基于遗传算法的配送中心选址
——以广州KT物流科技有限公司为例
2019-08-21林松辉
刘 辉,林松辉
物流配送中心作为线上销售、线下销售的主要节点和供应链的重要纽带,扮演着集中分配的角色,它介于上游制造商和下游零售商之间负责进行专业的仓储、拣货、运输等作业,并具有整合商流、物流、现金流、信息流等的功能,在物流配送系统中具有重要的地位。物流配送中心不仅可以提高供应链运营的效率,降低运营成本,还能够实现供应链的整体优化,间接提高企业竞争力。因此,研究物流配送中心的选址是重要而必要的。
一、配送中及其心选址
(一)配送中心的内涵
1.概念
配送中心是指从事以配送服务为主的现代化设施,是以组织配送式销售和供应、执行实物配送为主要功能的流通型物流结点。它能够很好地解决用户多样化需求和厂商大批量专业化生产的矛盾,因此逐渐成为现代化物流的标志。
2.与物流中心的区别
配送中心是储存众多物品且将储存周期较短的众多物品配送给众多零售店(如专卖店、连锁店、超市等)或最终客户的场所;而物流中心则是储存众多物品、且将储存周期稍长的众多物品送达下一层经销商或配送中心的场所。
(二)配送中心的分类
1.根据功能不同的分类
(1)流通加工型配送中心——配送中心对物品的流通和加工职能较为重视。为了匹配客户的要求,占有市场的主动权,配送中心主要进行流通以及再加工活动以满足客户的需求。
(2)配送型配送中心——配送中心对物品的配送职能较为重视。作为面向零售商和消费者的物流节点,配送中心不仅有集货、仓储、分拣、加工、运输等职能,更强调以快速为主要目标所进行的短距离、小范围的快速配送。
(3)仓储型配送中心——配送中心对物品的仓储能力较为重视。在提高土地利用率以及降低仓储成本的条件下,一般会采用此类配送中心。
(4)枢纽型配送中心——配送中心强调物品的集运及转运功能。因其特殊的功能多会把配送中心设在海关或机场附近。
2.根据投资主体不同的分类
(1)合作型配送中心——由多家企业合资建设的配送中心。合作型配送中心可以分摊建设费用,且可共用于同一区域进行配送服务。
(2)自用型配送中心——通常是供应链相关方为了提高物资的周转效率、降低配送成本、提高服务质量所自行建立的配送中心。
(3)公共型配送中心——投资主体多为政府或第三方物流企业。其特点是具有高度专业的配送能力,且对于客户的要求有强大的调整能力。
3.根据运营主体不同的分类
(1)制造商型配送中心——投资主体、运营主体及服务对象都是制造商本身。通过建立独特的物流中心,可以满足企业自身产品的配送要求,提高客户的服务水平,降低配送成本,提高企业的竞争力。
(2)批发商型配送中心——投资及运营主体是批发商或代理商。在商品的流通过程中,起桥梁及纽带作用,将生产商的产品聚集到配送中心,再分配到下游零售商或用户的手中,具有较高的社会合作性。
(3)零售商型配送中心——投资及运营主体是零售商。一般而言是多家大中型企业共同出资建立的配送中心,通过批量采购及批量运输取得规模效益,使整体的平均成本降低,提高自身的利润[1}。
(三)配送中心的选址
1.选址的内涵
在一定的经济区域内,用科学合理的方法对配送中心进行地理位置的选址,最佳的选址位置可以使配送中心发挥最大的效益。如:缩短配送时间、降低配送费用、满足配送需求、降低企业的运营成本、改善供应链,对企业的发展具有高度的战略意义。
2.选址的原则
(1)经济性原则——配送中心选址的最后确定要以低成本、高效率、高收益为目标,避免因建设配送中心而过度地占用企业经济资源。
(2)适应性原则——配送中心的选址要具有适应性,既要适应企业发展的战略目标,也要适应企业的运作需求,而且还需要适应客户的要求。
(3)弹性原则——配送中心的选址需要有一定的弹性,能够满足社会的变化,具有前瞻性、发展性。
3.选址的规划
根据配送中心选址的规划,可分为单中心选址和多中心选址,是根据配送中心的数量不同而进行分类的。如图1所示。
4.选址的影响因素
(1)自然环境——指地形、地貌、天气条件等自然因素。首先,配送中心需要尽可能缩短与供应商、或者客户的配送距离与配送时间,因此不宜建在地形迂回曲折的地方。其次,是否靠近河海的地貌也需考虑,这意味着运输方式的不唯一性。最后,该地的温度、湿度等也是对仓储造成重大影响的因素[2]。
(2)经济环境——多指当地的基建程度以及人才资源状况。在基建程度低的地方,配送中心会得不到各方面技术上的支持,如信息通讯、人才数量等。从而失去其存在的价值,甚至会导致亏损情况出现。
(3)政策环境——指政府的支持和优惠政策等,公司会因为政府政策带来的积极影响得到巨大的发展空间;然而,政府政策的不允许,也很容易形成各种障碍壁垒,从而限制企业的发展。
(4)企业战略选择——配送中心的类型是根据公司的战略选择而确定的。以配送为主的配送中心,往往会建在与多数客户较为接近的地方;而以仓储为主的配送中心,则更多地会考虑建设成本以及配送中心的空间利用率。
(5)城市路况——城市路况往往能够影响配送的及时性,成为影响运输时效的主要因素之一。例如广州的路况相对而言就远不及惠州:在广州城区只能行驶5公里路程,在惠州城区可能可以行驶8公里甚至8公里以上。
5.选址的实施步骤
(1)约束条件分析:首先明确建立配送中心的目的、意义、重要性,再分析好各种约束条件,如政府是否允许在此地建立配送中心、顾客的分布情况、配送中心的物流职能等。
(2)收集整理材料:选址是为了追求运输费、配送费、物流设施设备费用的最低化,因此搜集数据时,一般要掌握客户业务量、各项费用(运输费、配送费、土地费、人工费、业务费)和其他(包括配备车辆数、作业人员数、装卸方式、装卸机械费用)各类信息。
(3)地址筛选:在整理分析材料之后,应该考虑各种因素的影响并且对需求进行预测,初步确定选址范围。
(4)定量分析:根据不同情况采用不同模型进行运算。
(5)结果评价:综合各种因素,包括市场适应性、购置土地条件、服务质量等,对初步选址结果进行评价。
(6)复查:根据不同因素的不同影响程度,运用加权法进行运算,根据是否满足选址的约束条件将结果进行确认,若不满足,则返回第(3)步地址筛选继续运算。
(7)确定选址结果:通过一系列调查分析以及运算之后,确定选址结果。
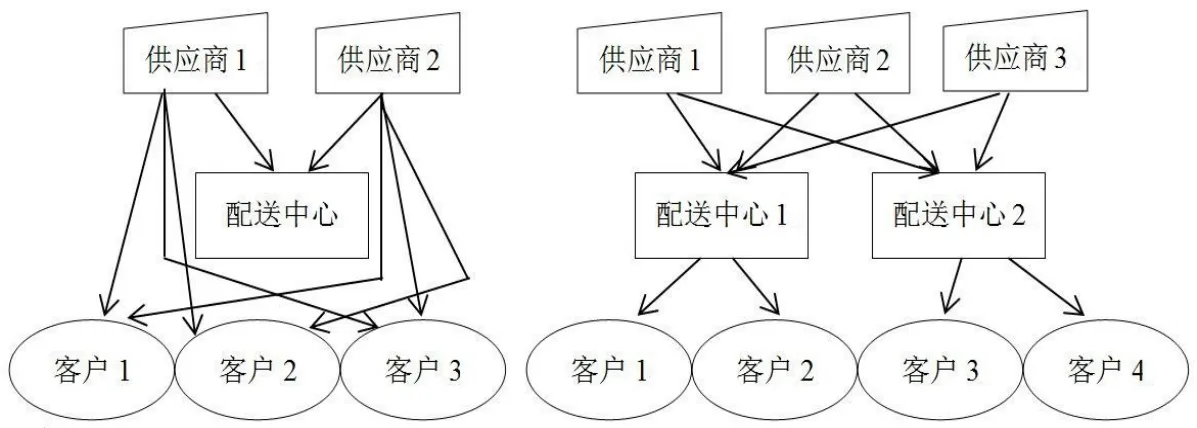
图1单中心选址和多中心选址示意图
二、配送中心选址的研究方法
(一)传统型算法
基于物流配送中心选址在降低物流成本、提高物流效率等方面的巨大作用,众多学者对混合整数规划、层次分析法、重心法等传统型选址算法进行了大量的研究。
胡敏通过双重中心法对配送中心的选址进行研究,确认了其有效性[3]。王富忠、庞海云通过遵循知识准则的求解算法,较好地实现了仓库选址最优及配送成本最优的双优目的[4]。杨彪等以供应链成本最低为目标运用混合整数规划的方法快速地解决了选址的问题[5]。张延亮、康国栋利用迭代重心法和蒙特卡罗随机模拟的方法对单一地方和两个地方的选址问题求得最佳选址方案[6]。徐其强基于层次分析法证明了对物流中心选址的可行性[7]。吴婷等认为在只考虑运输成本的单一因素时,CFLP模型对市场选址具有一定的优势[8]。宋正娜等验证了在多因素影响下P—中值模型对医院设施进行分布选址有一定的指导性[9]。董伟通过网络覆盖模型对航空飞行服务站分布进行研究,得出了较好的分析结果[10]。
(二)创新型算法
近几年,一些学者验证了遗传算法、粒子群算法、蝙蝠算法、布谷鸟算法等创新型算法在物流配送中心选址问题上的有效性和可行性。
杨立通过和谐搜索算法和遗传算法结合的混合算法得出选址的最优解[11]。欧阳浩等用遗传算法获得针对运营成本问题的近似最优的选址方案[12]。冯席席证实了粒子群算法和粒子群算法模型对选址进行求解的可行性[13]。黄鑫磊通过仿真验证蝙蝠算法其良好的全局优化性,还用连续型单配送中心、离散型多配送中心验证了蝙蝠算法求解选址问题的可行性[14]。赵世安、屈迟文采用改进的布谷鸟算法求解物流配送中心的选址问题,并且验证了有效性[15]。李小川在烟花算法中引入人群搜索算法中的利己行为、利他行为和预动行为,对物流配送中心选址出现的早熟收敛、搜索精度低、鲁棒性差等缺陷进行了完善,并且改进了此算法对于求解物流配送中心选址问题的有效性[16]。高雯倩对引力搜索算法进行了改进,并且提出了引力系数的动态调整策略以及基于粒子聚集程度的变异策略[17]。
(三)遗传算法与配送中心选址
如前所述,很多学者采用遗传算法去计算配送中心的选址,通过研究不同的影响因素、不同的选址范围计算遗传算法跟配送中心选址的匹配度,并且得知主要影响因素除距离、单位运费等之外,还包括天气状况、道路状况以及“种群”范围的选择等。
1.基本概念
遗传算法简称GA(Genetic Algorithm),其基于自然界中的适者生存规则,通过将算法拟化成自然界中种群的进化,将算法与种群进化中的染色体互换、基因突变等结合在一起,通过决定种群生存进化的“适应值”去筛选出最优解。
此算法跟重心法、层次分析法等截然不同,它通过与自然的结合,不需要多梯度的新信息;只是通过人工进化的方法,在多个解中根据适应值去逼近最优解,类似于堆积木的一个过程。
遗传算法将选址问题转化成为多目标排序的问题[18],并且提出了多个生物进化的名词,如种群、染色体、基因突变、适者生存等,同时用“遗传”的方式,并且通过反复的运算对比,找出最“适合生存”的解。遗传算法是与自然结合的创新型算法。
2.具体步骤
(1)编码:以二进制的方式按照一定规则对备选配送中心进行编码,编码成若干个独立的个体。
(2)组成种群:即所有被以一定规则编码的独立个体被汇聚在一起,组成一个类似于种群的一个集合,称之为初始种群。
(3)反解编码:根据设定的编码规则,通过反解编码的方式,将编码里面所包含的信息反解出来,类似于生物学中的染色体从表现型转换为基因型再转换成为表现型的一种转换流程。
(4)计算函数值:即将变量作为计算的数据,解出函数值。函数值又称为适应值,适应值是决定种群生存或者淘汰的一个验证值。
(5)选择交换染色体的个体:以适应值作为参考,选择出若干个交换染色体的个体,并依据选址需求,有目的地进行染色体互换,或者进行随机交换。
(6)基因突变:是将某一互换完染色体的独立个体,进行某一处的数据改变,以模仿自然界中的突变,并进行适应值的计算。
(7)适应值的重复运算:包括染色体交叉互换,基因突变等重复操作,直至满足目标函数的最优解出现或者运算终止,则标志为运算结束[19]。
3.遗传算法详解
(1)制定编码
制定编码的方法包括二进制编码、浮点数编码、格雷码编码等。由于二进制编码更近似于染色体,更符合生物进化的规律,因此选取二进制编码。
二进制编码是根据一定规律,将选址信息编码成由若干个三位二进制组成的“染色体”,所有的“染色体”又组成了“种群”,种群又可以称为解的集合。具体的表现如生物学中染色体的表现型向基因型的转变。
(2)目标函数的制定
目标函数用于计算染色体的适应度,选择遗传个体的交叉与变异,决定整体收敛性,对于整体的优化选择起着极其重要的作用。
由于是二进制编码,并且为了稳定收敛性,因此一般会选择线性函数作为目标函数。需要注意的是,目标函数的选择不当会出现局部最优解的情况,导致可能会出现整体最优解无法得到的情况。如:

(3)选择、交叉与变异算子
遗传算法的选择方式主要包括轮盘赌选择、随机选择。轮盘赌选择是通过概率高低,选择两条染色体作为父代跟母代进行交叉互换与变异,用于生成新一代的染色体,选择概率的高低取决于适应度的高低,适应度越高被选择的概率越高。如图2所示:染色体总适应值为8+6+4+2=20;则选中染色体A至D的概率分别为40%、30%、20%、10%。
而随机选择是通过轮盘赌的方式得出一对染色体进行比较,采取淘汰低适应度的方法,留下高适应度再进行随机抽取一对进行染色体交叉互换生成子代交叉即为染色体交叉互换。互换方式包括单点交叉、两点交叉及多点交叉,顾名思义,交叉的“碱基位”可以由一个到多个不等。如图3所示。
变异包括基因位变异与均匀变异。基因位变异是指以一定的概率,随机地选择一个或多个基因位进行突变;均匀突变则是通过某一小概率,去替换均匀分布的随机数,比较适用于算法前期。此步骤是通过选择父代和母代染色体,进行交叉互换及变异,生成多个子代,尽可能地提高适应值,得出最优解。
(4)适应度的再计算
通过生成的子代,进行适应值的计算,如此重复步骤,直至得出最优解或者当运算的代数到达上限时。
遗传算法的具体流程如图5所示。
4.遗传算法的优点
(1)可解性不可比拟
相较于复杂算法,遗传算法可以避免出现函数无解的情况。适应值作为遗传算法的主要支点,它并不需要函数的太多支持。面对函数时,可通过交叉互换或基因突变来改变无解的情况。因此,遗传算法对于函数的低依赖性是重心法、层次分析法等传统的选址计算方法所不能比拟的。
(2)特别强的鲁棒性
当求解的过程中可能出现多个异常结果的情况下,遗传算法有很高概率能得到最优可行解或者近似最优解。

图2轮盘赌算法概率图
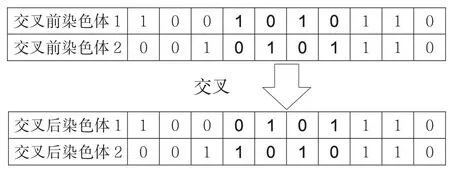
图3染色体交叉
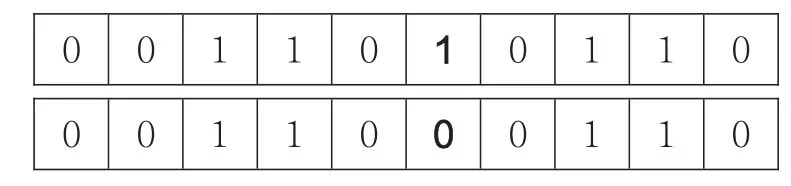
图4染色体变异

图5遗传算法流程图
(3)具有整体优化能力
遗传算法对于解的搜索是以一组包含多个初始解的集合展开的;在求解的后半段,生成的解不是唯一的单个解,而是多个最优解。因为可以让需求者拥有更多的选择,具备强大的整体优化能力。
(4)强大的可改动性
可改动性是指对原需求进行改变,如对目标函数的改进。许多算法在这样的情况下容易失灵进而无法继续求解,但是遗传算法可利用Matlab强大的计算能力,在程序上稍作修改便可继续求解。
(5)特别高的并行性
并行性不会直接在解集上反映,而是在对于求解编码的问题上,它会在多个信息空间区域内同时进行搜索,从而尽可能减少出现局部最优解的几率。
5.遗传算法的不足
(1)对遗传算法的研究有待提高
遗传算法是一种模拟生物进化的算法,在运用于选址实践中有着不错的效果。但作为一种创新型算法,有待加强其理论方面的研究。
(2)参数缺少对应的规范确定的准则
遗传参数的设置取决于编码以及遗传技术的差别,往往是依靠过去经验得来的参考值,所以该算法的应用也受参数不规范的影响。
(3)选取初始种群往往是决定性的
在处理单峰函数的问题上,遗传算法拥有着得天独厚的优势。但是在处理多峰函数的问题上,遗传算法就比较容易陷入局部最优解,导致无法收敛出全局最优值。因此种群的选取,往往是决定性的。
(4)局部搜索能力不够
遗传算法的搜索能力受控制参数以及初始种群的影响。一般情况下,遗传算法的收敛速度较慢。不仅如此,遗传算法的稳定性往往比较低,导致局部的搜索能力不足,这是简单的遗传算法存在的不可避免的缺点。
三、基于广州KT物流科技有限公司的实证分析
(一)选址背景
1.公司简介
广州KT物流科技有限公司成立于2017年,年营业额3亿元左右,员工约300人,是一个专门为中小企业提供物流运作解决方案和代管服务的智能化物流平台。其主要以“人工智能+云服务+大数据”为核心能力,通过互联网创新技术,优化整合社会运力,满足中小企业碎片化的物流运作需求,有效帮助中小企业降低物流成本。
2.选址情况简介
近年来,为满足公司发展需要,拟在珠海、东莞、中山、惠州、广州等地选址再建立三个配送中心,使配送中心由目前的两个增加为五个。根据统计,8个主要用户群到达各个配送中心的流程图以及成本分别见图6和附录。
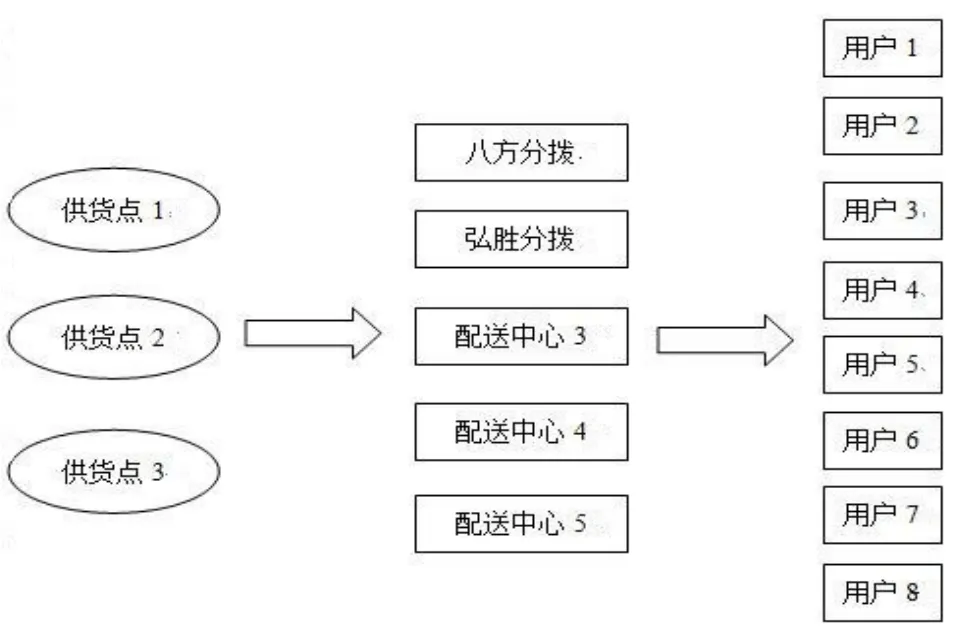
图6多点配送流程图
(二)选址要求
配送中心选址应符合以下规律[20]。
1.最小成本原则
供货点到配送中心的总成本+配送中心到用户的总成本+配送中心运营成本(可变成本+固定成本)最小。
2.限制条件
(1)供应点到配送中心总运量要小于配送中心总供应量。
(2)配送中心到用户的总运量要大于用户需求量。
(3)供应点到配送中心总运量要等于物流中心到用户的总运量。
(4)要选择该配送中心才可以出现运量。
(5)物流中心的个数不可超过上限。
(6)运量不可小于0。
(7)一个用户只对应一个配送中心,一个配送中心则可以对应多个用户。
因此综合运量、单位运费、固定成本的目标函数为:
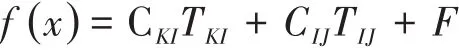
因此综合运量、单位运费、固定成本、可变成本的目标函数为:
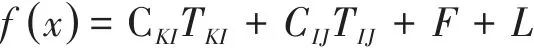
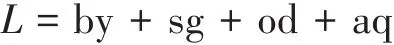
其中CKI为供货点到配送中心的单位成本,TKI为供货点到配送中心的运量,CIJ为配送中心到用户的单位成本,TIJ为配送中心到用户的运量,F为固定成本,L为可变成本。L可变成本为by自然环境成本、sg经济环境成本、od政治环境成本以及aq路况成本之和。
(三)过程与结果分析
将遗传算法跟配送中心选址结合起来,利用MatLab优化工具箱,设定迭代次数为100,交叉概率为0.85,种群规模为100,变异概率为0.2,设定完毕后如图7所示,然后进行运算。
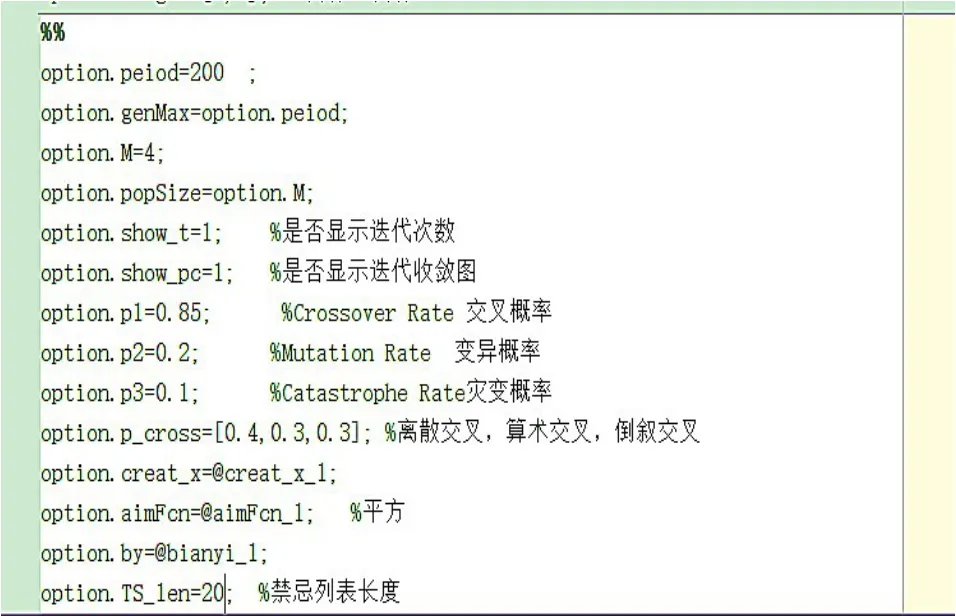
图7参数设定示意图一
1.结果Ⅰ(不包括附加影响因素)
运算结果(结合主要因素不包括附加影响因素)如图8、图9、图10所示。

图8运算结果(不包括附加影响因素)示意图一

图9运算结果(不包括附加影响因素)示意图二
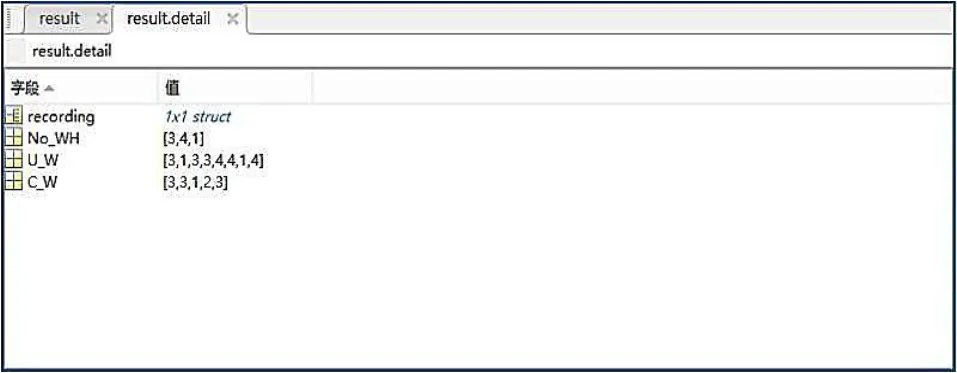
图10运算结果(不包括附加影响因素)示意图三
在综合单位运费、运量、固定成本的情况下,通过计算分析,会选择最优的三个配送中心为中山配送中心、惠州配送中心、珠海配送中心。各个配送中心服务用户的具体对应情况如表1所示。
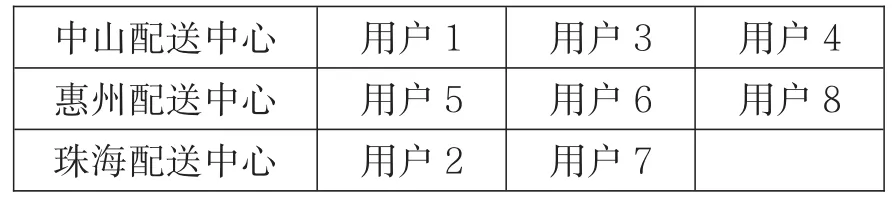
表1配送中心与用户对应表(结果Ⅰ)
2.结果Ⅱ(包括附加影响因素)
运算结果(包括附加影响因素)如图11、图12、图13、图14所示。
在综合所有因素的情况下,通过计算分析,选择最优的三个配送中心为中山配送中心、惠州配送中心以及珠海配送中心。各个配送中心服务用户的具体对应情况如表2所示。
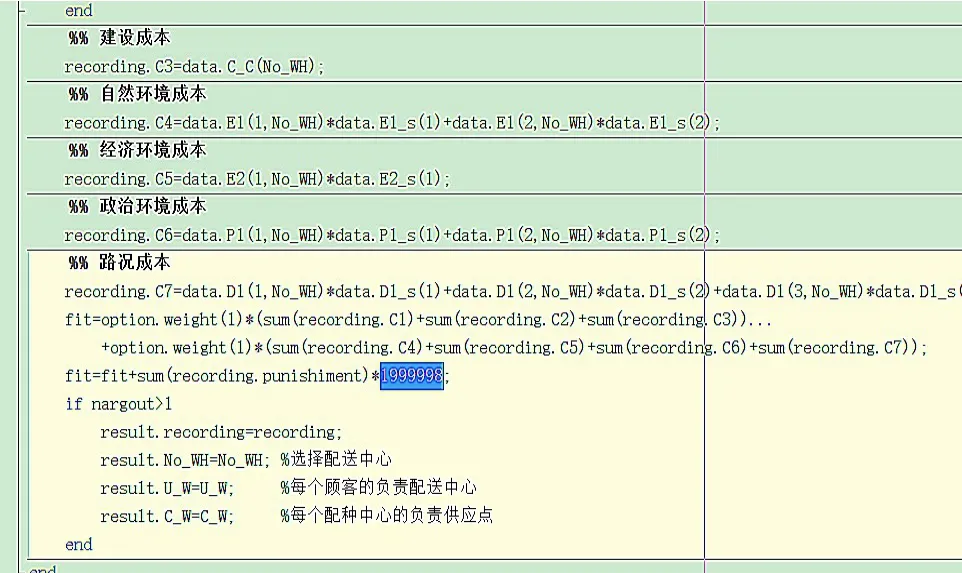
图11运算结果(包括附加影响因素)示意图一
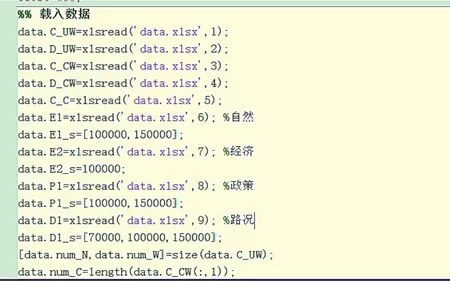
图12运算结果(包括附加影响因素)示意图二

图13运算结果(包括附加影响因素)示意图三

图14运算结果(包括附加影响因素)示意图四
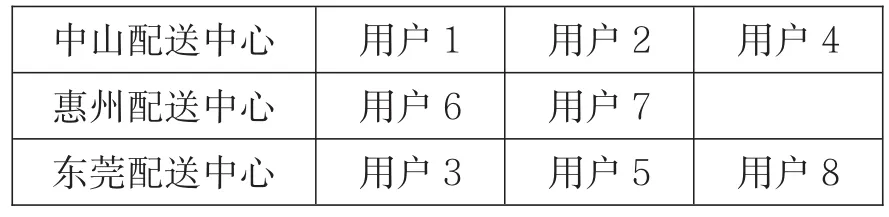
表2配送中心与用户对应表(结果Ⅱ)
四、总 结
综上,在只考虑固定成本、单位运输费用、运量等因素的条件下,遗传算法选址最优结果将中山、惠州、珠海作为备选的配送中心地址;但是在加上其他附加因素(建设成本、环境成本、经济成本、政策成本、路况成本)的情况下,选址结果发生了变化,中山、惠州、东莞成为更佳的选择。
因此,加入不同影响因素的情况下改变了函数整体走向的动态变化,但是依然能够保持精确度,所以可以得出以下结论:
1.遗传算法适用于配送中心的选址;
2.遗传算法可以更加简便地、便捷地综合更多的因素进行选址;
3.遗传算法具有强大的调整能力。
附 录
影响因素一(见表3—表5)附加影响因素二(见表6—表9)

表3

表4

表5固定成本表
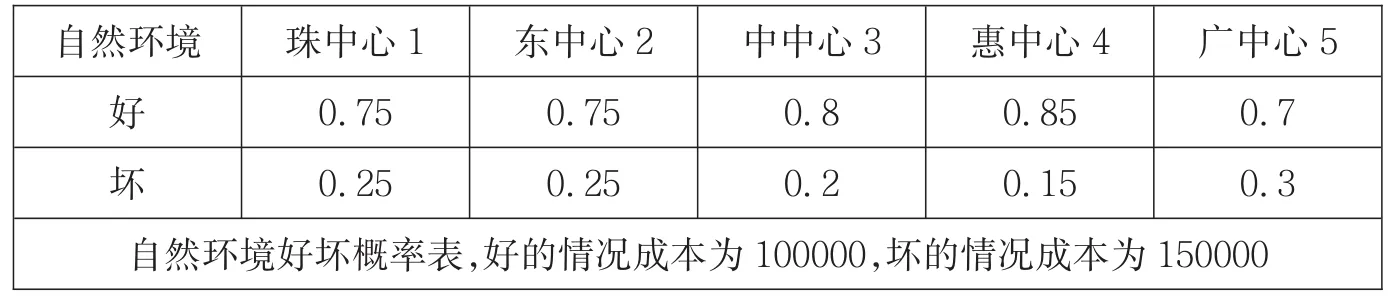
表6

表7
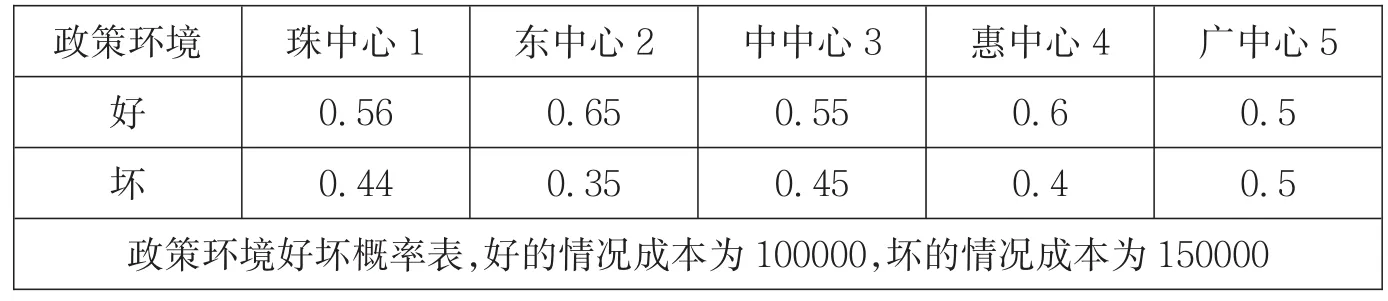
表8

表9
