基于相似主题和HITS的微博用户推荐算法研究
2019-08-05王嵘冰徐红艳安维凯
王嵘冰,徐红艳,冯 勇,安维凯
(辽宁大学 信息学院, 辽宁 沈阳 110036)
0 引言
Web 2.0时代的到来,使各类应用于社交的新媒体不断涌现。目前应用较为广泛的社交新媒体如: 新浪微博、Facebook、Twitter等。使用者通过这些新媒体可以得到自己感兴趣的资源与信息。国内社交新媒体的领军者新浪微博因用户群逐渐壮大而导致微博内容也随之激增,“信息迷航”问题[1]日益严峻。个性化推荐技术被认为是解决该问题的有效手段[2]。
本文在改进原始HITS(hyperlink-induced topic search)算法时将微博用户划分为不同的类别,在计算微博主题相似度时融入中心度及权威度,以达到提升推荐结果准确率的目的;对微博用户间的社交网络关系以及用户发布的微博主题内容进行分析,进而将兴趣、爱好相近的用户推荐给使用者。用户可以有效地利用这些社交平台提供的推荐功能来发现新朋友,进而使用户对社交平台产生依赖性,提高忠诚度。庞大的用户数量可以增强该社交平台的社会影响力,继而为平台带来可观的经济效益。
微博拥有数量庞大的用户群,只利用微博主题相似性去发现符合需求的用户推荐是难以实现的。本文以提高用户推荐准确度为目的,提出了一种基于相似主题和HITS的微博用户推荐算法。算法首先根据微博用户的粉丝数量、原创微博数量、转发微博数量来划分用户类别;然后,将改进后的HITS算法应用到微博用户权威度以及中心度的计算中。在本文中将重要用户划分为专家用户(Authority user)—Authority(权威度)值高、中枢用户(Hub user)—Hub(中心度)值高;最后按类别计算用户间的微博主题相似性,并进行兴趣相似微博用户的推荐。
本文的内容组织如下: 第1节是相关工作的介绍;第2节介绍基于相似主题的微博用户推荐算法框架;第3节对改进的推荐算法核心环节进行详细介绍;第4节介绍实验环节的设计及实验结果分析;第5节为本文的总结。
1 相关工作
1.1 微博重要用户发现方法研究
随着学者们对微博重要用户发现方法的深入展开,有研究者在推荐算法中运用微博主题相似性的计算来提升推荐质量[3]。代表性研究成果有: 仲兆满等[4]选择分别来自文化、企业管理、军事、时尚、教育5个领域的微博数据,利用这些数据来挖掘用户兴趣、计算用户相似度,但算法没有考虑到用户兴趣领域中的微博用户可分为不同的类型: 有的以原创为主,有的以转发为主,还有的以浏览为主。本文将上述三种类型用户命名为: 专家用户、中枢用户及普通用户。缺乏对用户所属类型的分析是导致推荐结果准确性不高的原因之一。姚彬修等[5]先对微博用户实施类型划分,接着对微博用户多源信息相似度进行计算,在计算时引入时间权重值和丰富度权重值。但该算法缺乏对微博用户之间社交网络结构的分析,因而该算法的推荐准确率依旧有待提高。彭泽环等[6]在设计推荐算法时考虑如下四类信息: 个人信息、社交网络结构信息、交互信息以及微博主题内容信息,但此推荐算法缺少对微博主题权重的进一步区分,因而推荐结果质量提升有限。
1.2 HITS算法
分析网页重要度的HITS算法是由美国康奈尔大学的Jon Kleinberg教授提出。该算法通过分析网页的链接关系来计算每个页面的Hub属性值和Authority属性值,并根据值的大小将网页分为Hub页面和Authority页面。
目前,HITS算法被广泛地应用在搜索引擎、自然语言处理、社交分析等领域。吴树芳等[7]针对传统的HITS算法,提出在计算微博用户可信度时融入博文内容以及用户交互行为的改进HITS算法。喻依等[8]通过HITS算法计算期刊的权威度和中心度来反映期刊的权威性和中心性,产生更权威性的期刊排序。苗家等[9]首先基于特征计算出评论的权重,然后结合图模型使用HITS算法得到正文句子权重,进而得到文摘句。上述算法都是使用HITS算法来计算链接图中节点的权威度和中心度。由于原始HITS算法仅仅考虑用户之间的链接关系,因而存在主题偏移、容易作弊等缺陷。
而本文所研究的微博用户之间的关注模型与网页的链入、链出模型很相似,因此建立链接图时,图中的节点为微博用户,图中的有向边为微博用户间的关注关系,通过改进HITS算法来准确计算微博用户的权威度和中心度,有效地解决了原始HITS算法的不足,从而提高微博用户推荐的准确率。
2 基于相似主题的微博用户推荐算法框架
随着微博用户数量的激增,将导致了多种用户类型的出现。例如: 微博认证用户以及普通微博用户。在社交平台中,普通微博用户通过浏览微博认证用户的微博来获取自己感兴趣的资源。而微博认证用户是浏览与自身兴趣相似或相近的其他微博认证用户的微博来获取资源。为使各类微博用户均能有效获取与自身兴趣相似的用户或信息,本文提出了一种基于相似主题的微博用户推荐算法。改进的算法包括如下四个环节[10]: ①用户社群划分—专家/中枢类、普通类;②用户类别划分—专家及中枢;③设定用户推荐关系;④微博主题相似度计算及Top-N推荐。其中环节②和环节④是算法的核心。改进算法框架描述如下:
(1)用户社群划分。根据用户拥有的粉丝量、转发微博量以及原创微博量划分出两大类用户社群: 专家/中枢类、普通类。计算如式(1)所示。
(1)
其中,F为用户粉丝数量,Y为原创数量,Z为转发数量,α和β的取值根据实验爬取的数据集确定。满足式(1)的用户不仅粉丝数量众多,而且微博信息量庞大,本文将该类用户归类为专家/中枢类。其他用户归类为普通类。
(2) 用户类别划分。对于步骤(1)中的专家/中枢类用户社群,本文将采用改进的HITS算法将其进一步划分为专家用户和中枢用户,此环节内容的实现过程详见3.1节。
(3) 用户推荐关系设定。步骤(1)和步骤(2)划分出了不同类型的用户,算法按照不同用户的需求进行推荐。各类型用户间的推荐关系设定如图1所示。在图中所示的推荐关系中,仅将专家用户推荐给中枢用户和其他专家用户,为普通用户仅推荐中枢用户。在推荐关系设定中,为普通用户推荐中枢用户的好处如下: ①普通用户无须关注过多的中枢用户即可获取中枢用户转发的多个专家用户的微博信息,从中发现与自身兴趣相同的信息。②专家用户兴趣单一,而中枢用户兴趣具有多样性,可将中枢用户所关注的专家用户的微博信息推荐给普通用户,这些信息分属不同兴趣领域,进而扩展普通用户的兴趣领域。

图1 用户推荐关系设定
(4) 微博主题相似度计算及Top-N推荐。该环节完成三类微博主题向量的计算: 原创微博主题向量(专家类)、转发微博主题向量(中枢类)以及所有微博主题向量(普通类)。对图1所示的三类推荐关系(专家推荐专家、专家推荐中枢、中枢推荐普通用户),本文使用余弦相似度来实现用户微博相似度的计算,根据计算结果完成Top-N推荐,此环节内容的具体实现详见3.2节。
3 推荐算法核心环节
3.1 用户类别划分
式(1)仅能将微博用户划分为两大类用户社群: 专家/中枢类、普通类。本文还需进一步区分专家用户和中枢用户,这个区分过程的实现可以借鉴HITS算法。传统HITS算法衡量检索到网页的重要度是通过如下两个指标来实现: 网页中心度(Hub)、权威度(Authority)[11]。据此,本文规定专家用户为Authority值高的微博用户,而中枢用户则为Hub值高的用户。受HITS算法中隐含假设的启发,我们同理认为社交平台中的专家用户与中枢用户之间的关注是相互的。本文将改进传统HITS算法,并使用改进后的算法来计算微博用户的Authority值和Hub值,以实现对专家用户和中枢用户的区分。
A(ui)为用户ui的Authority值,H(ui)为用户ui的Hub值。传统的HITS算法在计算用户Authority值时,仅累加该用户粉丝用户的Hub值,如式(2)所示;而计算用户Hub值时,也仅累加该微博用户所关注用户的Authority值,如式(3)所示。综上分析,传统的HITS方法因无法体现微博用户间的差异性而使计算所得的指标值准确率较低。
其中,d1,d2…,dj为用户ui的粉丝用户集合,t1,t2,…,tk为用户ui关注的用户集合。
每个微博用户类型具有自身的特点: 专家用户转发微博数量要远远小于原创微博数量,而中枢用户则恰恰相反。因而,在对HITS算法进行改进时将引入如下参数: 用户原创微博比例、用户转发微博比例。改进算法中对Authority值和Hub值的计算如式(4)、式(5)所示。
(4)
其中,Zdj为粉丝用户dj转发微博用户ui的微博数量,Ndj为用户dj的原创及转发微博数量和。
(5)
其中,Ytk为用户ui转发微博用户tk的原创微博数量,Ntk表示用户tk的原创及转发微博数量总和。
在HITS算法中使用式(4)和式(5),通过多次迭代计算所得的用户Hub值和Authority值更加精确,与传统的HITS算法相比能将用户之间的差异性体现得更为准确。
3.2 微博主题相似度计算及推荐
本文在计算用户微博主题相似度时,不同类别的用户将采用不同的计算方法。
(1) 针对普通用户: 整合该用户的所有转发和原创微博信息到一个文档中,继而运用LDA[12]对该普通用户的微博主题向量进行计算[13]。
(2) 针对专家用户: 计算其原创微博主题向量,如式(6)所示。
(6)
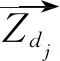
(3) 针对中枢用户: 计算其转发微博主题向量,如式(7)所示。
(7)
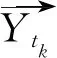
为了发现并推荐与使用者兴趣相似的其他微博用户,本文算法首先依据式(1)完成目标用户的社群划分[14],若目标用户划分到专家/中枢类用户社群,则继续使用式(4)、式(5)对Authority值和Hub值进行计算,以确定该用户是专家用户还是中枢用户;为了发现与目标用户兴趣相近的其他微博用户,微博主题相似度的计算使用余弦相似度[15]来实现。根据图1设定的微博用户推荐关系,为目标用户选择合适的用户类型进行微博主题相似度的计算。
上述微博主题相似度计算如式(8)所示。
(8)
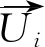
3.3 核心算法设计

算法1 相似主题的微博用户推荐算法

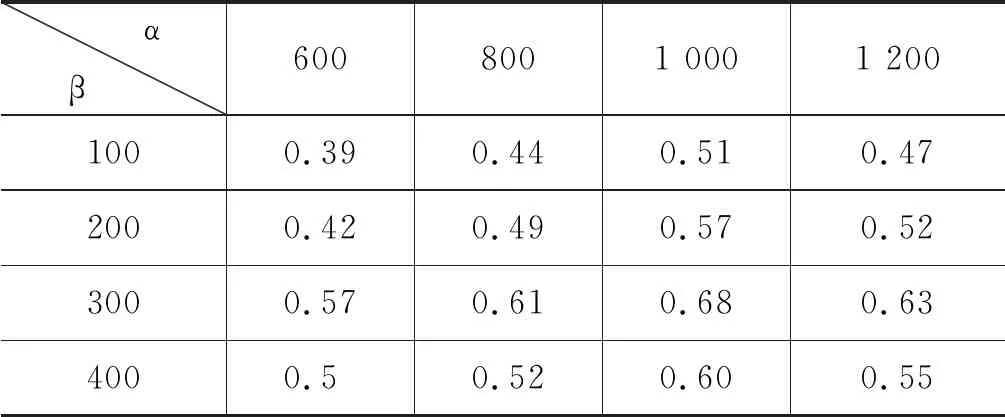
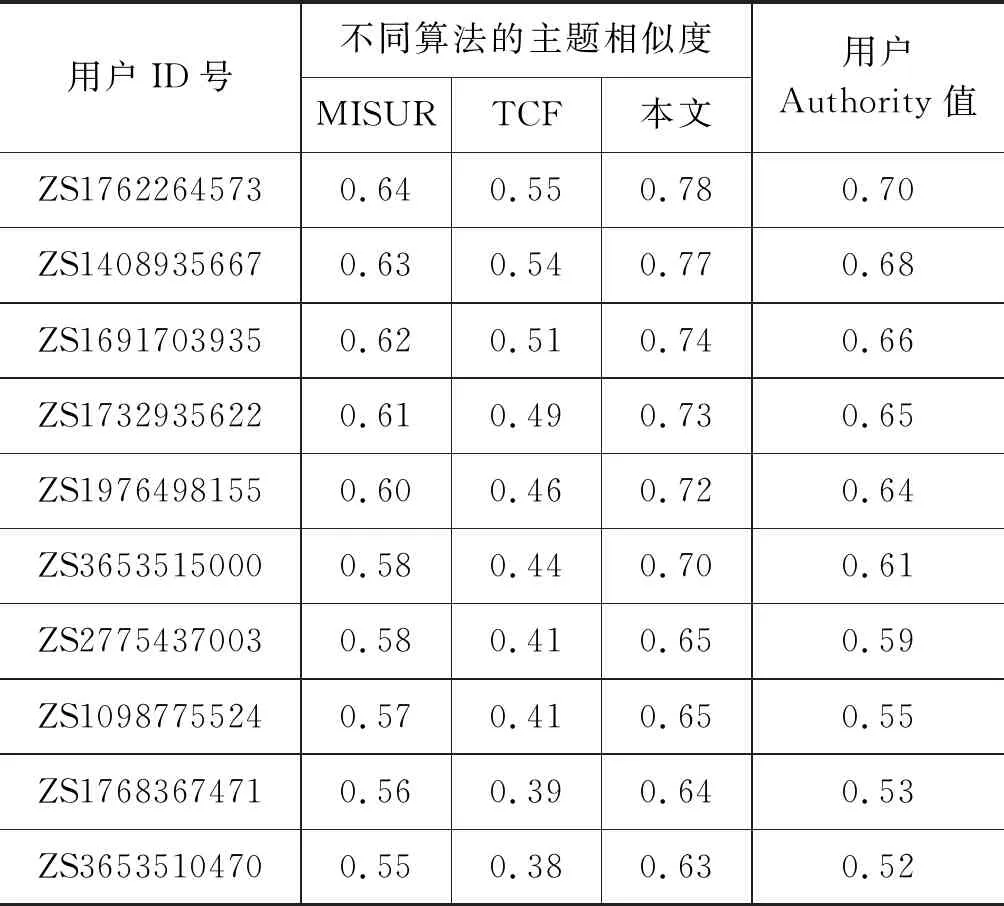
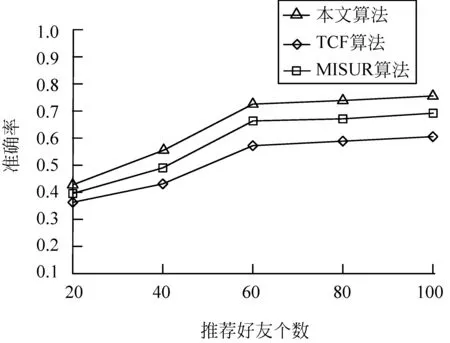
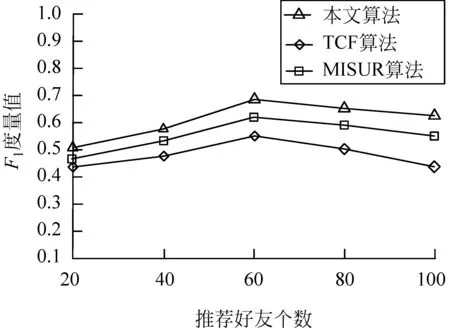
6: endif7:endfor//步骤2:改进的HITS算法8:fork=1tondo9: uk.auth=1;//Authority初始值设置为110:uk.hub=1;//Hub初始值设置为111:endfor12:forj=1tondo13. uj.auth=Get_Auth(uj.hub,Y);//用户uj的Author-ity14. uj.hub=Get_Hub(uj.auth,Z);//用户uj的Hub15:endfor//步骤3:用户类别划分—专家用户与中枢用户16:fork=1tondo17: ifuk.auth>>uk.hub&&uk∈L118: Uzj.AddUser(uk);//uk添加为专家用户Uzj19: elseifuk.auth< 在改进的HITS算法中: 引入用户微博转发率和用户微博原创率作为链接系数,用户之间的链接系数越大表明用户之间有更多的相似兴趣,因而有效解决主题偏移问题;此外,算法中还引入用户之间的微博转发率和原创率,即使作弊用户关注大量专家用户,但是作弊用户与专家用户之间的链接系数却很低,有效降低作弊用户的Hub值,使容易作弊问题得到有效的解决。 由于本文计算用户Authority值只是将原始HITS算法计算权威度的每一个Hub值乘以用户的微博转发率,计算用户Hub值也仅在原HITS算法计算中心度的每一个Authority值乘以用户的原创率(微博转发率、原创率均为介于0到1之间数值)。即若原始HITS算法计算所得的权威度记为A(i)、中心度记为H(i),本文算法计算所得的用户权威度和中心度分别为A′(i)和H′(i),则有A′(i)≤A(i),H′(i)≤H(i),改进算法的迭代规则与原始算法相同,因此,改进后的HITS算法依旧保持收敛。在算法设计中最大迭代次数max_iterations=150,最小误差阈值ε=0.001,在算法执行过程中,在进行105次迭代计算后收敛,得到稳定的数值。 本文实验所需的软硬件环境配置: 操作系统为Windows7、CPU为i5-4460、主频3.20GHz、硬盘空间50GB及以上、内存2GB及以上,编程语言为Java。在Eclipse环境下搭建实验平台并完成实验方案设计。Mahout为Apache的一个开源工具,提供大多数经典推荐算法的代码。在实验过程中使用和改编的对比算法均为封装在Apache Mahout框架中的协同过滤推荐算法。 本文通过新浪微博提供的API接口和爬虫工具[17],从新浪微博中选取8个常见的主题领域: 体育领域、美食领域、科技领域、健康领域、汽车领域、情感生活领域、房产领域和娱乐领域,实验中从这些领域中各随机选取10名种子用户进行辐射以爬取实验数据,最终采集微博用户信息15万条、微博主题信息5 000万条。按照式(1)将15万名用户划分到不同的用户社群: 专家/中枢类包含10 516名用户,剩下的用户均为普通类;进而继续使用用户类别划分算法将10 516名用户划分成4 275个专家用户、6 241个中枢用户。 实验中根据爬取的数据集确定参数α和β的取值。α=sum(数据集中所有用户的粉丝数量)/count(数据集中的用户);β=sum(数据集中所有用户的微博数量)/count(数据集中的用户)。针对本文数据集的计算结果α=1000、β=300。 为了验证本文参数α和β取值的合理性,在实验过程中另外选取α为600、800、1200,β为100、200、400,再加上本文选取的α=1000,β=300。根据不同的α和β取值组合进行实验,对每一组实验的F1值进行计算,结果如表1所示。 表1 不同α和β值对应的F1度量值 从表1的实验结果可以看出,当参数α=1 000、β=300时,F1度量值最大,实验效果最好。 实验选取的数据分布如表2所示。 表2 各领域实验数据分布 实验中分别从不同类别的微博用户中随机选取1名用户以验证用户分类的准确性: ① 中枢用户1772598673,微博主题领域为美食领域,原创微博数为615,转发微博数为12 650,用户Hub值为0.719 3; ② 专家用户3606455372,微博主题领域为情感生活领域,原创微博数为12 675,转发微博数为3 009,用户Authority值为0.672 3; ③ 普通用户1863606222,微博主题领域为科技领域,用户原创微博数为488,用户转发微博数为576。 对于不同类型微博用户的推荐结果如表3~表5所示。 表3~表5中的数据表明: 在三种类型用户的Top-10推荐列表中,对于同一个用户ID号,应用本文算法所推荐的主题相似度值均要高于MISUR算法和TCF算法。 表3 专家用户推荐结果列表 表4 中枢用户推荐结果列表 表5 普通用户推荐结果列表 续表 为了更好地验证本文算法的优势,本文选取了传统的微博用户推荐算法与本文算法进行对比: ①TCF[18]算法将协同过滤和标签进行结合: 算法在计算资源特征相似性和用户偏好度时融入资源标签,并应用基于资源的协同过滤推荐算法来完成资源的TOP-N个性化推荐;MISUR[5]算法在进行微博用户推荐时,考虑用户的社交信息、交互关系以及微博内容等多源信息,在计算总相似度时融入了时间权重因子及丰富度权重因子,最后根据计算所得的相似度值向用户进行Top-N推荐;本文算法与TCF算法和MISUR算法在推荐好友个数不同情况下的准确率、召回率和F1度量值[19]对比结果如图2~图4所示。 图2 不同算法推荐准确率对比 图3 不同算法推荐召回率对比 图4 不同算法推荐F1度量值对比 由图2可以观察到三种算法的推荐准确率随着推荐好友个数增加而不断提升,当推荐好友个数达到60时趋于平缓。在推荐好友为20时,本文算法的准确率比TCF算法提高了19.4%,比MISUR算法提高了7.5%;在推荐好友为60时,本文算法的准确率比TCF算法提高了28.6%,比MISUR算法提高了9.1%;在推荐好友为100时,本文算法的准确率比TCF算法提高了25%,比MISUR算法提高了8.7%。 从图3可以看出三种算法的召回率随着推荐好友个数增加而下降,当推荐好友个数小于60时下降较为平缓。当推荐好友个数为20、60、100时,本文算法的召回率与TCF算法相比分别提升了14.3%、17.3%、40.5%,比MISURF算法分别提升了4.9%、7%、15.6%。分析表明,随着推荐好友个数的增加,本文算法的召回率要优于其他两种对比算法。 图4中的数据表明,当推荐好友个数增加时,三种推荐算法的F1值都有所提升。当推荐好友数量达到60时,各算法的F1度量值均达到峰值;当推荐好友数量超过60后,各算法的F1度量值均在下降。产生这种情况的主要原因为: 当推荐好友数量偏多时,排名靠后用户的Authority值和Hub值都偏低,应用本文算法时无法体现这些专家/中枢用户的重要度,所以影响了微博主题相似性的计算,导致F1度量值下降。 根据图4中三种算法F1值的对比可以看出: 在推荐结果准确率上本文算法要优于MISUR算法和TCF算法。原因如下: 数据稀疏性问题是传统的TCF算法中存在的弊端,也是推荐准确率低的重要原因;MISUR算法虽然通过用户多源信息的融入来缓解数据稀疏问题对推荐结果的影响,但是缺乏对微博用户的社交结构信息进行考量。本文算法首先运用改进的HITS算法分析微博用户的网络拓扑结构,并根据分析的结果将用户划分为专家用户、中枢用户和普通用户,进行相似度计算时结合不同类型用户的行为特点,即本文在进行微博主题相似性计算时既考虑到微博用户的社交网络结构,又引入了Authority值和Hub值,从而使推荐准确率得到有效提升。 本文算法旨在解决传统个性化推荐算法普遍存在的推荐准确率较低的不足。所提算法在使用改进的HITS算法对微博用户的社交网络结构进行分析的基础上,将微博用户划分为专家用户、中枢用户及普通用户3个类型;在计算微博主题相似度时,既结合用户的Authority值和Hub值,又结合用户原创及转发微博信息的数量。通过本文算法与TCF算法和MISUR算法进行对比,结果表明本文算法由于考虑到微博用户的网络结构信息,同时采用改进的HITS算法准确地计算微博用户的Authority值和Hub值,在进行微博主题相似度计算时,融入计算所得的Authority值和Hub值,从而较大程度地提升了推荐的准确率。3.4 改进算法收敛性分析
4 实验实施与结果分析
4.1 实验环境配置
4.2 实验数据

4.3 实验结果与分析




5 结束语
