二型糖尿病肾病风险预测模型的比较
2019-08-15晋2蕾3任慧玲
林 鑫,李 晋2,刘 蕾3,梁 晨,任慧玲
随着人口老龄化和人们生活方式的转变,糖尿病患病率呈直线上升趋势,目前我国已成为全球糖尿病第一大国[1-2]。其中,二型糖尿病患者作为我国糖尿病人群的主体,其临床发病率呈逐步上升趋势,其并发症发生率也相对较高。目前我国大约有20%~40%二型糖尿病患者并发肾病,现已成为慢性肾脏病和终末期肾病的重要原因[3]。二型糖尿病肾病的临床特征主要以蛋白尿排泄异常为主,严重时常合并肾功能衰竭,一旦发展至终末期,将会比其他肾脏疾病的治疗更加棘手[4]。因此有效的早期预测及相关的风险预测模型研究对于二型糖尿病肾病的早期预防和降低并发率具有重要的意义。
目前临床上对糖尿病肾病进行诊断的依据主要包括实验室检查、病理学诊断、糖尿病视网膜病变等,诊断过程繁琐且耗时[5]。本文以二型糖尿病肾病风险预测为目的,对解放军总医院提供的糖尿病数据集进行预处理后,依据数据集中已有的各项临床检查指标,选用随机森林、BP神经网络、支持向量机3种较为成熟的算法建立风险预测模型,并利用查准率、召回率等指标对三种模型的性能进行比较,以选出在二型糖尿病肾病风险预测方面更具优势的算法,实现对二型糖尿病肾病的发生风险进行简便快捷的预测。
1 数据与方法
1.1 数据来源
本文数据来自国家人口与健康科学数据共享服务平台临床医学科学数据中心(中国人民解放军总医院)提供的2009-2010年糖尿病数据集[6]。该数据集包含诊断表、尿常规检查表、生化检查表等记录了患者的ID号、诊断结果、各项身体指征,以及包括尿白细胞、直接胆红素、血清白蛋白等在内的多项检查结果。每个表通过患者的唯一ID号进行关联,并对检查表中各项检查的正常值进行了说明。
1.2 数据预处理
由于原始数据被分为多个表格,且存在缺失值、异常值等噪声数据,故需要对原始数据进行预处理,以控制数据的完整性和准确性,保证结果的准确性。本文所做预处理步骤如下。
数据整合:由于原始数据被划分为诊断、尿常规和生化等多个表格,故首先依据诊断表中的信息筛选出单纯二型糖尿病及二型糖尿病并发肾病的记录,依据这些记录对应的患者ID以及诊断时间从诊断、尿常规、生化检查等表格中提取距离诊断时间最近的一次患者检查信息,利用Excel的lookup和min函数对诊断、尿常规和生化等多个表格中的检查数据进行整合。
缺失值处理:数据的缺失会增加分析过程的难度,造成分析结果的偏倚,降低结果的准确性。由于均值插补法计算量相对较小,可高效快速地对缺失值进行处理[7],对整合后的数据进行整理,然后分别求各列数据平均值后对空缺数据进行填补。
异常值处理:在处理异常值时,利用拉依达准则[8],即以给定的置信概率99.7%为标准,以3倍数据列标准差为依据,凡大于3倍标准差的误差则认为是粗大误差,即异常值,删除筛选出的异常值。
经过对数据集的预处理,共得到472条二型糖尿病并发肾病数据和422条单纯二型糖尿病数据。经过预处理后得到的数据集部分截图如图1所示。
图1预处理后的数据截图(部分)
2 风险预测模型构建
2.1 单因素逻辑回归分析
将整合各检查表得到38个检查指标,赋值后,利用SPSS 19.0进行单因素逻辑回归分析。部分赋值情况见表1。最终筛选出24个具有统计学意义的指标(P<0.05),分别为年龄、尿比重、尿胆原、尿红细胞、尿糖、尿液结晶、尿液颜色、尿蛋白、总蛋白、血清白蛋白、总胆红素、直接胆红素、尿素、谷氨酰基转移酶、肌酐、葡萄糖、血清尿酸、总胆固醇、肌酸激酶、乳酸脱氢酶、钙、钾、氯化物以及无机磷。

表1 数据集字段赋值对应表(部分)
2.2 模型算法选择及参数设置
在明确具有统计学意义的检查指标后,运用机器学习中的监督学习方法构建疾病风险预测模型。其中,随机选择数据集的70%(共626条)作为训练集,30%(共268条)作为测试集。结合不同算法特点选择的机器学习算法及相应的参数设置如下。
随机森林(Random Forest,RF)是一种基于集成学习的思想将多棵决策树进行组合从而对数据进行分类的机器学习算法[9]。最后的分类结果是由所有决策树进行投票来决定的,其分类结果比C5.0决策树模型更加精确,且具有更少的过拟合倾向[10]。本文利用R语言中的RandomForest函数进行模型构建,由于随机森林对参数并不敏感,因此使用默认参数。
BP神经网络是一种按照误差逆传播算法训练的多层前馈网络,由输入层、隐藏层和输出层组成,是目前应用最为广泛的神经网络模型之一[11]。该模型对自变量的要求比较低,可以是离散型,也可以是连续型。在BP神经网络模型的构建中,加载R语言中的nnet包,利用nnet建立BP神经网络模型。设定神经网络的输入节点数为24,输出节点数为1,权值的衰减参数为0.05,通过不断试验改变隐藏节点个数,不断优化神经网络模型,最终在中间隐藏节点数为10时,模型效果达到最优。
支持向量机(Support Vector Machine,SVM)是基于统计学习理论、VC维理论以及结构风险最小化原理的一种机器学习方法[12],在小样本、非线性以及高维模式下具有很大优势[13]。运用SVM算法对数据进行处理时,利用R语言中的ksvm函数和高斯RBF核函数,对数据进行训练和预测。
2.3 模型预测结果
利用R语言中相关函数包分别建立随机森林、BP神经网络和支持向量机3种风险预测模型,并依据7:3的比例将数据集随机划分为训练集和测试集,分别用于训练和对二型糖尿病并发肾病的预测。3种模型对于二型糖尿病并发肾病及单纯二型糖尿病的预测结果如表2至表4所示。

表2 随机森林预测结果

表3 BP神经网络预测结果

表4 支持向量机预测结果
3 模型性能评价与比较
3.1 模型评价指标
本文选择查准率(Precision)、召回率(Recall)、正确率以及F1值等4个度量值对各个模型的性能进行评价,以检测模型预测结果与真实结果之间的差异,为模型的选择提供依据。其中,查准率越高,算法的敏感性就越高;召回率越高,算法的特异性就越高;正确率越高,算法的精确度越好;而F1度量值越高则可确保召回率和查准率都越高,算法的总体性能越好[14-15]。这4个度量值的公式如下。



除此之外,本文还引入ROC曲线对模型进行评估。在ROC曲线中,横轴为假阳性率,纵轴为真阳性率[16],ROC曲线下面积在0.5~0.7之间的准确度较低,在0.7~0.9之间的准确度一般,在0.9以上的准确度较高,小于0.5则不符合真实情况[17]。
3.2 模型比较结果
依据预测结果及R语言的ROCR包,分别计算这3种算法的查准率、召回率、正确率、F1及ROC曲线下面积。结果如表5所示。
由表5可知,对于ROC曲线下面积,随机森林效果最优;对于正确率,随机森林效果最优;对于查准率,支持向量机效果最优;对于召回率,随机森林效果最优。但由于查准率和召回率是一组此消彼长的评价指标,仅用单个指标无法对算法的效果进行总体评价[14]。因此可以用F1值对这3种算法的综合性能进行评价,其结果为:随机森林>支持向量机>BP神经网络。综合上述指标来看,随机森林性能最优,这3种算法的训练效果均较好。
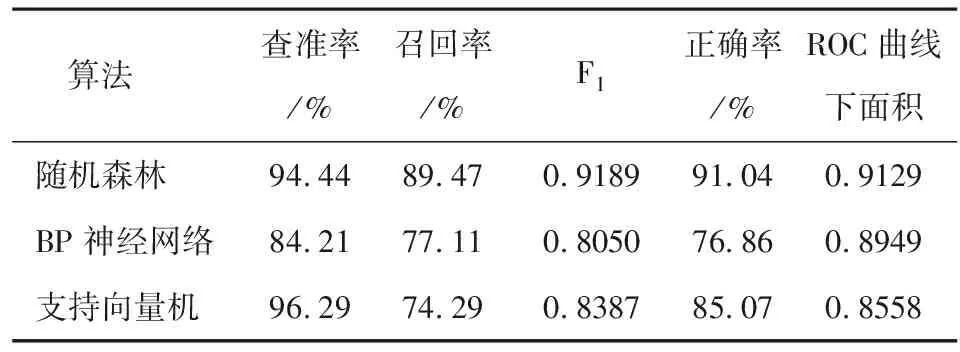
表5 3种算法的结果
4 讨论
由于糖尿病肾病是二型糖尿病患者常见的并发症,目前国内外针对二型糖尿病肾病风险预测模型的建模已有相关尝试,常用的建模方法主要包括逻辑回归、分类与决策树模型、支持向量机、神经网络模型等[18]。本文在综合前人研究成果的基础上,结合不同算法的特点及优缺点,充分考虑所选数据集的实际记录情况,最终选取随机森林、BP神经网络以及支持向量机这3种机器学习算法,并综合多种指标验证其应用于二型糖尿病肾病风险预测时的性能,为算法的选择提供依据。本文结合单因素逻辑回归进行指标筛选,再选择相关算法建立预测模型的方法具有普适性,其不仅可用于对二型糖尿病其他并发症进行预测,也可用于其他疾病的风险预测。
本文也存在局限性。考虑到数据集的数量和质量对模型的可靠性和可扩展性具有重要影响[19],本文采用的数据共894例,这些数据对于建模来说还相对较少,会直接影响到模型的效果。未来将进一步扩大数据量并对相关算法进行改进,使模型综合性能得以提高。
5 结语
二型糖尿病肾病由于存在复杂的代谢紊乱,一旦发展至终末期,其治疗将会更加棘手,因此早期对二型糖尿病肾病进行风险预测具有十分重要的意义。本文利用解放军总医院提供的2009-2010年度糖尿病数据集,采用均值插补法及拉依达准则对原始数据进行预处理,得到894条数据。利用单因素逻辑回归从原数据集的38个检查指标中筛选出24个有效指标并构建训练数据集和测试数据集,同时基于随机森林、BP神经网络、支持向量机3种算法分别构建二型糖尿病肾病风险预测模型。通过利用查准率、查全率、正确率、F1值以及ROC曲线下面积等5个度量值分别对这3种模型的性能进行比较,发现基于随机森林算法构建的风险预测模型性能最佳。本文结果可为二型糖尿病肾病的早期筛查及相关风险预测模型的算法选择提供参考及帮助。
