基于Caffe卷积神经网络的大豆病害检测系统
2019-08-14蒋丰千余大为张恩宝
蒋丰千,李 旸,*,余大为,孙 敏,张恩宝
(1.安徽农业大学 信息与计算机学院,安徽 合肥 230036; 2.农业农村部农业物联网技术集成与应用重点实验室,安徽 合肥 230036)
大豆又称黄豆,属于双子叶植物纲大豆属的一年生草本类植物,外表通常呈褐色硬毛状,其主产地位于我国东北地区。大豆因含有丰富的植物蛋白质而被广大居民所喜爱[1]。然而大豆病害带来的一系列问题给农业生产造成了巨大经济损失,也时刻影响着我国农产品市场的稳定[2]。深度学习算法作为目前图像识别领域的一大热点,其主要实现方式是以卷积神经网络为代表的神经网络算法。该算法与传统图像处理技术相比,拥有较高自主学习能力,同时还精简了许多复杂而繁琐的图像预处理环节[3]。我们在分析和研究大豆的4种主要病害(叶斑病、花叶病、霜霉病和灰斑病)的基础上,利用卷积神经网络技术设计了关于大豆病害的识别模型,并以此为基础引进了相关的优化措施。
1 材料制作
1.1 样本采集
本实验样本主要来源于安徽农业大学重点实验室提供的样本原型以及国内各大农业网站提供的图片素材,共计400张图片。并将其分为4组,每组再细分为训练集和识别集,分别为80张和20张大豆病害图片。部分实验图片如图1所示。
在对大豆病害图像的采集和研究中可知,叶斑病多发于大豆的叶片部位,初期多为不规则灰白色病斑,后期病斑干枯并伴有黑色小粒点[4]。灰斑病主要发生于叶片,但在茎、荚等部位也会出现,发病时首先出现褐色小斑点,后期扩展为圆形或不规则病斑,边缘多为褐色或黑色。霜霉病的发病对象主要是幼苗或成株的叶片,发病时叶片会出现大的块状病斑并布满白色霉层,导致提早落叶等现象发生[5]。花叶病则是一种病毒病,症状较多,常见的有花叶皱缩、植株矮小等[6]。
1.2 样本预处理
在提高神经网络模型训练的有效性时,本实验借助OpenCV库对采集的大豆病害图像进行二值化和轮廓分割等预处理[7],以此来去除噪声和冗余信息并突出图像中主要病害特征[8]。其中,OpenCV为一种跨平台计算机视觉库,其建立之初便凭借其在处理图像时的高效性以及对于Linux、Windows等多平台的包容性而迅速流行起来并受到广大科学研究者的喜爱[9]。
在完成大豆病害图像的ROI区域提取时主要利用了OpenCV中的FindContours函数来完成[10],该函数的主要功能为实现图像的轮廓检测并以链表的形式将得到的轮廓信息进行保存且该函数的处理对象需为二值图[11]。因此,首先进行图像的灰度化和二值化,而后利用该函数寻找轮廓信息并使用最小外接矩形对其进行标记[12],在此基础上利用R、G、B三通道独立赋值实现目标区域的分割和保存。具体实现过程如图2-图4所示。

图1 大豆病害图像样本Fig.1 Soybean disease image sample

图2 大豆病害图像预处理Fig.2 Preprocessing of soybean disease image

图3 目标区域的定位Fig.3 Location of the target area
2 模型设计
2.1 卷积神经网络的设计
2.1.1 Swish函数
(1)饱和激活函数
对于激活函数h(x),当x无限趋近于正无穷时,其导函数为0,称其为右饱和;当x无限趋近于负无穷时,其导函数为0,则称其为左饱和;当h(x)符合该条件下,即称其为饱和函数[13]。考虑到神经网络算法在使用误差逆传播算法优化网络参数时,其激活函数若出现饱和现象,则会降低网络的训练速度和效果,严重时会出现梯度弥散等现象[14]。
(2)Swish函数特性
Swish激活函数是在2017年10月由Google团队提出的一种新的激活函数,具体的数学公式如下[15]:
(1)
式中:f(x)为Swish函数激活后的输出;x为Swish函数激活前的输入。
由该公式可得其图像和导函数特性,具体如图5所示。
由上图Swish和Sigmoid的函数图像对比分析中可以得出,Swish激活函数具有一般激活函数的通性,即存在上界的独特的非单调性。此外,由其导函数图像可知其具有一定的平滑性,可有效缓解大部分神经网络因激活函数存在的饱和现象而产生的弥散问题[16]。
2.1.2 BN算法
为提高神经网络模型对于复杂事物的学习能力,训练过程中常使用激活函数,但激活函数在引入非线性因素提高学习能力的同时随着网络深度的不断加深会导致输入值(非线性变换前)产生偏移,进而使得神经网络在网络层较低处发生梯度消失,从而大幅度影响网络的训练速度。针对该问题,BN算法则是在激活函数前利用重构变换等归一化手段处理输入值,使其变换为标准正态分布[17]。而标准正态分布的点大多存在于激活函数的敏感区域,可有效避免梯度消失现象的发生。具体步骤如下:
以一个批次(样本为n)为单位,计算其均值u和方差σ[18]
(2)
(3)
利用批次均值和方差实现数据的归一化
(4)
考虑到σ取值为零的情况发生,需设置常量。
为保证原始数据特征分布在数据归一化过程中的完整性,利用重构变换和训练学习的方式来得到下式中的γi与βi,从而对原始数据进行完整的复原。
yi=γixi+βi;
(5)
(6)
βi=E[x]。
(7)
式中:Var为方差函数;γi为输入xi的标准差;βi为输入xi的均值;E为均值函数。
2.2 卷积神经网络的设计
本实验模型的设计主要以传统的卷积神经网络LeNet-5为基础,对其进行了结构层数量和种类的改进并利用Swish激活函数和BN算法对模型进行了优化。具体结构如图6所示:
图6中模型的输入层不是原始图像,而是对一张病害图像中出现的多处病害情况进行ROI定位和提取后得到的若干独立小图,从而充分保证了模型在训练时学习到不同程度的病害特征,避免了数据的单一性,有效地提高了模型的泛化能力。其中,特征提取层分别由3层卷积层(步长为1)、3层BN层、3层激活层和4层池化层(最大池化)交替叠加构成,在提取到图像的高维特征后再利用3层全连接层进行下一步的学习任务并将得到的结果送入分类器进行大豆病害种类的识别。具体参数(Cx表示卷积层,Sx表示子采样层,Fx表示全连接层)如表1所示:
3 实验仿真及UI界面设计
本次实验模型基于Ubuntu16.0.4操作系统,并安装配备了Caffe深度学习框架和UI界面设计软件Qt5.3。其中,Caffe框架在各大操作系统中都表现出了强大的通用性,加上其在图像处理领域中的便捷性,该框架一经提出便受到了国内外研究学者和众多人工智能企业的推崇和喜爱。此次实验过程中,针对优化措施有效性的验证,加入了传统LeNet-5模型在同样条件下的实验性能,利用在测试集上的准确率(Train acc)和验证集上的泛化率(Val acc)与优化后的神经网络进行对比,具体数据如表2所示。

图6 卷积神经网络优化模型Fig.6 Convolutional neural network optimization model
表1 神经网络架构层参数
Table 1 Neural network architecture layer parameters

网络层Network layerC1S1C2S2C3S3F4F5F6特征图个数Characteristic number32326464128128———输入尺寸Input size100×100100×10050×5050×5025×2525×255×5×1281024512内核尺寸Kernel size5×52×25×52×25×55×5———输出尺寸Output size100×10050×5050×5025×2525×255×5102451252
“—”表示无该数据。
“—” indicated no data.
由表2可知,在相同条件下,传统的LeNet-5模型的准确率仅仅只有81%,而优化后的卷积神经网络模型则达到了92%。在象征泛化能力的拟合率上,优化后的网络模型较LeNet-5模型则提高了15个百分点。综上所述,该模型经优化后相对于传统的卷积神经网络,其识别的准确率和泛化率均有一定的提升,对于大豆病害种类具有良好的识别能力。
在UI界面设计阶段,本实验主要利用了Qt Creator来开发Ubuntu下基于Caffe的图形化界面。QT是一个跨平台的C++图形用户界面库,由挪威TrollTech公司出品和维护。其开发环境具有十分丰富的API和详实的开发文档,加之其具有的良好的多平台通用性使得其迅速成为众多软件设计工程师在开发UI界面时的不二之选。本实验在设计UI界面时考虑到大豆种植户使用的便捷性,仅对主要的显示界面进行设计,具体的显示界面和系统流程如图7所示。
在识别结果上,本实验采取了病害类型加匹配度的方式,充分考虑了结果的多样性和客观性,此外,还为每种病害提供给了相应的治疗措施。实验测试图如图8所示。
表2 优化后的卷积神经网络与传统的卷积神经网络的精度比较
Table 2 Comparison of the precision between the optimized convolution neural network and the traditional convolution neural network

指标次数Index numberLeNet-5卷积神经网络LeNet-5 CNN准确率Train acc泛化率Val acc优化后的卷积神经网络Optimized CNN准确率Train acc泛化率Val acc10.310.290.660.5820.490.480.710.6730.590.500.810.6540.760.550.850.7050.810.630.920.78
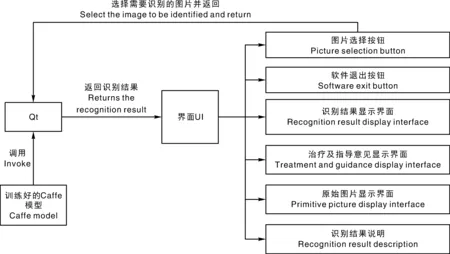
图7 基本流程图Fig.7 Basic flow chart

图8 叶斑病的识别结果Fig.8 Recognition of leaf spot disease
4 结论
本实验在传统神经网络的基础上进行了改进和优化,并以此设计了一种大豆病害种类识别系统。通过实验仿真可知优化后的网络模型的拟合能力达到了92%,而泛化能力为78%,较之前提高了15个百分点,在实际环境下对于大豆病害具有较好的识别能力。此外,借助Qt设计了基于Caffe框架的数据可视化界面,对病害种类、治疗意见进行了反馈,有效地提高了系统的可用性且较好地缓解了日常生产生活中大豆病害种类识别的难题。
