基于大数据的个人征信评级模型
2019-08-15王图南何阁邹怡宁黄运竹谭瑞
王图南 何阁 邹怡宁 黄运 竹谭瑞
摘 要:一个发展完备的个人征信系统含有广泛而精确的消费者信息,可以为P2P消费信贷行业等有个人贷款业务的机构提供贷款建议与利率依据。优质的信用分析产品可以帮助消费信贷机构以最有效、经济的方式接触到自己的目标客户,因而具有极高的市场价值。大数据时代,海量的信息可以被用于个人信用的评级,如何筛选出合适的原始信息并进行加工、处理,以构建出一个合理的信用评级模型来实现对个人信用的评分成为个人征信系统中重要的一环。
关键词:个人征信系统;个人信用评级;层次分析法
一、引言
在当今的大数据时代,个人征信评级的数据来源于人们的生活细节,最终也将用到人们的生活点滴中去。我们日常贷款需要进行信用评级来让金融机构判断是否可以为你办理贷款业务、该以怎样的利率贷款给你、贷款的额度是多少,贷款期限是多长等等,这一系列涉及双方利益的问题都是从信用数据中找到的答案。而在信用评级制度不健全的时候,这些数据都处于缺失状态,需要金融机构通过电话访问的方式是一项一项地了解与核实,这就大大增加了金融机构的工作量,同时信息的准确性也难以保证。然而目前为止,我国在大数据个人征信评级实用性模型方面的探讨还不多,由此可见,建立一个短期内可行的基于大数据的个人征信评级模型具有必要性和迫切性。
二、个人征信评级模型的建立
1.原始信息选择
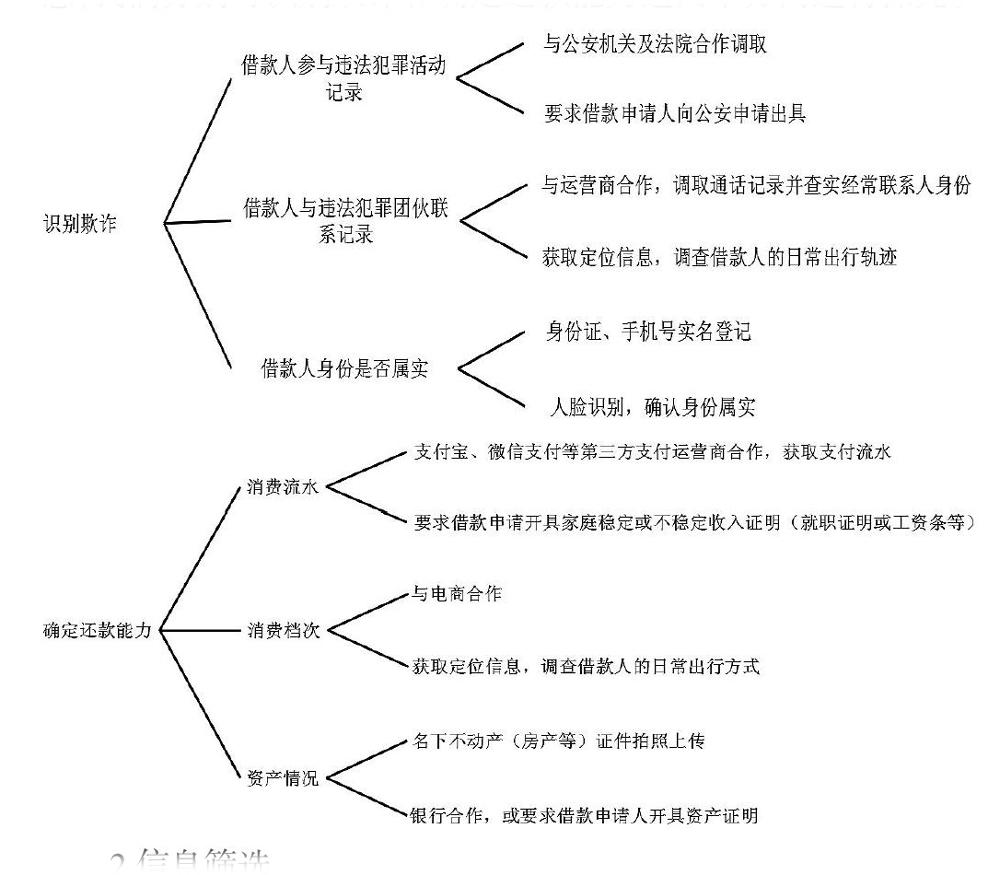
在大数据时代,获取信息的方式五花八门,几乎每个人都生产了海量的数据,这些数据可能是你的消费记录,也可能是位置信息,甚至是通话记录等等。為选择出满足个人征信要求的信息,我们分别对识别欺诈和确定还款能力这两个方向进行探究。
2.信息筛选
为了将原始信息处理成可用的征信信息,我们需要采用分布式爬虫技术进行所需有效信息的提取。
基本原理是:从数据仓库中取出URL,利用HttpClient进行下载,对下载后的页面内容使用HtmlCleaner和xPath等工具进行页面解析,这时,我们解析的页面可能是列表页面,也有可能是详细页面。如果是列表页面,则需要解析出页面中详细页面的URL,并放入Redis数据仓库,进行后期解析;如果是详细页面,则存入我们的MySQL数据。
3.信息处理
如何将我们筛选出的信息转换为最终的信用分或者信用评级呢?这就需要我们用到大数据分析的方法。本团队在这里借鉴阿里京东等企业的风控模型,给出一个互联网金融风控的一般方法。
(1)防欺诈风控系统
①根据以往的业务系统数据可以建立黑名单、白名单
白名单:通过建立数据模型进行数据挖掘,并利用机器学习相关算法进行优质用户的挖掘。
黑名单:通过手机号码、imei作为用户判断标识,调用第三方征信公司去进行鉴别。
在实际调查中,我们发现,很多互联网金融企业都会建立自己的白名单和黑名单,但是并没有一套共享机制。如果能做到黑名单的共享,企业之间各取所长,会进而大大降低欺诈行为的可能性。
②对移动端用户进行实时监测,获取用经纬作为、获取用户重力感应数据、mac地址、ip、移动设备注册时长等数据判断用户是否存在恶意欺诈,恶意注册。
在发现借款人存在欺诈行为或存在欺诈可能后,系统将主动上报,并禁止其进行P2P借贷等行为。
(2)风险等级划分
①数据量化
首先,对于能反应支付流水的数据,直接采用相应数据x 来带入模型中。
其次,对于反应消费档次的信息,我们采用分类赋分的方式。这样,每个层级的信息都会得到一个赋分,从而使加权成为可能。
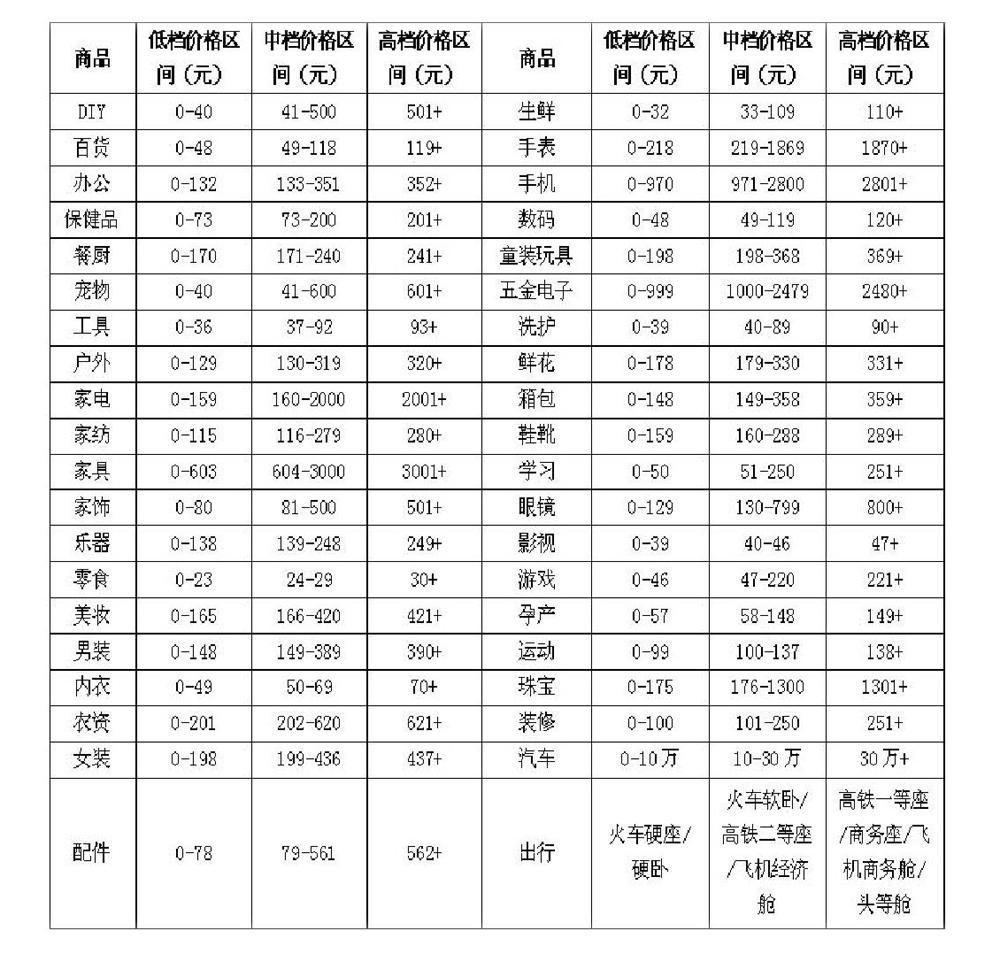
利用爬虫技术,我们从淘宝、天猫、京东、唯品会等多家电商网站搜集各种商品的价格区间范围,并以每个价格区间的商品数为依据划分消费等级并加以整理。其中,高、中、低档产品分别占同类别产品总数的30%、40%、30%。
消费档次分层情况如下表所示:
对于在考察时间范围内发生的消费情况,每件高档品消费记3分,中档记2分,低档记1分,并最终按该消费品占总消费情况的权重赋予相应权重。为与消费流水量级相同,在最终得分上乘10000以平衡量级,这样最终得到的消费档次得分是一个 10000-30000之间的数。例如,某借款人半年内发生20%的高档消费,40%的中档消费和40%的低档消费,则他最终消费档次得分:
y=10000*(20%*3+40%*2+40%*1)=18000
最后,对于反映资产状况的数据,我们将其与借款额做比并乘10000以平衡量级。令借款额=A,资产总额=B,资产情况得分:z=10000*B/A
确定了x,y,z后,通过加权就可以得出最终信用评分 S=a*x+b*y+c*z。
②模型权重确定
为了以一种科学的方式确定模型权重,本团队在查阅相关资料并请教了有关专家后决定采用层次分析法。
首先,建立结构层次模型。
本团队将确定还款能力大小作为目标层,建立层次分析法的模型。
消费流水显示了个人在一段时间内日常的各项支出情况,既包括日常生活消费,也包含了投资、奢侈品等大额支出,能够显示个人的消费水平和消费能力。
消费档次指通过观察个人消费商品的类别(高、中、低档),并根据各档次所占比例来对个人的消费档次进行量化。
资产情况能够直接反映个人的还款能力,用借款额占资产额的比重来衡量个人的资产状况好坏。
综上所述,个人还款能力应从消费流水、消费档次、资产情况三个方面的研究来确定。衡量个人还款能力的指标体系如图所示:然后,构造判断矩阵。
从层次结构模型的第2层开始,对于从属于(或影响)上一层每个因素的同一层诸因素,用成对比较法和1-9比较尺度构造成对比较阵,直到最下层。判断矩阵是将同一个矩阵的每两个因素的重要性程度进行相关性比较,并将相关性比较的程度用 1-9比较尺度进行表示。1-9比较尺度的关系如下表所示。
三、小结
1.模型改进与应用
除线性加权的方法外,我们还可选取逻辑回归模型等更加复杂的模型来算取最终的信用评分。且在人工智能技术快速发展的今天,想要实现模型的自主学习已经不是一件难事,随着模型的不断完善,信用评级技术将越来越精准。
借款人成功借款后,公司会尽全力继续跟着这笔借款的去向,同时,也会继续收集该借款人的个人征信信息,以实现实时的信用评级。一旦借款人出现了不良的消费行为,系统就会给予警告,当借款人的评分低于所设定的阈值时,公司便会勒令追回借款。P2P借贷不同于传统的抵押借贷,在追回借款的过程中,借款人可能出现拒不还贷等流氓行为,此类行为将把借款人放置于黑名单之列,从此该借款人都很难实现借贷等信用活动。更重要的是,随着企业间信息的共享,此借款人可能在所有涉及到个人信用的领域都会步履维艰。
2.个人信息风险
在信息时代,每个人都像是在海里裸泳,我们的各种信息,在不知情的情况下,很多已经被对方甚至第三方获取。虽然上述原始信息是需要经过个人授权才能被企业所使用的,但信息安全问题总还是带给我们隐隐的担忧。
在同学及亲友的帮助下,本团队共发放了1591份问卷。其中28岁以下的被调查者占40.51%,28岁以上的被調查中占59.49%。
问卷调查结果显示:
在利用互联网时,绝大多数人已经意识到个人信息的泄露问题,并会主动地采取措施避免个人信息泄露。
在征信过程中对防范欺诈起重要作用的人脸识别技术,正是基于不定期开启摄像头以验明身份来实现的。可调查结果却显示,有74%的人绝不允许P2P软件启用摄像头。同时有超过60%的人拒绝提供联系人、支付记录等对欺诈识别与还款能力评定至关重要的信息。另一方面,P2P借贷平台过多获取个人隐私信息的行为会使近70%的用户直接终止借款申请,还有超过15%的人会对该平台提起申诉。
由此看来,信息获取权限问题将是将来困扰个人征信行业崛起的重要方面。
为试图探求信息征集问题的解决之道,本团队拟建立一套加密系统来收集用户的隐私信息,并使得任何个人都将无法获取某项确切的个人信息内容,收集信息的结果只用于信用评分的生成。然而,人们的反应却并不乐观,即使的在信息加密的情况下,依然有大约60%的用户不同意P2P平台征集个人信息。
现实生活中,90%的人都有被骚扰电话打扰的经历,甚至部分人还因信息泄露遭受过精神及财产损失。尽管调查结果显示信息征集已很难进行,但只有10%的人认为自己有较高的信息安全意识,绝大多数人都认为自己的安全意识还有一定提高的空间。可以预见到,随着技术及制度的进步,人们正在有越来越强的隐私意识,并对个人隐私的保护有着越来越高的要求。这对新兴的大数据个人信用信息评级来说是一个不小的挑战。
参考文献:
[1]李俊丽.我国个人征信体系的构建与应用研究.农业经济管理,2007.
[2]李战江.最优策略下的商业银行信用风险的小样本评级模型.系统工程,2017.
[3]美通社.冰鉴科技获1.1亿元A轮融资——创世伙伴资本领投、领沨资本跟投.金卡工程,2017.
[4]薛洪言.百行征信的模式、边界与使命.金融经济,2018.
[5]马晓军,沙靖岚,牛雪琪.基于LightGBM算法的P2P项目信用评级模型的设计及应用.数量经济技术经济研究,2018.
