),uci=(li+hi)/2,li和hi分别表示网格单元第i维的最小值和最大值;重心点Ub是一个d维的向量(ub1,ub2,…,ubd),ubi=(b1i+b2i+…+bmi)/m。
定义3:网格单元密度。网格单元中数据点的个数用den(C)表示。
2.1.1 改进的密度阈值的选取
密度阈值的选取是区分量测和杂波的关键,在利用式(11)对数据空间进行动态网格划分后,选择合适的密度阈值,对量测划分结果的影响很大。传统的方法中主要利用单密度阈值来判断高低密度网格,该方法具有明显的不足:密度阈值选取偏大时,会将量测和杂波一同滤除;密度阈值选取偏小时,则会认定杂波为量测。鉴于此,文中借鉴平均密度的思想,采用双密度阈值对量测和杂波进行区分,在原有密度阈值的基础上,添加一个核心密度阈值[10]。
假设G为生成的网格数量,den(Ci)为网格单元密度,max(den(Ci))表示密度最大的网格单元,min(den(Ci))表示密度最小的网格单元,有如下定义,密度阈值ε:
(12)
核心密度阈值ε′:
(13)
定义den(Ci)≥ε′的网格为核心网格,den(Ci)≥ε的网格为高密度网格,den(Ci)≤ε的网格为低密度网格,核心网格也是高密度网格。在滤除杂波的过程中,将含有核心网格的高密度网格区域认定为量测,不包含核心网格的高密度网格区域和低密度网格区域认定为杂波[11]。
2.1.2 移动网格边界优化技术
为了使量测值和杂波划分结果更准确,需要对边界信息进行处理。问题描述如图1(a),单元中C点和B点同属于量测值,但由于密度阈值的设置,处于低密度网格中的C点将被当作杂波被滤除。为了避免这种情况发生,文中采用移动网格边界优化技术[12],对低密度网格以及不含核心密度的高密度区域中的数据点进行处理。扫描需要处理的网格中的数据点,以网格重心为中心,依据式(11)划分的网格边长建立新的网格,若新建网格的密度den(Cj)≥ε′,则保留网格中的数据点,将其归为量测值。如图1(b)中所示,以C点为中心建立新的网格,此时den(Cj)≥ε′,故将C认定为量测,避免了上述问题中将边界量测点C归为杂波的情况。为了保证算法的运行效率,移动网格边界优化步骤只执行一次。

图1 移动网格边界优化
2.1.3 杂波滤除预处理
基于动态网格密度量测集预处理的步骤如下:
步骤2:将全部数据映射到已划分的网格单元中,计算网格的密度;
步骤3:根据式(12)、式(13)得到的密度阈值和核心密度阈值对网格进行杂波滤除;
步骤4:利用移动网格边界优化技术,对边界值进行提取,保留符合要求的边界值。
为验证动态网格杂波剔除效果,进行了杂波滤除仿真实验,图2是在γ=0.5的情况下得到的杂波剔除仿真图。图2(a)是量测图,有3个高密度区域为量测点集合;图2(b)是经过双密度阈值滤波后得到的效果图,从图中可以看到,由于右下角量测集网格密度小于核心密度,被视为杂波剔除了;图2(c)是经过移动网格边界优化技术处理后的仿真图,原来被视为杂波处理的量测集经过移动网格边界优化后,重新被认定为量测值。经过动态网格滤波后,杂波占比由原来的37.7%降低至8.1%,杂波剔除效果比较明显。

图2 动态网格杂波剔除
2.2 基于SNN相似度的量测划分算法
2.2.1 SNN相似度
针对不同扩展目标产生量测密度差异较大的情况,引入共享最近邻(SNN)相似度的概念,以SNN相似度为划分指标,对扩展目标量测集进行量测划分。
各诗家的诗选本无疑都蕴含着自己的诗学理想和个人偏向,沈德潜选诗自然也不例外。沈德潜作诗主张“格调说”,“格调说”由明前后七子提倡,在当时及清初都备受批判,沈德潜重新关注并发扬光大,成为了影响世人创作的重要思想主张。“格调说”提倡“格高调响”,在创作上提倡发扬诗教传统,对“温柔敦厚”“教化人伦”“合乎风雅”之诗格外看重。《别裁》作为沈德潜的代表作,必然浸润着“格调说”的种种主张。在初刊本的序中,沈德潜提到了诗选本的重要性:
简而言之,当两个量测点共同包含一定数目的最近邻点时,则认定这两个量测点相似。
SNN相似度划分算法中需要对K值进行设定,K值的设定范围是依据实验结果统计得到的,文中采用文献[4]的统计结果,如表1所示:

表1 参数K的设定范围
SNN相似度的具体计算步骤如下:
初始化k;
令Xun=X;
计算数据集X的距离矩阵;
IfXun≠∅,则
{任意选择一个x∈Xun;
计算x的k-邻域Vk(x)={x1,x2,…,xk},
其中x1,x2,…,xk是x的k-邻域中的数据点
Fori=1,i≤k
{ifx∈Vk(xi) 则
SNN(x,xi)=Vk(x)∩Vk(xi);
else SNN(x,xi)=∅;}
Xun=Xun-Vk(x);}
End If
2.2.2 基于SNN相似度的划分算法具体实现步骤
SNN相似度代表了两量测点的k-邻域之间共同量测点的个数,基于SNN相似度的量测集划分方法将SNN相似度大于一定相似度阈值sl的量测归于同一簇中,实现步骤如下:
步骤1:量测集经过预处理后,统计量测集内每两个量测点之间的欧式距离;
步骤2:根据步骤1得到的统计结果,找到每个量测值的K个最近邻点,计算每两个量测点之间的SNN相似度;
步骤3:根据SNN相似度,建立n维的SNN相似度矩阵N,n为量测点的个数,如图3所示。

图3 构建SNN相似度矩阵
步骤4:选择相似度阈值sl,sl从0到K-1内选取,选取不同的阈值sl得到不同的划分结果,共K种划分结果。文中未讨论如何选取sl得到正确的划分结果,根据实验仿真划分统计结果,选取K/2作为相似度阈值sl。
步骤5:保留≥sl的SNN相似度,用1表示,其余的用0表示,形成矩阵Sth,对于图2(b),选取sl=2,可表示为图4,将矩阵Sth中同一个的1连通域对应的量测置于同一个簇,连通域的个数即为簇的个数。

图4 SNN相似度矩阵Sth
图5分别是采用k-means算法和基于SNN相似度划分算法的结果。从图5(a)中可以看到,k-means算法将目标1划分成了两个簇,并且和目标2混淆了;图5(b)是基于SNN相似度划分的划分结果,与正确的划分结果一致,参数K=6,sl=3。

图5 k-means划分和SNN相似度划分效果图
3 仿真实验与分析
文中采用ET-GM-PHD滤波器,对量测密度相差较大的几个扩展目标进行跟踪,对提出的基于动态网格密度的SNN相似度划分算法和传统的k-means划分算法进行跟踪性能的比较。
3.1 仿真场景设置

(14)
扩展目标的量测方程可表示为:
(15)
式中:量测噪声vk是均值为0,协方差Rk=(20 m/s)2I2的高斯白噪声,且目标产生的量测互不相关。
3.2 仿真结果分析
为了验证文中提出的算法的特性,本次实验进行100次蒙特卡洛仿真,和传统的基于k-means划分的多扩展目标PHD滤波进行对比,PHD滤波器采用高斯混合的实现形式。仿真结果如下。

图6 目标和杂波态势图
图6显示的是目标和杂波的态势图,目标产生量测个数和杂波个数均服从泊松分布,仿真场景中共4个目标,目标1,2的量测密度服从λ=10的泊松分布,目标3,4的量测密度服从λ=30的泊松分布,目标初始状态和始末时间如表2所示,杂波个数服从λ=10的泊松分布。
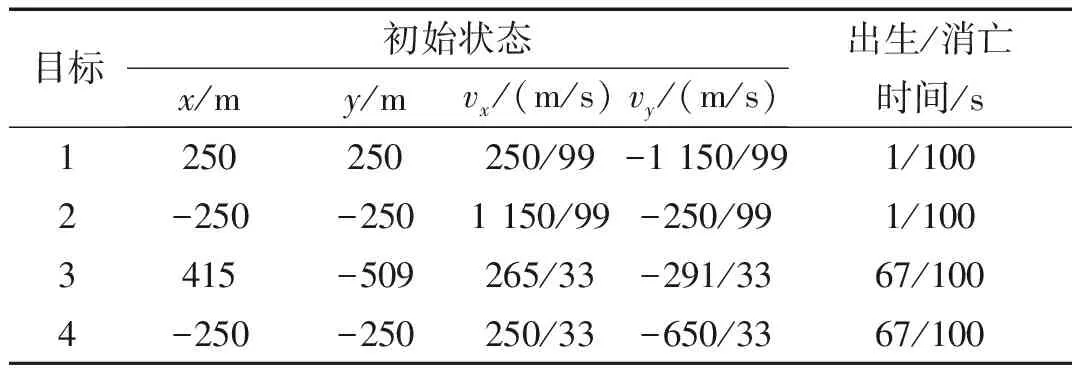
表2 目标初始状态和始末时间
图7给出了两种算法的平均运行时间,从图中可以看出,相较于传统的基于k-means划分的PHD算法,文中提出的算法在运行时间上减少了30%~40%,这是因为在量测划分阶段前进行了动态密度网格滤波,将大量的杂波剔除,减少了计算机对杂波的无效计算时间。

图7 算法平均运行时间
图8是两种算法对目标数估计的仿真图。如图中所示,两种算法在目标交叉,产生新生目标和衍生目标时都会发生目标个数的错误估计,但是文中算法发生误判的时间较短,这是因为基于SNN相似度的划分算法不再以距离为聚类标准,对于本实验中密度相差较大的量测集的划分效果要比k-means算法好,只有在目标极为接近时,才会导致本算法错误划分量测集。

图8 目标估计个数比较
图9给出了两种算法的OSPA距离图,OSPA距离[15]是随机有限集框架下的多目标跟踪算法的性能评价指标,公式定义如下:
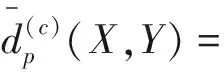
(16)
c为势误差与状态误差调节因子,p决定了对异常值的敏感性。本实验中c=10,p=2。如图9(b)所示,本算法的OSPA距离仅在56 s,67 s,77 s时刻左右出现了较大波动,波动时间较短,而传统算法的OSPA距离波动次数较多,持续时间较长,这说明文中所提出的算法在对多扩展目标进行跟踪时,有较好的稳定性。图中出现较大波动均是在目标数目估计出现误差的情况下发生的,因此OSPA曲线也可以反应目标数目的变化。

图9 两种算法OSPA比较
综上所述,文中提出的算法在对量测密度差异较大的扩展目标跟踪时,所用时间节省了30%~40%,跟踪稳定性也好于传统算法。
4 结束语
针对扩展目标产生量测密度差异较大的情况,文中提出了一种基于动态网格密度的SNN相似度的划分算法,对比于传统的划分算法,文中算法在降低计算时间的同时,保证了跟踪过程的稳定性和精确性,为扩展目标PHD滤波算法提供了一种新的划分方法。下一步将对算法中参数sl的选择问题进行研究。
