基于深度学习的水面漂浮物目标检测评估
2019-08-06雷李义艾矫燕彭婧姚冬宜
雷李义 艾矫燕 彭婧 姚冬宜

摘要:在这篇文章中,我们提出了一个关于水面漂浮物的小型数据集,并分析了几种目标检测模型在数据集上的表现,包括Faster R-CNN,R-FCN和SSD。我们的目的是探究目标检测模型在检测水面漂浮物特别是非物体类别时的特性,并找出权衡精确度和速度后最适合于引导水面清洁无人船的模型。为此,我们制作了一个小型的水面漂浮物数据集,数据集主要包括漂浮水草和漂浮落叶。之后我们通过将预训练模型在水面漂浮物数据集上进行迁移学习,实现了对于水面漂浮物区域的目标检测。我们对比并分析了这些模型的表现,SSD目标检测模型有着更高的精确度,Faster R-CNN模型则能给出更详细的预测,而同时拥有丰富结构特征和相当深度特征的模型对于困难目标有着更好的表现。
关键词:数据集;深度学习;目标检测
中图分类号:TP391 文献标识码:B 文章编号:2095-672X(2019)06-0-04
DOI:10.16647/j.cnki.cn15-1369/X.2019.06.071
Abstract:In this paper, we present a small dataset focusing on floating objects and analyses the performance of several object detection models when detecting floating objects, including Faster R-CNN, R-FCN, and SSD. We aim to explore the properties of these object detection models when detecting floating objects specifically “stuff” objects and find the speed/accuracy balance for guiding the unmanned surface vessel(USV) to clean rubbish on water surface automatically. To this end, we have created a floating objects dataset which is mainly focused on floating leaves and floating weeds. Then we fine-tune the pre-trained models on our dataset to achieve the ability to detect floating objects. We compare and evaluate the performance of these models, including the average precision on 2 major classes and weighted average precision. Our findings show that the models using SSD as meta-architecture gain higher precision but the models using Faster R-CNN as meta-architecture give more specific predictions, and the models have both rich hierarchies features and deep features perform better when dealing with difficult examples.
Keywords:Dataset;Deep learning;Object detection
大家都喜欢景观湖带来的美丽景色,但现阶段景观湖的日常维护非常麻烦。主要有落叶和水草2种漂浮物会每天累积在湖面,为了保证湖面的清洁,目前只能由工人从湖面一点一点打捞这两种漂浮物,这种清洁方式不仅耗时耗力而且很难完全清洁湖面。为了减少劳动力的浪费,我们计划制作一艘水面清洁无人船,而这便需要无人船拥有检测水面漂浮物的能力。最近几年,目标检测模型的性能进步非常快。自从计算机视觉进入深度学习时代后,有很多新的目标检测模型被提出,其中一些模型由于独特的设计和出色的性能到现在还被使用在各个领域,包括Faster R-CNN[5],R-FCN[6]和SSD[7]等。但是性能的提升主要针对于大型数据集,而大型数据集涵盖的都是常见的物体类别,很少包含特定领域的类别比如说我们需要的漂浮水草和漂浮落叶。
为了解决水面漂浮物检测的问题,我们制作了一个小型的水面漂浮物数据集。由于我们研究的两个景观湖主要有落叶和水草两种漂浮物累积,因此数据集中的图片主要为这两类漂浮物。考虑到这两类漂浮物的特性以及标注的效率,我们对含有这两类漂浮物的区域进行边界框标注。之后我们利用数据集对8个经过预训练的目标检测模型进行迁移学习,并从精确度和检测结果样张两个角度分析了这8个目标检测模型在数据集上的表现。
总结起来,本文的主要贡献如下:(1)一个聚焦于水面漂浮物的小型目标檢测数据集;(2)一个简要的目标检测架构对比分析;(3)8个目标检测模型在水面漂浮物数据集上的表现分析,其中SSD实现了最好的速度和精确度的平衡。进一步的,我们的研究发现同时拥有丰富结构特征和相当深度特征的模型在面对困难目标时有更好的表现。
1 相关工作
本节将从两个方面介绍相关工作,第一是公开的目标检测数据集;第二是现有的目标检测算法评估。
1.1 公开数据集
目前有很多公开的大型目标检测数据集。文献[1]提出了一个大型数据集ImageNet,数据集基于词典结构制作,包含了12个子树下的5247个类别,总共有320万标注图片。所有的图片都来自互联网,通过在几个搜索引擎中检索一组词典中的近义词得到。ImageNet数据集的出现大幅推动了计算机视觉的发展。文献[2]提出了一个大型数据集COCO,数据集旨在推动实现对于场景的理解。数据集包含32.8万张图片和250万个标注实例,涵盖了91个类别。文献中将事物的类别分为物体类和非物体类,由于数据集专注于物体的精确定位,因此数据集中只包含了物体类的事物。
1.2 目标检测模型评估
文献[8]提供了一个如何在速度与精确度的权衡中选择合适的目标检测模型的指导,并公开了一个整合了三种目标检测架构以及各种特征提取网络的项目。所有的模型都在COCO数据集上进行了训练,并从精确度、运行时间和内存占用等角度进行了对比分析。文献[9]分析了多个目标检测模型在德国交通标志检测基准(GTSDB)数据集上的表现,评估包括了多个度量下的对比分析,结果显示Faster R-CNN Inception ResnetV2有最高的精确度,但是R-FCN Resnet101在权衡了速度与精确度后表现最好。
2 水面漂浮物数据集
由于现有数据集都集中于常见物体并且标注的主要都是物体类的目标,因此不能用于检测水面漂浮物的训练。为了实现引导水面清洁无人船的功能,需要我们制作一个专门针对水面漂浮物进行标注的目标检测数据集。本节将介绍我们是如何制作水面漂浮物数据集以及数据集的相关统计数据。
2.1 数据集的制作
目前为止,所有的图片都是通过拍摄广西大学内的镜湖和碧云湖得到的。由于校內的景观湖每天都会定时清理,从上午的7点到9点和下午的3点到5点,因此漂浮物的累积主要集中于上午9点到下午3点这个时间段,也因此数据集中的图片主要采集于这个时间段。图1展示了2张数据集中的图片。
文献[2]将事物的类别分成了物体和非物体2类,其中物体类指的是独立的个体能够被轻易标注的类别,非物体类则包括材料和一些没有清晰边界的类别。由于漂浮水草和漂浮落叶两类目标经常聚集在一片区域并且单根水草和单片落叶的体积非常小,因此我们将漂浮水草和漂浮落叶归为非物体类别并且进行区域标注,即将漂浮水草区域和漂浮落叶区域标注为一个目标。尽管对图像进行语义分割区域的标注能够更加贴合区域的形状,但是标注语义分割区域的工作量远远高于标注目标检测边界框的工作量,因此我们选择通过边界框的形式对有明显漂浮水草或漂浮落叶聚集的区域进行标注,并且使边界框尽可能的贴近聚集区域的范围。同时为了进一步提高标注效率,在保证标注准确率的前提下,我们更倾向于将聚集的大范围区域视为大目标进行标注,而不是视为多个分散的小目标分别进行标注。
收集到的图像中,除了会出现落叶和水草漂浮在水面,还会出现长在湖中的睡莲和环绕在岸边的一些植物,因此数据集中标注了少量的睡莲和岸边植物。由于睡莲和植物都能视为物体类的目标,因此这两类的标注要轻松很多。
我们使用标注工具LabelImg对图像进行标注,标注信息保存为XML格式的文件,与PASCAL VOC数据集的格式相同。图2展示了2张标注图像。
2.2 数据集的统计数据
目前为止我们对683张图像进行了标注,总共标注了2015个边界框,数据集中的图像全部为19201080像素。我们将数据集中80%的图像(546张图像)作为训练集,剩下20%的图像(137张图像)作为验证集。表1展示了数据集中的统计数据,平均尺寸指的是边界框的面积在整幅图像中所占的百分比。我们可以注意到,漂浮落叶区域的边界框数量最多,而漂浮水草区域的边界框平均尺寸最大。由于睡莲和岸边植物并不作为主要研究对象,因此这两类目标的数据较少。
3 目标检测算法分析
本节将对实验中使用的三种目标检测算法进行对比分析。
Faster R-CNN和R-FCN都是二阶段目标检测架构。在第一阶段中,两者都同样使用特征提取网络提取特征图,然后通过区域预测网络得到对目标的位置信息和类别信息的初步预测。在第二阶段中,Faster R-CNN首先根据初步预测的位置对特征图进行截取,然后将得到的初步预测位置的特征图通过特征提取网络进行进一步的特征提取。与Faster R-CNN不同,在第二阶段中R-FCN先不对特征图进行截取,而是直接将整张图像的特征图通过特征提取网络提取特征,之后再根据初步预测的位置对新的特征图进行截取,得到对位置信息敏感的特征图。因此,两者的主要区别在于第二阶段中,是否在提取特征后再对特征图进行截取。两者的区别可以进一步理解为,在第二阶段的特征提取网络中,是根据第一阶段提取的位置信息进行调整,还是另外提取一遍位置信息后和第一阶段得到的位置信息进行整合。
尽管SSD属于一阶段目标检测架构,和Faster R-CNN之间依然有很多的相似之处,甚至可以将SSD视为是Faster R-CNN中第一阶段的升级版。升级主要集中在2个方面,第一,SSD不仅利用神经网络最后输出的特征图,而是利用包括前后多层的特征图进行预测;第二,得到特征图后SSD同时对目标的位置和类别进行预测,而不像Faster R-CNN仅仅对目标的位置和是否为目标进行预测。这两个升级可以进一步理解为,相比Faster R-CNN,SSD使用更少的特征提取网络来提取特征,但是利用了更多特征提取网络中的信息。
4 实验结果与分析
本节将展示实验结果,并从精确度和检测结果样张两个角度对实验结果进行分析。
4.1 精确度分析
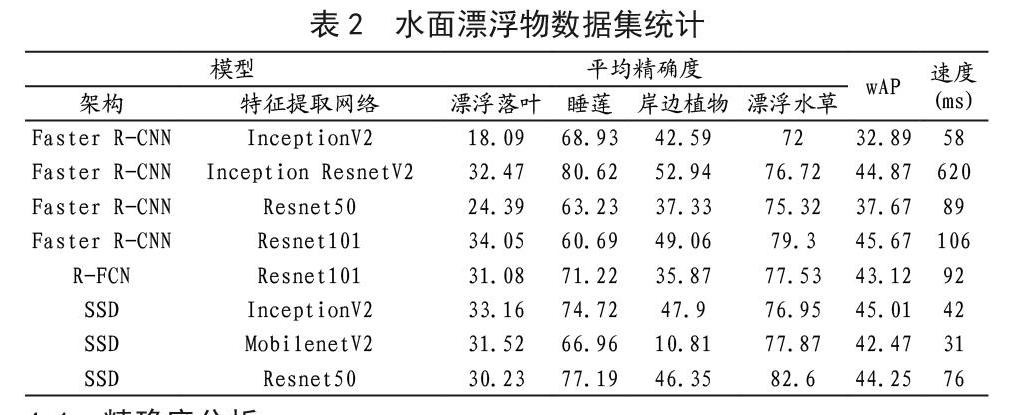
考虑到各个类别的样本数量差异较大,采用传统类别平均精确度(mAP)标准不能准确反映出模型的精确度,因此采用类别加权平均精确度(wAP)标准来衡量模型精确度。每个类别的权值与其类别的样本数量成正比。当预测的边界框与正确的边界框重叠度超过50%则视为预测正确。实验结果如表2所示,总共对8个模型进行了测试,表中的速度指的是使用一张NVIDIA GeForce GTX TITAN X显卡检测一张图像的运行时间。
首先分析主要两类漂浮物的检测精确度。在所有4个分类中,漂浮水草区域的平均精确度最高,而漂浮落叶区域的平均精度最低。漂浮落叶区域有着1161个训练样本,与之相比漂浮水草区域仅有382个训练样本,由此可见检测漂浮落叶区域相比检测漂浮水草区域更为困难。通过分析数据集中的图像我们发现,漂浮落叶的分布比较零散,而漂浮水草的分布相对比较集中,这也反映在两类目标的平均尺寸中,单个漂浮落叶区域的平均尺寸远小于单个漂浮水草区域的平均尺寸,尽管我们对两类目标都同样倾向于标注大范围区域。此外,由于单根水草的体积相对大于单片落叶,即使同样聚集在一个目标区域中,漂浮水草区域的视觉特征比起漂浮落叶区域也更为明显。
接下来分别分析检测漂浮落叶区域和漂浮水草区域时各个模型的表现。当检测漂浮落叶区域時,4个Faster R-CNN架构的模型的平均精确度从18.09到34.05,可以看出不同的特征提取网络对模型的性能影响较大,Faster R-CNN Resnet101得到了全部8个模型里最高的精确度。与Faster R-CNN架构的模型不同,SSD架构模型的平均精度稳定在30.23到33.16,与Faster R-CNN相比SSD架构在检测漂浮落叶区域时对特征提取网络的敏感度不高,而且3个模型都能得到超过30的精确度,采用相同特征提取网络时SSD架构模型的精确度远高于Faster R-CNN架构。值得注意的是, InceptionV2特征提取网络配合Faster R-CNN时在8个模型中精确度最低,但是配合SSD时的精度能在8个模型中排第2名。
当检测漂浮水草区域时,不管是Faster R-CNN架构还是SSD架构,模型的精确度都与特征提取网络的选择有较大关联。在4个Faster R-CNN架构的模型中,依然是Faster R-CNN Resnet101得到了最高的精确度。在3个SSD架构模型中,情况与检测漂浮落叶区域有所不同,SSD Resnet50得到了不仅是3个SSD架构模型而是所有模型中最高的精确度,而SSD InceptionV2的精确度在3个SSD架构模型中,也从检测漂浮落叶时的最高变成了最低。
从类别加权平均精确度来看,SSD架构模型的精确度整体要好于Faster R-CNN架构模型的精确度。在Faster R-CNN架构中,特征提取网络InceptionV2的表现要低于Resnet50,但是在SSD架构中两者的表现却是相反的。当综合考虑精确度和速度后,SSD InceptionV2是最优的选择,在8个模型中精确度排第2仅次于Faster R-CNN Resnet101,而速度方面也排在第2名仅次于SSD MobilenetV2。我们仅测试了一个R-FCN架构模型,它的性能与使用同样特征提取网络的Faster R-CNN模型较为接近,精确度上相对更低但速度上也相对更快。
4.2 检测样张图像分析
为了避免引起歧义,两张测试图片均来自验证集而非训练集。图3展示了来自8个模型的一组检测结果。从对比中我们可以发现3种架构模型的检测结果的风格有很大的不同。使用Faster R-CNN架构的模型会对目标给出更多的预测,不仅仅是使用少量的边界框来覆盖一大片区域,而是给出多个长宽比不同的边界框来尽可能准确的描述图像中存在目标的区域。值得注意的是,Faster R-CNN InceptionV2和Faster R-CNN Resnet50两个模型预测出了数据集中没有标注的漂浮水草区域,经过确认我们判断这两个预测都是正确的。此外,Faster R-CNN Resnet101预测到了画面右上角存在漂浮落叶区域,经过放大后仔细检查我们发现在湖面反光背后的确藏着漂浮落叶,视觉上非常难以发现。通过以上的分析,我们可以认为Faster R-CNN架构的模型在处理困难目标时相对R-FCN和SSD有着一定优势。
由于缺少足够的人力,我们并没有将漂浮物区域标注的足够细致,我们希望相对粗略的标注信息足够使神经网络学习到有用的目标信息,而检测样张表明神经网络的学习能力相当强大。当然粗略的标注信息的缺点也很明显,尽管从检测样张来看,Faster R-CNN并不弱于SSD,但由于预测出较多的边界框使之与粗略的标注信息不符,从而影响了精确度结果。
图4展示了来自8个模型的另一组检测结果。在这张图像中,漂浮落叶的分布较为分散,漂浮落叶区域共有3种类型的背景,一种是浅色的树木倒影,一种是深色的树木倒影,还有一种是明亮的天空倒影。这组图像展示了各个模型处理困难目标的能力。尽管整体来看依然是Faster R-CNN架构的模型相比SSD架构的模型能给出更多的预测,但是不管是有着相同的架构或者是相同的特征提取网络,每个模型给出的预测结果都与其他模型有着很大的不同。由于我们的主要研究对象是目标检测架构,因此分析主要集中于对比有着相同或相似特征提取网络的模型。
当对比Faster R-CNN InceptionV2和SSD InceptionV2时,情况与之前的准确率结果完全不同,在面对困难目标时Faster R-CNN InceptionV2尽管与标注信息仍有一定差距,但已经相当准确且除去一个最大的边界框后依然覆盖了大部分漂浮物区域,相比之下SSD InceptionV2只给出了一个置信度只有70%的预测。但在对比Faster R-CNN Resnet50和SSD Resnet50时情况又有所不同,Faster R-CNN Resnet50仅仅检测出了一个天空倒影下的目标和一个错误的目标,而SSD Resnet50则检测出了浅色树木倒影中的漂浮落叶区域,尽管依然遗漏了另外两种背景中的目标但相比起Faster R-CNN Resnet50还是更优秀的那个。当将Resnet50升级为Resnet101后,Faster R-CNN架构的模型检测困难目标的能力也得到了提升。Faster R-CNN Resnet101和R-FCN Resnet101之间的对比也颇为有趣,Faster R-CNN Resnet101检测出了浅色树木和深色树木两种倒影中的漂浮落叶,而R-FCN Resnet101则检测出了深色树木和天空两种倒影中的漂浮落叶,两者都检测出了3种背景中的2种但并不是同样的2种。
从以上的对比分析中可以发现,当面对复杂背景下的困难目标,同时拥有丰富结构特征和相当深度特征的模型有着更好的检测能力。具体来说,面对困难目标时Faster R-CNN InceptionV2优于SSD InceptionV2,SSD Resnet50优于Faster R-CNN Resnet50。其中Inception模块使用了多个尺度的卷积核,SSD架构使用了多个层次的特征图,这两者都可以被视为利用了丰富结构的特征信息。Resnet是一系列深度非常深的神经网络,二阶段目标检测架构在两个阶段中都使用了特征提取网络,这两者都可以被视为利用了相当深度的特征信息。
5 总结与展望
在本篇文章中,我们提出了一个小型的水面漂浮物数据集,并且分析了3种目标检测架構的模型在数据集上的表现。数据集含有683张水面图像,总共标注2015个边界框,其中大多数为漂浮落叶区域和漂浮水草区域。通过使用事先在COCO数据集上预训练的模型在水面漂浮物数据集上进行迁移学习,实现了对水面漂浮物区域的目标检测。我们对8个模型在水面漂浮物数据集上的表现进行了分析,从数据上看,SSD相比Faster R-CNN和R-FCN有着更高的精确度,SSD InceptionV2有着最优秀的精确度与速度的平衡。从检测结果样张上看,Faster R-CNN能够给对目标更详细的预测,但由于与数据集中较粗略的标注信息不符从而影响了精确度。此外,通过分析含有复杂背景的样张,我们发现在面对困难目标时,同时利用丰富结构特征信息和相当深度特征信息的模型有着更好的处理能力。
到目前为止,水面漂浮物数据集仍然处于一个早期阶段,我们不仅需要扩充数据量还需要增加数据的多元性。算法方面,我们认识到了目标检测算法对于处理水面漂浮物的局限性。从检测结果样张来看,神经网络从粗略的边界框标注信息中学习到了水面漂浮物的视觉特征,但是受限于边界框的输出形式不能很好地将预测结果呈现出来。同时由于漂浮落叶区域和漂浮水草区域属于非物体分类,边界框的标注不能被当作唯一准确的标注信息,这也影响到了对模型准确率的判断。我们相信在目标检测模型的后期处理中加入一定的限制条件可以改善模型预测与标注信息的匹配程度,但我们认为基于边界框信息的弱监督语义分割模型才是处理水面漂浮物的更好的解决方案。
参考文献
[1]Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., & Fei-Fei, L. (2009, June). Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on (pp. 248-255). Ieee.
[2]Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., ... & Zitnick, C. L. (2014, September). Microsoft coco: Common objects in context. In European conference on computer vision (pp. 740-755). Springer, Cham.
[3]Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 580-587).
[4]Girshick, R. (2015). Fast r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 1440-1448).
[5]Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (pp. 91-99).
[6]Dai, J., Li, Y., He, K., & Sun, J. (2016). R-fcn: Object detection via region-based fully convolutional networks. In Advances in neural information processing systems (pp. 379-387).
[7]Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C. (2016, October). Ssd: Single shot multibox detector. In European conference on computer vision (pp. 21-37). Springer, Cham.
[8]Huang, J., Rathod, V., Sun, C., Zhu, M., Korattikara, A., Fathi, A., ... & Murphy, K. (2017, July). Speed/accuracy trade-offs for modern convolutional object detectors. In IEEE CVPR (Vol. 4).
[9]Arcos-García, ?., ?lvarez-García, J. A., & Soria-Morillo, L. M. (2018). Evaluation of Deep Neural Networks for traffic sign detection systems. Neurocomputing, 316, 332-344.
[10]Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., ... & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
[11]Arora, S., Bhaskara, A., Ge, R., & Ma, T. (2014, January). Provable bounds for learning some deep representations. In International Conference on Machine Learning (pp. 584-592).
[12]He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
[13]Sifre, L., & Mallat, S. (2014). Rigid-motion scattering for image classification (Doctoral dissertation, PhD thesis, Ph. D. thesis).
收稿日期:2019-04-07
作者简介:雷李义(1993-),男,汉族,硕士研究生,研究方向为领域为模式识别。
